本記事は、ディープラーニングモデルの軽量化ツールPCASの使い方 (3) ーモデル変換と性能評価 (CPU/VPU) 編ー の続編です。
前回の記事では、モデル軽量化ツールPCAS(以下、PCASツール)を使用して軽量化したVGG10モデルを例に、OpenVINO形式(IR形式)への変換を行い、AE2100・汎用PC上で推論速度の実測評価をしました。
今回は、使用するモデルやデータ拡張、損失関数などに pytorch-image-models (timm) の実装を利用したいと思います。
本記事の要約
- PCASツールと画像分類ライブラリtimmの連携方法を解説します。
- 「Vegetable Image Dataset + MobileNetV2」を例題に、モデルの軽量化を行います。
- AE2100と汎用PC上での推論速度を実測し、軽量化効果を確認します。
PCASツール と pytorch-image-models (timm) を連携する
PCASツールは、豊富な種類のモデルやデータ拡張手法、損失関数を備える画像分類用ライブラリである pytorch-image-models (timm) と連携可能です。基本的な使用方法は、過去記事(第2回)で説明した内容と同じですが、使用するエントリーポイントと引数が異なります。
データセットの準備(Vegetable Image Dataset)
今回は例題として、トマトやカボチャなど15種類の野菜画像の分類を扱う「Vegetable Image Dataset 1」を使用したいと思います。

このデータセットには、解像度が224x224ピクセルの学習用画像15,000枚、評価用画像3,000枚が含まれ、以下のディレクトリ構造で格納されています。
vegetable_image_dataset/
├── train/ # 学習用
│ ├── Bean/ # クラス名
│ | ├── 0001.jpg # 「Bean」クラスの学習用画像
│ | ├── 0002.jpg
| ~~~ 省略 ~~~
│ ├── Radish/
│ └── Tomato/
└── validation/ # 評価用
├── Bean/ # クラス名
│ ├── 0023.jpg # 「Bean」クラスの評価用画像
│ ├── 0024.jpg
~~~ 省略 ~~~
├── Radish/
└── Tomato/
※ 分類したいクラス毎にフォルダが分かれている点にご注意ください。
利用可能なデータセットとモデルを確認する
PCASツール上でtimmを利用するには、エントリーポイントとしてexamples/classification/train_timm.pyを使用します。まず、現在PCASツール上に登録されていて利用可能なデータセットとモデルを確認します。
データセットとモデルの登録情報は、それぞれ--show_datasetsと--show_modelsのコマンドで、以下のように確認可能です(※記事スペースの都合で表示の一部を省略しています)。
> python examples/classification/train_timm.py --show_datasets --show_models
Registered datasets: # 登録済みのデータセット
['imagefolder_timm',
'my_cifar10']
Registered models: # 登録済みのモデル
['vgg16_bn_timm',
'resnet50_timm',
'cspdarknet53_timm',
'mobilenetv2_100_timm',
'my_vgg10']
この確認コマンドは、examples/classificationディレクトリの下位に含まれる登録内容を参照しています。timmのプリセットとして登録されているものは、XXX_timmという名称が付けられていますので、その中から使用するものを選択します。
今回は、timm用の汎用データセット(imagefolder_timm)とMobileNetV2モデル(mobilenetv2_100_timm)を使用します。なお、プリセットに含まれないtimmのモデルも、VGG10モデルの場合 と同様の方法で自由に追加可能です。
スクラッチ学習と軽量化を実行する
train_timm.pyでは、PCASツールの引数とPytorch Lightningの引数の他に、timm公式の学習用コードで使用されている引数の一部が利用できます。例えば、データ拡張のランダムイレース(--reprob)やモデルパラメータの指数平滑移動平均(--model-ema)、ラベル平滑化(--smoothing)などが利用可能です。
Vegetable Image Datasetに対して、MobileNetV2モデルのスクラッチ学習と軽量化を実行します。今回のケースでは学習に使用できる画像枚数が少ないため、軽量化ループ回数には、多めの21回を指定しています。
python examples/classification/train_timm.py \
--outdir /result/vegetable_mobilenetv2 \
--data_dir /data/vegetable_image_dataset \
--dataset imagefolder_timm \
--train-split train \
--val-split validation \
--model mobilenetv2_100_timm \
--max_epochs 300 \
--devices 2 \
--pcas_max_iters 21 \
--mode train \
--finetune_lr_ratio 0.3 \
--learning-rate 0.5 \
--batch-size 64 \
--reprob 0.5 \
--smoothing 0.1 \
--model-ema \
--pretrained
本例では、GPUを2枚使用(--devices 2)し、--train-splitと--val-splitで /data/vegetable_image_dataset 内の学習用・評価用ディレクトリを指定しています。
また、--pretrainedの指定により、timmが提供するImageNet学習済みモデルを重みパラメータの初期値として利用しています(※ SSL認証エラーが原因でダウンロードに失敗する場合は、引数に--proxy envあるいは--proxy $http_proxyを追加してお試しください)。
軽量化結果を確認する
まず、具体的な軽量化結果の確認方法については、過去記事(第2回) と同様の方法で行っていますので、適宜ご参照願います。まずは、浮動小数点演算回数(FLOPs)とパラメータ数に対する認識精度の関係をグラフ化します。
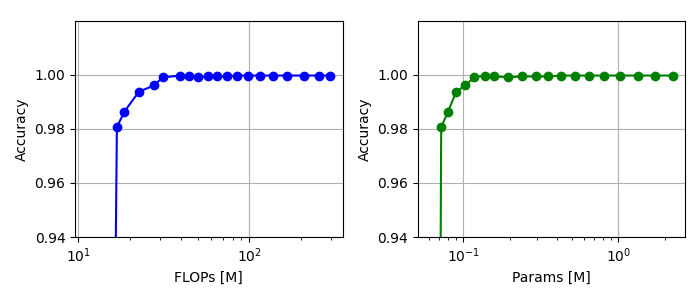
可読性を高めるために、横軸を対数に変更し、縦軸を拡大しています。グラフ上のデータ点ひとつひとつがモデルを表し、グラフの一番右側のデータ点が軽量化を実施していないオリジナルモデルで、左側のデータ点になるほど軽量化レベルが大きいモデルとなります。
精度98%付近のモデルを軽量化すると精度が一気に劣化したことから、軽量化の限界 はこの辺りと言えそうです。
AE2100 (CPU/VPU) 上で推論速度を計測する
まず、過去記事(第3回)に掲載しているモデル変換方法にしたがって、軽量化済みモデルをONNX形式に変換し、さらにそれをOpenVINO形式(IR形式)に変換します。変換後のモデルをAE2100に転送してCPUとVPUによる推論速度を計測します。
※ AE2100のセットアップ方法についても上記の過去記事をご参照ください。
推論速度の計測には、OpenVINOツールキットが提供するAPI("benchmark_app")を使用します。今回は、1000回分の推論(-niter 1000)における8個の非同期実行(-nireq 8)の場合の推論速度を計測します。例えば、以下のように実行します。
> benchmark_app -m iter00_train_epoch242.xml -d CPU -niter 1000 -nireq 8
Count: 1000 iterations
Duration: 24810.45 ms
Latency: 195.60 ms
Throughput: 40.31 FPS
また、今回は軽量化後のモデル数が多いので、上記でグラフ化した結果から、オリジナルモデル("Original")と精度が100%付近で最もFLOPsが小さいモデル("Iter14")、および精度98%付近でFLOPsが最も小さいモデル("Iter18")、の計3つに計測対象を絞りたいと思います。
さて、AE2100上で実際に計測したところ、以下の結果となりました。
| 軽量化レベル (圧縮率)2 | 認識精度 | FPS - CPU | FPS - VPU | モデルサイズ3 |
|---|---|---|---|---|
| Original (0%) | 100.0% | 40.31 | 166.93 | 4,350KB |
| Iter14 (90%) | 99.9% | 278.10 | 427.96 | 224KB |
| Iter18 (95%) | 98.1% | 455.80 | 459.00 | 121KB |
CPUとVPUのどちらの結果とも、軽量化レベルの増加とともにFPSが高まる傾向が確認でき、オリジナルとIter18を比べると、CPUでは 約11.3倍、VPUでは 約2.7倍 の改善効果が得られました。
ここでIter18に関するFPSに注目すると、CPUとVPUには差が3.2 FPSしかありません。その理由としては、VPUは畳み込み演算自体を高速化しますが、PCASにより畳み込み演算の規模が大幅に縮小したため、VPUの効果が表れ難くなったことが考えられます。
汎用PC (CPU) 上で推論速度を計測する
続いて、汎用PCにおけるCPU推論速度を計測します4。
| 軽量化レベル (圧縮率)2 | 認識精度 | FPS | モデルサイズ3 |
|---|---|---|---|
| Original (0%) | 100.0% | 160.10 | 4,350KB |
| Iter14 (90%) | 99.9% | 894.71 | 224KB |
| Iter18 (95%) | 98.1% | 1376.07 | 121KB |
解像度が224x224の画像を入力としていますが、最大約8.6倍のFPSの改善効果を確認できました。なお、本検証に使用したCPUは、リソース制約のあるAE2100に搭載の組込み用CPUではないため、より高いFPSが計測されています。
ユーザーは、認識精度を重視したモデル("Iter14")か、あるいは推論速度・モデルサイズを重視したモデル("Iter18") か、をデプロイ先の要求に応じて選択することができます。
INT8量子化機能を使用する(汎用PCでの実行)
過去記事(第3回)と同様に、AE2100がINT8演算の高速化に有効なAVX命令に対応していないため、汎用PC でINT8量子化による高速化効果を測定します。
以下の例のように、前記コマンド に対して、引数--quantization W8A8を追加するだけで、INT8量子化モデルの「スクラッチ学習と軽量化」が実行できます。
python examples/classification/train_timm.py \
--outdir /result/vegetable_mobilenetv2 \
--data_dir /data/vegetable_image_dataset \
--dataset imagefolder_timm \
--train-split train \
--val-split validation \
--model mobilenetv2_100_timm \
--max_epochs 300 \
--devices 2 \
--pcas_max_iters 21 \
--mode train \
--finetune_lr_ratio 0.3 \
--learning-rate 0.5 \
--batch-size 64 \
--reprob 0.5 \
--smoothing 0.1 \
--model-ema \
--pretrained \
--quantization W8A8 # 追加
まずは、INT8量子化モデルの軽量化結果についても、浮動小数点演算回数(FLOPs)とパラメータ数に対する認識精度の関係をグラフ化します。
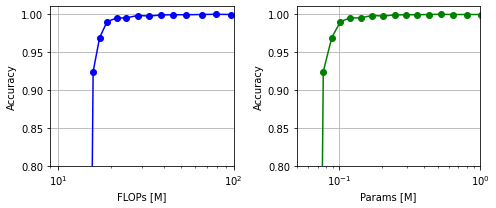
INT8モデルの場合、認識精度が93%を下回る軽量化レベル以降で、急激に精度が劣化する傾向が見られました。FP16モデルの評価と同様に、オリジナルモデルと、認識精度が100%付近の軽量化レベル"Iter13"と、98%付近の軽量化レベル"Iter15"について、OpenVINO形式にモデル変換を行った後、CPU推論速度を計測します4。
| 軽量化レベル (圧縮率)2 - ビット精度 | 認識精度 | FPS | モデルサイズ3 |
|---|---|---|---|
| Original (0%) - FP16 | 100.0% | 160.10 | 4,350KB |
| Iter14 (90%) - FP16 | 99.9% | 894.71 | 224KB |
| Iter18 (95%) - FP16 | 98.1% | 1376.07 | 121KB |
| Original (0%) - INT8 | 100.0% | 846.07 | 2,191KB |
| Iter13 (88%) - INT8 | 99.5% | 2181.88 | 141KB |
| Iter15 (91%) - INT8 | 98.3% | 2391.69 | 102KB |
評価の結果、FP16モデルに比べて軽量化レベルは落ちたものの(iter18 → iter15)、FPSとモデルサイズの両方において、より良い軽量化を達成しています。
軽量化前のオリジナルモデル("Original - FP16")と最も軽量化したモデル("Iter15 - INT8")を比較すると、約1.7%の精度劣化で、FPSが約14.9倍、モデルサイズが約1/42倍の効果が得られました。
今回、例題に用いた「Vegetable Image Dataset」に対しては、ほぼ精度劣化無く大幅に軽量化することができましたが、これは 初回の記事 でお伝えした、モデル規模のミスマッチが大きかったことが原因と思われます。
つまり、MobileNetV2モデルは、1000クラスの画像分類問題(ImageNet Dataset)を解くために設計されましたが、Vegetable Image Datasetは15クラスの画像分類問題を対象としていて、それらの難易度に差があることから(15クラスの方が易しい)、その15クラス分類を行うには不要な演算が多分に含まれていた、と推測できます。
モデル内に存在する全ての畳み込み層を対象に、手作業で不要な演算を特定すること(≒モデル分析作業)は大変かつ困難ですが、PCASツールでは自動で最適化できるので効率的です。
まとめ
本記事では、「Vegetable Image Dataset + MobileNetV2」の例題を通して、PCASツールとpytorch-image-models (timm) を連携利用する方法をご紹介しました。次回は、物体検出モデルを軽量化する例を解説したいと思います。
⇒ ディープラーニングモデルの軽量化ツールPCASの使い方 (5) ー物体検出モデルの軽量化編ー
本記事のバックナンバー:
ディープラーニングモデルの軽量化ツールPCASの使い方 (1) ーインストール編ー
ディープラーニングモデルの軽量化ツールPCASの使い方 (2) ー画像分類モデルの軽量化編ー
ディープラーニングモデルの軽量化ツールPCASの使い方 (3) ーモデル変換と性能評価 (CPU/VPU) 編ー
-
Ahmed, M. I., Mamun, S. M., & Asif, A. U. Z. (2021, May). DCNN-Based Vegetable Image Classification Using Transfer Learning: A Comparative Study. In 2021 5th International Conference on Computer, Communication and Signal Processing (ICCCSP) (pp. 235-243). IEEE. ↩
-
軽量化レベルを"IterXX"と呼び、XXには軽量化処理のループ回数が入ります。XXが大きくなるほど軽量化されたモデルとなります。圧縮率は、モデル全体のチャネル数に対する削減比率を表すもの(値が大きいほど削減量が多い)で、今回の軽量化処理ループ1回におけるチャネル削減率を$c$、プルーニングを行った回数を$n$とすると、$1−(1−c)^n$ で計算されます。今回のケースでは、デフォルト値である $c=0.15$(引数
--comp_rateで指定可能) を使用しています。 ↩ ↩2 ↩3