背景
今年社会人になったばかりということもあり、日々大量の情報をインプットしなければいけなくなってしまいました。
インプットする内容は何も社内の情報だけではありません。社会人たるもの、社会の情勢、エンジニアなら世間を賑わせている技術には常に高いアンテナを張っておくべきです。
今までは、出勤後の10~20分程度を技術記事の閲覧に充てていましたが、冷静に考えたら「技術記事の要約を出退勤の歩いている途中に動画で見れたらよくね?」という発想に至りました。
ということで本記事では、最近流行りのAI系のAPIをフル活用し実現を目指します。
対象読者
- AI関係のAPIの使用感をサクッと知りたい方
- AIで何かしらをやってみたい方
環境
- Mac O S13.3.1(Ventura)
使用API
- openAI gpt-4-turbo
- DALLE-E 3
- Text-to-Speech API
- Google Drive API
- (いけたら)AWS
成果物
成果物のワークフローを以下に設定します。
- 技術系のニュースをスクレイピング
- スクレイピングした内容を要約 & 関連した画像を生成
- 要約した文章を音声データ化
- 上記までで生成した音声データと画像を結合して映像データ化
- 映像データをGoogle Driveに保存
- 通勤中に自分で視聴!!圧倒的情報収集!!

こちらに今回のコードから生成した動画を視聴することができるので、是非とも試聴してみて下さい!(ただし、記事の要約はプライバシーポリシーに抵触するかもしれないので、代わりに弊部HPのコラムの要約をしています。)
また、今回のコードはこちらに公開しております。
以降の説明では、コードの主要部分のみ掲載しているので気になる方は是非ともお手元の環境でコードを参照しながらお読みになって下さい。
では、上記のワークフローに沿ってコードを作成していきます。
実装
1. 技術系のニュースをスクレイピング
今回は要約のソースとなる記事として「TECH+ 」を引用させていただきます。こちらは著作権と転載についてを読むに、driveに保存して自身で鑑賞する分には問題なく今回の要件にマッチしていると考えました。
以下該当コードです。
def main(content_num):
print("Start Scraping")
target_url = ['https://news.mynavi.jp/techplus/']
links = get_contents(target_url, "article-content", "href")
texts = get_contents(links, "article-body", "text")
print("Done Scraping")
return texts[:content_num], links[:content_num]
def get_contents(urls, class_, attr):
session = requests.session()
contents = []
for url in urls:
res = session.get(url)
bs = BeautifulSoup(res.text, "html.parser")
elems = bs.find_all(True, class_=class_)
for elme in elems:
if (attr == "text"):
contents.append(elme.get_text().replace('\n', ''))
else:
contents.append(elme.get(attr))
session.close()
return contents
こちらは一般的なBeautiful Soupのコードであるので説明は割愛します。
2. 要約
ここからが本題です。
今回は先ほどスクレイピングしてきた文章をOpenAIのgpt-4-turbo(gpt-4-1106-preview)を使用して要約します。
こちらからOpenAIにログイン可能です。
「API」->画面左メニューの「API keys」->「+ Create new secret key」
上記の順番に押下していくと、APIキーを作成することができます。
ただし、こちらの利用料金としてgpt-4では下記の料金が発生します。
個人利用すると若干お高いですね。。。
| 種別 | 利用料 |
|---|---|
| Input | $0.03/1K tokens |
| Output | $0.06/1K tokens |
では、上記のAPIキーを使用して要約してもらうコードを書いていきます。
import requests
import importlib
from dotenv import load_dotenv
load_dotenv()
import os
import urllib.request
from openai import OpenAI
from utils import get_datetime
importlib.reload(get_datetime)
system_command_summarize = "あなたはライターです。今から与える文章を中学生でもわかるように以下の制約条件に従って要約してください。# 制約条件:・500文字以内で出力してください。・敬語で出力してください。"
def main(contents):
print("Start Summarize")
summaries = []
for idx, content in enumerate(contents):
summary = summarize(content)
summaries.append(summary)
summaries = " 次の話題です。 ".join(summaries)
summaries_list = []
i = 0
batch_size = 200
while (i+1)*batch_size < len(summaries):
summaries_list.append(summaries[i*batch_size:(i+1)*batch_size])
i += 1
summaries_list.append(summaries[i*batch_size:])
print("Done Summarize")
return summaries_list
def summarize(content):
url = "https://api.openai.com/v1/chat/completions"
header = {
"Content-Type": "application/json",
"Authorization": "Bearer ここに先ほど取得したAPIキーを記入"
}
payload = {
"model": "gpt-4-1106-preview",
"messages": [{
"role": "system",
"content": system_command_summarize
},
{
"role": "user",
"content": content
}
]}
res = requests.post(url, headers=header, json=payload)
return res.json()["choices"][0]["message"]["content"]
上記のコードで重要なの2つあります。
1つ目がプロンプトです。
system_command_summarize = "あなたはライターです。今から与える文章を中学生でもわかるように以下の制約条件に従って要約してください。# 制約条件:・500文字以内で出力してください。・敬語で出力してください。"
プロンプトを書くときの常套手段としては以下が有名です。
- どのような立場であるべきか
- 「中学生でもわかるように」という文言を加える
- #で段落を分ける
今回は自腹でのAPI使用なので、文字数を抑えるために具体的に書いていませんが、必要に応じてもっと指示を与えてもいいかもしれません。
2つ目がheaderとpayloadの部分です。
header = {
"Content-Type": "application/json",
"Authorization": "Bearer ここに先ほど取得したAPIキーを記入"
}
payload = {
"model": "gpt-4-1106-preview",
"messages": [{
"role": "system",
"content": system_command_summarize
},
{
"role": "user",
"content": content
}
]}
先ほど取得したAPIキーをheaderのAuthorizationに、プロンプトをpayloadのmessages.contentに、要約したい元の文章をmessages.contentに渡してあげます。
以上のリクエストを投げると、次のような結果が返ってきます。
{
...
"model": "gpt-4-1106-preview",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "ここにgptの返事が入る"
},
"finish_reason": "stop"
}
],
...
}
つまり、choices[0].message.content にアクセスすると欲しい返値が得られます。
これで今回したいことの80%が終了しました。
こんなに簡単にAIを活用できるとは凄まじいですね。
参考:https://platform.openai.com/account/organization
参考:https://platform.openai.com/docs/guides/text-generation/chat-completions-api
参考:https://qiita.com/yousan/items/3d53ee3922dffa191987
3. サムネイル作成
正直 2. までで自分の要求はほぼ満たされているのですが、折角なのでもっと他のサービスも活用していきます。
まずは、先ほどの要約に関連するサムネイルを生成していきます。
今回は画像生成にOpenAIのDALL-E 3を使用します。
DALL-E 3 は2. と同様にOpenAIの提供するサービスですので、先ほどのアカウントをそのまま使用することができます。
また使用量は以下のとおりです。
良い品質の画像がこの値段で手に入るのは素晴らしいですね。
| サイズ | 料金 |
|---|---|
| 1024 x 1024 | $0.04/枚 |
| 1024 x 1792 | $0.08/枚 |
では、該当コードを見ていきます。
system_command_thumbnail = "あなたはプロンプトエンジニアです。動画のサムネイルを、DALL-E-3によって自動生成します。自動生成する際に使用するプロンプトを以下の制約条件に従って出力して下さい。# 制約条件:・200文字以内で出力してください。・人の目を引くような画像をDALL-E-3が出力するためのプロンプトを出力して下さい。・DALL-E-3が出力するサムネイルが、下記の動画内容を加味するようなプロンプトを出力して下さい。# 動画内容:"
def get_thumbnail(summary):
client = OpenAI()
prompt = summarize(system_command_thumbnail + summary)
response = client.images.generate(
model="dall-e-3",
prompt=prompt,
size="1024x1024",
quality="standard",
n=1,
)
result_url = response.data[0].url
output_path = f'../data/image/{get_datetime.get_date()}.png'
urllib.request.urlretrieve(result_url, output_path)
ここではプロンプトに注目して下さい。
あなたはプロンプトエンジニアです。動画のサムネイルを、DALL-E-3によって自動生成します。自動生成する際に使用するプロンプトを以下の制約条件に従って出力して下さい。# 制約条件:・200文字以内で出力してください。・人の目を引くような画像をDALL-E-3が出力するためのプロンプトを出力して下さい。・DALL-E-3が出力するサムネイルが、下記の動画内容を加味するようなプロンプトを出力して下さい。# 動画内容:[要約した内容]
プロンプトを上記のようにして、要約された内容をそのままプロンプトに組み込みます。
そのプロンプトによって生成されるプロンプトをDALL-E 3の入力とします。
このようにすることで、例えば記事の内容が「迷路ゲーム」をテーマに書かれた記事であるとこのような画像を生成することができます。

「人の目を引く」という文言が刺さったのか、毎回良い画像を出力してくれてますね。
ちなみに、OpenAIの利用料はまとめてこちらから確認することができます。
参考:https://platform.openai.com/docs/guides/images/usage?context=node
参考:https://openai.com/pricing
4. 音声読み上げ
次は動画化の肝となる音声読み上げです。
長いニュースを耳から入れることになるので、可能な限り聞きやすい声がいいですよね。
そこで今回選んだのが GooGle APIのText-to-Speechです。
最近発表された Neural2というモデルであれば本当のニュースキャスターが読み上げてくれるような安心感のある声で話してくれます。
また利用料に関しては以下のとおりです。
| モデル | 1ヶ月あたりの無料枠 | 無料の使用上限にと移した場合の料金 |
|---|---|---|
| Nueral2 | 0 ~ 10,000,000バイト | $0.000016/B |
大体6分くらいの音声データで1.5MB(=15,000B)あたりなので、全然無料枠で使うことができます。
個人利用勢にはあまりにも良心的ですね。
APIの使用準備に関しては、こちらの「3. 認証の設定」までに綺麗にまとまっていたのでそちらを参考にしてみて下さい。
上記の参考ページでGCP側のセットアップが終わったら次にアクセストークンを取得します。
アクセストークンの取得にはこちらを参考にしてみて下さい。
上記の参考ページの「5. curlを用いたアクセストークンとリフレッシュトークンの取得」まで行うと、リフレッシュトークンを取得することができるので、次回以降はそのリフレッシュトークンを利用して半永久的にコードを回し続けることができます。
このようにリフレッシュトークンを取得しなければ、Google APIは自動で動かすことができず途中で人の手が介入しなければいけなくなります。
以上で準備が終わったので該当コードを見ていきます。
def text_to_speech(content, idx):
generator = token_generator.TokenGenerator("textToSpeech", "TEXT_TO_SPEECH_CLIENT_ID", "TEXT_TO_SPEECH_CLIENT_SECRET")
access_key = generator.get_access_token()
url = "https://us-central1-texttospeech.googleapis.com/v1beta1/text:synthesize"
header = {
"Authorization": f"Bearer {access_key}", # ここにアクセストークンを入れる
"Content-Type": "application/json; charset=utf-8"
}
payload = {
"audioConfig": {
"audioEncoding": "LINEAR16",
"effectsProfileId": [
"small-bluetooth-speaker-class-device"
],
"pitch": 0,
"speakingRate": 1
},
"input": {
"text": content # ここに音声化する文字列を入れる
},
"voice": {
"languageCode": "ja-JP",
"name": "ja-JP-Neural2-B"
}
}
res = requests.post(url, headers=header, json=payload)
with open(f'../data/audio/tmp/audio_{idx}.wav', "w+b") as f:
encode_string = res.json()["audioContent"]
decode_string = base64.b64decode(encode_string)
f.write(decode_string)
def concat_audio(contents, audio_input):
dir = '../data/audio/tmp'
for i in range(len(contents)):
if i == 0:
audio = AudioSegment.from_file(f'{dir}/audio_{i}.wav', "wav")
else:
audio += AudioSegment.from_file(f'{dir}/audio_{i}.wav', "wav")
audio.export(audio_input, format="mp3")
for f in os.listdir(dir):
os.remove(os.path.join(dir, f))
class TokenGenerator():
def __init__(self, target, client_id, client_secret):
with open(f"../data/token/{target}.txt") as f:
self.refresh_token = f.read()
self.access_token = ""
self.client_id = client_id
self.client_secret = client_secret
def get_access_token(self):
url = "https://www.googleapis.com/oauth2/v4/token"
payload = {
"client_secret": os.getenv(self.client_secret),
"grant_type": "refresh_token",
"refresh_token": self.refresh_token,
"client_id": os.getenv(self.client_id)
}
res = requests.post(url, json=payload)
return res.json()["access_token"]
ここで重要な点は2点です。
1つ目は、アクセストークンです。
先ほども少し述べましたが、Google APIは有効期限1時間のアクセストークンをヘッダーに渡してあげなければ通信を行うことができません。
そのため、毎日1回定期実行するとなると毎回新鮮なアクセストークンが必要となるわけです。
新鮮なアクセストークンを獲得するには、アクセストークンと同じタイミングで受け取ることができるリフレッシュトークンを使います。
実際には、上記のコードの get_access_token メソッドで https://www.googleapis.com/oauth2/v4/token というエンドポイントにリフレッシュトークンを渡してあげることで、新鮮なアクセストークンを獲得しています。
2つ目は、入力する文字列の分割です。
Text-to-Sepeechは、最大5,000バイトまでしか一度に音声化することができません。
今回の音声化したい文字列では、その制約を大幅に超過してしまうため、文字列を200文字ずつに分割しています。
なお、小分けに生成された音声データは concat_audio 関数で結合しています。
核の部分は pydub というライブラリを使用しています。
使い方は難しくなく、ただ足し合わせていくだけで結合できてしまいます。
詳しくはこちらを参照ください。
参考:https://future-architect.github.io/articles/20210312/
参考:https://qiita.com/hanzawak/items/7355142f884cb56a4d57
参考:https://cloud.google.com/text-to-speech/pricing?hl=ja
参考:https://qiita.com/hanzawak/items/7355142f884cb56a4d57
5. 音声ファイルを動画ファイルに変更
こちらはpythonコードでゴリゴリ書いていきます。
本記事の本質から乖離するので、簡単に説明します。
まず該当コードは以下のとおりです。
def create_video(audio_file, image_file, output_file):
if os.path.exists(output_file):
os.remove(output_file)
input_image = ffmpeg.input(image_file, r=10, loop=1)
input_audio = ffmpeg.input(audio_file)
output_ffmpeg = ffmpeg.output(
input_audio,
input_image,
output_file,
ac=1,
shortest=None,
vcodec="libx264",
pix_fmt="yuv420p",
acodec='aac'
)
ffmpeg.run(output_ffmpeg)
return
画像データと音声データを入力にします。
この時に画像データの input で loop=1 とすることで、画像を1秒間でループし続ける動画として入力することができます。
これで、音声データと画像から動画を作成することができました。
参考:https://qiita.com/studio_haneya/items/a2a6664c155cfa90ddcf
6. Google Drive に動画をアップする
現状はPC上にしかなく、通勤中に携帯で見ることができないのでローカルなGoogle Driveにアップします。
基本的な構造は Text-to-Speechとあまり変わりはありません。
早速説明に移ります。
まず該当コードです。
def get_auth():
api_service_name = "drive"
api_version = "v3"
# >>> 初回の token 取得用 >>>
# client_secrets_file = "../client_secrets.json"
# flow = google_auth_oauthlib.flow.InstalledAppFlow.from_client_secrets_file(
# client_secrets_file, scopes, redirect_uri='http://localhost')
# credentials = flow.run_local_server()
# print(credentials)
# print(credentials.to_json())
# <<< 初回の token 取得用 <<<
# >>> 2回目以降の token 取得用 >>>
with open("../data/token/drive.json") as f:
pre_token = json.loads(f.read())
pre_token['client_id'] = os.getenv('DRIVE_CLIENT_ID')
pre_token['client_secret'] = os.getenv('DRIVE_CLIENT_SECRET')
credentials = google.oauth2.credentials.Credentials(
token=None,
**pre_token
)
http_request = google.auth.transport.requests.Request()
credentials.refresh(http_request)
next_token = json.loads(credentials.to_json())
del next_token["token"]
del next_token["client_id"]
del next_token["client_secret"]
with open("../data/token/drive.json", 'w') as f:
json.dump(next_token, f, indent=2)
# <<< 2回目以降の token 取得用 <<<
drive = googleapiclient.discovery.build(
api_service_name, api_version, credentials=credentials)
return drive
def upload(drive):
file_metadata = {
'name': f"{get_datetime.get_date()}のITニュース",
'parents': ['自分があげたいgoogle Drive のフォルダID']
}
media = MediaFileUpload(
'../data/video/video.mp4',
mimetype='video/mp4',
resumable=True
)
file = drive.files().create(
body=file_metadata, media_body=media, fields='id'
).execute()
print ('Folder ID: %s' % file.get('id'))
Text-to-Speech と異なる点は google.oath.2.credentials を使う点です。
Google Drive API は、curlコマンドはない(?)のでheaderのAuthorizationで認証をすることができません。
そのため、認証情報を持ったjsonファイルのリフレッシュトークンを使います。
初めてコードを実行する際は、コメントアウトしている部分のコメントを解除し、 2回目以降のtoken取得用 という部分をコメントアウトして下さい。
そうすると、新鮮なアクセストークンをまた作ることができるようになります。
次に、アップロード先のGooGle DriveのフォルダIDを入れてあげることで、先ほどまでで作成してきた、動画をファイルにアップロードすることができます。
参考:https://note.com/optim/n/n47e1150892be
結論
以外と簡単にAPIを活用して動画を作成することができました。
これで圧倒的な情報収集が実現しました!
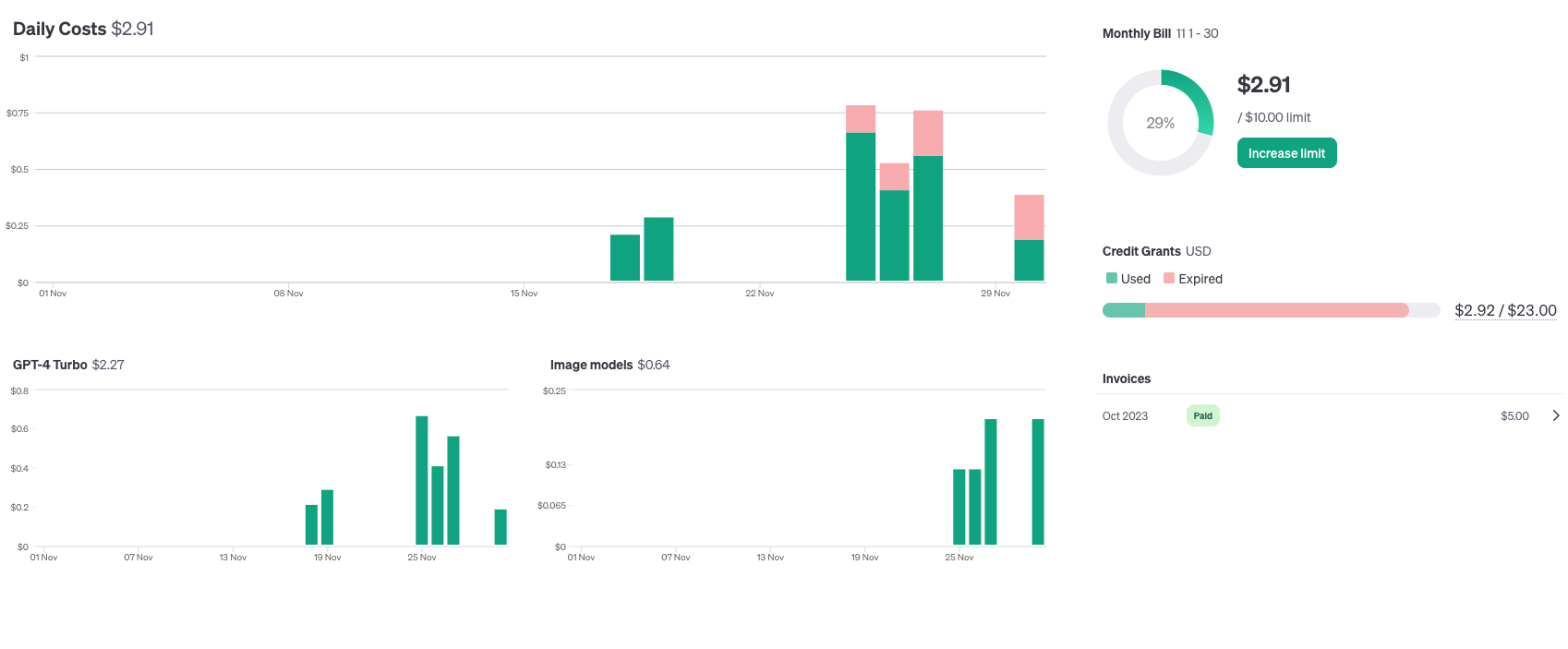
ちなみに今回のコードを作成する過程で発生したOpenAIの料金は以下のとおりです。
$2.91なので430円ですね。。
実行するごとにお金がかかっていくのはヒリつきがあってよかったですね笑