組合せ最適化プログラムの可読性について
Discussion
Closed
解決したいこと
pythonのpandasとpulpを独学で学んで作ったプログラムを、職場のシフト表作成で使うことになったのですが、将来的な引き継ぎも考えると、可読性やメンテナンス性に優れたものでないとマズい気がしています。
一応、思った通りの動作はしているのですが、可読性については自分で客観的な評価ができないため、実際に作ったプログラムに対し、可読性・処理などについてアドバイスをいただきたくて投稿しました。
基本仕様と元データ
基本的にやりたいことは、
シフト表の中身を、
「労基法に引っかからないようにしつつ」、
「勤務者の希望も聞きつつ」、
「人件費的にもいい感じに埋めたい」。
という事になります。
表1:勤務希望表
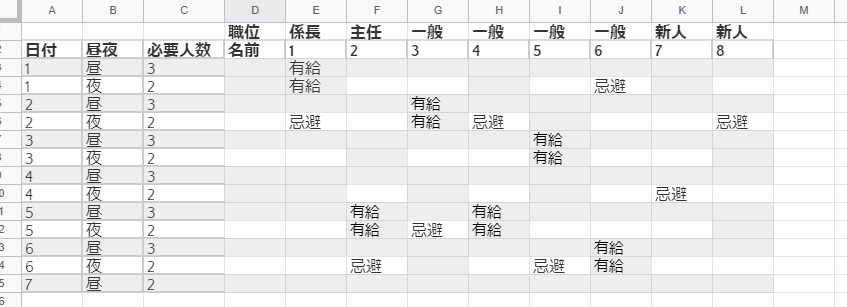
現状はこのような勤務希望表を元に、管理職が上手いこと必要人数を埋めつつ、
いい感じになるようにシフトを埋めています。
今回作ったプログラムは、
基本仕様を抑えつつ、最終的に表2のような組み合わせを自動出力するものとして作りました。
表2 勤務シフト表
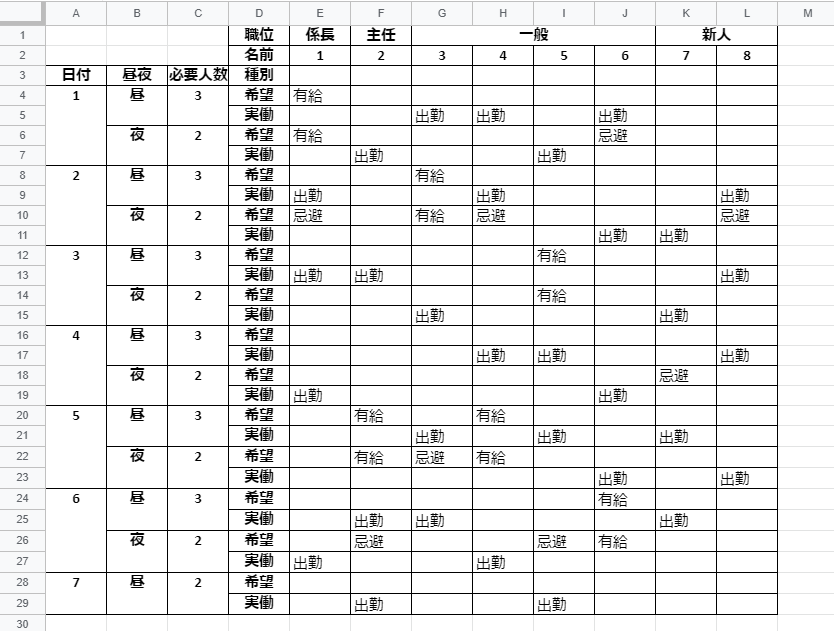
pulpを構築する上での制約条件と目的関数は全てプログラム内コメントとして記述してあります。
使用環境
・google colaboratory
pulpさえインストールしておけば、後は下記のソースコード丸コピで動くことを確認しています。
以上、どうぞよろしくお願いいたします。
ソースコードとコメント
import openpyxl
import pandas as pd
import numpy as np
import pulp
dict_raw = {('係長', 1): {(1, '昼', 3): '有給', (1, '夜', 2): '有給', (2, '昼', 3): '', (2, '夜', 2): '忌避', (3, '昼', 3): '', (3, '夜', 2): '', (4, '昼', 3): '', (4, '夜', 2): '',(5, '昼', 3): '', (5, '夜', 2): '', (6, '昼', 3): '', (6, '夜', 2): '', (7, '昼', 2): ''},
('主任', 2): {(1, '昼', 3): '', (1, '夜', 2): '', (2, '昼', 3): '',(2, '夜', 2): '', (3, '昼', 3): '', (3, '夜', 2): '', (4, '昼', 3): '', (4, '夜', 2): '', (5, '昼', 3): '有給', (5, '夜', 2): '有給', (6, '昼', 3): '',(6, '夜', 2): '忌避', (7, '昼', 2): ''},
('一般', 3): {(1, '昼', 3): '', (1, '夜', 2): '', (2, '昼', 3): '有給', (2, '夜', 2): '有給', (3, '昼', 3): '',(3, '夜', 2): '', (4, '昼', 3): '', (4, '夜', 2): '', (5, '昼', 3): '', (5, '夜', 2): '忌避', (6, '昼', 3): '', (6, '夜', 2): '', (7, '昼', 2): ''},
('一般', 4): {(1, '昼', 3): '', (1, '夜', 2): '', (2, '昼', 3): '', (2, '夜', 2): '忌避', (3, '昼', 3): '', (3, '夜', 2): '', (4, '昼', 3): '', (4, '夜', 2): '',(5, '昼', 3): '有給', (5, '夜', 2): '有給', (6, '昼', 3): '', (6, '夜', 2): '', (7, '昼', 2): ''},
('一般', 5): {(1, '昼', 3): '', (1, '夜', 2): '', (2, '昼', 3): '',(2, '夜', 2): '', (3, '昼', 3): '有給', (3, '夜', 2): '有給', (4, '昼', 3): '', (4, '夜', 2): '', (5, '昼', 3): '', (5, '夜', 2): '', (6, '昼', 3): '', (6, '夜', 2): '忌避',(7, '昼', 2): ''},
('一般', 6): {(1, '昼', 3): '', (1, '夜', 2): '忌避', (2, '昼', 3): '', (2, '夜', 2): '', (3, '昼', 3): '', (3, '夜', 2): '', (4, '昼', 3): '',(4, '夜', 2): '', (5, '昼', 3): '', (5, '夜', 2): '', (6, '昼', 3): '有給', (6, '夜', 2): '有給', (7, '昼', 2): ''},
('新人', 7): {(1, '昼', 3): '', (1, '夜', 2): '',(2, '昼', 3): '', (2, '夜', 2): '', (3, '昼', 3): '', (3, '夜', 2): '', (4, '昼', 3): '', (4, '夜', 2): '忌避', (5, '昼', 3): '', (5, '夜', 2): '', (6, '昼', 3): '',(6, '夜', 2): '', (7, '昼', 2): ''},
('新人', 8): {(1, '昼', 3): '', (1, '夜', 2): '', (2, '昼', 3): '', (2, '夜', 2): '忌避', (3, '昼', 3): '', (3, '夜', 2): '',(4, '昼', 3): '', (4, '夜', 2): '', (5, '昼', 3): '', (5, '夜', 2): '', (6, '昼', 3): '', (6, '夜', 2): '', (7, '昼', 2): ''}}
df_raw=pd.DataFrame.from_dict(dict_raw, orient="columns").rename_axis(["date","action","needs"])
df_raw.columns.set_names(["position","member"],inplace=True)
#dataframeの値を数値変換する前にコピーを取っておく(後で使う)
df_origin=df_raw.copy()
df_raw.rename(index={"昼":0,"夜":1},level=1,inplace=True)
df_raw.rename(columns={"係長":1,"主任":2,"一般":0,"新人":3},level=0,inplace=True)
df_raw.replace({np.NaN:0,"忌避":1,"有給":2},inplace=True)
#df_rawのindexとcolumnをリスト化しておく
#list_dtnはdate,time,needs list_pmはposition,memberを格納
list_dtn = df_raw.index.to_list()
list_pm = df_raw.columns.to_list()
#問題の定義
ShiftScheduling = pulp.LpProblem("ShiftScheduling", pulp.LpMinimize)
#変数宣言
#まずはx[p,m,d,t]で全パターンの0-1変数を作成する。x[p,m,d,t]=1ならば出勤を表す
#例:x[3,8,1,1]=1なら、新人(3)の8番が1日目の夜(1)に出勤したことになる。
x = {}
for p,m in list_pm:
for d,t,n in list_dtn:
x[p,m,d,t] = pulp.LpVariable("x({:},{:},{:},{:})".format(p,m,d,t), 0, 1, pulp.LpInteger)
#目的関数1 全員の出勤の合計値が小さい方が良い=全変数の総和が小さい方が良い
obj1= pulp.lpSum(x)
#目的関数2 夜勤忌避の希望が通る方が良い
#まず、夜勤忌避希望になっているp,m,d,tの組み合わせを全て取得し、list_yakinに格納する
list_yakin=[]
for p,m in list_pm:
df_yakin = df_raw[df_raw.loc[:,(p,m)]==1]
for i in range(len(df_yakin)):
dt_yakin = df_yakin.index
list_temp = [p,m,dt_yakin[i][0],dt_yakin[i][1]]
list_yakin.append(list_temp)
#list_yakinを元に「夜勤忌避のときの変数の総和」を取り、これを目的関数にする
obj2 = pulp.lpSum(x[p,m,d,t] for p,m,d,t in list_yakin)
#目的関数3 有給の希望が通る方が良い
#セルの値=2とするだけで、obj2と全く同じ
list_yukyu=[]
for p,m in list_pm:
df_yukyu = df_raw[df_raw.loc[:,(p,m)]==2]
for i in range(len(df_yukyu)):
dt_yukyu = df_yukyu.index
list_temp = [p,m,dt_yukyu[i][0],dt_yukyu[i][1]]
list_yukyu.append(list_temp)
obj3 = pulp.lpSum(x[p,m,d,t] for p,m,d,t in list_yukyu)
#目的関数4 勤務者間の労働回数はなるべく近いほうが良い。
#「最多出勤回数-最少出勤回数」を用いる。
#ただ、今回は最低出勤回数が3と決まっているので、最大値だけを最小化してもらえば、同じことになるはずである
obj4 = pulp.LpVariable("workcount",lowBound=0)
#目的関数の定義
ShiftScheduling += obj1 + obj2 +obj3 + obj4
#制約条件
#制約条件1:全員必ず3回以上出勤
#制約条件4:勤務回数の偏りを減らす(勤務回数の最大値がobj4に格納されるようにする)
for p,m in list_pm:
ShiftScheduling += pulp.lpSum(x[p,m,d,t] for d,t,n in list_dtn) >= 3
ShiftScheduling += pulp.lpSum(x[p,m,d,t] for d,t,n in list_dtn) <= obj4
#制約条件2:全シフトで必要人数以上出勤
#必要人数のデータはlist_dtnのnに入っているので、(各シフトの出勤回数)>=nとすれば良い
for d,t,n in list_dtn:
ShiftScheduling += pulp.lpSum(x[p,m,d,t] for p,m in list_pm) >= n
#制約条件3:連続出勤不可
#まず、1日目昼~6日目夜のリストと、1日目夜~7日目昼のリストを用意する
list_dt1 = list_dtn[:-1]
list_dt2 = list_dtn[1:]
for i in range(len(list_dt1)):
list_dt1[i]=list_dt1[i]+list_dt2[i]
#list_dt1には、「1日目昼のdate,time,needs,1日目夜のdate,time,needs」「1日目夜のdtn,2日目昼のdtn」・・・と格納される
for p,m in list_pm:
for d1,t1,n1,d2,t2,n2 in list_dt1:
ShiftScheduling += x[p,m, d1, t1]+x[p,m,d2,t2] <=1
#隣り合うシフトのx[p,m,d,t]の和が2以上になってたら連続勤務になっていると分かる。
#よって、ここでは制約条件として和が1以下と設定する
#制約条件5:夜勤一回以上
#まずはt=1のときの組み合わせを夜勤の必要回数リストとして作成する
df_yakin_min = df_raw.groupby(["action"]).get_group(1)
list_yakin_min = df_yakin_min.index.to_list()
for p,m in list_pm:
ShiftScheduling += pulp.lpSum(x[p,m,d,t] for d,t,n in list_yakin_min) >=1
#各勤務者の夜勤回数の総和が1以上になるように制約条件を設定
#制約条件6:新人だけでシフトを埋めてはいけない
#制約条件に「>」は使えず、「>=」を使うしか無いため、各シフトの総和 >= 新人の総和+1 とする。
#まず新人の列だけを抜き取った専用リストを作る
df_newbe = df_raw.groupby(["position"],axis=1).get_group(3)
list_newbe = df_newbe.columns.to_list()
for d,t,n in list_dtn:
ShiftScheduling += pulp.lpSum(x[p,m,d,t] for p,m in list_pm) >= pulp.lpSum(x[p,m,d,t] for p,m in list_newbe)+1
#各シフトの勤務回数 >= 新人の勤務回数 + 1
#出力
results = ShiftScheduling.solve()
print("optimality = {:}, target value = {:}".format(pulp.LpStatus[results], pulp.value(ShiftScheduling.objective)))
#opitmalと出ればOK。
#target value は全勤務回数+有給希望を無視した回数+夜勤忌避を無視した回数+勤務者の中の最多勤務回数を示す。
#target value の理論上最低値はこの設定だと32+0+0+4=36
#解いた結果を入れるためのdataframeを準備(indexなどは数値化されたもの)
df_results=df_raw.copy()
#x[p,m,d,t]の中身を辞書型で全て取り出す
dict_x = ShiftScheduling.variablesDict()
for d,t,n in list_dtn:
for p,m in list_pm:
keys_pmda = "x({},{},{},{})".format(p,m,d,t)
values_pmda=dict_x[keys_pmda]
r =pulp.value(values_pmda)
df_results.at[(d,t,n),(p,m)]=r
#df_results の各セルに、対応するx[p,m,d,t]の値を代入する
df_results.rename(index={0:"昼",1:"夜"},level=1,inplace=True)
df_results.rename(columns={1:"係長",2:"主任",0:"一般",3:"新人"},level=0,inplace=True)
df_results.replace({0:"",1:"出勤"},inplace=True)
df_results.index.set_names(["日付","昼夜","必要人数"],inplace=True)
df_results.columns.set_names(["職位","名前"],inplace=True)
#出力前に数値化していたindexやcolumnなどを文字列に戻す
#この後、希望と実態を併記して出力するため、indexに「種別」欄を1列増やす
df_results["種別"]="実働"
df_results.set_index("種別",inplace=True,append=True)
#最初にコピーしておいたdataframeを呼び出し、こちらもindex「種別」を追加。
df_origin.index.set_names(["日付","昼夜","必要人数"],inplace=True)
df_origin.columns.set_names(["職位","名前"],inplace=True)
df_origin.replace(np.nan,"",inplace=True)
df_origin["種別"]="希望"
df_origin.set_index("種別",inplace=True,append=True)
#df_resultsとdf_originを結合した後、いい感じに並べ替えして出力
df_results = df_results.append(df_origin)
df_results = df_results.sort_index(level=[0,1,3],ascending=[1,0,0])
print(df_results)
0 likes