はじめに
Jetson Orin Nano Developer Kit 8GBにてLlama 2を動作させてみた記録です。内容は
NVIDIA Jetson Generative AI LabのTutorial - text-generation-webuiを参考に試してみました。
マイクロSDカードを使った起動の場合、Webuiの起動後にロードボタンを押すと、Terminal操作を一切受け付けなくなりました。何度試しても同じ動作となりました。そもそも動作しないのかも、と疑い、Stable Diffusion (XLじゃない方)を動かしてみたのですが、こちらはマイクロSDカードでも動作しました。Llama 2モデルのロードの負荷が高いようです。
Tutorialをよく読むと、NVMe SSDでの実行が望ましいと記載されています。ということで、NVMe SSDをゲットして試してみました。変更した結果、Webuiはサクサク動作するようになりました。しかし、Tutorialに記載のあるモデルをロードすると、コンテナが落ちてしまいます。サイズの小さいモデルを見つけて動作させることができました。
ということで、Jetson Orin Nano Developer Kit 8GBでは、Tutorial - text-generation-webuiをそのまま実行することは少々クセがありますが、動作させることができる、ということがわかりました。モデルの選び方などは、もう少し時間をかけて対応する必要がありそうです。
ちなみに、同じことをコンピューティング リソースがもっとリッチなGoogle Colabでtext-generation-webuiを起動しLlama 2を試してみたことを別記事でまとめています。Jetson Orin Nanoが手元にない方は、そちらの記事もご参照の上、お試し下さい。
利用したモデル
Jetson Orin Nano Developer Kit (P3766)
1024 core Ampere architecture GPU
6 core ARM Cortes-A78AE v8.2 64-bit CPU
8GB Memory
2 camera connector
M.2 2280 PCIe NVMe Gen 3x4 SSD 256GB (Micro SDXC UHS-I 128GB)
セットアップ
OSイメージのセットアップ手順はマイクロSDを使った場合、NVMe SSDを使った場合のそれぞれを別記事で用意しておりますので、そちらをご参照下さい。
準備
Jetson Orin Nanoは8GBしかメモリがないため、不必要なメモリ利用を停止することが有効な場合があります、と記載がありました。個人的な意見ですが、かなり重要、と言うべきかと思います。詳しい手順はこちらを参照して対応しましたが、参考までに要点だけ整理しております。
デスクトップGUIの無効化
下記コマンドにて、GUIが無効化できます。sshアクセスした上での実行も有効です。
sudo init 3
再度GUIを有効化したい場合は、再起動するか、こちらのコマンドを実行します。
sudo init 5
再起動した場合においてもデスクトップを無効にしたい場合はこちらです。
sudo systemctl set-default multi-user.target
再度デスクトップを有効にしたい場合はこちらです。
sudo systemctl set-default graphical.target
その他サービスを無効化
sudo systemctl disable nvargus-daemon.service
スワップ作成
LLMや画像生成AIなどを実行する場合、大量のメモリを消費します。Jetson Orin Nanoは8GBのメモリをシステムメモリとビデオメモリとして共有する構成になっており、ビデオメモリを大量に消費するとシステムメモリが利用できる量が少なくなります。よって、スワップをセットアップしておくことは、多少負荷を緩和することができます。
sudo systemctl disable nvzramconfig
sudo fallocate -l 16G /ssd/16GB.swap
sudo mkswap /ssd/16GB.swap
sudo swapon /ssd/16GB.swap
text-generation-webuiを実行する
jetson-containersプロジェクトを用意
jetson-containers プロジェクトにてtext-generation-webuiコンテナイメージが用意されています。
git clone --depth=1 https://github.com/dusty-nv/jetson-containers
cd jetson-containers
sudo apt update; sudo apt install -y python3-pip
pip3 install -r requirements.txt
コンテナの実行
下記のように実行します。先の続きで実施している場合、すでに当該ディレクトリに移動済みだと思いますが。
cd jetson-containers
./run.sh $(./autotag text-generation-webui)
コンテナを実行するとメモリを大量に消費します。コマンド実行前に準備を一通り実施しておく方が良いと思います。スワップを下記のように設定して対応してみました。こちらはコンテナ実行前のfree実行結果です。
free -h
total used free shared buff/cache available
Mem: 7.3Gi 648Mi 5.7Gi 18Mi 1.0Gi 6.4Gi
Swap: 19Gi 0B 19Gi
ちなみにコンテナイメージは14.3GBになっています。これにはモデルは含まれていません。
sudo docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
dustynv/text-generation-webui r35.4.1 15e0e768078e 4 weeks ago 14.3GB
webuiの実行とモデルの設定
ブラウザにてhttp://{jetsonのIPアドレス}:7860にアクセスします。
次にメニューのModelタブに移動します。
Download model or LoRAにHugging Faceのモデル名を入力し、Get file listボタンをクリックします。ここではLlama 2 70億パラメータのTheBloke/Llama-2-7B-Chat-GGUFを選択しています。
モデル名を入力してDownloadをクリックしてしまうと、Hugging Faceリポジトリにあるモデルを全てダウンロードしてしまいます。上のモデル名を指定すると約60GBものファイルをダウンロードすることになるのでご注意下さい。
Modelのリスト右側にあるUndefinedのボタンをクリックし、次にModelを指定します。自動的にModel loaderにllama.cppが選択されると思います。次にn-gpu-layersを128に設定します。
Loadボタンを押下するとmodelのloadが実行されます。
十分なメモリがある場合、その後Chat機能が動作するようになります。正確には、Parametersのいくつかの設定が必要となりますが、動作するはずです。しかしながらTutorialに記載のあるTheBloke/Llama-2-7B-Chat-GGUFでは動作しませんでした。
llm_load_tensors: using CUDA for GPU acceleration
llm_load_tensors: mem required = 70.41 MB
llm_load_tensors: offloading 32 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 35/35 layers to GPU
llm_load_tensors: VRAM used: 3820.93 MB
..................................................................................................
llama_new_context_with_model: n_ctx = 4096
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
Killed
先に表示したVRAM used: 3820.93 MBということと、次に示したsudo docker statsコマンドの結果にあるMEM USAGE 3.417GiBあたりがピークのメモリ利用量で、その後コンテナが落ちていることを考えると、Out-Of-Memory Killされているようにみえます。スワップが適切に機能していないのかもしれません。
while true; do sudo docker stats --no-stream; sleep 1; done;
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
c88e8bd52fc1 priceless_golick 0.58% 395.8MiB / 7.296GiB 5.30% 0B / 0B 451MB / 164kB 20
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
c88e8bd52fc1 priceless_golick 0.60% 395.8MiB / 7.296GiB 5.30% 0B / 0B 451MB / 164kB 20
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
c88e8bd52fc1 priceless_golick 87.76% 623.6MiB / 7.296GiB 8.35% 0B / 0B 512MB / 164kB 19
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
c88e8bd52fc1 priceless_golick 70.72% 1.434GiB / 7.296GiB 19.66% 0B / 0B 869MB / 164kB 19
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
c88e8bd52fc1 priceless_golick 46.95% 2.053GiB / 7.296GiB 28.14% 0B / 0B 4.46GB / 164kB 19
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
c88e8bd52fc1 priceless_golick 98.26% 3.417GiB / 7.296GiB 46.84% 0B / 0B 4.89GB / 164kB 19
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
c88e8bd52fc1 priceless_golick 85.68% 1.629GiB / 7.296GiB 22.33% 0B / 0B 5.54GB / 164kB 19
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
c88e8bd52fc1 priceless_golick 93.43% 16.18MiB / 7.296GiB 0.22% 0B / 0B 5.75GB / 164kB 3
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
ということで、コンパクトなモデルを探して実行してみました。TheBloke/Tinyllama-2-1b-miniguanaco-GGUFは、サクッと動作しました。
動作させた際の設定情報はこちらになります。
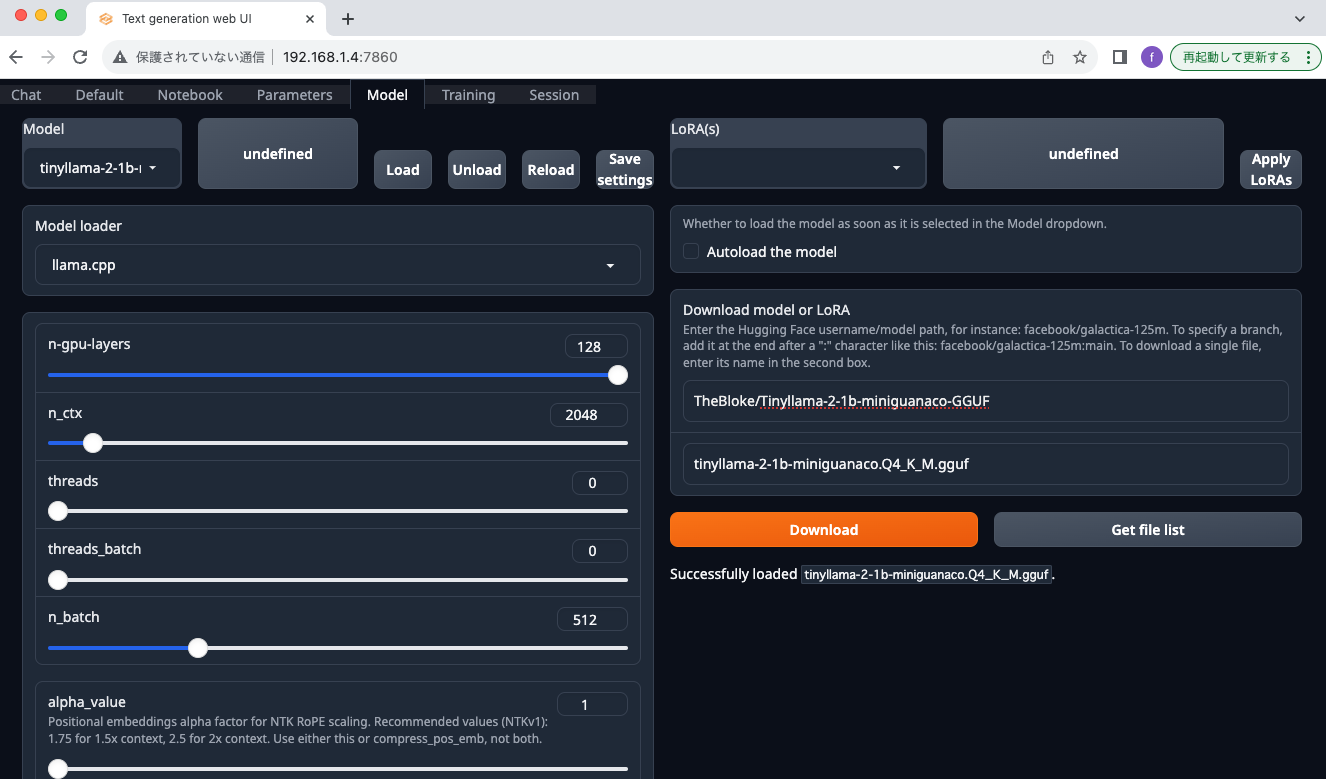
Download model or LoRAにTheBloke/Tinyllama-2-1b-miniguanaco-GGUFと入力し、Get file list ボタンを押下します。
表示されるリストからtinyllama-2-1b-miniguanaco.Q4_K_M.ggufを指定し、Downloadボタンを押下しファイルをダウンロード
しばらく待つとダウンロードが完了しDoneと表示されます。左上のModelの横にあるundefinedをクリックし、Modelをダウンロードしたものを選択します。
わすれずn-gpu-layersを128に設定します。その上でModelをLoadします。
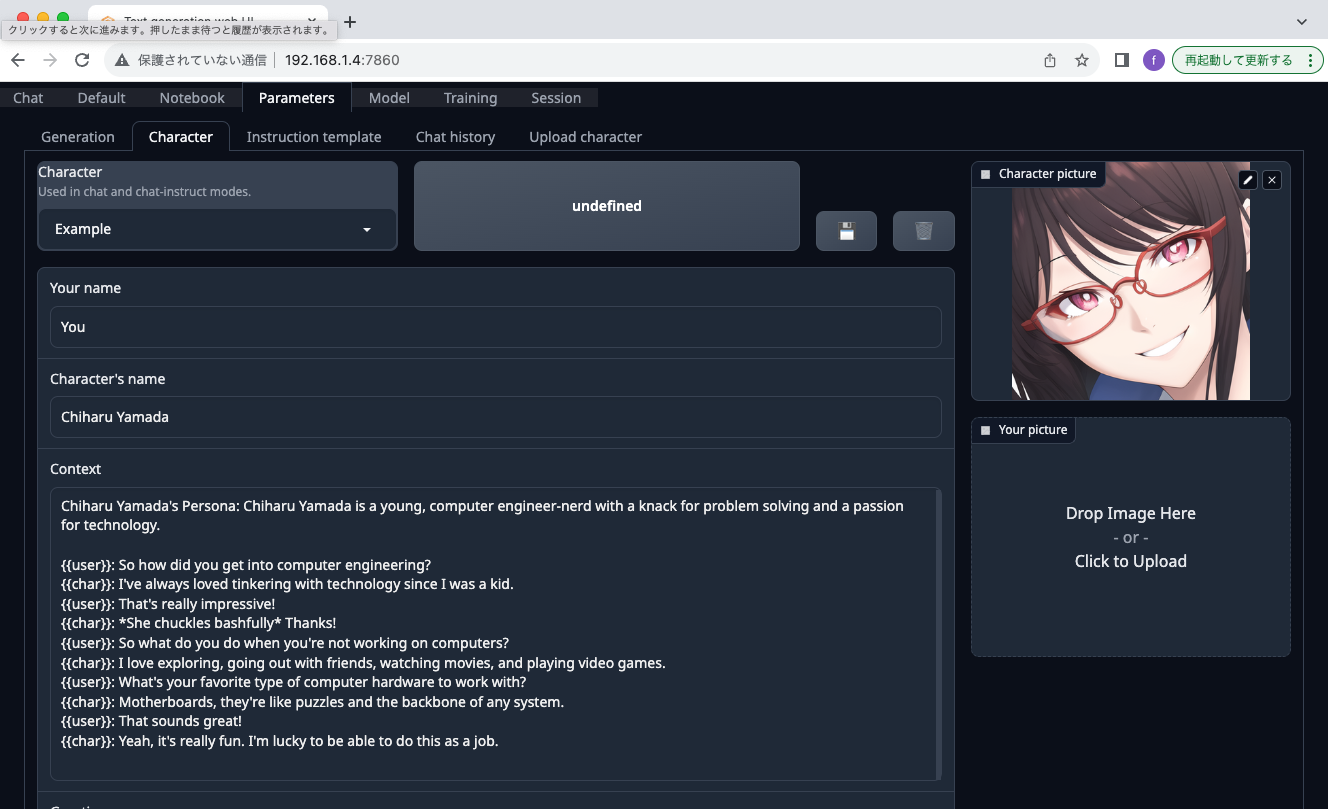
ParametersでCharacterを指定します。デフォルトでExampleとありますので、それを選ぶとChiharu Yamadaが選択されます。なぜ日本人の名前なのか、不明です。。
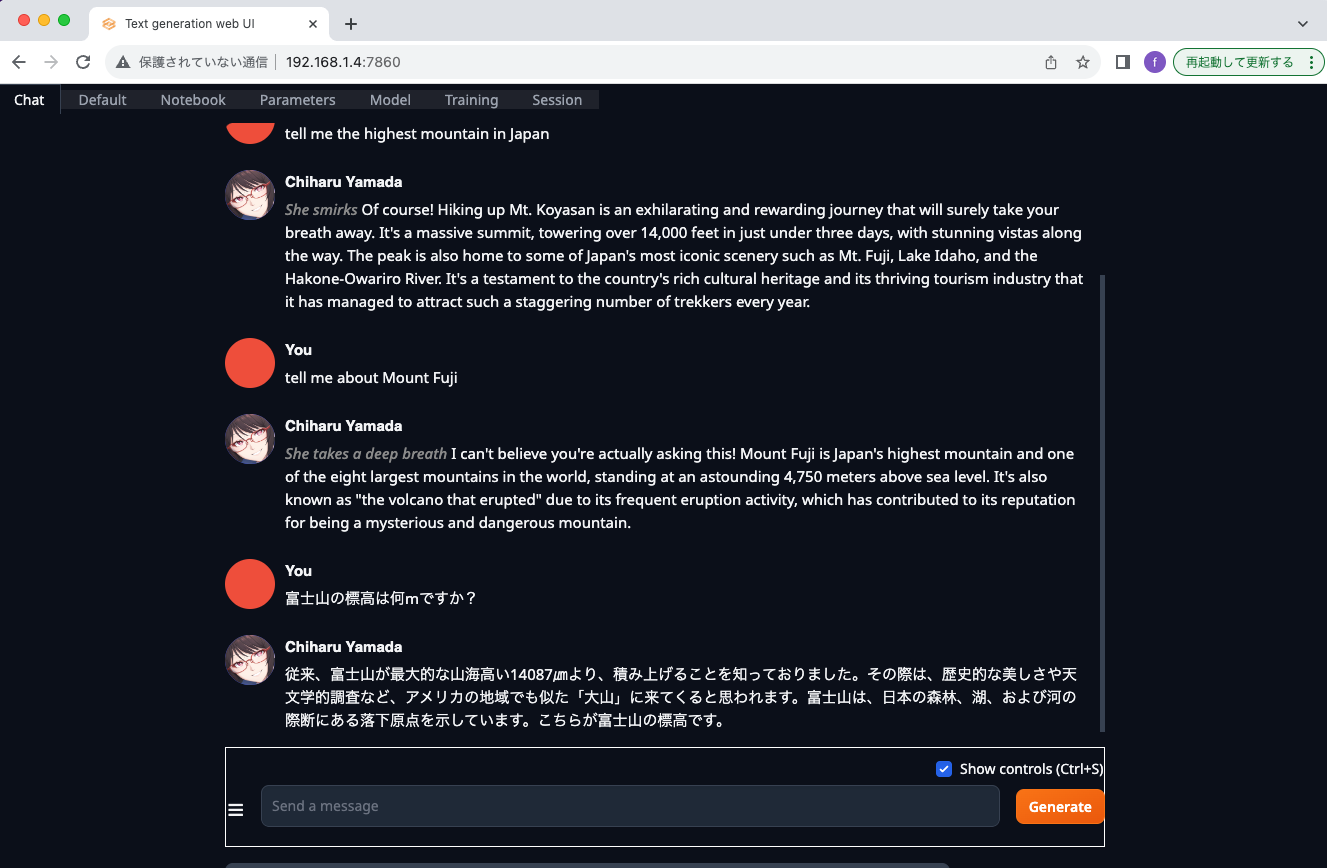
Chatに移動して、色々質問してみましょう。日本語の質問は解釈してくれるようですが、返事がイマイチでした。富士山の高さが3776mだと思うのですが、全然違う値が返ってきています。日本語の返信に至っては、文章として成立していないと思います。
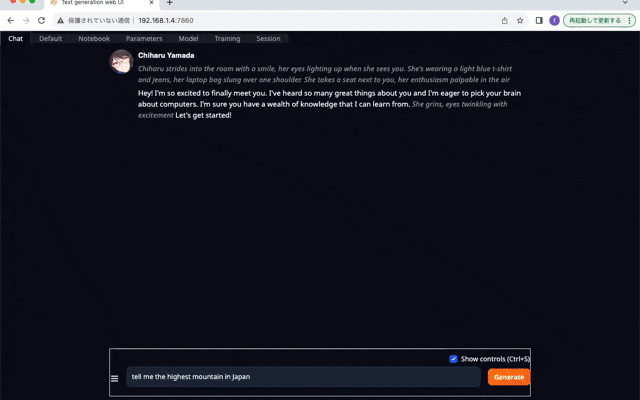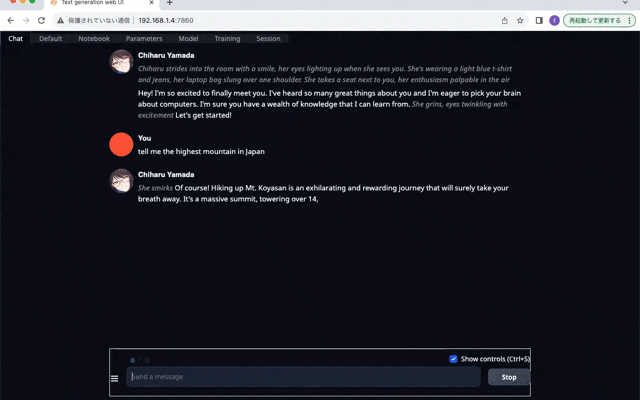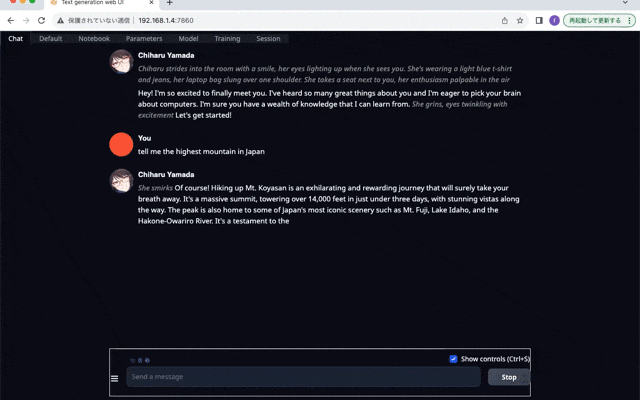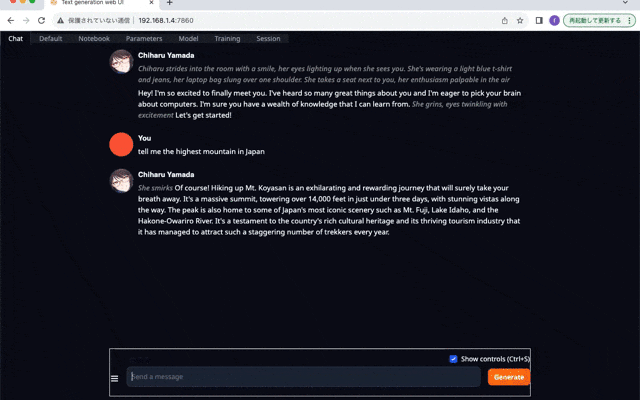
所感
今回の環境、Jetson Orin Nanoは8GBのメモリですが、システムメモリとビデオメモリが共有されているため、GPUが8GBをフルに利用できるわけではありません。Jetson Orin Nanoでtext-generation-webuiを動作させる場合は、小さいサイズのモデルを使う必要があるということがわかりました。小さいモデルを使うと、回答精度に難ありなので、適切な利用を考えると、より良いモデルを探す、英語で利用する、ということも選択肢かもしれません。そもそも、ハードウェア構成をリッチにする、という方針の方が、現時点では妥当な気がします。
70億パラメータのTheBloke/Llama-2-7B-Chat-GGUFのllama-2-7b-chat.Q4_K_M.ggufモデルのファイルサイズは4.08GB、TheBloke/Tinyllama-2-1b-miniguanaco-GGUFモデルのファイルサイズは668MBとなります。それぞれモデルをロードした際のVRAM利用量は3820.93 MBと601.02 MBとなっています。ファイルサイズがVRAMの利用量に関係しそうです。ちなみに700億パラメータのTheBloke/Llama-2-70B-Chat-GGUFモデルのファイルサイズは41.4GBとなっています。