はじめに
Llama 2をtext generation webuiで動作させてみた記録です。内容は
github.com/oobabooga/text-generation-webuiにあるGoogle Colab notebookを参考に試してみました。
Google Colabでは、無償アカウントであってもNVIDIA T4のGPUが使えるマシンが使えるサービスです。共有利用のようなので、スペック詳細は公開されていないようです。
利用したモデル
Google Colab 無償アカウントで利用可能なT4マシン
セットアップや準備
特にありません。github.com/oobabooga/text-generation-webuiの最下部あたりに説明にあるGoogle Colab notebookのリンクをクリックするとGoogle Colabに移動します。更新されることがありそうなので、ここにはリンクを張るのはやめておきます。
text-generation-webuiを実行する
Google Colabをオープンするとこの画面が表示されます。

1. Keep this tab alive to prevent Colab from disconnecting you
実行(Run cell)をクリックすると、しばらくすると音楽プレイヤーが表示されます。プレイヤーを再生状態にしておけば、Google Colabの接続が途切れることはない、ということかと思います。
本当にこの対応が必要なのか、よく考えてご利用頂く方が良さそうですね。。
2. Launch the web UI
次にLaunch the web UIを実行します。しばらく処理に時間がかかりますが、下記のように結果が表示されたら準備完了です。下記のリンクは公開時には無効にしてあります。
2023-11-12 13:25:39 INFO:Loading the extension "gallery"...
Running on local URL: http://127.0.0.1:7860
Running on public URL: https://a5a5b0eb94b2343ca1.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)
ブラウザよりアクセス
ブラウザを開き、先に示したRunning on public URL:にアクセスします。デフォルト設定で起動するとHugging Faceのturboderp/Mistral-7B-instruct-exl2がロードされた状態で起動します。

モデルの変更
デフォルト設定のまま起動した場合は、turboderp/Mistral-7B-instruct-exl2/4.0bpwが利用されています。
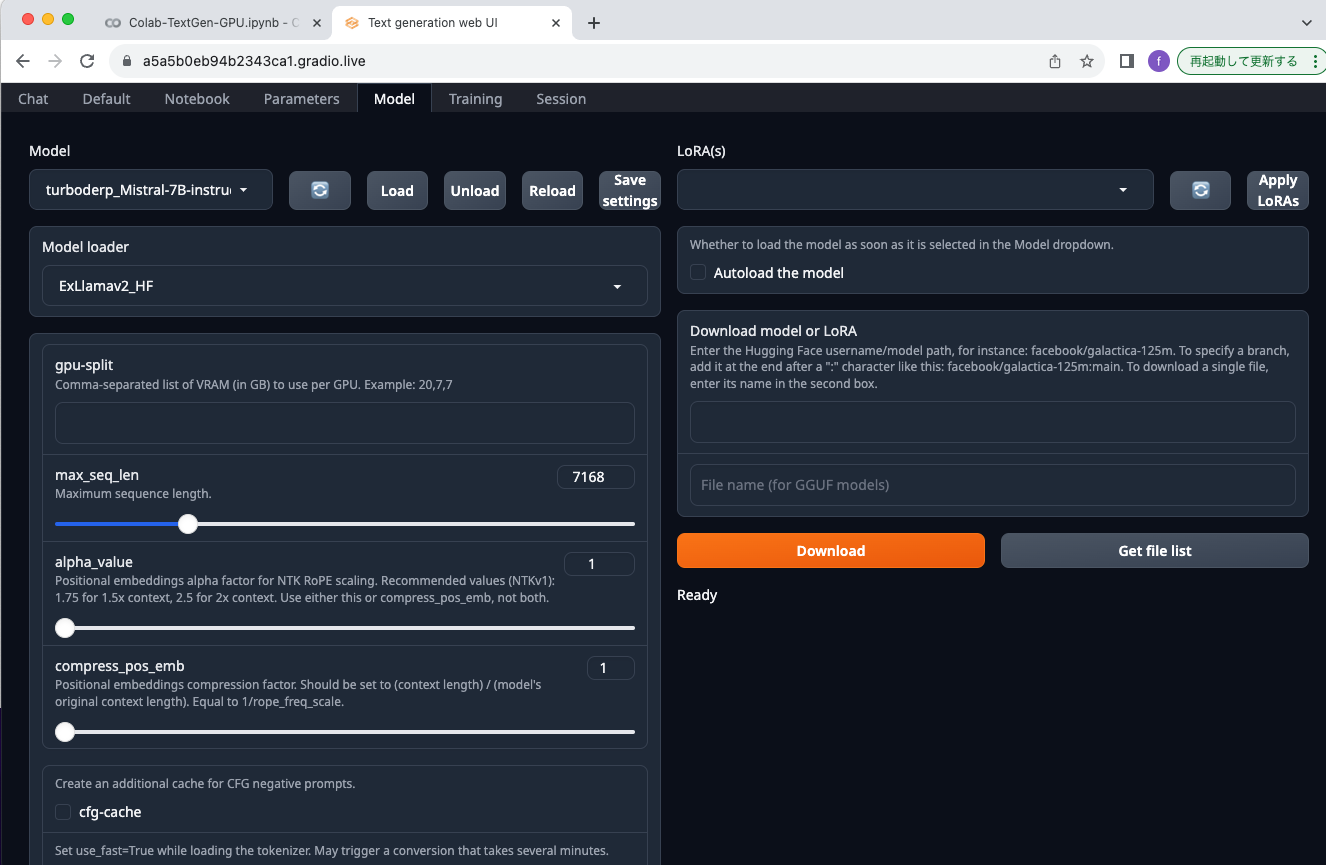
起動後でもモデルを変更することができます。
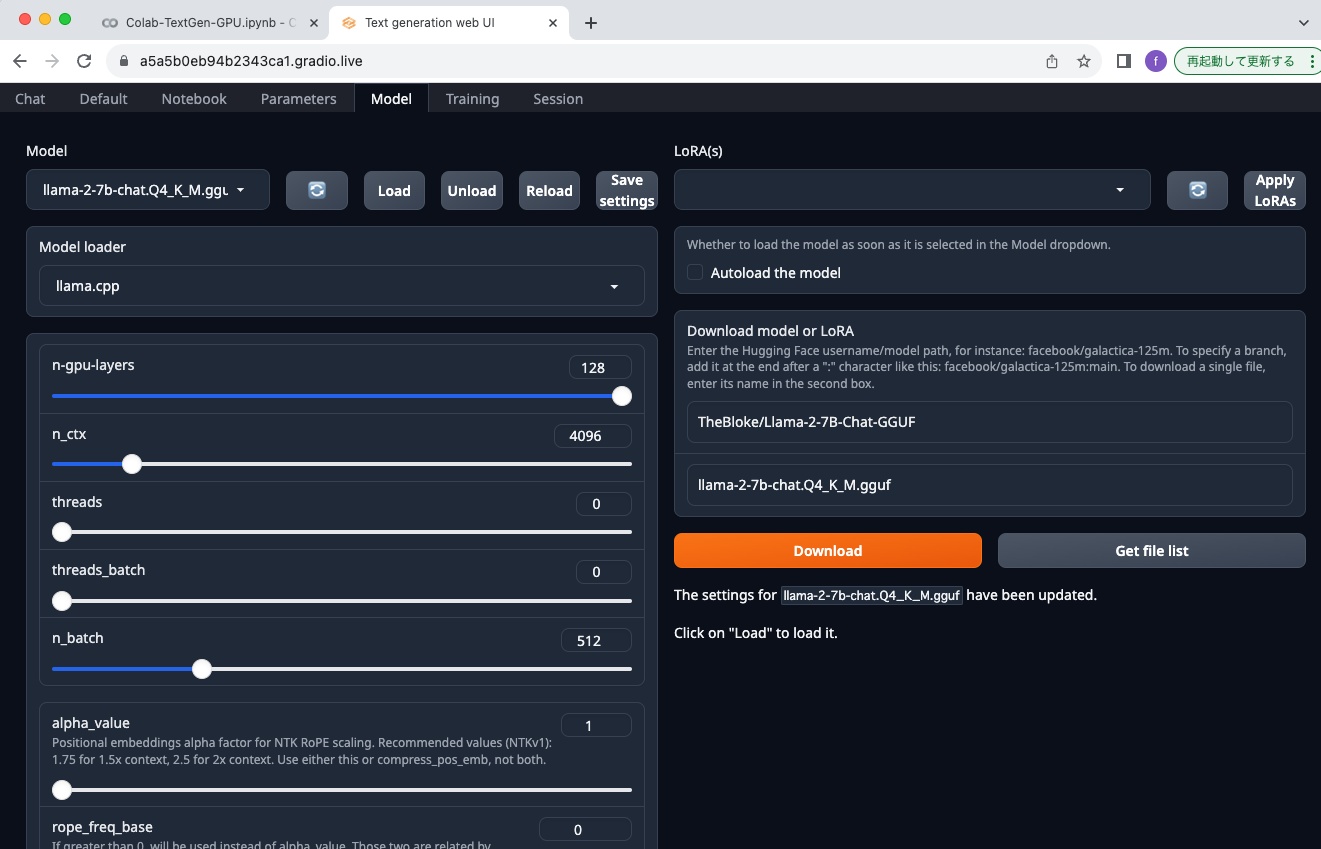
Modelメニューに移動し、右下のDownload model or LoRAの上の方のTheBloke/Llama-2-7B-Chat-GGUFと入力し、Get file listボタンをクリックすると、一覧が表示されます。ここでは、llama-2-7b-chat.Q4_K_M.ggufを選択してDownloadボタンをクリックしました。
次に左上にあるModelの項目のリロードアイコンボタンをクリックします。ボタンの左にあるModel選択のプルダウンメニューからllama-2-7b-chat.Q4_K_M.ggufを選択します。しばらくするとModel loaderが自動で選択されます。
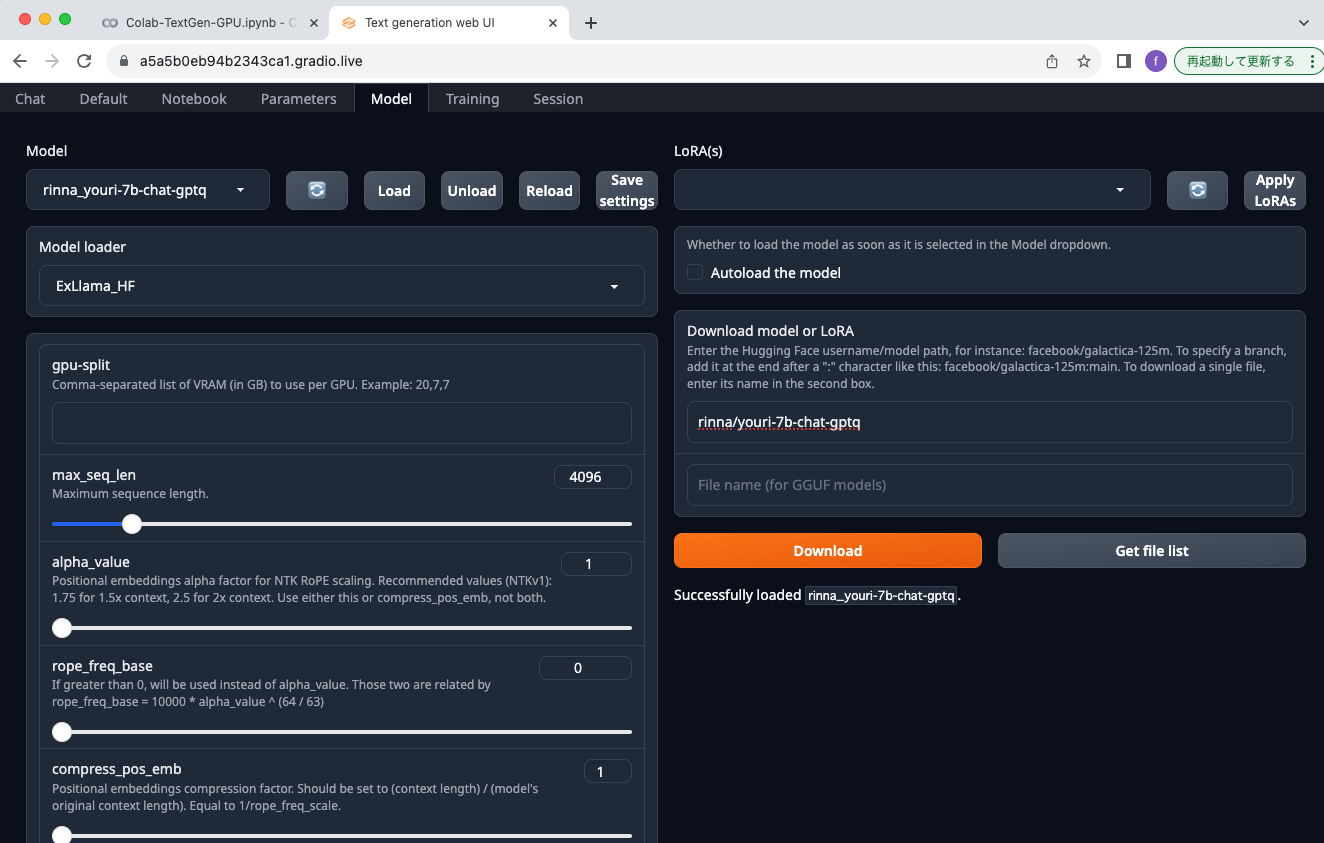
同じようにrinna株式会社が提供しているLlama 2の日本語継続事前学習モデルYouri 7Bも試してみました。こちらもサクッと起動します。
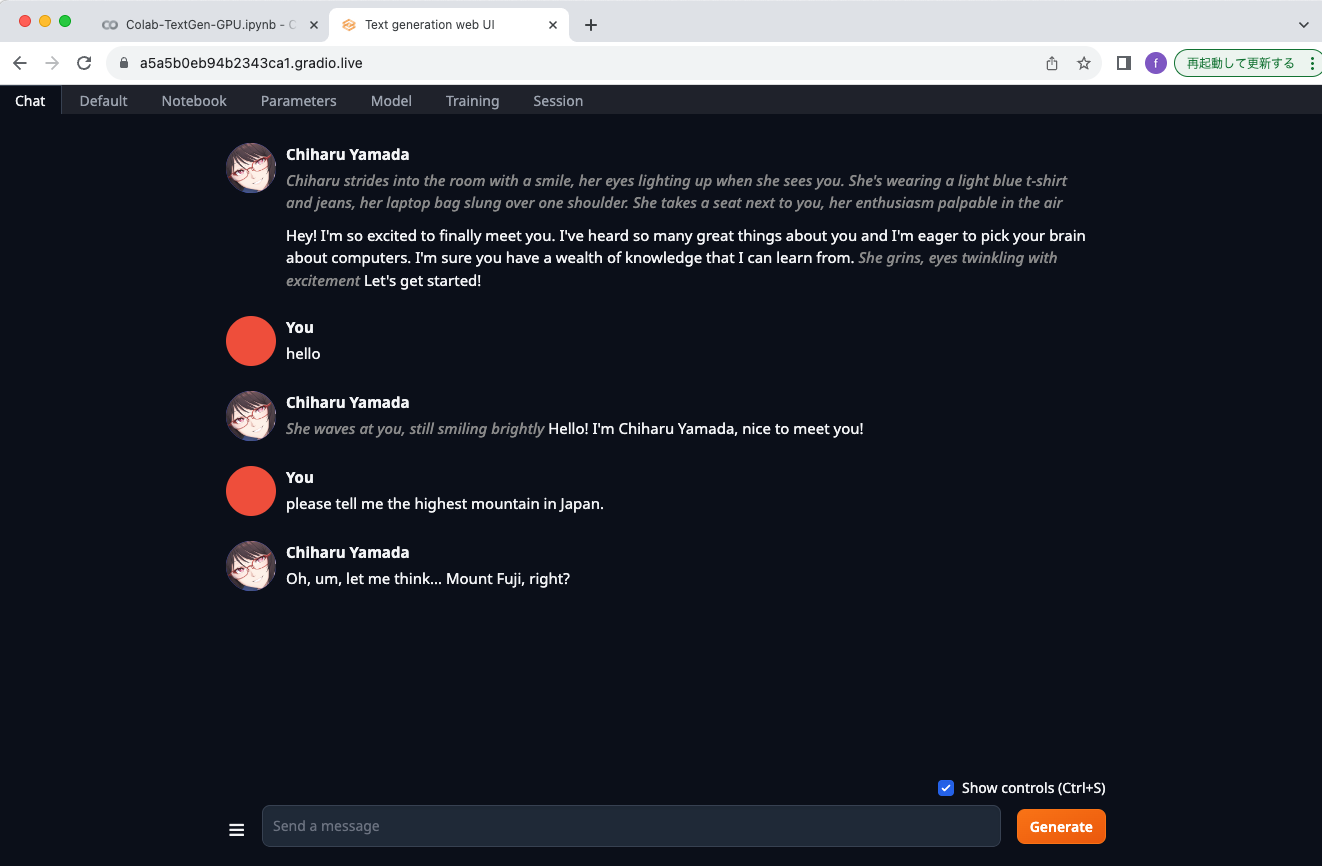
Characterの変更
ParametersメニューにあるCharacterタブに移動します。デフォルトではAssistantになっていますが、Exampleに変更すると、Chiharu Yamadaというキャラクターに変更になります。なぜ日本人の名前なのかはわかりません。。

キャラクターを変更したので、もちろんChat画面も変化します。
所感
Google Colab 無償版でもNVIDA T4 GPUを使えるので、様々なモデルの起動を試すことができました。Jetson Orin Nanoで対応しようとするとそれなりに苦労するので、様々なモデルを動かしてみたい、という意図であれば、こちらの方が断然効率的かと思います。