本記事はPostgreSQL on Kubernetes Advent Calendar 2018の15日目です。
昨日は「PostgreSQLコンテナの紹介」ということで、PostgreSQL on Kubernetesで利用しているコンテナイメージとそのカスタマイズ内容について記しました。
今日はPostgreSQL on Kubernetesの検証の続編として、「運用を考える」編の第一回をお送りしたいと思います。
TL;DR
- PostgreSQL on k8sの運用性の検証をしてみる。
- kubectl drainを使えば、DBクラスタの手動フェイルオーバ/フェイルバックが可能。
- drainコマンドを使った後はkubectl uncordonの実行を忘れずに。
「運用を考える」って何?
先日#7から#9の3回に分けて、「PostgreSQL on k8sで障害テスト」のケースをそれぞれ説明しました。
- DBノード障害
- ストレージノード障害
- ポッド障害
というのがその内容でしたが、これは単なる障害テストではなく、今回のPostgreSQL on Kubernetesの運用性を確かめる検証の一環でした。
結果をPGConf.Asia 2018で発表したのですが、下表の4つの観点で検証をしています。
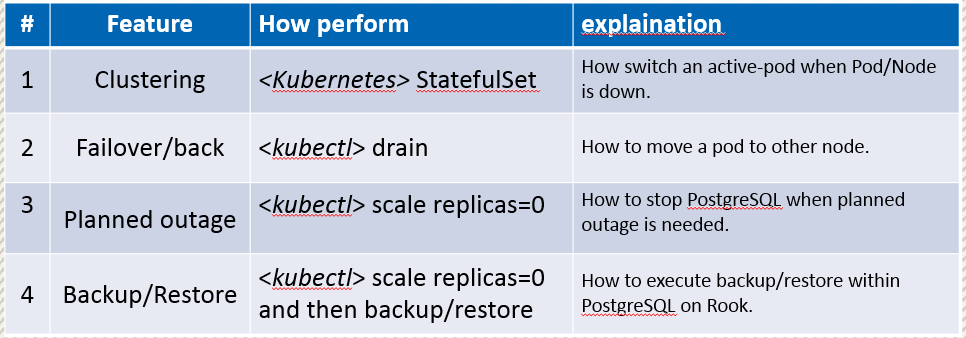
※詳細はこちらにスライドがあります。
DBクラスタとして正しく稼動してサービスを復旧・継続できるかが**#1**のClusteringで、先ほどの各ノードの障害として検証した内容です。
そして続編として、クラスタでは運用として必要なフェイルオーバ/フェイルバックが**#2**、DBを計画的に停止する際の運用が**#3**、バックアップとリストア手順を確認するのが**#4**となっています。
フェイルオーバ/フェイルバック
そして、今回は上の表の#2フェイルオーバ、フェイルバックの運用手順とその検証結果を共有します。具体的にはkubectl drain コマンドを使ってみました。
実現したいこと
この検証で確認したいのは下図の通りです。
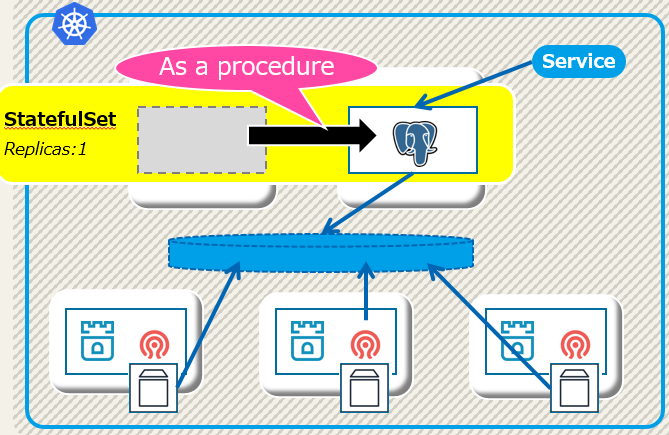
ノード障害時のような自動フェイルオーバではなく、手動操作によって、ソースのサーバからターゲットにPostgreSQLインスタンスを移動させることが目的です。
検証結果
まず、現状のノードとポッドの稼動状況を確認します。
$ kubectl get node
NAME STATUS ROLES AGE VERSION
ip-172-31-15-204 Ready worker 15d v1.10.5
ip-172-31-3-135 Ready worker 15d v1.10.5
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pg-rook-sf-0 1/1 Running 0 20h 10.42.6.22 ip-172-31-3-135
このとき、ポッド:pg-rook-sf-0はノード:ip-172-31-3-135で稼動していますね。
では、drainしてみましょう。
$ kubectl drain ip-172-31-3-135 --force --ignore-daemonsets
node/ip-172-31-3-135 cordoned
WARNING: Ignoring DaemonSet-managed pods: cattle-node-agent-5rlrr, nginx-ingress-controller-w5xt4, canal-dlg6x, rook-ceph-agent-2l9cp, rook-discover-8hl2m
pod/pg-rook-sf-0
pod/kube-dns-5ccb66df65-d2p5r
オプションとしてignore-daemonsetsを付けているのでデーモンセットは対象外となっていますが、pg-rook-sf-0が退避されました。結果を確認してみましょう。
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pg-rook-sf-0 1/1 Running 0 1m 10.42.5.55 ip-172-31-15-204
ポッドが稼動しているノードが変わりましたね。これでフェイルオーバ完了です。
注意点
上記のdrainコマンドで移動させた後に一点注意すべきことがあります。
- drainコマンドの対象となったノードはステータスがSchedulingDisabledとなるため、kubectl uncordonの実行が必要。
先ほどの検証を行った直後のノードの状況を確認すると以下のようになっています。
$ kubectl get node
NAME STATUS ROLES AGE VERSION
ip-172-31-15-204 Ready worker 15d v1.10.5
ip-172-31-3-135 Ready,SchedulingDisabled worker 15d v1.10.5
このSchedulingDisabledを外しておかないと、そのノードにポッドを戻すことは出来ませんので、フェイルバックが出来ません。下記のようにノードの状態を戻しておきましょう。
$ kubectl uncordon ip-172-31-3-135
node/ip-172-31-3-135 uncordoned
$ kubectl get node
NAME STATUS ROLES AGE VERSION
ip-172-31-15-204 Ready worker 15d v1.10.5
ip-172-31-3-135 Ready worker 15d v1.10.5
DBノード2台がReadyの状態になりました。あとはフェイルオーバと同じようにdrainコマンドを実行すればフェイルバックが可能です。
まとめ
今回はActive-StandbyのDB構成において、kubectl drainコマンドを用いたフェイルオーバを試してみました。結果は特に問題なく、ポッドの稼動ノードを変更することが出来ています。
明日は「運用を考える」編の第2回・計画停止やバックアップ・リストアについて書いていきます。
よろしくお願いします。