はじめに
前回の記事でwganおよび改良型wgan(wgan-gp)の説明をおこないました。
今回はkerasでの実装のポイントと生成結果について紹介します。
参考にしたコードは以下
tjwei/GANotebooks
実装
discriminatorの学習のためのモデル定義
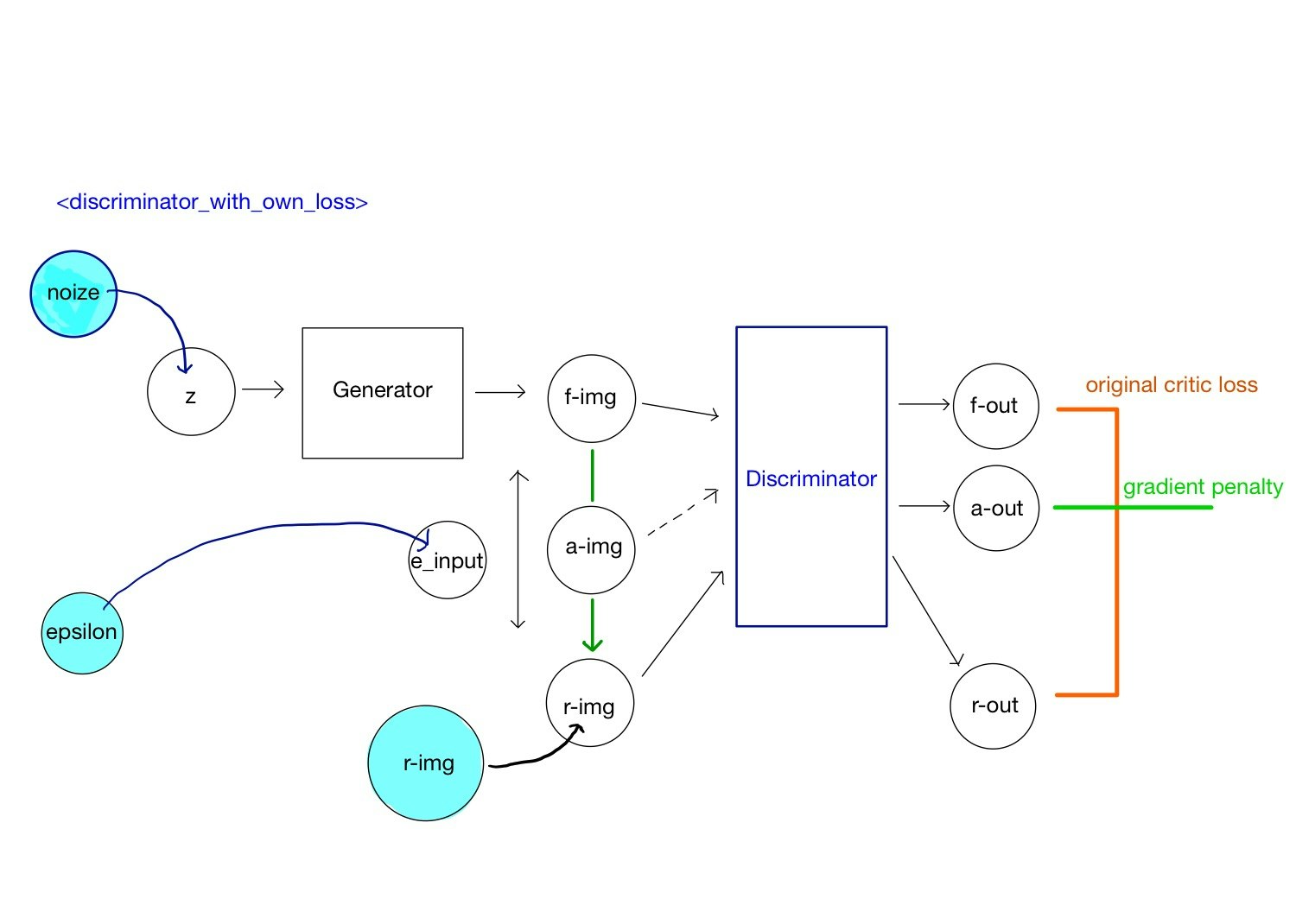
discriminatorの学習のための全体構造(discriminator_with_own_loss)を実装していきます。
WGAN-gpにおける学習では、識別でよく使われる形式 (y_true, y_pred)、つまり、「正解ラベルと予想結果を付き合わせる」といった形式を用いません。binary_cross_entropyなどの既に定義された関数を使うのではなく、損失関数を独自に定義する必要があります。
損失関数を定義して使用する
損失関数を独自に定義し、optimizerに渡して学習させていく手順は以下です。
- modelを作成する
- 損失関数を定義する
- optimizerをインスタンス化し、updatesメソッドで学習する重みを指定する
- 入力、出力、インスタンス化したoptimizerを引数として、関数化する
以下、コードをもとに順に説明していきます。
def build_discriminator_with_own_loss(self):
# 1. モデルの作成
# generatorの入力
z = Input(shape=(self.z_dim,))
# discriimnatorの入力
f_img = self.generator(g_input)
img_shape = (self.img_rows, self.img_cols, self.channels)
r_img = Input(shape=(img_shape))
e_input = K.placeholder(shape=(None,1,1,1))
a_img = Input(shape=(img_shape),\
tensor=e_input * img_input + (1-e_input) * g_output)
# discriminatorの出力
f_out = self.discriminator(f_img)
r_out = self.discriminator(r_img)
a_out = self.discriminator(a_img)
##モデルの定義終了
# 2. 損失関数の作成
# original critic loss
loss_real = K.mean(r_out)
loss_fake = K.mean(f_out)
# gradient penalty
grad_mixed = K.gradients(a_out, [a_img])[0]
norm_grad_mixed = K.sqrt(K.sum(K.square(grad_mixed), axis=[1,2,3]))
grad_penalty = K.mean(K.square(norm_grad_mixed -1))
# 最終的な損失関数
loss = loss_fake - loss_real + GRADIENT_PENALTY_WEIGHT * grad_penalty
# 3. optimizerをインスタンス化
training_updates = Adam(lr=1e-4, beta_1=0.5, beta_2=0.9)\
.get_updates(self.discriminator.trainable_weights,[],loss)
# 4. 入出力とoptimizerをfunction化
d_train = K.function([img_input, g_input, e_input],\
[loss_real, loss_fake], \
training_updates)
return d_train
1. モデルを作成する
discriminatorの学習時のmodel構造(上図の全体構造)をdiscriminator_with_own_lossと名付けます。
この構造のインプットは
- generatorへの潜在変数z
- 本物画像の入力r_img
- 生成データと偽物データの比率を決めるe_input
です。zはgeneratorで偽物データf-imgに変換されます。
次にf-imgとr-imgを結んだ直線上の任意の点a-imgを定義します。点の位置はパラメータepsilonで調整します。これら3つの入力をdiscriminatorに通し、それぞれ出力させ、f_out, r_out, a_outを得ます。
2. 損失関数を定義する
定義に沿って、損失関数を宣言します。勾配をとる箇所がありますが、微分される関数、微分を行う変数を間違えないようにします。

3. optimizerをインスタンス化
Adam optimizerをインスタンス化し、training_updates変数に格納します。get_updatesメソッドの引数には
- 学習対象の重み
- 学習の際の制約条件
- 損失関数
を指定します。制約条件はないので空リストを指定します。
4. 入出力とoptimizerインスタンスをfunction化
function関数に突っ込んであげておしまいです。メソッド定義していますのでreturnで返してあげます。
相違点
これまでのコードでは、入力と出力に対して
model = Model(input, output)
model.compile(optimizer= Adam(0.0001, beta_1=0.5, beta_2=0.9),\
loss = 'binary_crossentropy')
model.train_on_batch(input, y_true)
のようにmodelを定義し、さらにcompileメソッドを用いて、optimizerとlossを指定し、train_on_batchメソッドで学習させていました。この方法ですと、train_on_batchメソッドに必ず入力と正解ラベルを入れ必要があります。
その思想で作られたWGAN-gpのコードもあったのですが(keras-contrib/examples/improved_wgan.py)
損失関数の記述が若干トリッキーになると感じたのと、上記のコードでは生成した画像がぼやけてあまり良くありませんでした。
これから様々なアルゴリズムを実装する上では、損失関数を明示的に表す方が良いと思い、今回の実装にしました。
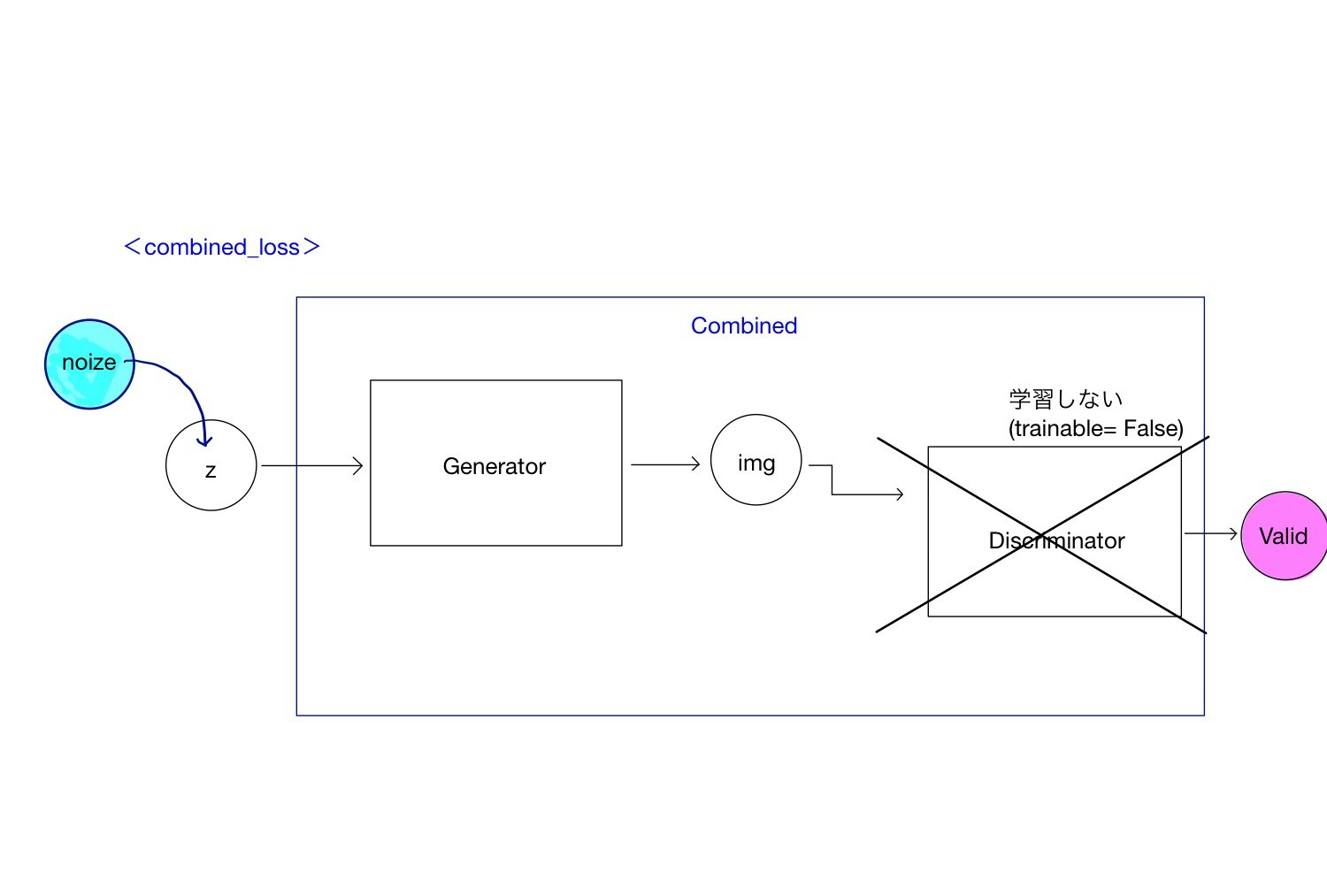
generatorの学習のためのモデル定義
下図に従って作成します。discriminator と同様です。
def build_combined2(self):
z = Input(shape=(self.z_dim,))
img = self.generator(z)
valid = self.discriminator(img)
model = Model(z, valid)
model.summary()
loss = -1. * K.mean(valid)
training_updates = Adam(lr=1e-4, beta_1=0.5, beta_2=0.9)\
.get_updates(self.generator.trainable_weights,[],loss)
g_train = K.function([z],\
[loss], \
training_updates)
return model, g_train
modelを出力する必要はないですね。summaryで出したかっただけです。
インスタンスの初期化
# combinedモデルの学習時はdiscriminatorの学習をFalseにする
for layer in self.discriminator.layers:
layer.trainable = False
self.discriminator.trainable = False
self.netG_model, self.netG_train = self.build_combined2()
# discriminator_with_ow_lossモデルの学習時はgeneratorの学習をFalseにする
for layer in self.discriminator.layers:
layer.trainable = True
for layer in self.generator.layers:
layer.trainable = False
self.discriminator.trainable = True
self.generator.trainable = False
self.netD_train = self.build_discriminator_with_own_loss()
generator, discriminatorの各学習に対して、学習しない方を固定します。
全体の学習時
for epoch in range(epochs):
for j in range(TRAINING_RATIO):
# ---------------------
# Discriminatorの学習
# ---------------------
# バッチサイズ分のノイズをGeneratorから生成
noise = np.random.normal(0, 1, (batch_size, self.z_dim))
gen_imgs = self.generator.predict(noise)
# バッチサイズ分の本物画像を教師データからピックアップ
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
# discriminatorを学習
epsilon = np.random.uniform(size = (batch_size, 1,1,1))
errD_real, errD_fake = self.netD_train([imgs, noise, epsilon])
d_loss = errD_real - errD_fake
# ---------------------
# Generatorの学習
# ---------------------
noise = np.random.normal(0, 1, (batch_size, self.z_dim))
# Train the generator
g_loss = self.netG_train([noise])
discriminator_with_own_loss, combinedで定義したK.functionに対して、入力値を指定します。
返り値は、outputで指定したloss値が返るのでので、それを変数で受けます。
変数で受ける目的は、その値をプロットするためですが、その際に学習が行われています。(間違っていたら教えてください)
全体のコードはgithubで公開しています。
生成画像
dcganの結果と同じく潜在変数の次元を変えて画像を生成させます。
まずはz_dim= 100

z_dim= 50

z_dim= 10

前回みられたような、振動や同じ文字が生成されることはありませんね。
z_dim= 5

z_dim= 2

dcganのときのような、モード崩壊が起きていないように見えます。
前回モード崩壊が起きたのは、学習のバランスというよりも単純に潜在変数の次元が少なく、generatorの表現力が小さいためと思っていたのですが、z_dim=2のときでも、うまく画像を生成できていますね。ちょっと驚きです。
訂正。前回アップロードしていたGIFは別パラメータのものでした。
各epoch iterationで同じ乱数から生成しているのに、画像が安定していないですね。
z_dim=1

さすがにここまでくると、完全にモード崩壊しているのがわかります。同じ画像が生成されているのがわかります。
潜在変数の次元が低く、WGANを用いても表現力が低すぎました。
終わりに
さて、mnistでどれだけ恩恵を受けられたかわかりませんが、学習を安定させるためのテクニックとしてWGAN-gpを紹介しました。
次は、acganを用いて任意の数字を能動的に生成していきたいと思います。