ExcelファイルをPythonでデータ分析する
1.Excelファイルの読み込み - 2.グラフ - 3.度数分布 - 4.ランキングチャート - 5.相関 - 6.ディシジョンツリー
「ExcelファイルをPythonでデータ分析する」は上のような一連の記事になっており、2~6までは事前に1.Excelファイルの読み込みが行われていることを前提としています。
環境
Google Colaboratoryを使用します
Google Colaboratoryは、Googleの提供するオンラインPythonプログラミング環境です。ノートブック形式と呼ばれる、プログラム、実行結果、メモを1つのファイルで取り扱うことができて、またその中をセルという単位で分割できます。例えばExcelファイルの読み込みまでのプログラムを1つのセルにして実行しておいて、その読み込み結果からグラフを描画するプログラムを別のセルにしておけば、描画プログラムを変更するたびに毎回ファイルを読み直すことをしなくても良くなります。
日本語matplotlibのインストール
図のキャプションなどを日本語で表示できるように、japanese-matplotlibをColaboratoryにインストールします。
!pip install japanize-matplotlib
記事作成時のPythonおよび各モジュールのバージョン
- Google Colaboratory
- Python 3.10.12
- japanize-matplotlib 1.1.3
- matplotlib 3.7.1
- numpy 1.25.2
- pandas 2.0.3
Colaboratoryのそれぞれのバージョン情報の確認の仕方は、次のように行うことができます。
!python -V
!pip list | egrep "numpy|^pandas |*matplotlib "
Excelデータファイル(男女別人口データ)
データファイルの取得
政府統計の総合窓口(e-Stat)(https://www.e-stat.go.jp/)から、男女別人口及び人口性比 - 全国,都道府県(大正9年~令和2年)(da01.xlsx)を利用させていただきます。

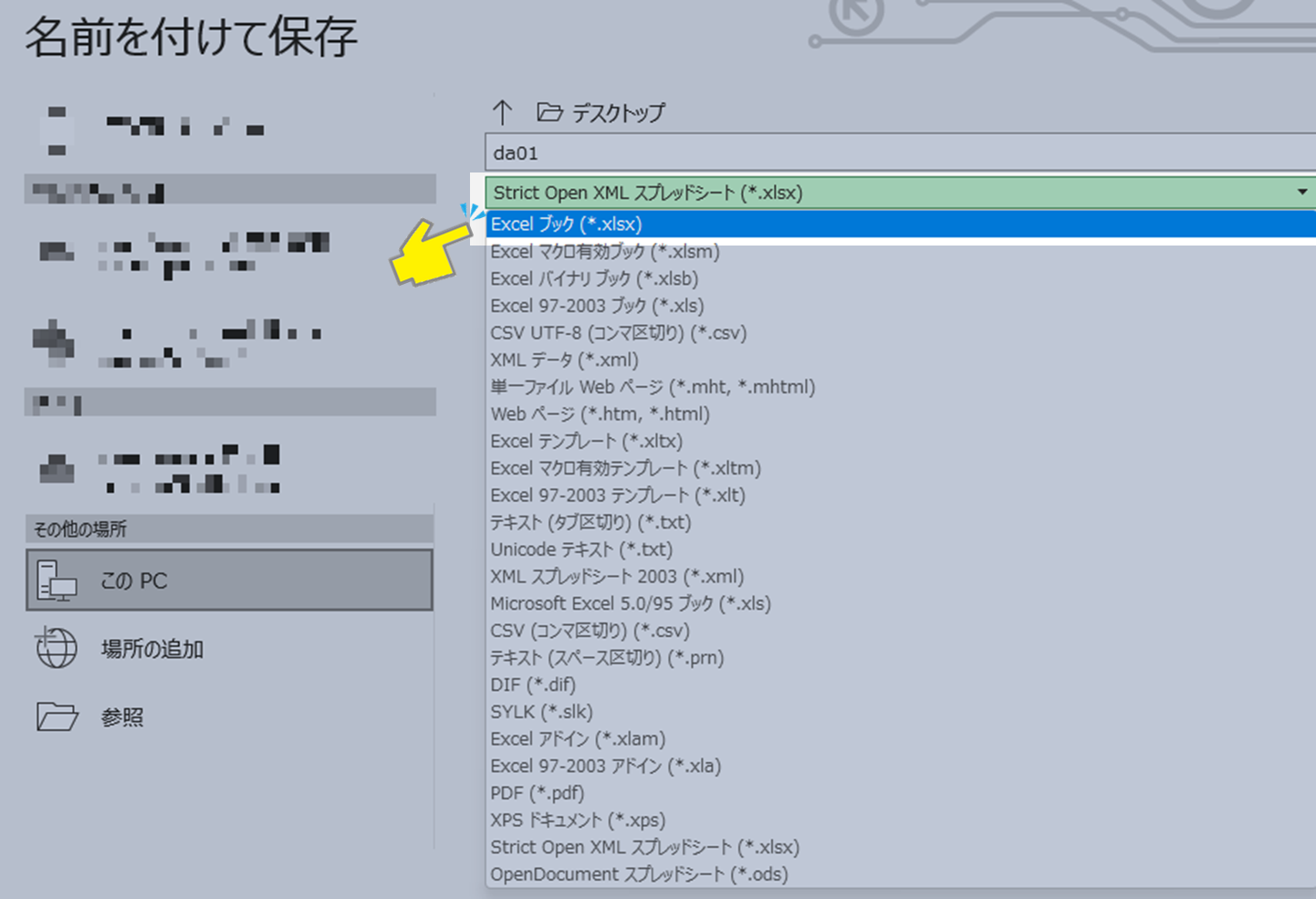
Excelファイル形式の変更
上記のデータは、「Strict Open XML スプレッドシート(.xlsx)」という形式になっているので、Excelの名前を付けて保存によって「Excelブック (.xlsx)」形式に上書き保存してください。
Colaboratoryで読み込み
ファイルを選択してアップロードする方法と、Google DriveにファイルをアップロードしてColaboratoryからマウントする方法の2つがあります。とりあえず試す場合、最初のファイルを選択してアップロードの方が簡単だと思います。
Colaboratory上でファイルを選択してアップロード
この方法は、Colaboratoryのセッションが終了するとアップロードしたファイルは無くなります。よって新しいセッションを作るたびにファイルをアップロードする必要があります。
Colaboratoryのセルで以下を実行すると、ファイル選択のボタンが表示されます。
from google.colab import files
uploaded = files.upload()
!ls

ファイルをアップロードし直す場合、Colaboratoryはすでに同名のファイルがあると新しいファイルを別名に変更します。

上記の例は、"da01.xlsx"を2回目にアップロードしたときに、新しいファイルを"da01 (1).xlsx"というファイルとして保存したとのメッセージです。この場合、次のファイルを読み込むPythonプログラムを"da01 (1).xlsx"に変更するか、以下のプログラムを実行して元のファイルを削除してからアップロードしてください。
!rm *.xlsx
プログラムからアップロードしたファイルを読み込むときは、アップロードしたファイルは現階層にあるためパス指定なしのファイル名だけで読み込むことができます。
Colaboratory上でファイルを選択してアップロードしたファイルを読み込む例は次のようです。
import pandas as pd
df0 = pd.read_excel('da01.xlsx')
Google Driveにファイルをアップロードして、Colaboratoryからマウントする
この方法は、上のColaboratory上でファイルを選択してアップロードとは異なり、Colaboratoryのセッションが終了してもファイルは消去されません。ただし、Google Driveのマウントはセッション開始後に毎回行う必要があります。
以下のように、Google Driveをマウントします。この例では、マウント先のパス名は、/content/driveとなっています。MyDriveは、Google Driveで最初に開いたときに見えている階層です。
from google.colab import drive
drive.mount('/content/drive')
!ls /content/drive/MyDrive
実行するとGoogleから許可を求めるダイアログ等が表示されるので、許可します。ちなみにその許可によってさらにGoogleからセキュリティ通知のメールが送られてきたりするので、自分の行った操作であり問題はないと回答しておくと良いでしょう。
プログラムからGoogle Driveのファイルを読み込むには、上記の例では/content/driveというマウントしたパスを使用した絶対パスで読み込むことができます。
Google DriveにファイルをアップロードしてColaboratoryからマウントしてファイルを読み込む例は次のようです。
import pandas as pd
df0 = pd.read_excel('/content/drive/MyDrive/da01.xlsx')
ここでエラーが表示される場合は、Excelファイルがダウンロードしたときのフォーマット(Strict Open XML スプレッドシート)になっている可能性があります。ダウンロードしたファイルをExcelで開いて、名前を名付けて保存によって「Excelブック(.xlsx)」形式に変換してください。
DataFrameの確認
# データ全体を表示
print(df0)
# データの上部のみを表示
print(df0.head())
# データの行を表示
print(df0.index)
# データの列を表示
print(df0.columns)
データの行を表示すると次のように出力されます。これは、自動的に作成されたインデックスで0から57の1つ前の56までが割り振られています。

データの列を表示すると次のように出力されます。これはデータファイルの1行目をDataFrameの列名にしようとした結果です。データファイルの最初のセルに記載されいてる「国勢調査....」のみが割り振られていて後は自動で作成された列名となっています。

このままでは分析に扱いにくいので、以下のように不要なところを排除したり名前を付けたりします。
男女別人口データの読み込みとPythonでの事前処理
人口データのExcelファイルは、8行目までがヘッダーで最初の列(A列)が行のインデックスにしたい都道府県名が入ったデータです。まず不要な行をスキップして読み込み、行のインデックス、列の名前を分析で扱いやすいように行は都道府県名、列は"年_[総数 or 男 or 女]"とします。
以下はPythonによってデータを整形する事前準備を行いますが、Excelによってデータファイルを操作してから読み込んでも良いかもしれません。
import pandas as pd
import numpy as np
import re
# データファイルの1~8行目までは、ヘッダーとして使用する7行目を除いて読み込みをスキップする。
# また「全国(人口集中地区)」「全国(人口集中地区以外の地区)」は1965年までの欠損値が大きくあるのでこれもスキップする。
# 沖縄県は1945年に欠損値がある。列番号16~18を指定して、欠損値の"-"をnp.nanに変換する。
# スキップしたあとの最初の行はヘッダーとして扱い、また最初の列はDataFrameのindexとして扱う。
# 行、列の指定はプログラム内では0から数える数値となっている。
df0 = pd.read_excel('da01.xlsx',skiprows=[0,1,2,3,4,5,7,9,10],header=0,index_col=0,converters={i:lambda x:np.nan if x=="-" else int(x) for i in range(16,19)})
# DataFrameのインデックスを整形する。
# データファイルでは0000_全国のようにコード_県名なので、
# _ 以降だけをインデックスとして使用する。
m = map(lambda l:re.findall(r".*_(.*)",l)[0],df0.index)
df0 = df0.set_axis(list(m),axis="index")
# DataFrameの列名を整形する。
# データファイルでは7行目を列名として使用するが、
# 1920年, 大正9年, (空白), ... となっている。それぞれの意味は、1920の総数、男、女の人口なので、
# それに合わせた列名になるように修正する。
column_labels = []
for i in range(0,len(df0.columns),3):
for l in ["総数","男","女"]:
column_labels.append(f"{df0.columns[i]}_{l}")
df0 = df0.set_axis(column_labels,axis="columns")
読み込んだDataFrameを確認します。それぞれのPythonプログラムと出力結果を示します。
print(df0.head())

データが各都道府県ごとに、各年の総数、男、女で表されています。
print(df0.index)

行のインデックスは都道府県名になっています。
print(df0.columns)

列の名称は、"年_[総数 or 男 or 女]"となっています。
DataFrameのloc関数(参考)を使用して、例えば新潟県の1920年と2020年の人口をそれぞれ表示することもできます。
# 行、列の両方を1つだけ指定する。
print(df0.loc["新潟県","2020年_総数"])
# 行は1つ、列は複数を指定する。
print(df0.loc["新潟県",["2020年_男","2020年_女"]])
# 行は複数、列は1つを指定する。
print(df0.loc[["新潟県","東京都"],"2020年_総数"])
# 行、列の両方を複数指定する。
print(df0.loc[["新潟県","東京都"],["2020年_男","2020年_女"]])
出力結果は上から順に次のようになります。
行、列の両方を1つだけ指定すると、その県のその年の人口が出力されます。

列を複数にすると、同じ県の2つ以上のデータが表示されます。このデータは、pandas.Seriesの形式です。

行を複数にすると、列の複数と同様に、複数の都道府県の同じ年のデータが表示されます。このデータ形式もpandas.Seriesです。

行、列を複数にするとテーブル形式で表示されます。このデータの形式は、pandas.DataFrameです。
男女別人口データのExcelでの事前処理
次のようにExcelファイル上で不要な行や列を削除したり、名前を変更することによってPythonの処理を書かなくても同様の読み込みを行うことができます。
- 1行目に1920年_総数、1920年_男... のように[xxxx年_(総数 or 男 or 女]のデータを作成する。
- A列目に全国を含めて都道府県名を作成する。
- 元のデータから、該当する都道府県、年をコピーする(全国の人口集中地区と書かれた2行以外をコピーする)。
- 1945年の沖縄県の欠損値が "-"になっているので、空白に変更する。

この加工したExcelファイルを読み込むPythonプログラムは、そのファイル名を"da01_modified.xlsx"とし以下のように行います。
import pandas as pd
df0 = pd.read_excel('da01_modified.xlsx',index_col=0)
print(df0.head())
読み込みを実行するとDataFrameの変数であるdf0は、上のPythonで前処理を実施したものと同じものになります。
Excelファイルへの出力
Pythonで加工したDataFrameはExcelファイルとして保存してローカルPCにダウンロードすることができます。以下の例では、新潟県と東京都の男女データを除外した人口総数のみのExcelファイルを作成してダウンロードしています。
# データの抽出例(新潟県と東京都の、男女データを除外した人口総数のみ)
df1 = df0.loc[["新潟県","東京都"],filter(lambda l:"総数" in l,df0.columns)]
print(df1.head())
# 出力のファイル名を output.xlsx, シート名を Sheet_name_1 としてColaboratory上に保存する。
df1.to_excel("output.xlsx",sheet_name="Sheet_name_1")
from google.colab import files
# 保存したファイル名でローカルにダウンロードする。
files.download("output.xlsx")
ダウンロードしたExcelファイルを開くと次のように確認することができます。

参考
pandas.DataFrame API
pandas.Series API
NumPy API
matplotlib API
早く知っておきたかったmatplotlibの基礎知識、あるいは見た目の調整が捗るArtistの話