ExcelファイルをPythonでデータ分析する
1.Excelファイルの読み込み - 2.グラフ - 3.度数分布 - 4.ランキングチャート - 5.相関 - 6.ディシジョンツリー
「ExcelファイルをPythonでデータ分析する」は上のような一連の記事になっており、2~6までは事前に1.Excelファイルの読み込みと事前処理が行われていることを前提としています。
人口から都道府県名を判定するディシジョンツリー
人口データは1920年から2020年までの100年間に、5年に一度の国勢調査が行われていて21回分のデータがあります。
この記事の作成のために、以下のことを試してみました。主にデータの離散化、統合です。離散化や統合をする理由としては、データが細かすぎる場合には作成できるディシジョンツリーが膨大な大きさになって人の理解を困難とさせてしまうからです。
- 行(都道府県)をエリア(3大都市圏、地方)単位にしてディシジョンツリーを作成してみる。
→ 「○○年の人口が多い場合は××地方」といったような地方を判別できるようなディシジョンツリーが作れなかったので、行はそのままとして都道府県単位で名前を判別するディシジョンツリーとしました。 - 列(年)を統合するために21個のデータを幾つかのグループに分けてみる。
→ 以下の例では隣り合う年、例えば1920年と1925年を1つにしてグループ化してみました。
→ 多くの年を1つのグループにしても、少ない年の数を1つのグループにしてもあまり結果には影響が無いようでした。 - データ(人口数)を離散化する。
→ 離散化手法は等間隔で分けています。
→ あまり細かく分けるとディシジョンツリーの可読性が悪くなるので、「特大、大、中、小」の4パターンで試してみました。
結果的に以下の例では、次のようにデータを離散化、統合しています。
| データの種類 | 離散化、統合の方法 |
|---|---|
| 都道府県 | そのまま使用します。 |
| 調査年 | 2回分、調査は5年に1度なので10年ごとにまとめます。 |
| 人口数 | 調査年のグループごとに等間隔に4分割し「特大、大、中、小」とします。 また人口総数、男性数、女性数のすべてを使用します。 |
年を統合して離散化する
以下のプログラムは、人口データの変数df0から離散化、統合をしたデータを新たに追加した変数df1を作成します。
import numpy as np
from functools import reduce
import matplotlib.pyplot as plt
import japanize_matplotlib
# 全国のデータを除外する。総数、男、女の人口数はすべて使用する。
years = list(df0.columns)
df1 = df0.loc[filter(lambda l:l not in "全国",df0.index),years]
# 年を以下の範囲で統合する。
year_range = 2
for t in range(3):
for i in range(0,len(years),year_range*3):
r = years[i+t:i+t+year_range*3:3]
# 統合された年は _summed という識別子を列名を追加した新しい列をDataFrameに追加する。
df1.loc[:,f"{r[0]}-{r[-1]}_summed"] = reduce(lambda a,e:a+df1.loc[:,e],r,pd.Series(0,df1.index))
# 統合された列の一覧を作成する。
ranged_years = list(filter(lambda l:"_summed" in l,df1.columns))
# 統合された列のデータを離散化する。
bin_names = ["小","中","大","特大"]
for year in ranged_years:
bins = len(bin_names)
# 離散化はpandas.DataFrame.cutを使用する。
bin = pd.cut(df1.loc[:,year].dropna(),bins)
dic = {v:bin_names[i] for i,v in enumerate(bin.cat.categories)}
# 離散化後のデータは _categories という識別子を列名に追加した新しい列をDataFrameに追加する。
df1.loc[:,f"{year}_categories"] = bin.map(dic)
print(df1.head(2))
実行するとdf1の一部が表示されます。
1920年_総数 1920年_男 1920年_女 1925年_総数 1925年_男 1925年_女 1930年_総数 \
北海道 2359183 1244322 1114861 2498679 1305473 1193206 2812335
青森県 756454 381293 375161 812977 408770 404207 879914
1930年_男 1930年_女 1935年_総数 ... 1930年_女-1935年_女_summed_categories \
北海道 1468540 1343795 3068282 ... 中
青森県 441441 438473 967129 ... 小
1940年_女-1945年_女_summed_categories 1950年_女-1955年_女_summed_categories \
北海道 大 大
青森県 小 小
1960年_女-1965年_女_summed_categories 1970年_女-1975年_女_summed_categories \
北海道 中 中
青森県 小 小
1980年_女-1985年_女_summed_categories 1990年_女-1995年_女_summed_categories \
北海道 中 中
青森県 小 小
2000年_女-2005年_女_summed_categories 2010年_女-2015年_女_summed_categories \
北海道 中 中
青森県 小 小
2020年_女-2020年_女_summed_categories
北海道 中
青森県 小
[2 rows x 129 columns]
例えば作成したデータを確認したい場合には、以下のプログラムを実行してExcelファイルとしてローカルPCにダウンロードすることができます。
# データをファイルに保存して確認
df1.to_excel(f"df1.xlsx",sheet_name="Sheet_name_1")
from google.colab import files
files.download(f"df1.xlsx")
また離散化、統合した様子を変数df1の一部をグラフ化して確認することもできます。
# 確認用に元データと離散化後のデータを最初の年の総数、男、女の人口数に対して描画する。
for year in ranged_years[0::int(len(ranged_years)/3)]:
# 離散化前と離散化後の2つのグラフを描画する。
for i in range(2):
# 描画領域を作成する。
fig,ax = plt.subplots(figsize=(16,8))
if i == 0:
# 離散化前の場合は、pandas.Seriesのデータ形式をmatplotlib.axes.Axes.plotに渡す。
ax.plot(df1.loc[:,year+("" if i==0 else "_categories")].dropna())
else:
# 離散化後のpandas.Seriesはdtypeがcategoryになっていてそのまま描画するとFutureWarningを
# 発生するので、pandas.Series.cat.codesで数値化してから描画する。
ax.plot(df1.loc[:,year+("" if i==0 else "_categories")].dropna().cat.codes)
# 縦軸の目盛りは、離散化後のラベルにする。
ax.set_yticks([i for i in range(len(bin_names))])
ax.set_yticklabels(bin_names)
# グラフタイトル、横軸の目盛りラベルを設定しグリッドを描画する。
ax.set_title(f"{year}_{'離散' if i!=0 else ''}")
ax.set_xticklabels(df1.index,rotation=90)
ax.grid()
plt.show()
統合されたデータのグラフは次のように表示されます。
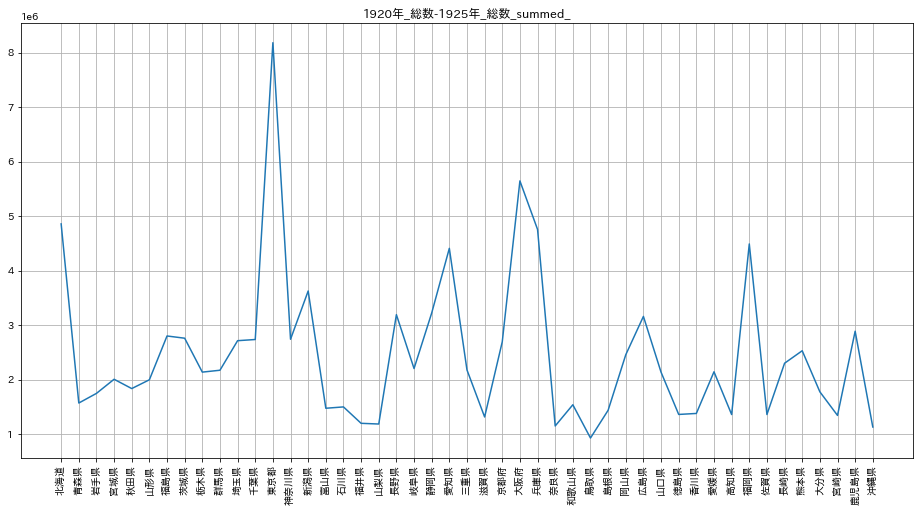
これを離散化すると次のようになります。縦軸が4段階となっています。
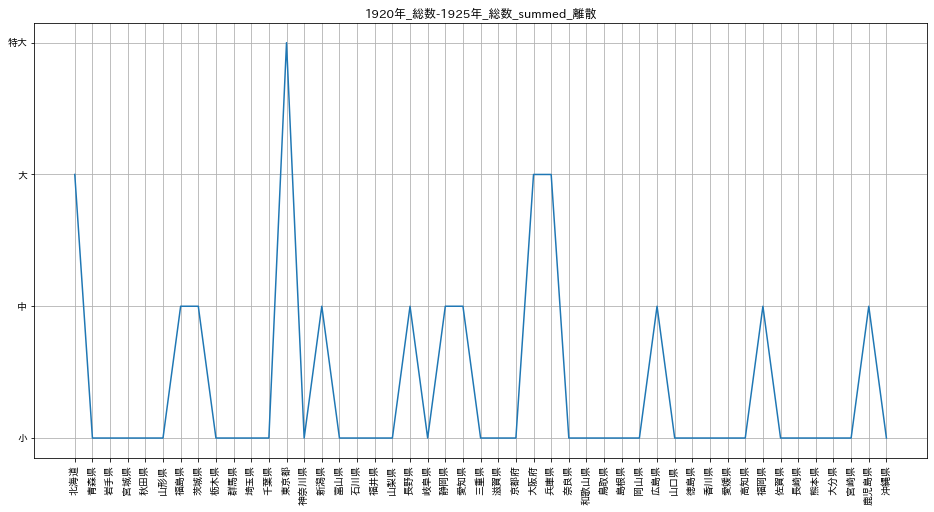
ディシジョンツリーを作成します。
離散化、統合したデータであるdf1を用いてディシジョンツリーを作成していきます。ディシジョンツリーの目的は、○○年は人口の多い/少ないといったデータからそれは××県というように都道府県名を判定することです。
Pythonで0からディシジョンツリーを作って理解する (1. 概要編)の「1.4.1 プログラムの全文」をコピーして、このプログラムがディシジョンツリーを作成するために使用するDataFrameであるdftを次のように入れ替えます。
# ディシジョンツリーのデータになる dft を入れ替える。
# 欠損値 Nan を "不明" に変換する
df2 = df1.copy()
for year in ranged_years:
df2[f"{year}_categories"] = df2.loc[:,f"{year}_categories"].cat.add_categories("不明")
df2[f"{year}_categories"].fillna(df2.loc[:,f"{year}_categories"].cat.categories[-1],inplace=True)
dft = df2.loc[filter(lambda l:"全国" not in l,df1.index),filter(lambda l:"_categories" in l,df1.columns)]
dft.loc[:,"pref"] = dft.index
そしてディシジョンツリーを作成する以下のプログラムを実行します。このプログラムは、Pythonで0からディシジョンツリーを作って理解する (1. 概要編)で示したID3というディシジョンツリー作成プログラムを実装したものです。ただしdftというディシジョンツリーのもとになるデータは、1つ上のプログラムで作成されたものを使用するので、この記事内ではコメントアウトされています。
import math
import pandas as pd
from functools import reduce
# データセット
#d = {
# "天気":["晴","晴","曇","雨","雨","雨","曇","晴","晴","雨","晴","曇","曇","雨"],
# "温度":["暑","暑","暑","暖","涼","涼","涼","暖","涼","暖","暖","暖","暑","暖"],
# "湿度":["高","高","高","高","普通","普通","普通","高","普通","普通","普通","高","普通","高"],
# "風":["無","有","無","無","無","有","有","無","無","無","有","有","無","有"],
# # 最後の列が、目的変数、正解データともよばれる、他の列から導き出したいデータとなる。
# "ゴルフ":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"],
#}
#dft = pd.DataFrame(d)
# 値の配分を求めるラムダ式、引数はpandas.Series、戻り値は各値の個数が入った配列
# 入力sからvalue_counts()で各値の度数を取得し、辞書型のデータのループ items()を呼び出す。
# sortedは、実行毎に出力結果が変化しないように、度数の小さい順に並べ替えている。
# そして、要素がキー(k)と値(v)の文字列となった配列を生成する。
cstr = lambda s:[k+":"+str(v) for k,v in sorted(s.value_counts().items())]
# ディシジョンツリーのデータ構造
tree = {
# name: このノード(幹)の名前
"name":"decision tree "+dft.columns[-1]+" "+str(cstr(dft.iloc[:,-1])),
# df: このノードに関連付けられるデータ
"df":dft,
# edges: このノードから出ているエッジ(枝)一覧、下にエッジの無い葉ノードの場合は空配列となる。
"edges":[],
}
# ツリーの生成は、枝が伸びる可能性のある幹についてこのopenに保存しておく。
open = [tree]
# エントロピーを計算するラムダ式、引数はpandas.Series、戻り値はエントロピーの数値
entropy = lambda s:-reduce(lambda x,y:x+y,map(lambda x:(x/len(s))*math.log2(x/len(s)),s.value_counts()))
# openが空になるまで繰り返す。
while(len(open)!=0):
# openの先頭を取り出し、そのノードが保持しているデータを取り出しておく。
n = open.pop(0)
df_n = n["df"]
# このノードのエントロピーが0の場合、これ以上エッジを展開できないので、
# このノードからの枝分かれはしない。
if 0==entropy(df_n.iloc[:,-1]):
continue
# 分岐可能性の属性値一覧を保存する変数を作成しておく。
attrs = {}
# クラス属性の最後の列以外の属性をすべて調査する。
for attr in df_n.columns[:-1]:
# この属性で分岐する場合のエントロピーと、
# 分岐後のデータと分岐する属性値を保存する変数を作成する。
attrs[attr] = {"entropy":0,"dfs":[],"values":[]}
# この属性の取りうる値をすべて調査する。またsortedは、属性値の重複除去された配列を、
# 実行のたびに順番が入れ替わらないようにするためである。
for value in sorted(set(df_n[attr])):
# 属性値でデータをフィルタリングする。
df_m = df_n[df_n.loc[:,attr]==value]
# エントロピーを計算し、関連するデータ、値をそれぞれ保存しておく。
attrs[attr]["entropy"] += entropy(df_m.iloc[:,-1])*df_m.shape[0]/df_n.shape[0]
attrs[attr]["dfs"] += [df_m]
attrs[attr]["values"] += [value]
pass
pass
# クラス値を分離可能な属性が1つも無い場合は、このノードの調査を終了する。
if len(attrs)==0:
continue
# エントロピーが最小になる属性を取得する。
attr = min(attrs,key=lambda x:attrs[x]["entropy"])
# 分岐する属性のそれぞれの値、分岐後のデータを、ツリーとopenにそれぞれ追加する。
for d,v in zip(attrs[attr]["dfs"],attrs[attr]["values"]):
m = {"name":attr+"="+str(v),"edges":[],"df":d.drop(columns=attr)}
n["edges"].append(m)
open.append(m)
pass
# データセットを出力する。
print(dft,"\n-------------")
# ツリーを文字に変換するメソッド、引数は tree:ツリーのデータ構造、indent:子ノードにつくインデント、
# 戻り値は、treeの文字表現。このメソッドは、再帰的に呼ばれて、ツリーのすべてを文字に変換する。
def tstr(tree,indent=""):
# このノードの文字表現を作成する。このノードが葉ノードの場合(edges配列の要素数が0)には、
# treeに関連付けられたデータdfの最後の列の度数分布を文字化する。
s = indent+tree["name"]+str(cstr(tree["df"].iloc[:,-1]) if len(tree["edges"])==0 else "")+"\n"
# このノードからのエッジについて、すべてループする。
for e in tree["edges"]:
# 子ノードの文字表現を、このノードの文字表現に付け加える。
# indentには、このノードのindentに、さらに文字を加える。
s += tstr(e,indent+" ")
pass
return s
# ツリーを文字表現して、出力する。
print(tstr(tree))
実行すると次のようなディシジョンツリーが作成されます。
decision tree pref ['三重県:1', '京都府:1', '佐賀県:1', '兵庫県:1', '北海道:1', '千葉県:1', '和歌山県:1', '埼玉県:1', '大分県:1', '大阪府:1', '奈良県:1', '宮城県:1', '宮崎県:1', '富山県:1', '山口県:1', '山形県:1', '山梨県:1', '岐阜県:1', '岡山県:1', '岩手県:1', '島根県:1', '広島県:1', '徳島県:1', '愛媛県:1', '愛知県:1', '新潟県:1', '東京都:1', '栃木県:1', '沖縄県:1', '滋賀県:1', '熊本県:1', '石川県:1', '神奈川県:1', '福井県:1', '福岡県:1', '福島県:1', '秋田県:1', '群馬県:1', '茨城県:1', '長崎県:1', '長野県:1', '青森県:1', '静岡県:1', '香川県:1', '高知県:1', '鳥取県:1', '鹿児島県:1']
1940年_女-1945年_女_summed_categories=不明['沖縄県:1']
1940年_女-1945年_女_summed_categories=中
1990年_総数-1995年_総数_summed_categories=中
1920年_総数-1925年_総数_summed_categories=中['静岡県:1']
1920年_総数-1925年_総数_summed_categories=小['千葉県:1']
1990年_総数-1995年_総数_summed_categories=大
1950年_総数-1955年_総数_summed_categories=中['神奈川県:1']
1950年_総数-1955年_総数_summed_categories=小['埼玉県:1']
1990年_総数-1995年_総数_summed_categories=小
1920年_男-1925年_男_summed_categories=中
1930年_総数-1935年_総数_summed_categories=中['新潟県:1']
1930年_総数-1935年_総数_summed_categories=小
1920年_総数-1925年_総数_summed_categories=中
1940年_総数-1945年_総数_summed_categories=中
1950年_総数-1955年_総数_summed_categories=小
1960年_総数-1965年_総数_summed_categories=小
1970年_総数-1975年_総数_summed_categories=小
1980年_総数-1985年_総数_summed_categories=小
2000年_総数-2005年_総数_summed_categories=小
2010年_総数-2015年_総数_summed_categories=小
2020年_総数-2020年_総数_summed_categories=小
1930年_男-1935年_男_summed_categories=小
1940年_男-1945年_男_summed_categories=中
1950年_男-1955年_男_summed_categories=小
1960年_男-1965年_男_summed_categories=小
1970年_男-1975年_男_summed_categories=小
1980年_男-1985年_男_summed_categories=小
1990年_男-1995年_男_summed_categories=小
2000年_男-2005年_男_summed_categories=小
2010年_男-2015年_男_summed_categories=小
2020年_男-2020年_男_summed_categories=小
1920年_女-1925年_女_summed_categories=中
1930年_女-1935年_女_summed_categories=小
1950年_女-1955年_女_summed_categories=小
1960年_女-1965年_女_summed_categories=小
1970年_女-1975年_女_summed_categories=小
1980年_女-1985年_女_summed_categories=小
1990年_女-1995年_女_summed_categories=小
2000年_女-2005年_女_summed_categories=小
2010年_女-2015年_女_summed_categories=小
2020年_女-2020年_女_summed_categories=小['広島県:1', '長野県:1']
1920年_男-1925年_男_summed_categories=小
1920年_総数-1925年_総数_summed_categories=中
1930年_総数-1935年_総数_summed_categories=小
1940年_総数-1945年_総数_summed_categories=中
1950年_総数-1955年_総数_summed_categories=小
1960年_総数-1965年_総数_summed_categories=小
1970年_総数-1975年_総数_summed_categories=小
1980年_総数-1985年_総数_summed_categories=小
2000年_総数-2005年_総数_summed_categories=小
2010年_総数-2015年_総数_summed_categories=小
2020年_総数-2020年_総数_summed_categories=小
1930年_男-1935年_男_summed_categories=小
1940年_男-1945年_男_summed_categories=小
1950年_男-1955年_男_summed_categories=小
1960年_男-1965年_男_summed_categories=小
1970年_男-1975年_男_summed_categories=小
1980年_男-1985年_男_summed_categories=小
1990年_男-1995年_男_summed_categories=小
2000年_男-2005年_男_summed_categories=小
2010年_男-2015年_男_summed_categories=小
2020年_男-2020年_男_summed_categories=小
1920年_女-1925年_女_summed_categories=中
1930年_女-1935年_女_summed_categories=小
1950年_女-1955年_女_summed_categories=小
1960年_女-1965年_女_summed_categories=小
1970年_女-1975年_女_summed_categories=小
1980年_女-1985年_女_summed_categories=小
1990年_女-1995年_女_summed_categories=小
2000年_女-2005年_女_summed_categories=小
2010年_女-2015年_女_summed_categories=小
2020年_女-2020年_女_summed_categories=小['福島県:1', '茨城県:1']
1940年_女-1945年_女_summed_categories=大
1920年_総数-1925年_総数_summed_categories=中
1940年_総数-1945年_総数_summed_categories=中['福岡県:1']
1940年_総数-1945年_総数_summed_categories=大['愛知県:1']
1920年_総数-1925年_総数_summed_categories=大
1930年_総数-1935年_総数_summed_categories=中
1950年_総数-1955年_総数_summed_categories=中['兵庫県:1']
1950年_総数-1955年_総数_summed_categories=大['北海道:1']
1930年_総数-1935年_総数_summed_categories=大['大阪府:1']
1940年_女-1945年_女_summed_categories=小
1920年_女-1925年_女_summed_categories=中
1920年_総数-1925年_総数_summed_categories=中['鹿児島県:1']
1920年_総数-1925年_総数_summed_categories=小['京都府:1']
1920年_女-1925年_女_summed_categories=小
1920年_総数-1925年_総数_summed_categories=小
1930年_総数-1935年_総数_summed_categories=小
1940年_総数-1945年_総数_summed_categories=小
1950年_総数-1955年_総数_summed_categories=小
1960年_総数-1965年_総数_summed_categories=小
1970年_総数-1975年_総数_summed_categories=小
1980年_総数-1985年_総数_summed_categories=小
1990年_総数-1995年_総数_summed_categories=小
2000年_総数-2005年_総数_summed_categories=小
2010年_総数-2015年_総数_summed_categories=小
2020年_総数-2020年_総数_summed_categories=小
1920年_男-1925年_男_summed_categories=小
1930年_男-1935年_男_summed_categories=小
1940年_男-1945年_男_summed_categories=小
1950年_男-1955年_男_summed_categories=小
1960年_男-1965年_男_summed_categories=小
1970年_男-1975年_男_summed_categories=小
1980年_男-1985年_男_summed_categories=小
1990年_男-1995年_男_summed_categories=小
2000年_男-2005年_男_summed_categories=小
2010年_男-2015年_男_summed_categories=小
2020年_男-2020年_男_summed_categories=小
1930年_女-1935年_女_summed_categories=小
1950年_女-1955年_女_summed_categories=小
1960年_女-1965年_女_summed_categories=小
1970年_女-1975年_女_summed_categories=小
1980年_女-1985年_女_summed_categories=小
1990年_女-1995年_女_summed_categories=小
2000年_女-2005年_女_summed_categories=小
2010年_女-2015年_女_summed_categories=小
2020年_女-2020年_女_summed_categories=小['三重県:1', '佐賀県:1', '和歌山県:1', '大分県:1', '奈良県:1', '宮城県:1', '宮崎県:1', '富山県:1', '山口県:1', '山形県:1', '山梨県:1', '岐阜県:1', '岡山県:1', '岩手県:1', '島根県:1', '徳島県:1', '愛媛県:1', '栃木県:1', '滋賀県:1', '熊本県:1', '石川県:1', '福井県:1', '秋田県:1', '群馬県:1', '長崎県:1', '青森県:1', '香川県:1', '高知県:1', '鳥取県:1']
1940年_女-1945年_女_summed_categories=特大['東京都:1']
ディシジョンツリーの枝刈り
上記のディシジョンツリーではツリーが大きすぎて理解しづらいので不必要な枝を刈ってツリーを小さくしていきます。
今回使用しているディシジョンツリー作成のアルゴリズムはID3と呼ばれるもので、枝刈りと呼ばれる不必要に深掘りされたツリーを短く浅くしていく仕組みはありません。ID3の発展版であるC4.5などを用いることも考えられますが、ここでは手動で枝刈りし以下のようにまとめてみます。
手動で枝刈りすることの方針は、都道府県の名称を分離できる分岐点だけを残す、というものです。例えば以下のようなディシジョンツリーがあったとします。このディシジョンツリーは、x年の人口が特大の場合はA県、x年の人口が大でありかつ△年の人口が中の場合はB県かC県のことである、というものです。
x年=特大['A県']
x年=大
△年=中['B県','C県']
ここでこのディジョンツリーのx年=大は、その下の△年=中があってもB県、C県を分離できていないので、x年=大の時点でそのデータの場合はB県かC県かのうちどちらかが決定します。よって次のようなディシジョンツリーに枝刈りします。
x年=特大['A県']
x年=大['B県','C県']
このようにして先に示した人口による都道府県判定ディシジョンツリーを枝刈りすると、次のようになります。
1940年_女-1945年_女_summed_categories=特大['東京都:1']
1940年_女-1945年_女_summed_categories=大
1920年_総数-1925年_総数_summed_categories=大
1930年_総数-1935年_総数_summed_categories=大['大阪府:1']
1930年_総数-1935年_総数_summed_categories=中
1950年_総数-1955年_総数_summed_categories=大['北海道:1']
1950年_総数-1955年_総数_summed_categories=中['兵庫県:1']
1920年_総数-1925年_総数_summed_categories=中
1940年_総数-1945年_総数_summed_categories=大['愛知県:1']
1940年_総数-1945年_総数_summed_categories=中['福岡県:1']
1940年_女-1945年_女_summed_categories=中
1990年_総数-1995年_総数_summed_categories=大
1950年_総数-1955年_総数_summed_categories=中['神奈川県:1']
1950年_総数-1955年_総数_summed_categories=小['埼玉県:1']
1990年_総数-1995年_総数_summed_categories=中
1920年_総数-1925年_総数_summed_categories=中['静岡県:1']
1920年_総数-1925年_総数_summed_categories=小['千葉県:1']
1990年_総数-1995年_総数_summed_categories=小
1920年_男-1925年_男_summed_categories=中
1930年_総数-1935年_総数_summed_categories=中['新潟県:1']
1930年_総数-1935年_総数_summed_categories=小['広島県:1', '長野県:1']
1920年_男-1925年_男_summed_categories=小['福島県:1', '茨城県:1']
1940年_女-1945年_女_summed_categories=小
1920年_女-1925年_女_summed_categories=中
1920年_総数-1925年_総数_summed_categories=中['鹿児島県:1']
1920年_総数-1925年_総数_summed_categories=小['京都府:1']
1920年_女-1925年_女_summed_categories=小['三重県:1', '佐賀県:1', '和歌山県:1', '大分県:1', '奈良県:1', '宮城県:1', '宮崎県:1', '富山県:1', '山口県:1', '山形県:1', '山梨県:1', '岐阜県:1', '岡山県:1', '岩手県:1', '島根県:1', '徳島県:1', '愛媛県:1', '栃木県:1', '滋賀県:1', '熊本県:1', '石川県:1', '福井県:1', '秋田県:1', '群馬県:1', '長崎県:1', '青森県:1', '香川県:1', '高知県:1', '鳥取県:1']
1940年_女-1945年_女_summed_categories=不明['沖縄県:1']
ディシジョンツリーは、1940年代という戦争の時期の女性の人口数で最初に分岐しています。「特大」は東京都のみ、「大」には大阪府、北海道、兵庫県、愛知県、福岡県があります。これらは、1920年代という1940年代よりも以前に人口総数がどうであったのかによってさらに分岐し、おおよそどの年代でも「大」である大阪府、「大」から「中」に変化した北海道や兵庫県、そして1920年代では「中」であったのが1940年代に女性については「大」になった愛知県、福岡県と見ることができます。
同様に1940年代に女性人口が「中」であった都道府県では、そのあとの1990年代の人口総数で「大」に増えた神奈川県、埼玉県、「中」を保持している静岡県、千葉県、そして「小」に減少した新潟県、広島県、長野県、福島県、茨城県と見れます。
1940年代に女性人口が「小」であった都道府県では、鹿児島県と京都府が1920年代に女性人口が「中」であったところから減っている、それ以外は「小」のままの都道府県が多数あることが読み取れます。
以上これで、ExcelファイルをPythonでデータ分析するシリーズをすべて終了いたします。