ExcelファイルをPythonでデータ分析する
1.Excelファイルの読み込み - 2.グラフ - 3.度数分布 - 4.ランキングチャート - 5.相関 - 6.ディシジョンツリー
「ExcelファイルをPythonでデータ分析する」は上のような一連の記事になっており、2~6までは事前に1.Excelファイルの読み込みと事前処理が行われていることを前提としています。
都道府県ごとの相関
相関係数とは2つのデータの関係性を示す指標です。例えば片方のデータが徐々に増えるデータでもう一方が同じように増える場合、正の相関があると言います。逆に片方が増えていくときにもう一方が減っていくような場合には負の相関があると言います。数値にすると1.0から-1.0までの値を取り、1.0に近いほど正の相関があり、-1では負の相関、0の値は無相関といいます。
各年の人口データでいうと、例えばある都道府県を1つ選び、その都道府県との相関係数を他の都道府県についてすべて求めると、類似した人口変化をしている都道府県とそうではないところが明らかとなります。
以下の例では、新潟県を対象としてその新潟県と相関係数の高い、つまり同じように人口が増加/減少している都道府県と、相関係数の低い、つまり新潟県の人口変化とは異なる動きになっている都道府県を抽出してみます。相関係数は、pandas.DataFrame.corrを用いて計算します。
以下の例では人口を0から1の間にスケールして描画しています。グラフの縦軸の最小値が0、最大値が1になっていることに注目してください。なぜ人口を0~1の間にスケールするのかについては、その理由はこの記事の下の方で説明しています。
グラフは、相関係数の高い都道府県名と低い都道府県名を配列にしたdata変数をループし、それぞれに対してmatplotlib.axes.plotなどを用いて描画しています。
import matplotlib.pyplot as plt
import japanize_matplotlib
# "全国"を除外して都道府県一覧を作成する。
prefs = list(filter(lambda l:"全国" not in l,df0.index))
# 年一覧を作成する
years = list(map(lambda l:re.findall(r"(.*)_.*",l)[0],
filter(lambda l:"総数" in l,df0.columns)))
# 男女データを除外して人口総数のみで相関係数を求める。
df1 = df0.loc[prefs,filter(lambda l:"総数" in l,df0.columns)]
corr = df1.transpose().corr()
# 新潟県の相関係数を抽出する。
pref = "新潟県"
rank = 5 # グラフ描画する類似/非類似の都道府県数
corr = corr.loc[pref,:].sort_values()
data = {
f"{pref}と類似した人口変化の都道府県":corr.keys()[-rank-1:],
f"{pref}と似ていない人口変化の都道府県":np.append(np.array(corr.keys()[:rank]),[pref]),
}
# グラフ描画用に、人口を0~1の間にスケールする。
maxes = df1.max(axis=1)
mins = df1.min(axis=1)
df1 = df1.apply(lambda x:(x-mins[x.name])/(maxes[x.name]-mins[x.name]),axis="columns")
# 相関係数の高い類似したデータと、相関係数の低い似ていないデータをそれぞれ描画する。
for label in data:
fig,ax = plt.subplots(figsize=(16,8))
for pref in data[label]:
ax.plot(df1.loc[pref,filter(lambda l:"総数" in l,df0.columns)].set_axis(years))
ax.grid()
ax.set_title(label)
ax.set_ylabel("人口比(期間中の最大人口から最小人口までの1~0の間にスケールしたもの)")
# ax.set_ylabel("人口総数") # 0-1に人口をスケールしないときの縦軸ラベル
ax.legend(list(map(lambda l:f"{l} ({corr[l]:.2f})",data[label])),bbox_to_anchor=(1.14,1))
plt.show()
上記の「新潟県」を比較対象とした相関係数の高い/低い都道府県の描画では、次のような2つのグラフが描画されます。
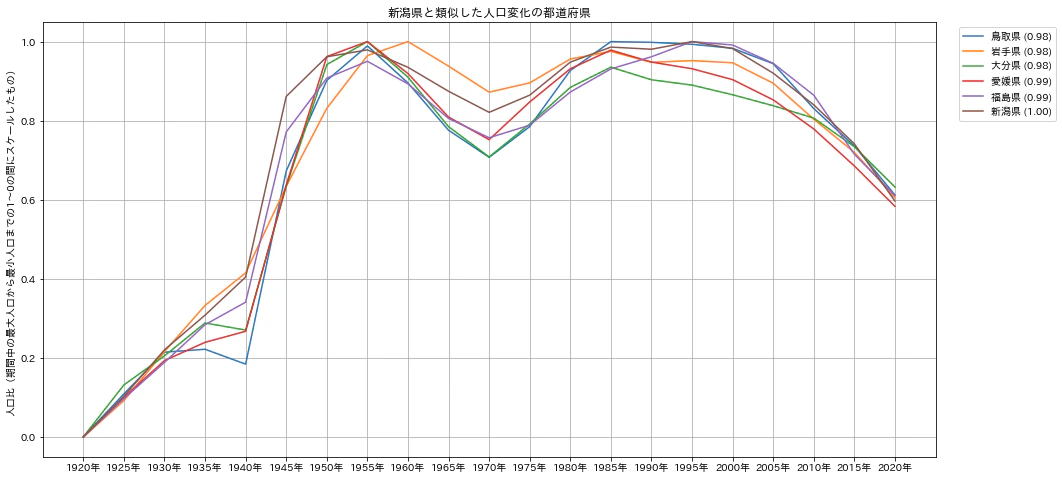
新潟県と類似した人口変化を示す5つの都道府県です。縦軸は計測期間の1920年から2020年までの最小人口を0、最大人口を1としたときの各年の人口比率です。凡例の都道府県名の横の数字は、新潟県との相関係数を示しています。
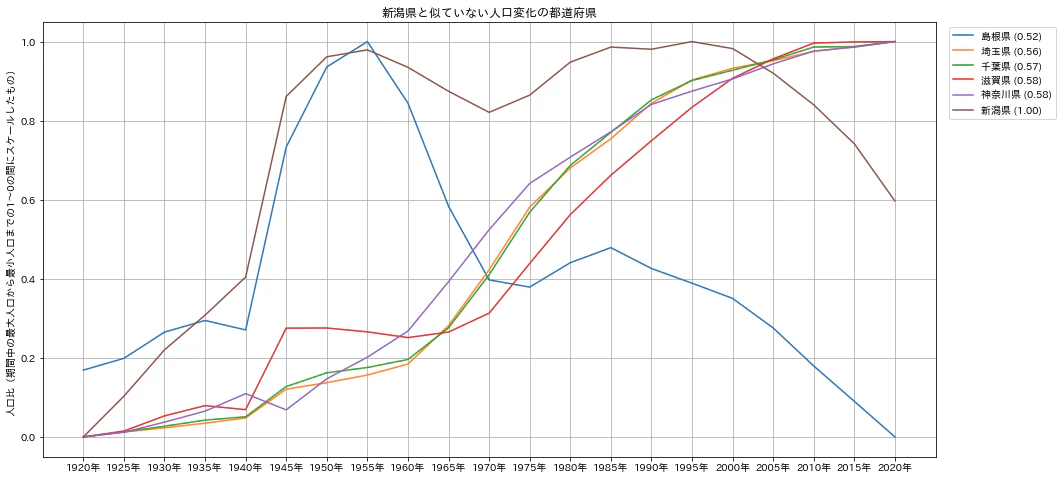
上記は、新潟県と相関係数の低い都道府県です。島根県以外は、東京都、大阪府近辺の2020年に至るまで人口が増え続けている都道府県です。また相関係数とは関係がありませんが、島根県は1920年よりも2020年の方が人口が少ないことも分かります。
グラフ描画用に人口を0~1の間にスケールする
相関係数は、人口数の大小ではなく「変化」を計測しています。大小ではなく変化とは、人口のそのものの数値ではなく前回の測定に比べて○○名増えた、××名減ったといったプラスマイナスだけを見るということです。これは、人口の多い都道府県、少ない都道府県といった分類に依存せずに変化が同じ都道府県があるのではないか、という考えからくるものです。
この考えに基づいて相関係数を求めても、グラフ描画するときに人口の数値そのものを描画すると次のようになります。
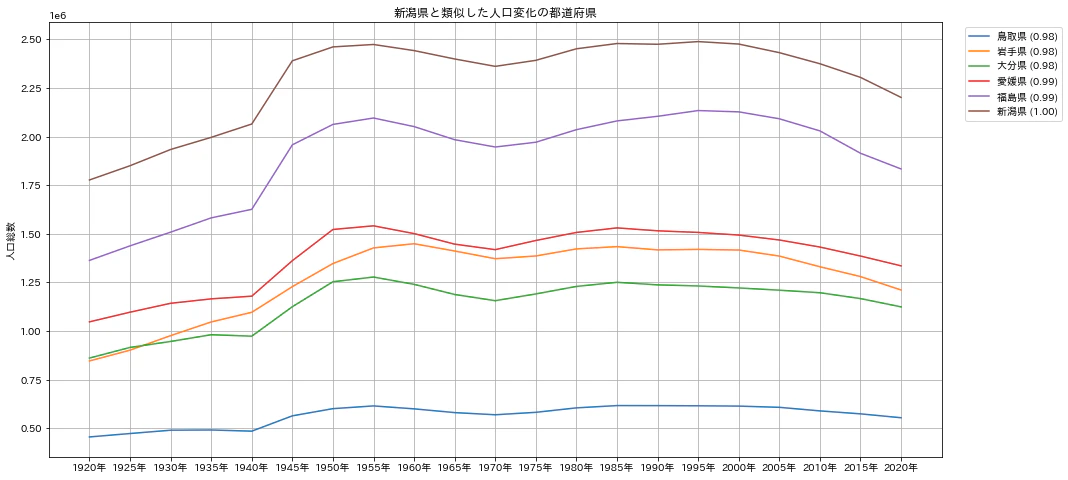
このグラフの場合、先に示した0-1にスケールしたグラフに比べて変化を読み取りにくいところがあります。ちなみにこのグラフは、上記のPythonプログラムの、以下の部分をコメントアウトすると表示することができます。
df1 = df1.apply(lambda x:(x-mins[x.name])/(maxes[x.name]-mins[x.name]),axis="columns")
データを0-1の間にスケールするとは、次の式によって各都道府県の最大、最小人口から人口比率の数値を計算します。
0-1にスケールされた人口 = \frac{人口数 - 最小人口数}{最大人口数 - 最小人口数}
0-1にスケールするとは、人口の測定期間の中で最大の人口になった箇所が1、最小になったところが0となるという意味です。このようなデータの正規化にはいろいろな手法がありますが、今回は0-1の間にスケールする方法を取りました。
人口の総数は異なるけど変化が似ている例
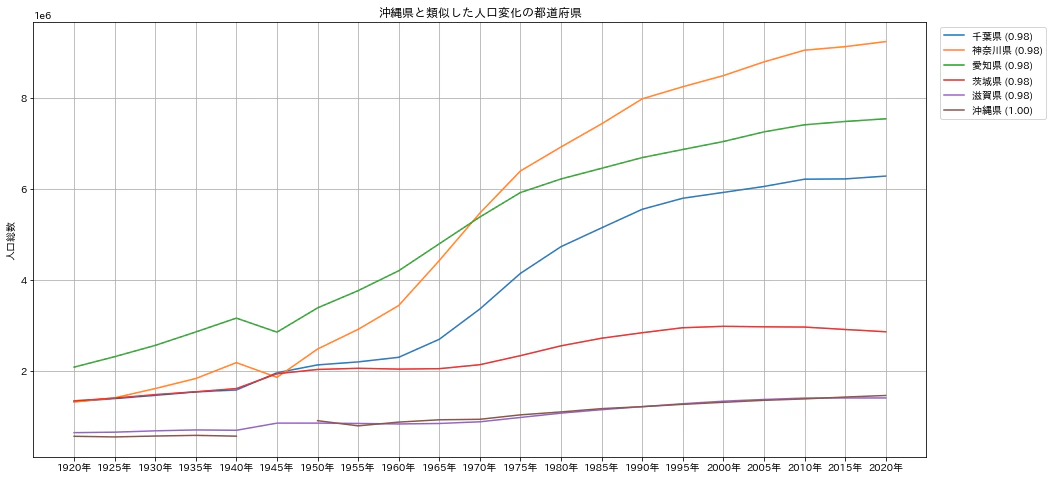
沖縄県を対象として相関係数の高い、類似した変化をしている都道府県を5つ表示してみます。次のグラフは縦軸を人口総数としたときのグラフです。沖縄県は神奈川県、千葉県、愛知県に比べて人口総数は大きく異なっているにもかかわらず相関係数は高い数値となっています。
これを人口を0-1にスケールしたグラフで見てみます。
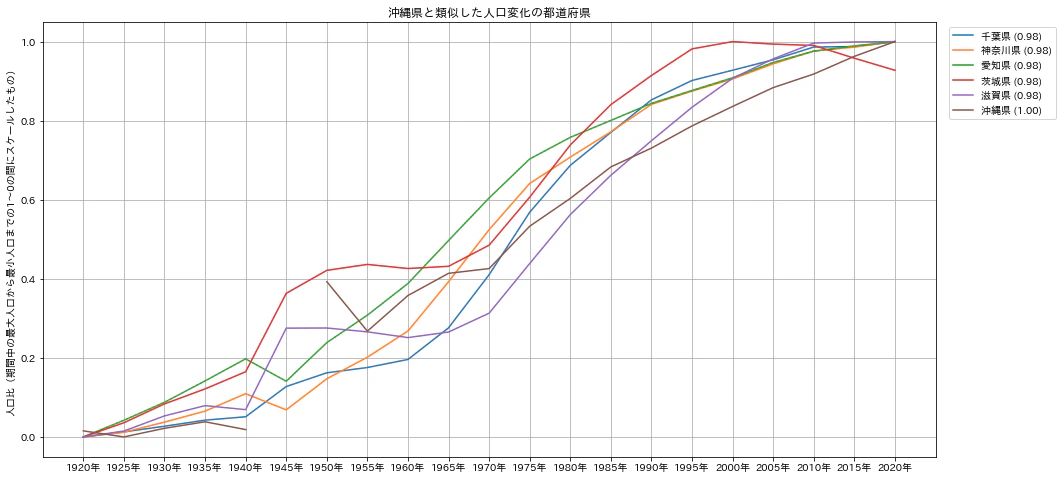
人口が増加し続けているという意味で沖縄県は、人口の多い都道府県である神奈川県等と似ているということが見て取れると思います。