ExcelファイルをPythonでデータ分析する
1.Excelファイルの読み込み - 2.グラフ - 3.度数分布 - 4.ランキングチャート - 5.相関 - 6.ディシジョンツリー
「ExcelファイルをPythonでデータ分析する」は上のような一連の記事になっており、2~6までは事前に1.Excelファイルの読み込みと事前処理が行われていることを前提としています。
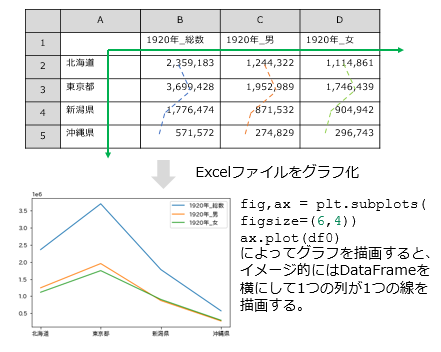
DataFrameをそのままプロットする
matplotlib.pyplotおよびjapanese_matplotlibをインポート後に、plt.subplotsによってグラフ領域を作成し、matploblib.axes.plotをExcelファイルから作成したdf0という名前のDataFrameを引数として呼び出します。そして最後に描画を実施するplt.show()を呼び出します。
import matplotlib.pyplot as plt
import japanize_matplotlib
fig,ax = plt.subplots(figsize=(12,8))
ax.plot(df0)
plt.show()
グラフは以下のように描画されます。
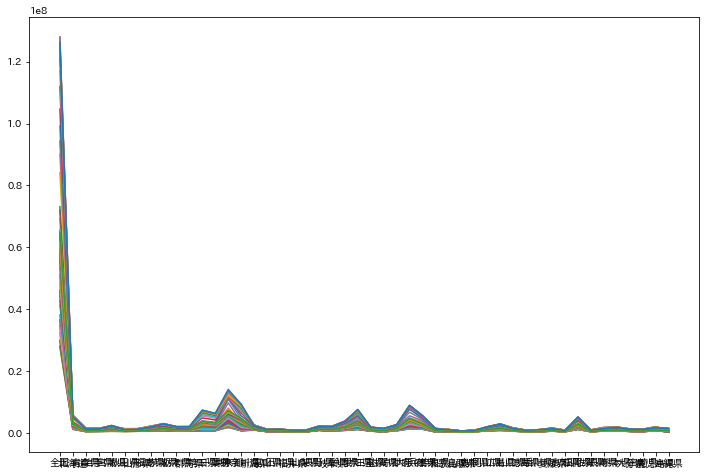
横軸はDataFrameの行で縦軸は人口であり、DataFrameの各列である調査年ごとに1本の折れ線グラフが書かれています。全国と都道府県を同じ図に描画しているのでスケールが異なりよく分かりません。以下ではそれぞれ見たいデータを抽出しながら、またグラフタイトルなどの装飾を行いながらグラフを描画していきます。
因みにpandas.DataFrameをそのままグラフ化するとは、次のようにDataFrameのデータである行が横軸、1つの列が1つの折れ線を作るというイメージで描画されます。言い方を変えると、グラフ化したいデータは1つのグラフに描画する線の数だけExcelで列を作り、データを行として追加していけば良いことになります。
人口グラフ
全国の人口グラフ
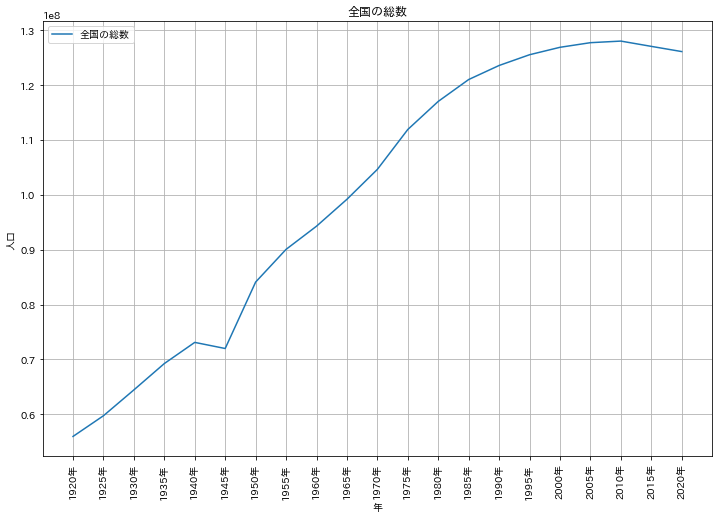
まず手始めに、全国の総数を折れ線グラフで描画します。描画に必要なmatplotlib.pyplot、および日本語でキャプション等が記述できるようにするjapanese_matplotlibをインポートします。最初に、年の一覧を作成しておきます。df0のDataFrameは、年ごとに"総数","男","女"の3つのデータがあるため、まず"総数"のみを取り出し、正規表現によって年の部分だけを抽出して一覧を作成しています。
図の描画はplt.subplotsによって図の領域になるfig変数、その中の1つのグラフを表すax変数を作成し、DataFrameのlocによって抽出されたデータを引数にax.plotを呼び出します。後はそのaxに対してグラフの装飾を行い、最後にplt.show()によって実際にグラフが出力されます。
# グラフを描画する matplotlib.pyplotと、そこで日本語表示を可能とする japanize_matplotlibをインポートする。
import matplotlib.pyplot as plt
import japanize_matplotlib
# DataFrameにある年一覧を作成する。
years = list(map(lambda l:re.findall(r"(.*)_.*",l)[0],
filter(lambda l:"総数" in l,df0.columns)))
# 図の領域を作成する。figsizeは、(横,縦)をインチで指定する。
fig,ax = plt.subplots(figsize=(12,8))
# DataFrameの行を「全国」、列を「総数」のみとしたデータとし、グラフを描画する。
ax.plot(df0.loc["全国",filter(lambda l: "総数" in l,df0.columns)])
# キャプションを表示する。
ax.set_title("全国の総数")
# グリッドを描画する。
ax.grid()
# x軸のメモリを「年」にする。
ax.set_xticks([i for i in range(len(years))])
ax.set_xticklabels(years,rotation=90)
# 凡例を描画する。
ax.legend(["全国の総数"])
# x軸、y軸のラベルを描画する。
ax.set_xlabel("年")
ax.set_ylabel("人口")
# グラフを出力する
plt.show()
上記のプログラムで次のようなグラフが描画されます。
都道府県ごとの人口総数、男女別人口数のグラフ
グラフを表示したい都道府県を予め配列にし、後でその配列でループしながらグラフを描画していきます。
上の全国の例と同じように、年の一覧を作成しておきます。
グラフ描画は、plt.subplotsによって描画領域を作成し、その領域に"男","女"の2データを表示するために2回分のax.plotを行います。その後はキャプションなどの図の装飾をしてplt.showで実際に図が出力されます。
import matplotlib.pyplot as plt
import japanize_matplotlib
# グラフにする都道府県名を配列にしておく。
prefs = ["新潟県","東京都","沖縄県"]
# 横軸になる年一覧を作成する。
years = list(map(lambda l:re.findall(r"(.*)_.*",l)[0],
filter(lambda l:"総数" in l,df0.columns)))
# 都道府県一覧でループする。
for pref in prefs:
fig,ax = plt.subplots(figsize=(6,4))
tp = ["男","女"]
for s in tp:
# locによってデータを抽出し、set_axisによって列名を years 変数の値でセットします。
# set_axisを行わないと、列名が"1920年_総数", "1920年_男"のように異なるデータとなるため、
# グラフに描画したときに2つのグラフがx軸の位置に重ならないになってしまいます。
ax.plot(df0.loc[pref,filter(lambda l:s in l,df0.columns)].set_axis(years))
ax.set_title(f"{pref}_{','.join(tp)}")
ax.grid()
ax.set_xticks([i for i in range(len(years))])
ax.set_xticklabels(years,rotation=90)
ax.set_ylabel("人口")
ax.legend(tp)
plt.show()
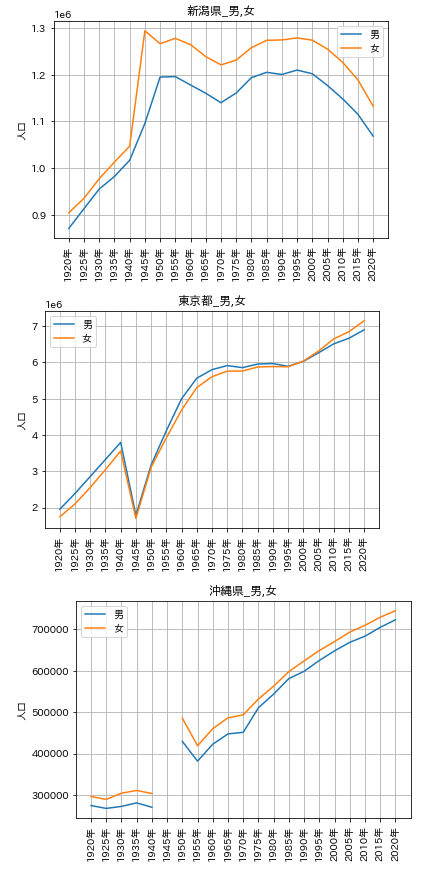
沖縄県には欠損値(データが存在しないところ)があり、グラフのその部分が切れています。
1920年の都道府県ごとの男女の人口棒グラフ
これまでは全国や1つの都道府県を指定して各年の変化を見てきましたが、ここでは1つの年を指定して各都道府県の人口を棒グラフをして表示してみます。
以下の例は1920年の男女別人口棒グラフです。matplotlib.axes.barを用いて棒グラフを描画しています。
import matplotlib.pyplot as plt
import japanize_matplotlib
import numpy as np
# グラフを表示する年
year = "1920年"
# 全国のデータを除外する。
prefs = list(filter(lambda l:"全国" not in l,df0.index))
# グラフの幅(グラフの隣の県までの幅が1のところ、男女2つの棒が占める幅)
width = 0.35
# 都道府県の通し番号を作成しておく。
x = np.arange(len(prefs))
# グラフの描画領域を作成する。
fig,ax = plt.subplots(figsize=(16,4))
# 男女データをそれぞれ描画する。
for i,s in enumerate(["男","女"]):
# 棒グラフの棒のx軸の位置を通し番号のxからwidthの半分だけ左右にずらして表示する。
ax.bar(x+((i%2)*2-1)*width/2,df0.loc[prefs,year+"_"+s],width,label=s)
# タイトル、x軸メモリ、y軸ラベル、凡例、グリッドを表示する。
ax.set_title(year+"の人口(男女)")
ax.set_xticks(x)
ax.set_xticklabels(prefs,rotation=90)
ax.set_ylabel("人口")
ax.legend()
ax.grid(axis="y")
plt.show()
実行すると次のように表示されます。
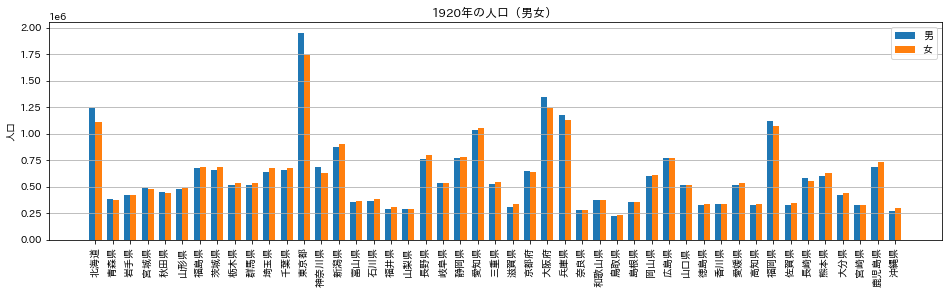
1920年時点では人口の多い上位5都道府県(東京都、大阪府、北海道、兵庫県、福岡県)はいずれも女性より男性の方が多いです。だたその次ぐらいに位置している愛知県、新潟県などは女性の方が多くなっています。
ラベルデータの描画
ラベルデータとは名義尺度ともよばれ、数値ではなく文字として表されるデータのことです。ここでは、人口データという数値データではなくラベルデータを描画する方法について例を示したいと思います。
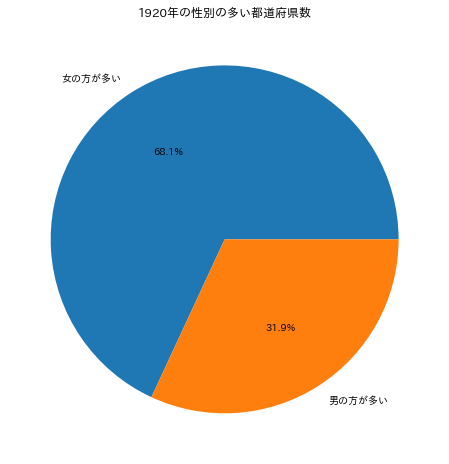
ラベルデータとして、各都道府県の人口の多い性別を作成したいと思います。例えば1920年の東京都では男性の人口の方が多いので「男」というデータになります。そしてグラフではこの男が多い都道府県数と女が多い都道府県数を円グラフとして描画したいと思います。
以下のプログラムは全国のデータを除外したdf1に対してyear変数によって指定された年の男女人口の差分を取り、そのプラスマイナスから”同じ”,"男","女"といった人口の多い性別を持ったデータを作成いたします。ここで各都道府県の男女どちらの人口が多いかが明らかとなります。
# グラフ化したい年を指定します。
year = "1920年"
# 全国のデータを除外する。
df1 = df0.loc[filter(lambda l:l not in "全国",df0.index),:]
# 指定された年の男の人口数から女の人口数を引いたデータを作り、そのプラスマイナスによって"同じ","男","女"の3パターンの文字になるデータを作成します。
data = (df1.loc[:,f"{year}_男"]-df1.loc[:,f"{year}_女"]).map(lambda x:"男女の数は同じ" if x==0 else "男の方が多い" if x>0 else "女の方が多い")
print(data.head())
実行すると、次のようなpandas.Series型のラベルデータが作成されます。
北海道 男の方が多い
青森県 男の方が多い
岩手県 女の方が多い
宮城県 男の方が多い
秋田県 男の方が多い
dtype: object
このラベルデータを円グラフによって描画したいと思います。男が多い都道府県と女が多いのの割合を示す円グラフです。まず各都道府県の"同じ","男","女"のデータの個数をpandas.Series.value_countsによって求めます。そしてその結果をpandas.Series.sort_indexによってソートします。ソートを呼び出している理由は、円グラフを1つだけ作成する場合には関係があまりないのですけど、複数年から複数の円グラフを描画するときに男と女の割合が同じ色で表示されるようにデータの名前でソートして常に同じ順番とするためです。
そしてmatplotlib.pyplot.subplotsによって描画領域を作成し、matplotlib.axes.pieによって円グラフを描画します。
import matplotlib.pyplot as plt
import japanize_matplotlib
# pandas.Series.value_countsを用いてデータの個数を求めます。
counts = data.value_counts().sort_index()
# グラフ描画領域を作成します。
fig,ax = plt.subplots(figsize=(16,8))
# 円グラフを描画します。
ax.pie(counts,labels=counts.index,autopct="%1.1f%%")
# 指定された年を含めた文字をグラフタイトルとして設定します。
ax.set_title(f"{year}の性別の多い都道府県数")
# グラフを描画します。
plt.show()
実行すると以下のような円グラフが描画されます。
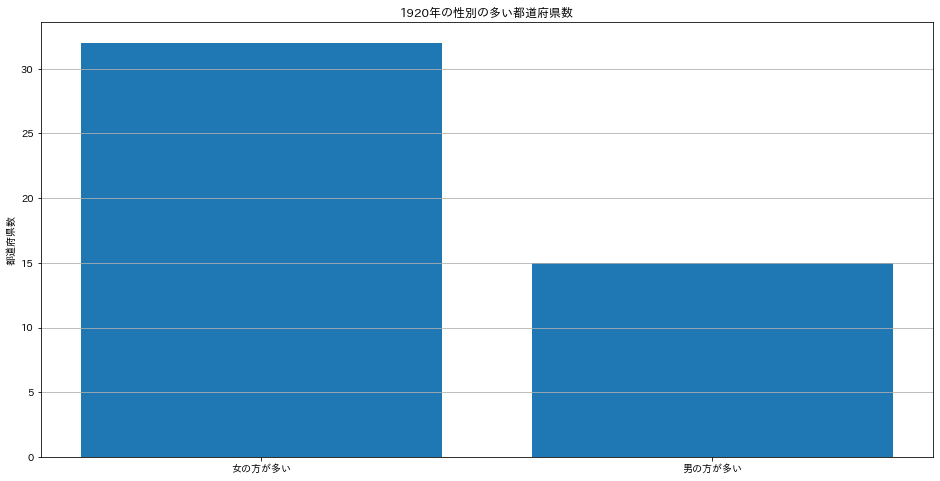
次の棒グラフを描画してみます。先ほどの円グラフと同様にvalue_countsによって個数を求めインデックスでソートします。matploblib.axes.barを使用してx軸にcounts.indexの各都道府県名、y軸にcountsを指定します。今回はグラフタイトル以外にもy軸のラベル、y軸のグリッドも表示しています。
import matplotlib.pyplot as plt
import japanize_matplotlib
# pandas.Series.value_countsを用いてデータの個数を求めます。
counts = data.value_counts().sort_index()
# グラフ描画領域を作成します。
fig,ax = plt.subplots(figsize=(16,8))
# 棒グラフを描画します。
ax.bar(counts.index,counts)
# 指定された年を含めた文字をグラフタイトルとして設定します。
ax.set_title(f"{year}の性別の多い都道府県数")
ax.set_ylabel("都道府県数")
ax.grid(axis="y")
# グラフを描画します。
plt.show()
実行すると次のような棒グラフが描画されます。
参考
pandas.DataFrame API
pandas.Series API
NumPy API
matplotlib API
早く知っておきたかったmatplotlibの基礎知識、あるいは見た目の調整が捗るArtistの話