はじめに
IBM Cloud(Public)上のIaaS環境(Linux)にアクセスする際は、VPN接続をしてteratermなどでssh接続して操作することになると思います。
そのLinux上にファイルを転送するにはscpが使えますが、VPN経由のアクセスのせいか、転送速度が遅くてサイズが大きいor大量のファイル転送の場合やってられません。
そこで、IBM Cloud Object Storage(ICOS)を介したファイル転送を試してみました。
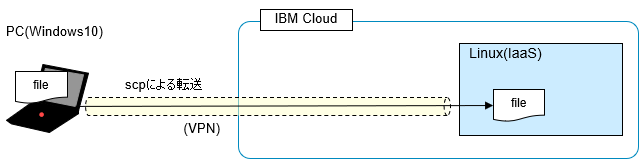
こういう経路の代わりに...
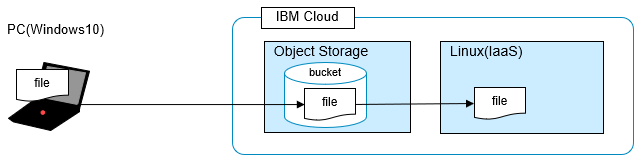
こういう経路でファイルを転送するイメージです。
(PCから一旦Object Storageにファイルを置いて、次にLinuxからファイルを取得)
ワンクッションはさみますが、こっちの方が5倍くらい早くなりました(転送速度については末尾のセクション参照)。
もちろん逆方向の転送でも同様に利用できます。
Windows/Linuxそれぞれ、Object Storageに対してファイルをアップロード/ダウンロードするのにCLIが使えます。IBM Cloud Object Storage専用のCLIもあるようですが、AWS CLIも使えるようで、なんとなくそっちの方が使いやすそうだったのでここではAWS CLIを使ってObject Storageにアクセスすることにします。
参考:
IBM Cloud CLI の使用
AWS CLI の使用
AWS の公式コマンド・ライン・インターフェースは、IBM COS S3 API と互換性があります。
ちなみに、ここでは取り上げませんが、MSP360 backup/MSP360 ExplorerというGUIのツールを使ってアップロード/ダウンロードすることもできるようです。
IBM Cloud Object Storage(ICOS)を使ってPCファイルのバックアップ
IBM Cloud Object Storage(ICOS)を使ってPCファイルのバックアップ2
(2つめの方がよさそう)
※追記
上のGUIのツールの2つめ「MSP 360 Explorer」(CloudBerry Explror)というのも使ってみましたが、そちらはICOSにアップロードできる1ファイルサイズの上限は5GBまでのようです。5GB以上のファイルを送信しようとするとエラーになりました(Freeware版の制約のようです)。ちなみにダウンロード(ICOS=>PC)の場合は5GBの制約は無さそうです(6GBのファイルのダウンロードはできました)。
当記事で記載しているAWS CLIの方法では、約11GBのファイル転送が行えることは確認済みです。恐らくCLIだと1ファイル5TBまでは許容されると思われます。
参考:
大きなオブジェクトの保管
AWS CLI を使用して、Amazon S3 にファイルをマルチパートアップロードする方法を教えてください。
Amazon S3 マルチパートアップロードの制限
関連記事
IBM Cloud Object Storageを介したファイル転送
IBM Cloud Object Storageを介したファイル転送 - その2(curl編)
IBM Cloud Object Storageの作成
インスタンス作成
IBM CloudのカタログからObject Storageを選択して新規作成します。
ライトプランだと最大25GB/月くらいまで無料で利用できるようです。
これで作成ボタンを押します。
バケットの作成
バケットという器みたいなもの?ディレクトリみたいなもの?を作成する必要があるようです。
作成されたObject Storageのインスタンスを開いて、左側のメニューからバケットを選択し、バケットの作成をクリック
カスタム・バケットを選択
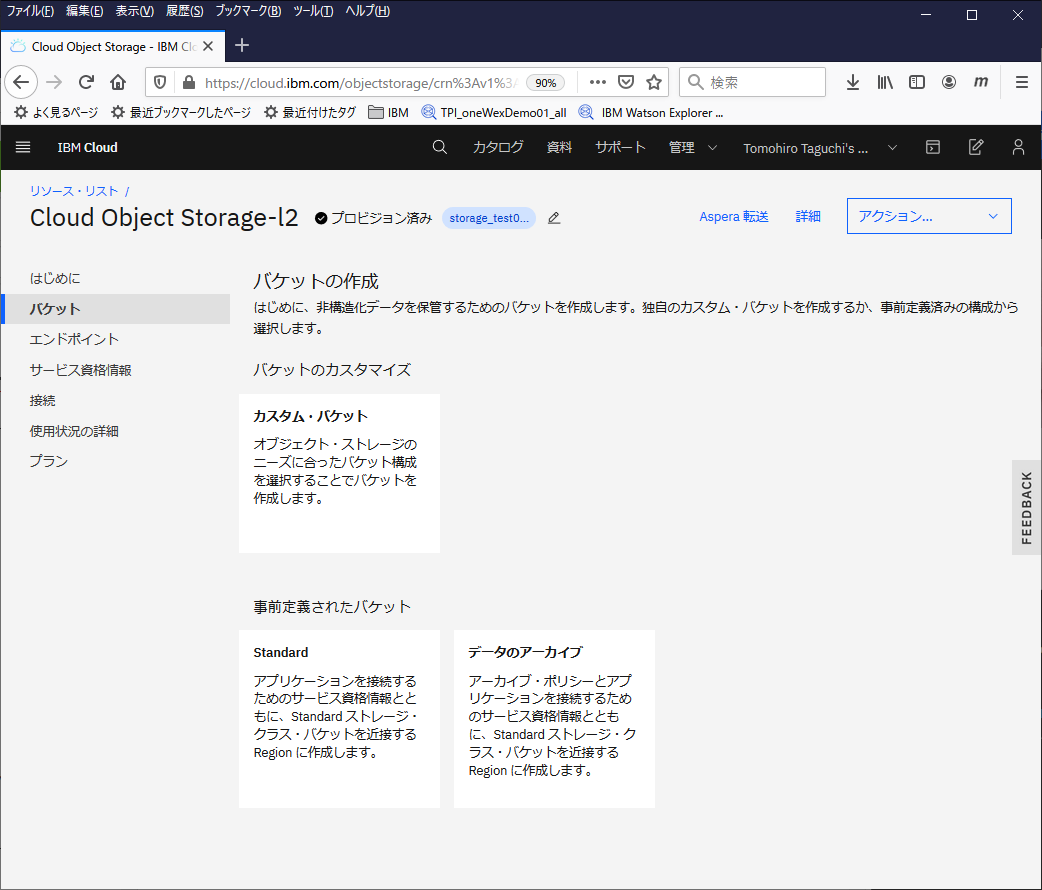
名前を指定して、ストレージクラスはStandardを選択して作成
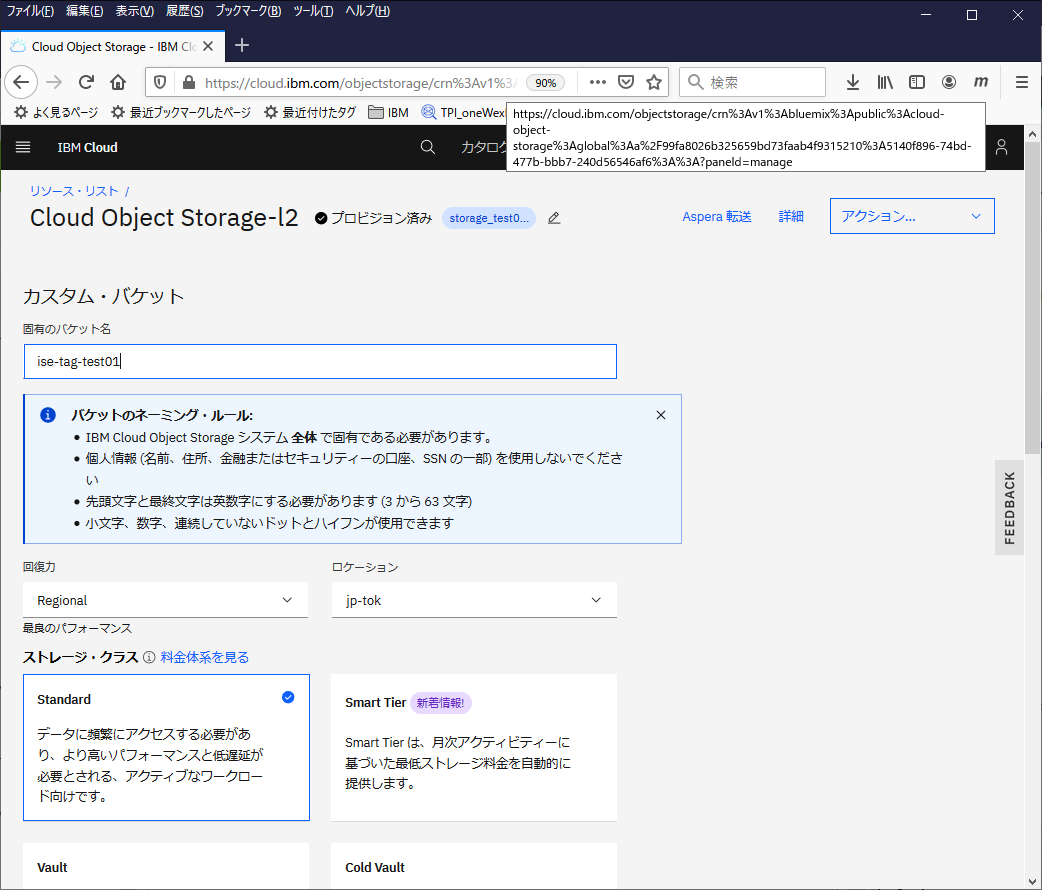
エンドポイント情報の確認
以下のいずれかの方法で、エンドポイント情報を確認しておきます。
(1) 作成したバケットを選択し、左側のメニューから構成を選択し、プライベートとパブリックのURLを確認ます。
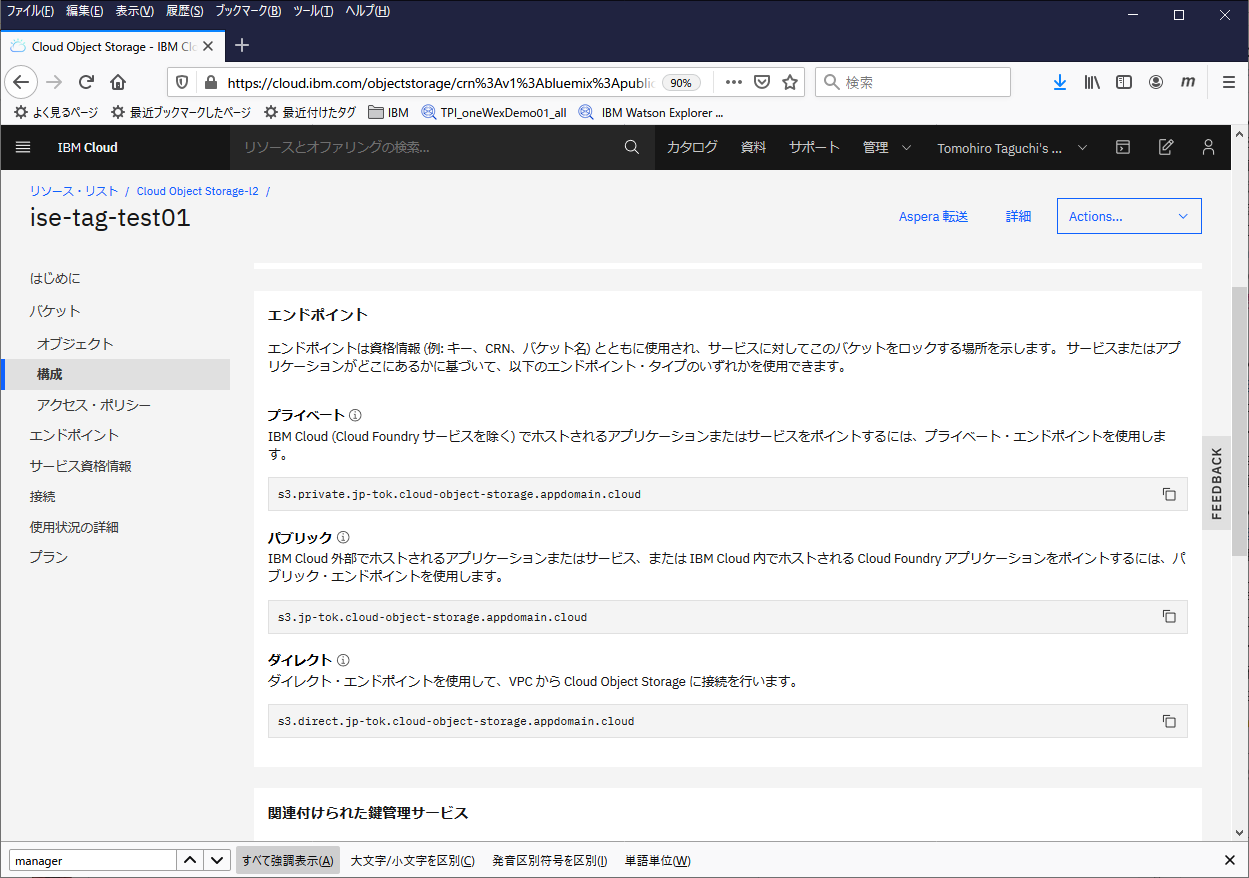
(2) もしくは、左側のメニューからエンドポイントを選択し、エンドポイント情報を確認しておきます。
回復力とロケーションの設定は、バケット作成時のものと合わせ、表示されるプライベートとパブリックのURLを確認ます。
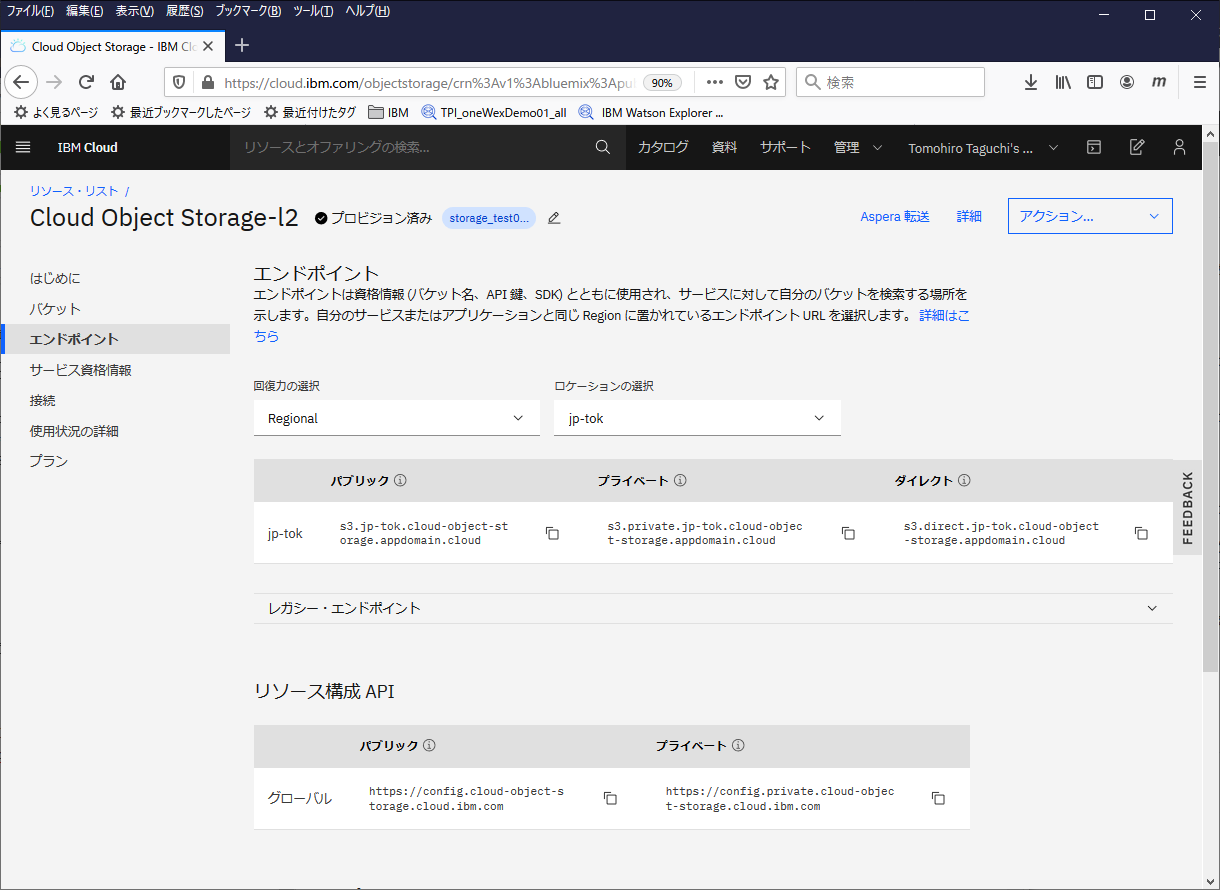
Object Storageにアクセスする際に必要になるのでメモっておきます。
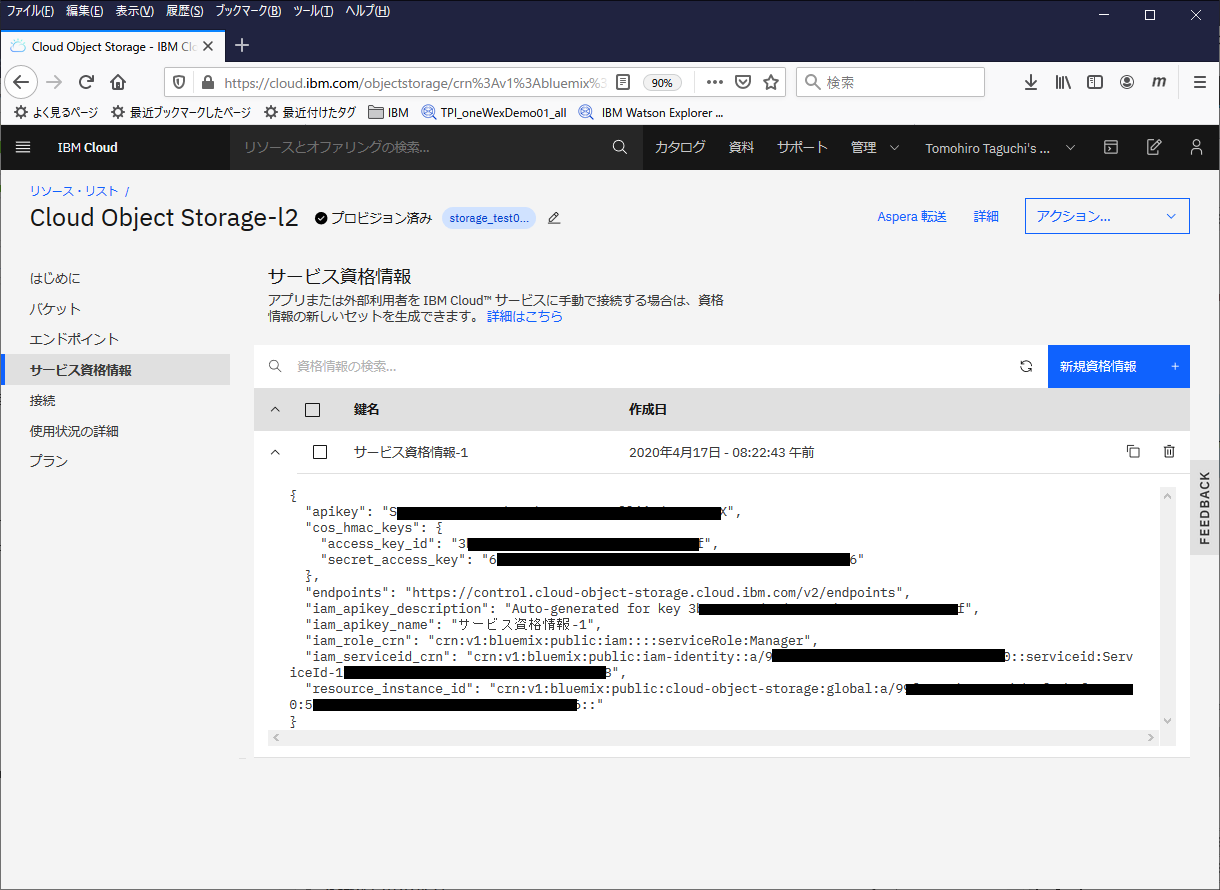
サービス資格情報の設定
左側のメニューからサービス資格情報を選択し、新規資格情報をクリック
役割:Manager, HMAC 資格情報を含めるをONにして追加
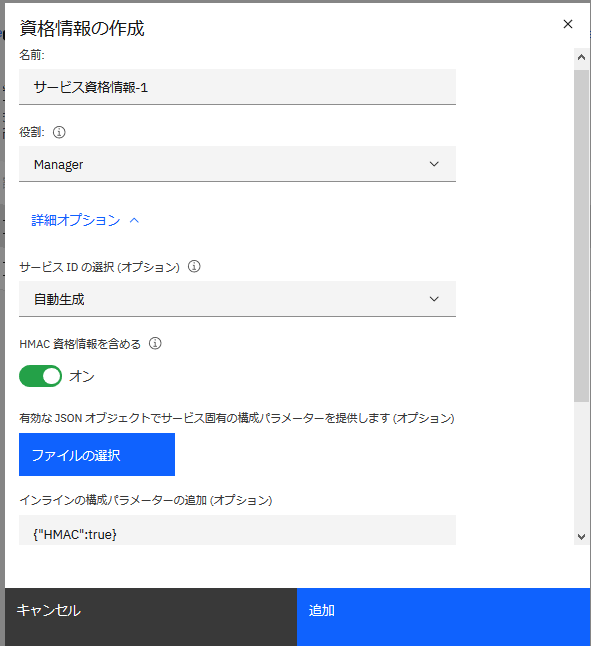
作成された資格情報を確認します。この情報はこのObject Storageにアクセスする際に必要になるのでメモっておきます。
PC(Windows10)上の操作
WindowsへのAWS CLIの導入
参考: Windows での AWS CLI バージョン 2 のインストール
基本、上の手順に従えばよいです。インストーラーをダウンロードして実行し、適当なフォルダ選択するくらい。なのでここでは手順は省略。
で、awsコマンドが使えるようになります。
c:\y\FileTransfer>aws --version
aws-cli/2.0.8 Python/3.7.5 Windows/10 botocore/2.0.0dev12
aws接続構成
参考:
AWS CLI の使用
AWS CLI のかんたん設定
上の記述に倣って、接続用の構成を行います。
c:\>aws configure
AWS Access Key ID [None]: 3xxxxxxxxxxf
AWS Secret Access Key [None]: 6xxxxxxxxxxxxxxxxx6
Default region name [None]: jp-tok-standard
Default output format [None]: json
AWS Access Key IDには、上で作成した資格情報のaccess_key_idの値を設定します。
AWS Secret Access Key には、上で作成した資格情報のsecret_access_keyの値を設定します。
Default region nameには、以下のガイドから、ロケーションとストレージクラスの組み合わせから判断します。
参考: ストレージ・クラスの使用
ここで作成したのは、ロケーションが日本で、ストレージクラスはStandardなので、jp-tok-standardを指定します。
Default output formatはjsonを指定します。
これで接続に必要な設定が完了です。設定内容は、以下の2つのファイルに保持されます。
~/.aws/credentials
~/.aws/config
Object Storageへのアクセス
aws --endpoint-url {endpoint} s3 <command> という形で操作ができます。command としては、ls, cp, mv, rmなどが使えます。
endpointは上で確認したものを使います。
パブリック: s3.jp-tok.cloud-object-storage.appdomain.cloud
プライベート: s3.private.jp-tok.cloud-object-storage.appdomain.cloud
IBM Cloud内から利用する場合はプライベートの方を使います(有償オプションで使っていたとしてもプライベートの方だと課金対象から外れるらしい。今回は無料枠の範囲内で使っているから関係ないけど、)。
今回は自PC上からのアクセスなので、パブリックのエンドポイントを使います。
まず、Object Storage上のバケットを確認してみます。
c:\>aws --endpoint-url http://s3.jp-tok.cloud-object-storage.appdomain.cloud s3 ls
2020-04-17 08:42:42 ise-tag-test01
バケットがリストされました。ここに、ファイルを転送したいと思います。
test.txtというファイルを作って、それをアップロードします。
c:\y\FileTransfer>aws --endpoint-url http://s3.jp-tok.cloud-object-storage.appdomain.cloud s3 cp test.txt s3://ise-tag-test01/
upload: .\test.txt to s3://ise-tag-test01/test.txt
アップロードされました!
Linux on IBM Cloud上の操作
LinuxへのAWS CLIの導入
参考: Linux での AWS CLI バージョン 2 のインストール
ここで利用しているLinuxはRHELです。
curlでインストーラー(zipファイル)をダウンロード、unzip、インストーラーを実行、でOKです。
[tomotagjp@zoselk ~/Inst_Image/AWSCLI]$ curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 31.1M 100 31.1M 0 0 16.9M 0 0:00:01 0:00:01 --:--:-- 16.9M
[tomotagjp@zoselk ~/Inst_Image/AWSCLI]$ ls
awscliv2.zip
[tomotagjp@zoselk ~/Inst_Image/AWSCLI]$ unzip awscliv2.zip
[tomotagjp@zoselk ~/Inst_Image/AWSCLI]$ sudo ./aws/install
You can now run: /usr/local/bin/aws --version
これでawsコマンドが使えるようになります。
[tomotagjp@zoselk ~]$ sudo /usr/local/bin/aws --version
aws-cli/2.0.8 Python/3.7.3 Linux/3.10.0-1062.1.2.el7.x86_64 botocore/2.0.0dev12
aws接続構成
参考:
AWS CLI の使用
AWS CLI のかんたん設定
やることはWindowsの時と同じです。上の記述に倣って、接続用の構成を行います。
[tomotagjp@zoselk ~]$ sudo /usr/local/bin/aws configure
AWS Access Key ID [None]: 3xxxxxxxxxxf
AWS Secret Access Key [None]: 6xxxxxxxxxxxxxxxxx6
Default region name [None]: jp-tok-standard
Default output format [None]: json
Object Storageへのアクセス
先にWindowsからObject Storageにファイルを転送したので、ここでは、Object StorageにあるファイルをLinuxにダウンロードしてみます。
利用するコマンドは同様ですが、こちらはIBM Cloud上のIaaSなので、エンドポイントはプライベートのものを使います。
まず、lsでObject Storageの中をのぞいてみます。
[tomotagjp@zoselk ~]$ sudo /usr/local/bin/aws --endpoint-url http://s3.private.jp-tok.cloud-object-storage.appdomain.cloud s3 ls
2020-04-17 08:42:42 ise-tag-test01
[tomotagjp@zoselk ~]$ sudo /usr/local/bin/aws --endpoint-url http://s3.private.jp-tok.cloud-object-storage.appdomain.cloud s3 ls ise-tag-test01
2020-04-17 18:56:10 4 test.txt
test.txtというファイルがあるのが確認できます。今度はこいつをmvでLinux上に落とします。(mvだとObject Storage上のファイルは消える)
[tomotagjp@zoselk ~]$ sudo /usr/local/bin/aws --endpoint-url http://s3.private.jp-tok.cloud-object-storage.appdomain.cloud s3 mv s3://ise-tag-test01/test.txt ./
move: s3://ise-tag-test01/test.txt to ./test.txt
[tomotagjp@zoselk ~]$ ls -la | grep test
-rw-------. 1 root root 4 Apr 17 18:56 test.txt
[tomotagjp@zoselk ~]$ sudo /usr/local/bin/aws --endpoint-url http://s3.private.jp-tok.cloud-object-storage.appdomain.cloud s3 ls ise-tag-test01
[tomotagjp@zoselk ~]$
Linux上にファイルがダウンロードされて、Object Storageからはファイルが消えたことが確認できました。
応用編
さて、上の一連の流れで一通り転送できることが分かりましたが、(1)Windows側でファイルをObjectStorageにおいて、(2)Linux側で取ってくる、という2ステップあるので、何度も転送をする必要がある場合はちょっと鬱陶しいです。
そこで、スクリプト作っておいてそれを1回でできるようにします。
方針としては、(2)用のスクリプトをLinux側に作っておいて(1)実行後にWindows側からssh経由で実行する、という感じです。
なので、ssh公開鍵認証の設定をしておくのがよいでしょう。また、できればsudoでawsコマンドはパスワード入力無しにできるとベター。できなければパスワード打たないといけないのですが、その辺は環境次第かと。
Linux側準備
まず、Linuxユーザーのホームに以下のようなデータダウンロード用シェルスクリプトを作成しておきます。
#!/bin/bash
targetDir=$1
endpoint=http://s3.private.jp-tok.cloud-object-storage.appdomain.cloud
bucket=ise-tag-test01
sudo /usr/local/bin/aws --endpoint-url ${endpoint} s3 mv s3://${bucket}/ ${targetDir} --recursive
ここではs3のコマンドとしてmvを使用しているので、ファイル取得後Object Storage上のデータは消える想定です。
また、データ転送先のディレクトリ ~/dataを作っておきます。
Windows側準備
Windows側では、以下のようなバッチファイルを作成します。
@echo off
setlocal enabledelayedexpansion
cd %~dp0
set sourceDir=%1
set endpoint=http://s3.jp-tok.cloud-object-storage.appdomain.cloud
set bucket=ise-tag-test01
echo begin - %time%
aws --endpoint-url %endpoint% s3 cp %sourceDir% s3://%bucket%/ --recursive
ssh -t -i C:\Users\TomohiroTaguchi\.ssh\id_rsa.txt tomotagjp@isecloud01 ~/receive.sh ~/data
echo end - %time%
aws s3 cpでObject Storageにファイルを転送した後、ssh経由でLinux上のreceive.shを叩くようにしています。
ここでは、Linux側のデータ転送先は~/dataに決め打ちしていますが、変数にしてもよいでしょう。
ファイル転送実行
Windows上に、./testというディレクトリを作成し、そこに転送対象のファイルを格納しておきます。
c:\y\FileTransfer\test>dir
ドライブ C のボリューム ラベルは Windows です
ボリューム シリアル番号は 1866-E2FC です
c:\y\FileTransfer\test のディレクトリ
2020/04/17 19:25 <DIR> .
2020/04/17 19:25 <DIR> ..
2020/03/26 11:52 44,413 test01.txt
2020/03/26 11:52 319,644 test02.txt
2020/03/26 11:53 177,104 test03.txt
2020/03/26 11:53 60,913 test04.txt
2020/03/26 11:53 76,540 test05.txt
2020/03/26 11:53 160,677 test06.txt
6 個のファイル 839,291 バイト
2 個のディレクトリ 442,514,546,688 バイトの空き領域
で、以下のようにsend.batを実行します。
c:\y\FileTransfer>send.bat test
begin - 19:52:12.42
upload: test\test01.txt to s3://ise-tag-test01/test01.txt
upload: test\test05.txt to s3://ise-tag-test01/test05.txt
upload: test\test04.txt to s3://ise-tag-test01/test04.txt
upload: test\test06.txt to s3://ise-tag-test01/test06.txt
upload: test\test03.txt to s3://ise-tag-test01/test03.txt
upload: test\test02.txt to s3://ise-tag-test01/test02.txt
[sudo] password for tomotagjp:
move: s3://ise-tag-test01/test01.txt to data/test01.txt
move: s3://ise-tag-test01/test02.txt to data/test02.txt
move: s3://ise-tag-test01/test05.txt to data/test05.txt
move: s3://ise-tag-test01/test06.txt to data/test06.txt
move: s3://ise-tag-test01/test04.txt to data/test04.txt
move: s3://ise-tag-test01/test03.txt to data/test03.txt
Connection to 10.168.222.38 closed.
end - 19:52:26.28
これで、testディレクトリ以下の全ファイルが、Linux上の~/dataにコピーされました!
上の例ではsudoでパスワード入力が必須な環境なので、途中でパスワード入れないといけないですが、Windows側の操作だけでファイル転送ができるようになりました。
※補足
s3のコマンドのcpやmvではファイル名指定にワイルドカード"*"は使用できません。--recursiveオプションを指定するとディレクトリ以下が全部操作対象になるので、そちらを利用する必要があります。さらに、--exclude, --includeオプションで除外する/含めるファイルをコントロールできますが、そちらではワイルドカード指定ができるようなので、それらを合わせると複数ファイルまとめて扱うことができるようです。今回は--recursiveのみ利用しています。
参考: [小ネタ] S3に保存されているログファイルをAWS CLIでまとめてコピーする
参考: 転送速度について
約1GBのファイルを転送してみた時の結果です。
scp/VPNでPC=>Linux転送: 17分20秒 (1MB/sくらい)
PC=>ObjectStorage: 2分20秒 (7MB/sくらい)
ObjectStorage=>Linux: 22秒 (46MB/Sくらい)
合わせても2分42秒くらいになりました。