概要
CUDA/ cuDNNの複数バージョンの平行運用を可能にする、dockerのラッパーであるnvidia-dockerをUbuntu 17.04環境に導入し、Keras(on TensorFlow)のmnist_cnn.pyサンプルの動作確認まで行う。ついでにethereum miningとの同時起動も試す。
nividia-dockerの導入
基本手順は下記に従い、nvidia-dockerのサービス起動まで確認する。NVIDIA driverはホストPC側にあらかじめ導入が必要。
Ubuntu 16.04 LTS で NVIDIA Docker を使ってみる - CUBE SUGAR CONTAINER
ただし自環境はUbuntu 17.04
$ cat /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=17.04
DISTRIB_CODENAME=zesty
DISTRIB_DESCRIPTION="Ubuntu 17.04"
16.04 LTS用のイメージではうまくいかないため、Issueを確認し、16.10以降用のbuildしなおされたものを使う。(自己責任)
Cannot install on Ubuntu 16.10 Yakkety - dependency issues · Issue #234 · NVIDIA/nvidia-docker
作業用dirを作り、作業。
$ mkdir nvdocker-setup
$ cd nvdocker-setup
$ wget https://github.com/NVIDIA/nvidia-docker/files/818401/nvidia-docker_1.0.1-yakkety_amd64.deb.zip
$ unzip nvidia-docker_1.0.1-yakkety_amd64.deb.zip
$ sudo dpkg -i nvidia-docker_1.0.1-yakkety_amd64.deb
$ systemctl list-units --type=service | grep -i nvidia-docker
nvidia-docker.service loaded active running NVIDIA Docker plugin
サービス起動まで確認。
dockerイメージのbuild
記事はcuDNN5用の手順となっている。latestのTensorFlowはcuDNN6が必要なため、一部書き換えて対応する。
cudnn6用のdocker imageをひいてきて、それをベースとしてイメージを再ビルドする。
$ sudo docker pull nvidia/cuda:8.0-cudnn6-runtime
Dockerfileを、FROM句を書き換えて、再作成する。
$ cat << 'EOF' > Dockerfile
FROM nvidia/cuda:8.0-cudnn6-runtime
LABEL maintainer "example@example.jp"
RUN apt-get update
RUN apt-get -y install python3-pip curl
RUN pip3 install keras tensorflow-gpu
EOF
dockerイメージをビルドし、実行する。
$ sudo docker build -t test/my-dl-image .
$ sudo nvidia-docker run --rm -i -t test/my-dl-image /bin/bash
mnist_cnn.pyを試す
上で成功していればdockerのbashに入っている。(#プロンプトが表示)
コンテナ内でmnist_cnn.pyまで試す。
# curl -O https://raw.githubusercontent.com/fchollet/keras/master/examples/mnist_cnn.py
# echo 'K.clear_session()' >> mnist_cnn.py
# python3 mnist_cnn.py
...
Epoch 12/12
60000/60000 [==============================] - 4s - loss: 0.0370 - acc: 0.9891 - val_loss: 0.0278 - val_acc: 0.9909
Test loss: 0.0277940831313
Test accuracy: 0.9909
成功。
カスタムdocker
下記Dockerfileで、ほぼ全部入り環境からはじめられる。素のイメージで5GB弱。
入っているもの:
- CUDA8, cuDNN6
- Anaconda3-4.4.0(Python 3.6) on pyenv
- preinstalled jupyter, numpy, pandas etc
- DL libraries
- Keras/ TensorFlow
- Chainer
- Pytorch
- Others
- OpenCV
- Open AI Gym
- Kaggle CLI
$ cat << 'EOF' > Dockerfile
FROM nvidia/cuda:8.0-cudnn6-runtime
RUN apt-get update
RUN apt-get install -y curl git unzip imagemagick bzip2
RUN git clone git://github.com/yyuu/pyenv.git .pyenv
WORKDIR /
ENV HOME /
ENV PYENV_ROOT /.pyenv
ENV PATH $PYENV_ROOT/shims:$PYENV_ROOT/bin:$PATH
RUN pyenv install anaconda3-4.4.0
RUN pyenv global anaconda3-4.4.0
RUN pyenv rehash
RUN pip install opencv-python tqdm h5py keras tensorflow-gpu kaggle-cli gym
RUN pip install chainer
RUN pip install http://download.pytorch.org/whl/cu80/torch-0.2.0.post3-cp36-cp36m-manylinux1_x86_64.whl
RUN pip install torchvision
EOF
(余談) miningしながらnvidia-docker
ホストPCでのethereum miningと、nvidia-docker上(CUDA8, cuDNN6)のlearningが同時に動くか試す。結論としては動いたが、もちろん学習はかなり遅くなる。メモリは使えている。
$ nvidia-smi
Sun Sep 3 21:45:08 2017
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.66 Driver Version: 384.66 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 1070 Off | 00000000:01:00.0 Off | N/A |
| 54% 76C P2 136W / 150W | 7980MiB / 8112MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 2085 C ./ethdcrminer64 2311MiB |
| 0 2241 C python3 5659MiB |
+-----------------------------------------------------------------------------+
さきほどは 4s/epochだったので、4-5倍時間がかかっている。
Epoch 5/12
60000/60000 [==============================] - 18s - loss: 0.0627 - acc: 0.9811 - val_loss: 0.0365 - val_acc: 0.9879
Epoch 6/12
60000/60000 [==============================] - 18s - loss: 0.0563 - acc: 0.9834 - val_loss: 0.0338 - val_acc: 0.9889
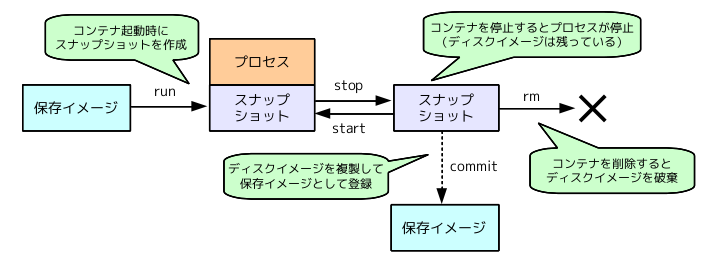
(参考) コンテナのライフサイクル
nvidia-dockerはdockerのラッパーなので、docker自体の使い方に習熟する必要がある。
dockerのライフサイクルと、ベストプラクティスをおさえる。
複数dockerで共用することを考え、データセット、学習済みモデルなどはすべてホストPCのボリュームをマウントして使う、などいろいろ盛り込んでcustom docker imageを作るところは次に!