はじめに
生まれてはじめて機械学習で物体検出をやってみました。
OSはWindows10を使っています。
いろいろと指導してくれた同僚のI氏にこの場を借りて感謝です。
やりたいこと
ブラウザ上で、読み込んだ画像上にある複数の物体を検出する。
全体の流れ
学習用データを増やすところと、ブラウザ上でモデルの検出結果を処理するところを詳細に書いています。
- 学習用データの作成
- 学習用データを増やす←詳細
- 学習
- モデルの変換
- ブラウザ上での認識(バウンディングボックスの処理)←詳細
1.学習用データの作成
学習用の画像の中で、どこにどんな学習させたい物があるかを指定する作業(アノテーション)を行います。
色々なフリーソフトがありますが、LabelImgを使いました。
このリンクの一番下にある最新版をダウンロード。
LabelImg
ダウンロードしたフォルダ内の「labelImg.exe」を実行するだけでできます。
学習用画像は、一つのフォルダにまとめておきます。
具体的な方法はこちらの5から。
ただし、今回は出力形式は、「Pascal VOC」のままで良いです(2.の増殖を行うため)。
【YOLO V5】AIでじゃんけん検出
2.学習用データを増やす
学習用データを揃えるのは労力がかかるため、
一枚の画像に対して、回転、拡大、縮小等を行うことで、別の画像として学習データを用意する手法があります。
今回は、この増殖が簡単にできるウェブサービスを使いました。
こちらにアクセス
roboflow
なお、手法の詳細についてはこちら
【YOLO】 labelImgでアノテーション済みデータを増殖(data augmentation)
roboflowのサイトで新規登録し、ログインするとこのような画面になります。
下の「Create New Project」をクリック。
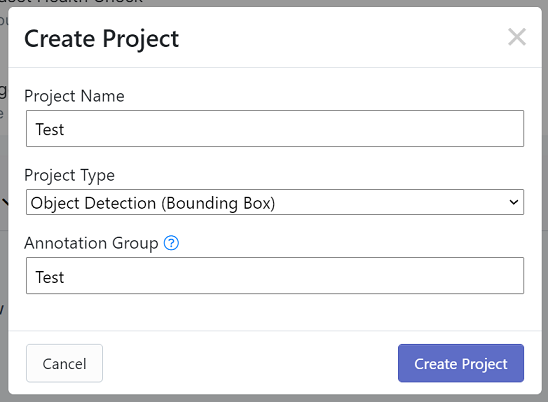
Project Name:プロジェクト名(何でも良い)
Project Type:Object Detection (Bounding Box)
Annotation Group:今回検出したいもののグループ名(何に使うかはいまいち分かりませんが)
「Drag and drop images and annotations」と表示されているところに、アノテーションした画像とxmlファイルのフォルダごとドラッグアンドドロップする。
無事アップロードできれば、学習用画像に、アノテーションした枠が載っている画像が表示されるため、確認して、画面右上の「Finish Uploading」を押す。
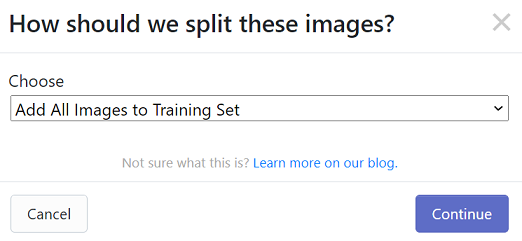
「How should we split these images?」と聞かれたら、Train用データ、Valid用データ、Test用データの割合を決める。
今回は、全てTrain用データとするため、Chooseで「Add All Images to Training Set」を選択し、「Continue」を押す。
その後、変換のための前処理とデータの増殖の設定を行います。
- 前処理
学習用画像のサイズを変更できます。
YOLOV5のデフォルトが640×640なので、この値に変更しました。
Auto-Orientは、右の×を押して消しました。
消さなくて良いかもしれません。
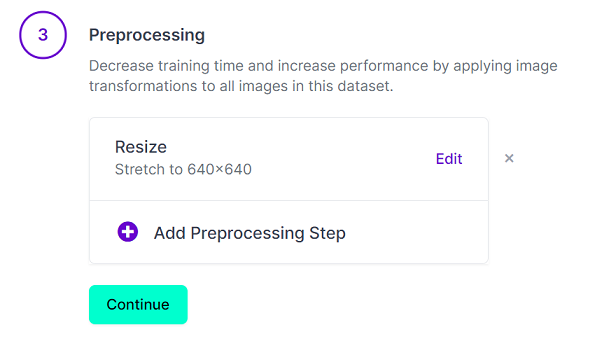
設定したら「Continue」を押します。
- データの増殖
「Add Augmentation Step」を押して、追加できます。
その後のチェックボックスを押して、「Apply」を押します。
今回は、水平・垂直反転、90度回転を追加しました。
他にも明るさや色合いを変えた画像を追加できます。
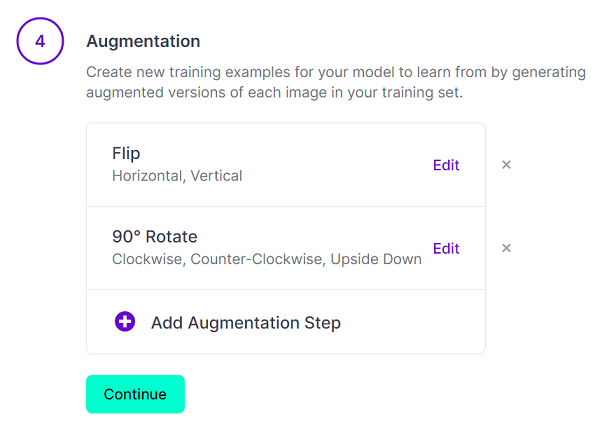
設定したら「Continue」を押します。
-
Generate
「Maximum Version Size」を大きくすると、トレーニングに時間がかかりますが、モデルのパフォーマンスが向上することがあるそうです。
無料版は、36 images (3x)が最大なので、これを選択し、「Generate」を押す。
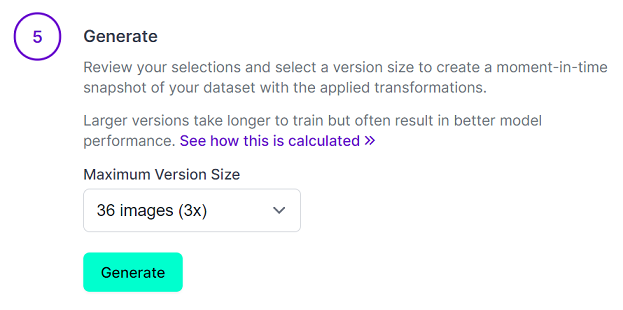
-
データの出力
Save Name:保存する名前
Format:YOLO v5 Pytorchを選択
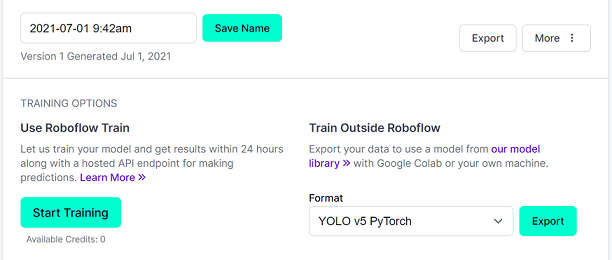
「Export」を押した後、「your zip file」を押すとダウンロードできます。
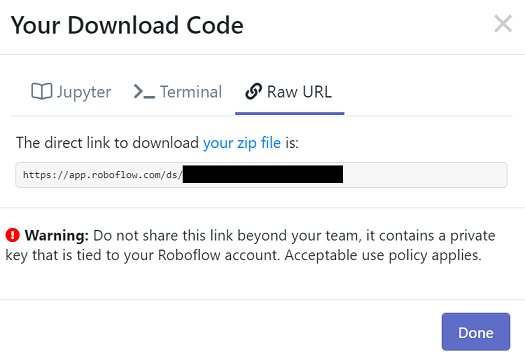
3.学習
学習部分については、色々載っているため、詳細は割愛。
【YOLO V5】AIでじゃんけん検出
【忘備録】
- 今回は、Train用データとValid用データに同じものを使っているため、data.yamlのtrain: とval: には同じフォルダを指定
train: train/images
val: train/images ←trainと同じフォルダ
nc: 1
names: ['test']
- YOLOV5の「models/yolov5s.yaml」内のncを学習用データのタグ数に変更
# parameters
nc: 1 # number of classes ←data.yaml内のncの値に合わせる
- パラメータファイル
スマホ上でも動かしたいため、「yolov5s.yaml」を使用。
「yolov5l.yaml」や「yolov5x.yaml」で作成したら、モデルのサイズが大きくなりスマホで読み込めなかった。
「yolov5m.yaml」では読み込めたが、読み込みに時間がかかる。
4.モデルの変換
YOLOV5のモデルは、PyTorchのモデルのため、TensorFlow.js用に変換するには、下記手順で行います。
-
PyTorch→ONNX
-
ONNX→TensorFlow
-
TensorFlow→TensorFlow.js
-
PyTorch→ONNX
YOLOV5に変換プログラムが同梱しています。
python models/export.py --weights weights/best.pt --img 640 640 --batch-size 1 --include onnx
学習済モデル名は適宜変更
- ONNX→TensorFlow
こちらを使います。
https://github.com/onnx/onnx-tensorflow
onnx-tf convert -i best.onnx -o bestpb
- TensorFlow→TensorFlow.js
pip install tensorflowjs
今回のやり方では、tfjs_layers_modelには非対応のため、output_formatは、tfjs_graph_modelを選択します。
tensorflowjs_converter bestpb tfjs --input_format=tf_saved_model --output_format=tfjs_graph_model
参考
PyTorchのモデルを別形式に変換する方法いろいろ
TensorflowのモデルをTensorflow.jsの形式へ変換する方法
5.ブラウザ上での認識(バウンディングボックスの処理)
変換したモデルは、物体の検出結果をバウンディングボックスで出力するため、出力結果から欲しい検出結果を得るには、ちょっとした手間が発生します。
- 入力画像の変換
画素値を255で割って正規化(0~1の範囲に変換)する処理が必要です。
let imageTensor = tf.browser.fromPixels(loader, 3);
imageTensor = imageTensor.resizeBilinear([MODEL_HEIGHT, MODEL_WIDTH]).toFloat();
let offset = tf.scalar(255);
imageTensor = imageTensor.div(offset).expandDims(0);
//NHWC⇒NCHW
imageTensor = imageTensor.transpose([0, 3, 1, 2]);
- 出力データの取り出し
output[0].arraySync()で検出結果のバウンディングボックスを取得します。
var output = model.executeAsync(imageTensor).then(output=> {
const o0 = output[0].arraySync();
(略)
}
- しきい値以上のバウンディングボックスを取得
バウンディングボックスの座標は、下記を示しています。
([ボックス中心のX座標], [ボックス中心のY座標], [ボックスの幅], [ボックスの高さ], [検出スコア], [検出の確かさ])
しきい値 = 検出スコア * 検出の確かさ
で計算します。しきい値を例えば、0.5などで設定し、しきい値以上のもののみ取得します。
- 倍率の変更
バウンディングボックスの座標は、画像サイズを640×640に変換した画像に対する位置を示しています。
入力画像の実際の大きさに合わせて修正する必要があります。
また、後々JavaScriptのstrokeRect関数でボックスを画像上に描画するため、ボックスの中心座標は、ボックスの左上の座標にする必要があります。
const OBJECT_TH = 0.5; //しきい値
const bairitu_w = 画像の元の幅/入力時の幅;
const bairitu_h = 画像の元の高さ/入力時の高さ;
let a=0;
var list = new Array();
for (let i = 0; i < o0[0].length; i++) {
if((o0[0][i][4]*o0[0][i][5])>OBJECT_TH){
a = a+1;
const dx = o0[0][i][2]*bairitu_w/2;
const dy = o0[0][i][2]*bairitu_h/2;
var ary = new Array();
ary.push(o0[0][i][0]*bairitu_w - dx);
ary.push(o0[0][i][1]*bairitu_h - dy);
ary.push(o0[0][i][2]*bairitu_w);
ary.push(o0[0][i][3]*bairitu_h);
ary.push(o0[0][i][4]*o0[0][i][5]);
list.push(ary);
}
}
- 重なりすぎているボックスを削除
バウンディングボックス内には、同じ物体を検出したボックスが多数あります。
そこで、ボックス間の重なり度合い(IOU)を計算し、重なりすぎているものは削除します。
そのために、下記のフローで求めることにしました。
- バウンディングボックスを、しきい値の低い順に並び替える
- 先頭から順に他のバウンディングボックスとの重なりを計算し、指定した度合い以上の場合、このボックスは描画せず、次のボックスへ
- 最後まで重なり度合いが、指定した度合い以下の場合、描画する
しきい値の低い順に並び替えたのは、同じ物体を検出したボックスの中で、しきい値が高いものが最後に残るようにしたかったからです。
//リスト内の配列[4]には、しきい値を計算したものを入れています。
list.sort(function(a,b){return(a[4] - b[4]);});
function bbox_iou(box1, box2){
xs1 = Math.max(box1[0], box2[0]);
ys1 = Math.max(box1[1], box2[1]);
xs2 = Math.min(box1[0] + box1[2], box2[0] + box2[2]);
ys2 = Math.min(box1[1] + box1[3], box2[1] + box2[3]);
intersections = Math.max(ys2 - ys1, 0) * Math.max(xs2 - xs1, 0);
unions = (box1[2] * box1[3]) + (box2[2] * box2[3]) - intersections;
ious = intersections / unions;
return ious;
}
ctx.lineWidth = 2;
ctx.strokeStyle = "rgb(255, 255, 255)";
for (let i = 0; i < list.length; i++) {
let aa = 0;
for(let j = i+1; j< list.length; j++) {
var iou = bbox_iou(list[i], list[j]);
if(iou > 0.5) {
aa = 1;
break;
}
}
ctx.fillStyle;
if(aa==0) {
ctx.strokeRect(list[i][0], list[i][1], list[i][2], list[i][3]);
}
}
ソースはこちら
いろいろツッコミどころのある書き方してますが、そのうち直します。
https://github.com/tomo00223/YOLOV5andTFJS
さいごに
TensorFlow.jsでカスタムモデルによる物体検出を行う例が少なかったため、皆様の一助になれば幸いです。
余力がある時に、もっと分かりやすく修正します。