1. はじめに
AIで手の形を検出できたら、手話の翻訳などにも活用できそうですよね。いきなり手話翻訳は難しいので、まずは、じゃんけんの「グー・チョキ・パー」をAI(YOLO)でリアルタイム検出できるか試してみたいと思います。
※サクッと**じゃんけん検出**だけ遊びたい人は、手順7~9までをLocal PCで実施してください😉
2. 具体的にどんなことをやるか
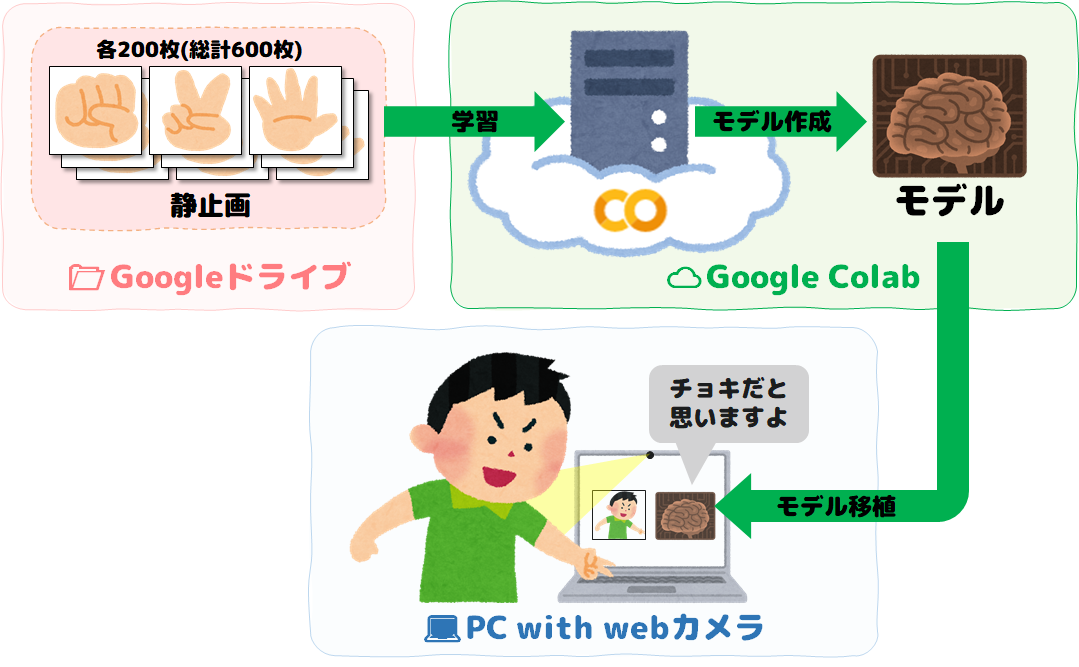
Local PCのwebカメラを使って、じゃんけん(グー・チョキ・パー)をAIに検出させたいと思います。モデルを作成するのにLocal PCだとかなり時間がかかりそうなので、モデル作成はGoogle ColabのGPUパワーを利用しサクッとモデルを作って、作ったモデルをLocal PCへ移植したいと思います。
モデル作成は、最先端リアルタイム物体検出システムである**
YOLO V5**を使用します😊
イメージ図
3. 開発環境
3.1 開発環境
| 開発環境 | 備考欄 |
|---|---|
| Google Colab | 学習(モデル生成)時に使用します。Googleアカウントがあれば誰でも無料で使用できます。GPUを利用でき学習スピードがとても早いためこちらを利用します。Google Colabでの利用の仕方は「tutorial.ipynb」を参照すると便利です。 |
| Local PC with webカメラ |
静止画撮影、ラベリング、物体検出時に使用します。今回はLocal PCとして、win10を使用しました。pythonの仮想環境はanacondaを利用しました。 |
3.2 使用ツール
■Google Colab
| 必要なツール類 | 備考欄 |
|---|---|
| YOLO V5 | Google Colab上では、学習(モデル生成)時に使います。フリーウェア(GNU GPL V3)です。 |
■Local PC
| 必要なツール類 | 備考欄 |
|---|---|
| YOLO V5 |
Local PC上では、物体検出時に使います。 |
カメラアプリ
|
win10標準アプリ。静止画撮影時に使います。相応のもので撮影できれば何でもOKです。 |
| labelImg | 教師データのラベリングに使用します。フリーウェア(MIT License)です。 |
3.3 YOLOとは
YOLOとは最先端のリアルタイム物体検出システムです。今回はこれらの最新バージョンである、YOLO Ver5を利用したいと思います。
| YOLO | 作者 | 機械学習ライブラリ | 備考欄 |
|---|---|---|---|
| YOLO Ver3 | Joseph Chet Redmon | Darknet | Darknetは、CおよびCUDAで記述されたオープンソースのニューラルネットワークフレームワーク。Darknetの作者はJoseph Chet Redmonです。 |
| YOLO Ver4 | Alexey Bochkovskiy | Darknet | Ver3の作者とは異なる作者によるリリース。V3よりパワーアップ! |
| YOLO Ver5 | Glenn Jocher(ultralytics.com) | PyTorch | PyTorchとは、Python向けのオープンソース機械学習ライブラリ。V3より更にパワーアップップ💪 |
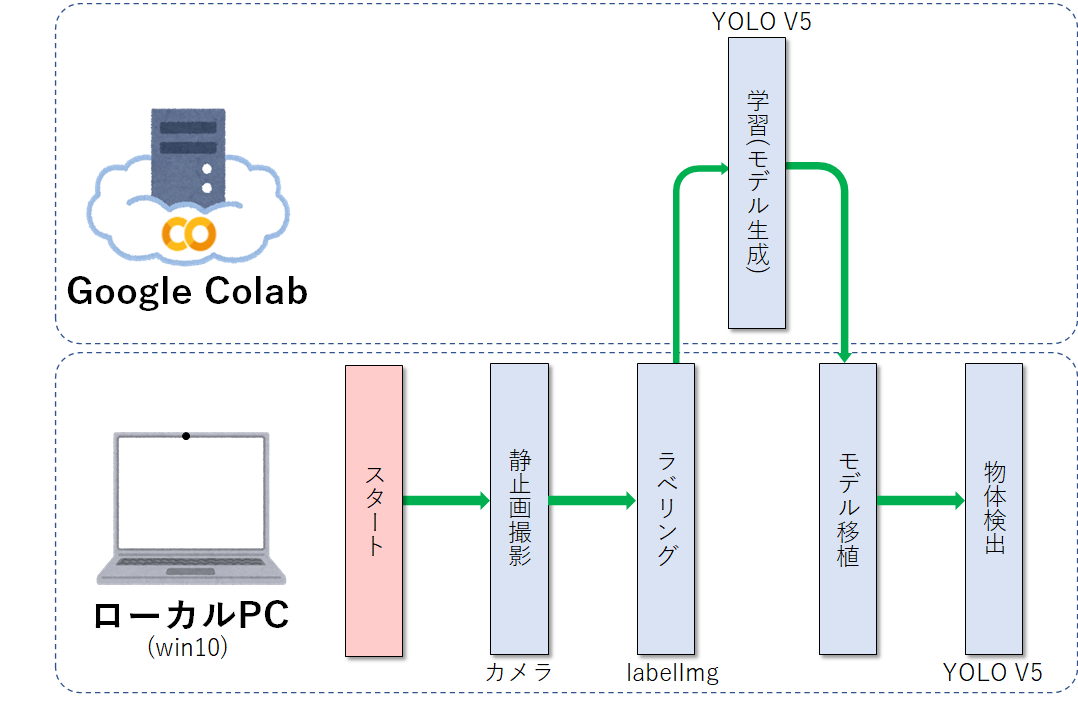
3.4 開発フロー
開発環境が複数あるため、分かりにくいので開発フローを記載しておきます。参考にしてください。以下、どこで作業しているのか、分かりやすくするために「💻」はLocal PCを、「☁」はGoogle Colab、「📂」はGoogle Driveを示すこととします。
4. 学習データ収集
静止画を集めるために、まずLocal PC(win10)でカメラアプリを起動し、グー・チョキ・パーの撮影を行います。Local PCにwin10以外を使用する方は、相応のアプリで写真を撮ってください。
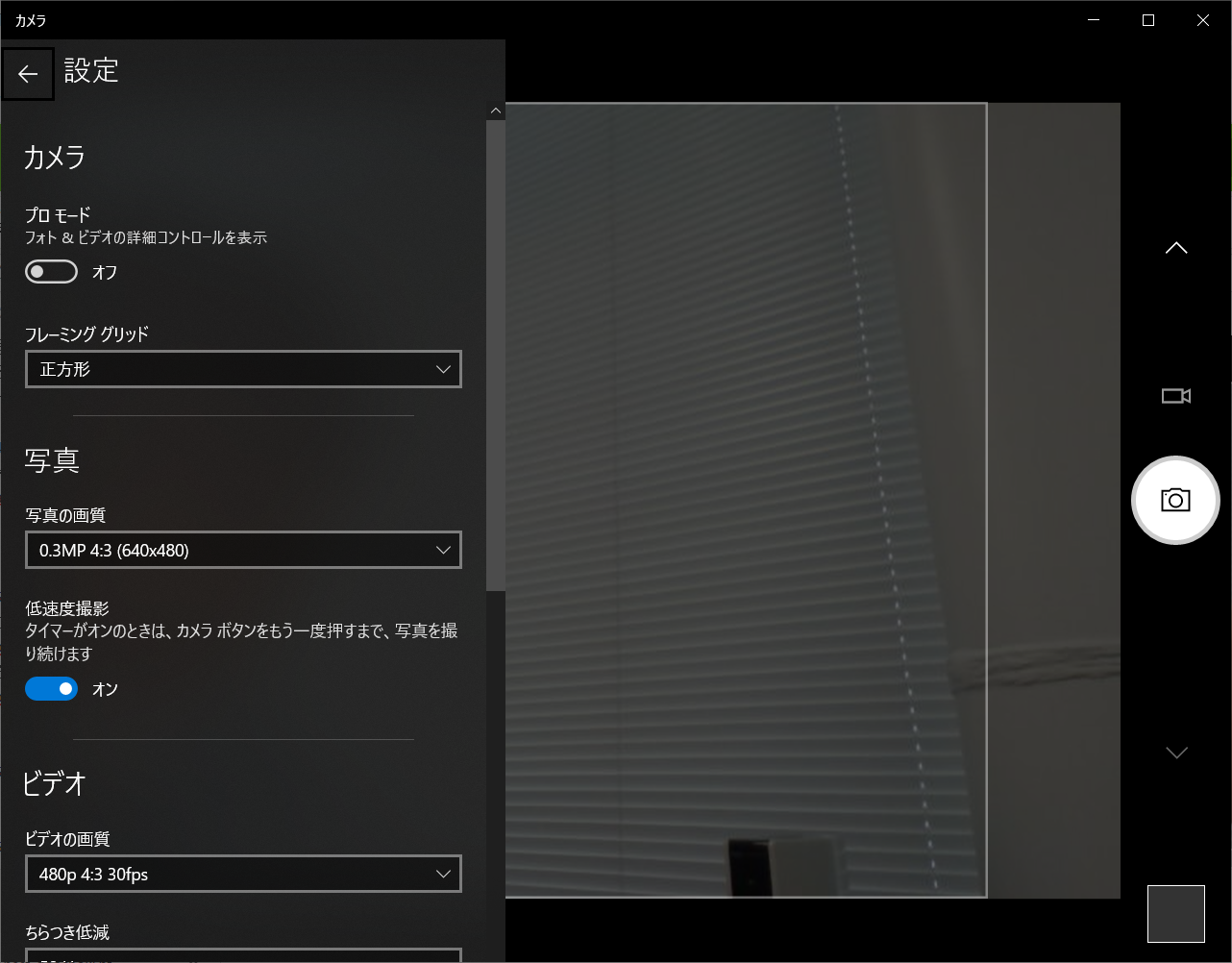
4.1 💻:カメラアプリ設定
カメラアプリの設定ですが、写真の解像度を640x480の設定にしました。低速度撮影をONにし、2秒タイマーをかけると連続撮影がとても楽です。
4.2 💻:静止画撮影
「グー・チョキ・パー」を色んな角度から写真を撮ってください。私はラベリング作業を素早くするために、「グー・チョキ・パー」それぞれ単体の写真を各200枚ずつ、計600枚写真を撮りました。

5. ラベリング
5.1 💻:labelImgツール インストール
[Github]:https://github.com/tzutalin/labelImg
Local PCにwin10を使用している方は、バイナリ版「windows_v1.8.1.zip」をダウンロードし適当な場所に解凍してください。Local PCでpython+各環境(Ubuntu、mac、win)で動作させる場合は、gitのInstallationを参考にインストールしてください。
5.2 💻:ラベリング作業
ダウンロードした「windows_v1.8.1.zip」を解凍したら、「labelImg.exe」を実行して、ラベリングしていきます。**フォーマットをYOLOに設定**するのを忘れないでください。あとは「グー・チョキー・パー」総計600枚をシコシコとラベリングしていきます。
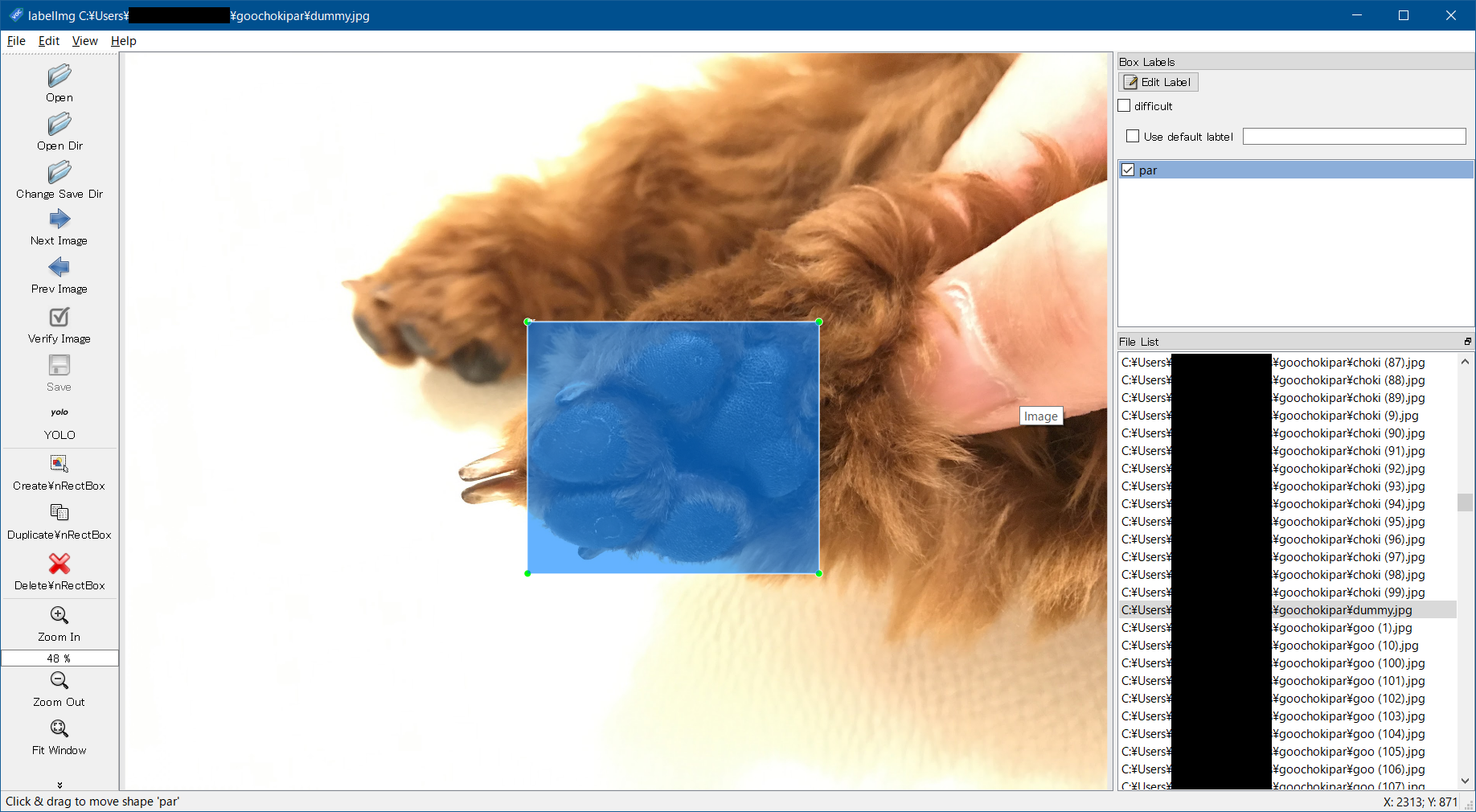
基本的に「グー・チョキ・パー」それぞれの写真を撮っているため、「Use default label」をONに設定して、「グー」なら「goo」、「チョキ」なら「choki」、「パー」なら「par」とラベリングしていくと作業が早いと思います。左手で「'w'」キーを押下し枠モードにして、右手マウスで枠を囲う、save後、Next Image押下して………と、次々作業していくイメージです。
下の画像はダミー(ワンコの手です😁)ですが、こんな感じで「グー・チョキ・パー」をBOXで囲いどんどんラベリングしてください!
5.3 💻:ラベリング結果
■ラベリング結果
ラベリング作業が終わると、以下のようにラベリングファイルとクラス定義ファイルが作成されています。
LabelImg_Data
│
├─choki (1).jpg … 画像ファイル
├─choki (1).txt … ラベリング
│ ︙
├─choki (200).jpg
├─choki (200).txt
│
├─goo (1).jpg
├─goo (1).txt
│ ︙
├─goo (200).jpg
├─goo (200).txt
│
├─par (1).jpg
├─par (1).txt
│ ︙
├─par (200).jpg
├─par (200).txt
│
└─classes.txt … クラス定義ファイル
■ラベリング結果(例)
例えば、「choki (1).jpg」のラベリングデータは、「choki (1).txt」となります。「choki (1).txt」を開くと、そこにラベルデータが書かれています。先頭列がクラスを表しているのでこれは「クラス0」ということになります。また、その後にバウンディングボックスの位置データが入っています。
0 0.554688 0.566667 0.315625 0.404167
↑
クラス0が定義されていることを表す
例えば、「goo (1).jpg」のラベリングデータは、「goo (1).txt」となります。「goo (1).txt」を開くと、そこにラベルデータが書かれています。先頭列がクラスを表しているのでこれは「クラス1」ということになります。また、その後にバウンディングボックスの位置データが入っています。
1 0.424219 0.476042 0.245312 0.427083
↑
クラス1が定義されていることを表す
例えば、「par (1).jpg」のラベリングデータは、「par (1).txt」となります。「par (1).txt」を開くと、そこにラベルデータが書かれています。先頭列がクラスを表しているのでこれは「クラス2」ということになります。また、その後にバウンディングボックスの位置データが入っています。
2 0.474219 0.310417 0.201563 0.437500
↑
クラス2が定義されていることを表す
「classes.txt」はTrainingには使いませんが、きちんとクラス分け出来ているか確認することができます。先頭行からクラス0、クラス1、クラス2となります。
choki ← クラス0が定義されていることを表す
goo ← クラス1が定義されていることを表す
par ← クラス2が定義されていることを表す
6. 学習 Training
6.1 ☁:YOLOインストール
Google Colabにyolo v5をインストールするため、コードをgitからダウンロードします。
!git clone https://github.com/ultralytics/yolov5
yolo v5を起動するために必要なライブラリをインストールします。
!pip install -r yolov5/requirements.txt
6.2 💻→📂:データセット
Googleドライブのマイドライブ配下に「goochokipar」フォルダを追加して、その中に「5.3 ラベリング結果」で作った教師データ(画像データ及びラベルデータ)を全てコピーします。
今回は、以下のGoogle Driveへ
画像データ、ラベルデータを格納しました。
/content/drive/My Drive/goochokipar
※Google Colabにもアップロードできますが、こちらにUPLOADしたファイルは、ランタイムのリサイクル時に削除されてしまいます。そのため、ユーザが作成したデータは、Googleドライブに格納することを推奨します。
6.3 📂:データセットの格納場所&クラス分類定義
モデル作成のためのデータ(教師データ、検証データ)格納場所、クラス分類数、クラス名について、設定ファイル「goochokipar.yaml」で定義します。先程作ったGoogleドライブの「goochokipar」フォルダに「goochokipar.yaml」を作成してください。今回、学習データと検証データは同一のものとしています。
今回は、以下のGoogle Driveへ
goochokipar.yamlを格納しました。
/content/drive/My Drive/goochokipar
# GooChokiPar dataset
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: /content/drive/My Drive/goochokipar
val: /content/drive/My Drive/goochokipar
# number of classes
nc: 3
# class names
names: ['choki', 'goo', 'par']
6.4 ☁:学習 Training
cocoモデルに「グー・チョキ・パー」の判別を追加することもできますが、今回は余計なものは省き、「グー・チョキ・パー」の3つのみを判別するモデルを作成していきます。
%cd /content/yolov5
!python train.py --img 640 480 --batch 20 --epochs 300 --data '/content/drive/My Drive/goochokipar/goochokipar.yaml' --name goochokipar
6.5 ☁:モデル生成結果
batch数を20、epoch数を300にして実施しましたが、モデル生成には大体3時間45分くらいかかりました😱。ログの最後の方にどこにモデルができたかパスが表示されます。今回は、下記にモデルが出来上がっていました。
「/content/yolov5/runs/exp2_goochokipar/weights/best_goochokipar.pt」
last_xxxx.ptは、トレーニングの最後のエポックからの重み、best_xxxx.ptは、トレーニング中に記録された最高の重みだそうです。今回はbestの方を利用したいと思います。
Optimizer stripped from runs/exp2_goochokipar/weights/last_goochokipar.pt, 14.8MB
Optimizer stripped from runs/exp2_goochokipar/weights/best_goochokipar.pt, 14.8MB
/content/yolov5
Using CUDA device0 _CudaDeviceProperties(name='Tesla K80', total_memory=11441MB)
Namespace(adam=False, batch_size=20, bucket='', cache_images=False, cfg='', data='/content/drive/My Drive/goochokipar/goochokipar.yaml', device='', epochs=300, evolve=False, global_rank=-1, hyp='data/hyp.finetune.yaml', image_weights=False, img_size=[640, 480], local_rank=-1, logdir='runs/', multi_scale=False, name='goochokipar', noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=20, weights='yolov5s.pt', workers=8, world_size=1)
Start Tensorboard with "tensorboard --logdir runs/", view at http://localhost:6006/
2020-09-01 11:51:29.733753: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
Hyperparameters {'lr0': 0.00447, 'lrf': 0.114, 'momentum': 0.873, 'weight_decay': 0.00047, 'giou': 0.0306, 'cls': 0.211, 'cls_pw': 0.546, 'obj': 0.421, 'obj_pw': 0.972, 'iou_t': 0.2, 'anchor_t': 2.26, 'fl_gamma': 0.0, 'hsv_h': 0.0154, 'hsv_s': 0.9, 'hsv_v': 0.619, 'degrees': 0.404, 'translate': 0.206, 'scale': 0.86, 'shear': 0.795, 'perspective': 0.0, 'flipud': 0.00756, 'fliplr': 0.5, 'mixup': 0.153}
Overriding {'nc': 80, 'depth_multiple': 0.33, 'width_multiple': 0.5, 'anchors': [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], 'backbone': [[-1, 1, 'Focus', [64, 3]], [-1, 1, 'Conv', [128, 3, 2]], [-1, 3, 'BottleneckCSP', [128]], [-1, 1, 'Conv', [256, 3, 2]], [-1, 9, 'BottleneckCSP', [256]], [-1, 1, 'Conv', [512, 3, 2]], [-1, 9, 'BottleneckCSP', [512]], [-1, 1, 'Conv', [1024, 3, 2]], [-1, 1, 'SPP', [1024, [5, 9, 13]]], [-1, 3, 'BottleneckCSP', [1024, False]]], 'head': [[-1, 1, 'Conv', [512, 1, 1]], [-1, 1, 'nn.Upsample', ['None', 2, 'nearest']], [[-1, 6], 1, 'Concat', [1]], [-1, 3, 'BottleneckCSP', [512, False]], [-1, 1, 'Conv', [256, 1, 1]], [-1, 1, 'nn.Upsample', ['None', 2, 'nearest']], [[-1, 4], 1, 'Concat', [1]], [-1, 3, 'BottleneckCSP', [256, False]], [-1, 1, 'Conv', [256, 3, 2]], [[-1, 14], 1, 'Concat', [1]], [-1, 3, 'BottleneckCSP', [512, False]], [-1, 1, 'Conv', [512, 3, 2]], [[-1, 10], 1, 'Concat', [1]], [-1, 3, 'BottleneckCSP', [1024, False]], [[17, 20, 23], 1, 'Detect', ['nc', 'anchors']]]} nc=80 with nc=3
from n params module arguments
0 -1 1 3520 models.common.Focus [3, 32, 3]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 19904 models.common.BottleneckCSP [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 1 161152 models.common.BottleneckCSP [128, 128, 3]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 1 641792 models.common.BottleneckCSP [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 656896 models.common.SPP [512, 512, [5, 9, 13]]
9 -1 1 1248768 models.common.BottleneckCSP [512, 512, 1, False]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 378624 models.common.BottleneckCSP [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 95104 models.common.BottleneckCSP [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 313088 models.common.BottleneckCSP [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1248768 models.common.BottleneckCSP [512, 512, 1, False]
24 [17, 20, 23] 1 21576 models.yolo.Detect [3, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 191 layers, 7.26049e+06 parameters, 7.26049e+06 gradients
Transferred 364/370 items from yolov5s.pt
Optimizer groups: 62 .bias, 70 conv.weight, 59 other
Scanning labels /content/drive/My Drive/goochokipar.cache (600 found, 0 missing, 0 empty, 0 duplicate, for 600 images): 600it [00:00, 11442.86it/s]
Scanning labels /content/drive/My Drive/goochokipar.cache (600 found, 0 missing, 0 empty, 0 duplicate, for 600 images): 600it [00:00, 6890.78it/s]
/usr/local/lib/python3.6/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.
import pandas.util.testing as tm
Analyzing anchors... anchors/target = 2.42, Best Possible Recall (BPR) = 1.0000
Image sizes 640 train, 480 test
Using 2 dataloader workers
Starting training for 300 epochs...
Epoch gpu_mem GIoU obj cls total targets img_size
0/299 5.86G 0.06498 0.01338 0.01231 0.09067 47 640: 100% 30/30 [00:44<00:00, 1.50s/it]
Class Images Targets P R mAP@.5 mAP@.5:.95: 100% 30/30 [00:16<00:00, 1.78it/s]
all 600 614 0 0 0.000393 6.18e-05
Epoch gpu_mem GIoU obj cls total targets img_size
1/299 5.76G 0.05824 0.009701 0.01148 0.07942 57 640: 100% 30/30 [00:33<00:00, 1.12s/it]
Class Images Targets P R mAP@.5 mAP@.5:.95: 100% 30/30 [00:13<00:00, 2.23it/s]
all 600 614 0 0 0.00134 0.000207
Epoch gpu_mem GIoU obj cls total targets img_size
2/299 5.76G 0.0537 0.008562 0.01106 0.07332 54 640: 100% 30/30 [00:33<00:00, 1.11s/it]
Class Images Targets P R mAP@.5 mAP@.5:.95: 100% 30/30 [00:12<00:00, 2.37it/s]
all 600 614 0 0 0.00226 0.000376
~ 省略 ~
Epoch gpu_mem GIoU obj cls total targets img_size
298/299 5.76G 0.009543 0.002208 0.0006254 0.01238 50 640: 100% 30/30 [00:31<00:00, 1.05s/it]
Class Images Targets P R mAP@.5 mAP@.5:.95: 100% 30/30 [00:10<00:00, 2.82it/s]
all 600 614 0.993 1 0.995 0.903
Epoch gpu_mem GIoU obj cls total targets img_size
299/299 5.76G 0.009511 0.002123 0.000563 0.0122 42 640: 100% 30/30 [00:31<00:00, 1.05s/it]
Class Images Targets P R mAP@.5 mAP@.5:.95: 100% 30/30 [00:10<00:00, 2.84it/s]
all 600 614 0.993 1 0.995 0.9
Optimizer stripped from runs/exp2_goochokipar/weights/last_goochokipar.pt, 14.8MB
Optimizer stripped from runs/exp2_goochokipar/weights/best_goochokipar.pt, 14.8MB
300 epochs completed in 3.668 hours.
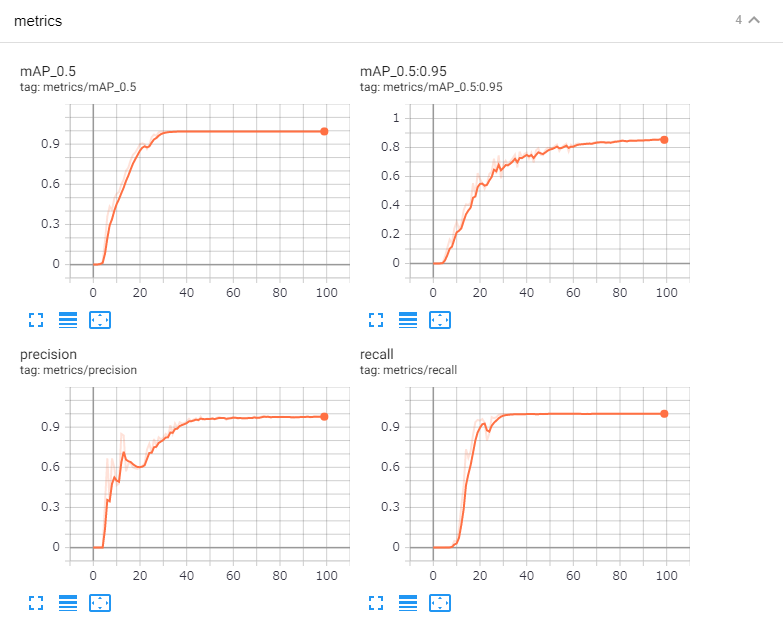
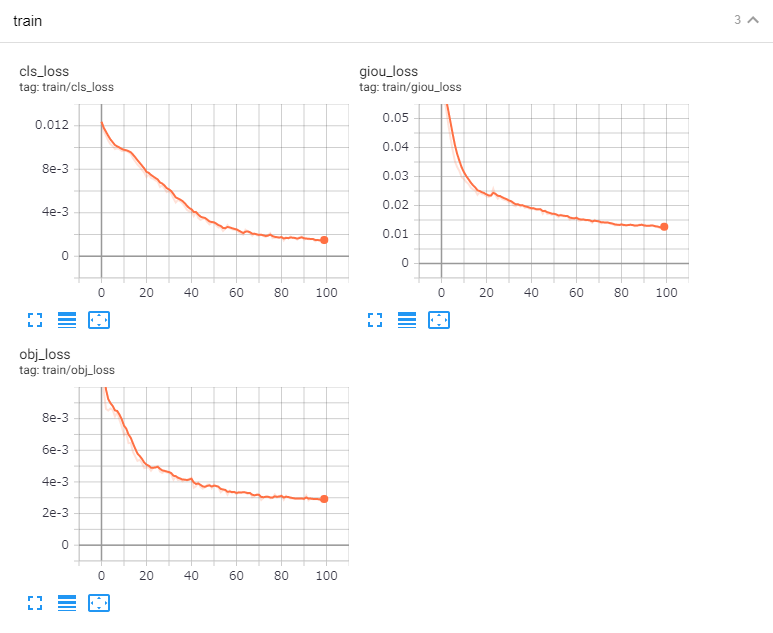
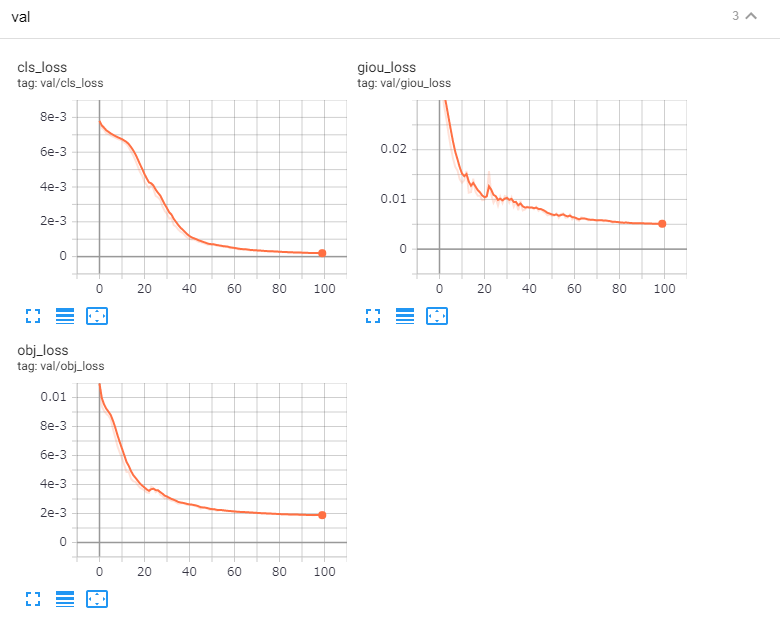
6.6 ☁:TensorBoard結果
手順には記載していませんが、念の為TensorBoardの結果を貼り付けておきます。と言いたいところですが………すみません!300epocの取り忘れました😓………代わりに100epocのを参考に貼っておきます😣💦
TensorBoard結果を取得したい方は、「6.4 ☁:学習 Training」の直前でTensorBoardを起動しておいてください。起動方法は以下です。
%load_ext tensorboard
%tensorboard --logdir runs
7. モデル移植
7.1 💻:Local PC 設定
python仮想環境としてanacondaを利用しました。
以下のコマンドを実施して、Local PCにyolo5の環境を構築します。
c:\>conda create -n yolov5 python=3.8
c:\>conda activate yolov5
(yolov5) c:\>git clone https://github.com/ultralytics/yolov5.git
(yolov5) c:\>cd yolov5
(yolov5) c:\yolov5>conda install pytorch torchvision -c pytorch
(yolov5) c:\yolov5>pip install -U -r requirements.txt
Local PCで以下のコマンドを実行し、webカメラの映像が見れることを確認してください。detect.pyでモデルを設定していない場合、自動でcocoモデルが適用されますので、この時点で80種の物体認識が可能となっています。キャプチャは「'q'」を押下で終了できます。
(yolov5) c:\yolov5>python detect.py --source 0
7.2 ☁→💻:モデル移植
Google Colabで作成したモデル「best_goochokipar.pt」をダウンロードし、Local PCのyolov5のディレクトリ直下にコピーします。
C:\yolov5\best_goochokipar.pt
となるようにコピーしてください。
8. 検出 Detect
それではいよいよ今回のクライマックスです😊ドキドキ❤
8.1 💻:物体検出
Local PCで以下のコマンドを実行してください。
(yolov5) C:\yolov5>python detect.py --source 0 --weight best_goochokipar.pt
8.2 💻:物体検出結果
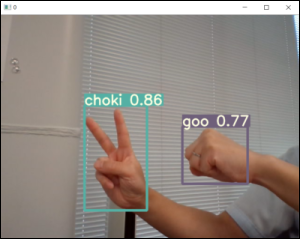
ちゃんと「グー・チョキ・パー」がリアルタイムで認識されました😄🎉

9. 共有データ
今回作成したモデルを共有します。以下からダウンロードしてください。Local PCにダウンロードしたモデルを7~8項を参考にセットすると簡単に遊ぶことができます😃「グー・チョキ・パー」の教師データ(画像データ及びラベルデータ)につきましては、私のヘン顔が所々に写っているため、恐縮ですが共有しないこととしました。あしからず😉
教師データ → 共有していません。
モデル(epoc:300) → 共有しています。Download:best_goochokipar_300epoc.pt
C:\yolov5>python detect.py --source 0 --weight best_goochokipar_300epoc.pt
10. OMAKE
色々記事を書いているので、まとめておきます。
(1)画像認識ツール紹介記事
| No. | ツール名 | 検出ターゲット | 環境 | 記事 | Thumbnail |
|---|---|---|---|---|---|
| 1 | YOLO v5 | じゃんけん検出 | ①GoogleColab ②LocalPC+webcam |
【YOLO V5】AIでじゃんけん検出 | |
| 2 | YOLACT | じゃんけん検出 | ①GoogleColab ②LocalPC+webcam |
【YOLACT】AIでじゃんけん検出 |  |
| 3 | YOLACT | COCOデータセット | ①GoogleColab | 【リアルタム物体検知】YOLACT for Google Colab【YOLOを超えた?】 |  |
| 4 | YOLACT | COCOデータセット | ①LocalPC+webcam | 【リアルタム物体検知】YOLACT for win10+webcam【セグメンテーション検出】 |  |
(2)アノテーションツール紹介記事
| No. | ツール名 | 対応フォーマット | 対応ツール | 記事 | Thumbnail |
|---|---|---|---|---|---|
| 1 | labelImg | YOLO/PascalVOC形式 | YOLO v5 … | 【YOLO V5】AIでじゃんけん検出 | |
| 2 | coco-annotator | COCO形式 | YOLACT … | 【coco-annotaror】アノテーションツール |  |
11. 以上
YOLO V5を利用すると、AIのネットワーク定義などせずとも**いとも簡単に物体検知させることができました!BIGデータさえあれば**(そこが地味に大変😅)誰もが簡単にモデル作成できてしまうので、YOLO V5はとっても便利ですね。
お疲れ様でした!