labelImgでアノテーション作業が済んでいて、前置きはどうでもいいので増殖だけしたい人はこちら
はじめに
tiny YOLOで独自データセットでの物体検出のモデル作成に取り組んでいるが、
なかなか精度が上がらず、パラメータの調整だけでは限界と思い始めてきた。
学習に使う画像データは200枚程度で行っており、画像データを探してくるのもアノテーション作業もどちらもめんどくさいので、
できればパラメータ調整だけで精度を上げられないかと試みていたが、
改善が望み薄そうだったので学習用データの方を工夫してみようということにした。
データ拡張(data augmentation)
機械学習を行う際に、学習に必要な学習用のデータを揃えるのは
機械学習を行う者の鬼門となっている(受け売り)。
そのため、データ拡張(data augmentation)という手法があって、
一枚の画像に対して、回転、拡大、縮小等を行って別の画像として学習データを用意する手法がある。
Googleの画像検索で持って来れる画像は全て使い切っているため、
今回は既に手元にある画像に対して加工する形でデータの水増しをしてみることにする。
labelImg
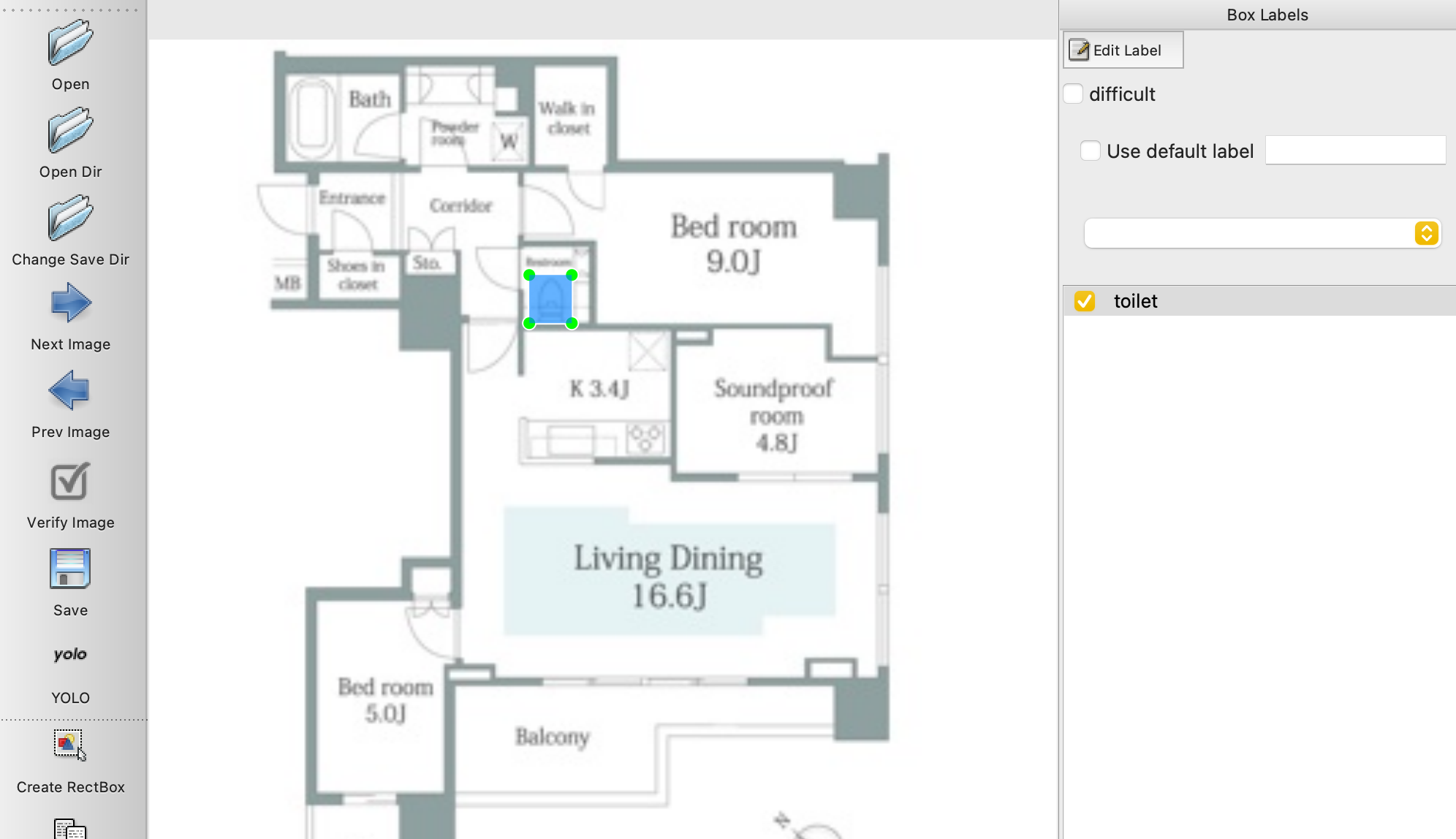
物体検出の学習を行う場合、画像内の**「どこ」に「なに」**があるかが示されている学習用データを準備する必要がある。
labelImgはこんな感じで、画面内の「どこ」に「(事前に定義した)なに」があるのかを示してあげて、学習用のデータを準備してあげることのできるツールになる。
データ拡張
データ増殖流れ
- オリジナル画像に対するアノテーション
- 増殖
オリジナル画像に対するアノテーション
labelImgを使ったアノテーション作業を行います(YOLO)
アノテーション作業の記事
今回のサンプル

画像ファイルと同じ名前で.txtファイルが出来上がります。

アノテーション後データの増殖
増殖パターン
今回は、画像を
- 上下反転
- 左右反転
- 上下左右反転
させます。



アノテーションの.txtファイルの内容
0 0.798438 0.223438 0.059375 0.071875
・・・
画面の左上を始点(x:0,y:0)として
| 項目 | 内容 |
|---|---|
| 0 | label番号(0:toilet,1:kitchen,2:bath) |
| 0.798438 | xの座標 |
| 0.223438 | yの座標 |
| 0.059375 | box横幅(x) |
| 0.071875 | box縦幅(y) |
変換の考え方
上下 or 左右反転の場合、boxサイズについては変更なし
xとyの座標は左上が(0.00, 0.00)、右下が(1.00, 1.00)
上下反転の場合はy座標の反転になるので、(1 - y座標)
左右反転の場合はx座標の反転になるので、(1 - x座標)
上下左右の場合は、どちらも座標反転する(1 - x座標)(1 - y座標)
増殖させるコード
画像の加工はこちらを参考にさせていただきました。
反転した画像に対となるアノテーションファイルを作成する作りになってます。(今回はjpgのみ対応してます)
import os
import cv2
img_dir = '99_layout_tmp/' # labelImgで結果を出力したディレクトリ
def main():
for file in os.listdir(img_dir):
name, ext = os.path.splitext(file)
print('base:' + name + ' ext:' + ext)
if ext == '.jpg':
img = cv2.imread(img_dir + file)
label_info = load_labeldata(name)
flipped_y(img, name, label_info)
flipped_x(img, name, label_info)
flipped_xy(img, name, label_info)
def flipped_y(img, filenm_base, label_info):
img_flip_ud = cv2.flip(img, 0)
cv2.imwrite(img_dir + filenm_base + '_flipped_y.jpg', img_flip_ud)
f = open(img_dir + filenm_base + '_flipped_y.txt', 'a')
for data in label_info:
label, x_coordinate, y_coordinate, x_size, y_size = data.split()
f.write(label + ' ' + x_coordinate + ' ' + turn_over(y_coordinate) + ' ' + x_size + ' ' + y_size + '\n')
f.close()
def flipped_x(img, filenm_base, label_info):
img_flip_lr = cv2.flip(img, 1)
cv2.imwrite(img_dir + filenm_base + '_flipped_x.jpg', img_flip_lr)
f = open(img_dir + filenm_base + '_flipped_x.txt', 'a')
for data in label_info:
label, x_coordinate, y_coordinate, x_size, y_size = data.split()
f.write(label + ' ' + turn_over(x_coordinate) + ' ' + y_coordinate + ' ' + x_size + ' ' + y_size + '\n')
f.close()
def flipped_xy(img, filenm_base, label_info):
img_flip_ud_lr = cv2.flip(img, -1)
cv2.imwrite(img_dir + filenm_base + '_flipped_xy.jpg', img_flip_ud_lr)
f = open(img_dir + filenm_base + '_flipped_xy.txt', 'a')
for data in label_info:
label, x_coordinate, y_coordinate, x_size, y_size = data.split()
f.write(label + ' ' + turn_over(x_coordinate) + ' ' + turn_over(y_coordinate) + ' ' + x_size + ' ' + y_size + '\n')
f.close()
def turn_over(coordinate):
val = 1 - float(coordinate)
return '{:.6f}'.format(val)
def load_labeldata(filenm):
try:
f = open(img_dir + filenm + '.txt', 'r')
return f.readlines()
except Exception as e:
print(filenm)
print(e)
finally:
f.close()
main()
実行結果
このような感じで、画面の反転に合わせてラベルも移動してくれています。




おわりに
データ量が4倍になったこともあり、モデルの精度が結構上がりました。
1度作ると、何度も使えるので便利だと思います。
少し難易度も上がりますが、もっと精度が顕著に上がりそうであれば「回転」「拡大・縮小」もやってみたいと思いました(引き算ではない少し複雑な計算が必要になるので今回はやらなかったですが、どこかのタイミングでやってみようと思います)
参考