YOLOを採用した自前のデータセットで学習するという記事は日本語サイトとしても沢山存在するが、
v2となると(さらにはtinyになると)なかなか情報が出てこず、大体どれもv3以降のドキュメントに辿り着いてしまい、
モデル作成(+作成後の変換)までに結構つまったので整理の意味も込めて残してみる。
前段
YOLOとは
リアルタイムの物体検出のアルゴリズムの一つで、
入力画像(や映像)の中から指定された物体の位置とカテゴリを特定します。
例えば、こんな感じで間取り図からトイレの位置を検出してみたりできます。
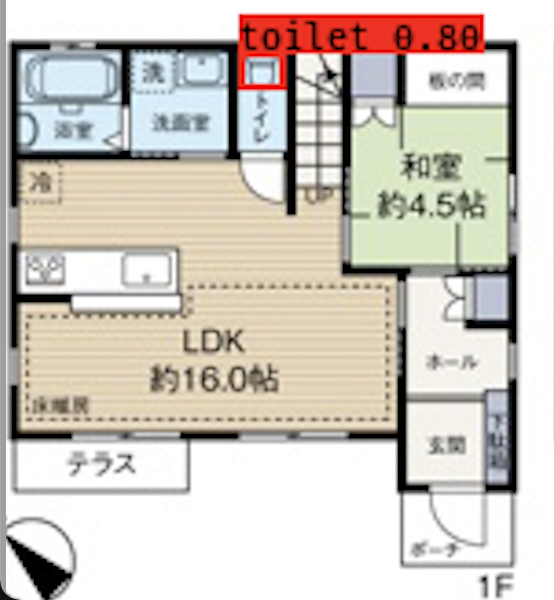
「You only look once」の略で、darknetというCとCUDAで書かれたオープンソースのニューラルネットフレームワークを用いて実装されています。
darknetはCPUとGPUでの計算をサポートしていて、高パフォーマンスを実現するためにCで構成されています(あと導入が簡単)
darknetの詳しいことについては公式を確認ください。
Tiny YOLOv2を採用する背景
前述の通り、YOLOについては既にv5まで存在し(2021/4月時点)、
YOLO関連の検索上位はv3以降の情報で占拠されている状態になっています(私感)。
検索条件にv2をつけてもあまりヒットしてこないなー、、という感じです(私感)。
ではなぜv2なのかでいうと、
作成したモデルをUnityのNN推論ライブラリであるBarracudaで使うことを最終的な目的としており、
そちらでサポートされているのがYOLOv2(tiny)ということで、今回はv2を採用しています。
Barracudaのモデルサポート情報はこちら
独自モデル作成までの流れ
ざっくりと、
学習データの準備→darknet内パラメータファイル修正→必要ファイルの配置→学習
となります
学習データの準備(アノテーション作業)
今回、参考のベースにさせてもらった記事では、BBox Label Toolというものを使ってアノテーションを行っていますが、
動作環境がpython2なのと、他の画像認識アーキテクチャを採用するときに幅広く使いたいという強欲さが相俟って、
色々調べた結果、サポート幅の広そうなlabelimgを使ってみることにしました。
導入とアノテーションについてはこちらの記事を参考にさせていただきました。
本記事では簡素な内容しか記載しないので、参考にした記事を参照いただくこと推奨
labelimgの導入
本家READMEベースで進めていきます
$ git clone https://github.com/tzutalin/labelImg.git
$ brew install qt # Install qt-5.x.x by Homebrew
$ brew install libxml2
$ pip install pyqt5 lxml # Install qt and lxml by pip
$ cd labelImg
$ make qt5py3
$ python3 labelImg.py
アノテーション作業
事前に準備しているデータが置いてあるフォルダを指定して、
ひたすらにラベル付け作業をしていく
(図はトイレを教えるためのデータを準備してます)
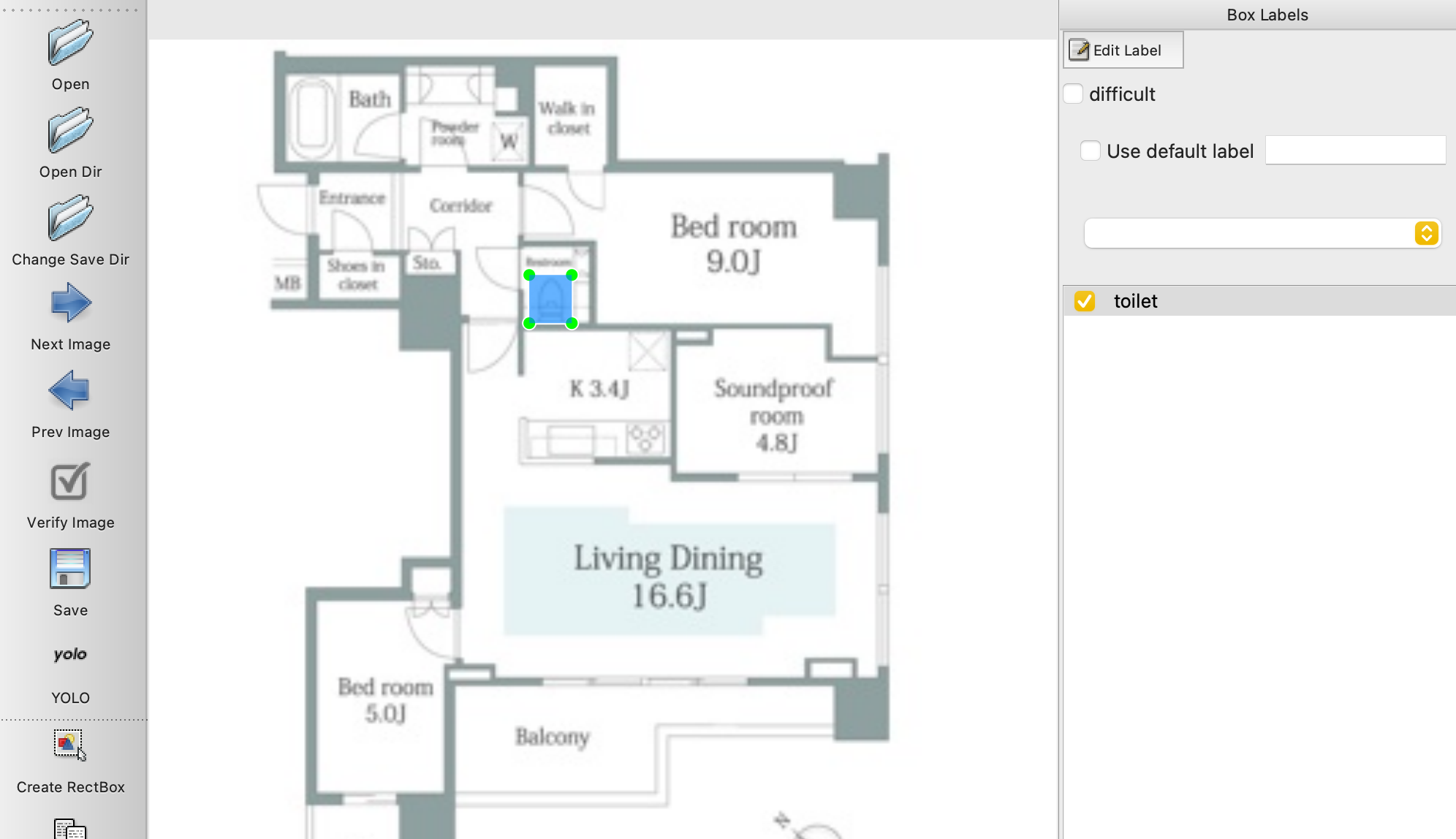
labelimgのどの記事にも注意として書いてあるので、ここでも!
アノテーション作業を開始する前に必ず「Save」の下にある形式を「YOLO」に変える必要あり。
これがYOLO以外だとアノテーション作業をやり直す必要があるみたいです・・・

あとはアノテーション→保存→アノテーション→保存・・・・と繰り返していきます。
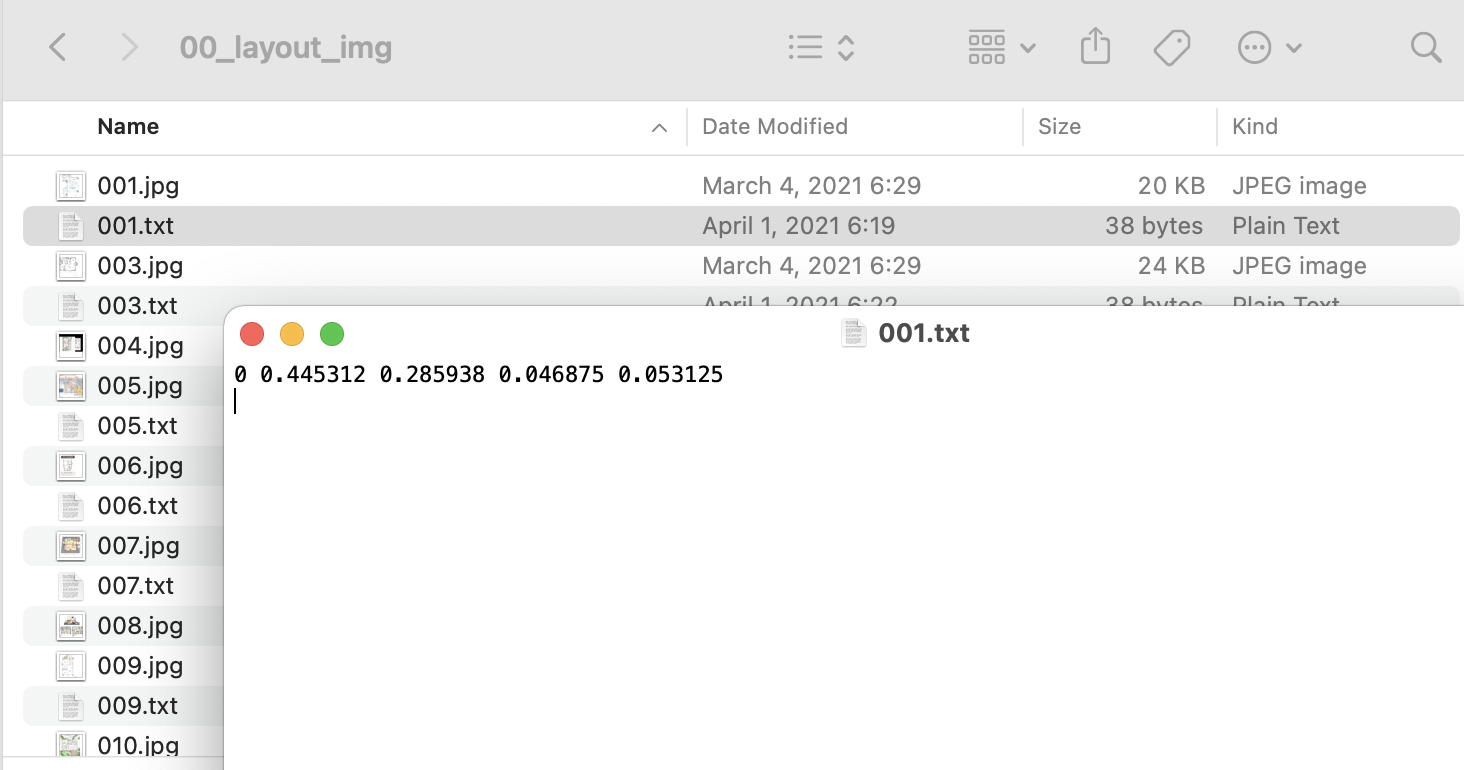
そうすると、こんな感じでjpgに対するアノテーションデータ(.txt)ができていきます。
darknetの導入と設定
darknetをcloneしてきて、学習データの配置とcfgファイルの修正、クラス情報の設定などを行います。
この手順ではlocal端末(Mac)での学習手順にしています。
google colab使用する場合は読み替えてください。
darknetの取得
darknetをローカルに取得
# clone
$ git clone https://github.com/pjreddie/darknet.git
$ cd darknet
# GPUを使用する場合はMakefileのGPUを0から1に変えてあげる(MacはGPU使えない)
$ sed -i 's/GPU=0/GPU=1/g' Makefile
#create
$ make
cfgファイルの編集
...darknet/cfg/yolov2-tiny-voc.cfg
に対して編集を行います。
端末と学習内容に合わせて以下を編集
L3 batch=64
L4 subdivisions=8
この設定値については以下参照
https://github.com/pjreddie/darknet/issues/224
追記
処理できそうならbatchもsubdivisionsも"1"にできれば
40000回の学習が1~2時間くらいで完了します。(Google Colab計測)
L124 classes = 学習させたいラベル数
L118 filters = (classes + 5) * 6
学習データの配置
darknet/data/obj
フォルダ配下に学習で使ったイメージデータと、それの対となるlabelimgで出力した.txt
ファイルを配置してあげる。
画像データとテキストデータが1対1になっていないと、学習開始時にエラーが発生します
訓練データ、テストデータの仕分け
準備した学習データを
学習を行うための訓練データと精度を測るためのテストデータに仕分けする。
学習データを配置したdarknet/data/obj配下に以下pythonコードを配置
import glob, os
# Current directory
current_dir = os.path.dirname(os.path.abspath(__file__))
# Directory where the data will reside, relative to 'darknet.exe'
path_data = 'data/obj/'
# Percentage of images to be used for the test set
percentage_test = 10;
# Create and/or truncate train.txt and test.txt
file_train = open('train.txt', 'w')
file_test = open('test.txt', 'w')
# Populate train.txt and test.txt
counter = 1
index_test = round(100 / percentage_test)
for pathAndFilename in glob.iglob(os.path.join(current_dir, "*.jpg")):
title, ext = os.path.splitext(os.path.basename(pathAndFilename))
if counter == index_test:
counter = 1
file_test.write(path_data + title + '.jpg' + "\n")
else:
file_train.write(path_data + title + '.jpg' + "\n")
counter = counter + 1
percentage_testの値が学習データ内に占めるテストデータの割合になります。
ここの設定は精度に影響出てくるのでデータセットの内容や学習結果でチューニングする項目になってきます。
上記のコードの場合、テストデータは全体の10%になります。
配置したディレクトリまで移動して、以下のコマンドでプログラムを実行
$ python process.py
正常に実行が完了すると、同ディレクトリに以下のファイルが作成されます。
- test.txt
- train.txt
中身を確認すると、学習データのパスが記載されています

namesファイルとdataファイルを作成
以下の2ファイルを新規作成して内容を編集する
- darknet/cfg/obj.data
- darknet/cfg/obj.names
classes=1
train = data/obj/train.txt
valid = data/obj/test.txt
names = cfg/obj.names
backup = backup/
- classes : 学習させたいラベル数
- train : 先ほど出力した訓練データ情報
- valid : 先ほど出力したテストデータ情報
- names : ラベル情報を書くnamesファイル
- backup : 学習の途中結果のモデルと最終的な成果物モデルが出力される先
toilet
今回は間取り画像のトイレだけを学習させるので1行になります
conv.23ファイルの配置
darknetディレクトリ直下にconv.23ファイルを配置
以下のwgetコマンドで取得できます。
v2の公式からもダウンロードできます。
事前に用意されている畳み込み重みのセットとなっていて、
学習を始めるために必要な情報です。
自分で用意するか、提供されているものを使うかします。
wget https://pjreddie.com/media/files/darknet19_448.conv.23
学習
待ちに待った学習開始の時間です
参考記事をもとに、darknet配下に移動して以下コマンドを実行
./darknet detector train cfg/obj.data cfg/yolov2-tiny-voc.cfg darknet19_448.conv.23
・・・
30: 8.291001, 14.352291 avg loss, 0.000100 rate, 377.533053 seconds, 1920 images, 3.036925 hours left
Saving weights to backup//yolov2-tiny-voc_final.weights
If you want to train from the beginning, then use flag in the end of training command: -clear
何時間も待ちますが、無事に学習が完了するとbackup配下にyolov2-tiny-voc_final.weightsというファイルが出力されています。
このweightsファイルと学習に使ったcfgファイルを使って、推論とかコンバートとかしていく感じになります。