8章の内容
- 8.1 ネットワークをより深く
- 認識精度を高めるためのテクニックを紹介
- 8.2 ディープラーニングの小歴史
- 有名なネットワークを紹介
- 8.3 ディープラーニングの高速化
- 高速化手法を紹介
- 8.4 ディープラーニングの実用例
- 代表的なユースケースを紹介
- 8.5 ディープラーニングの未来
- さらなる応用ユースケースを紹介
- 8.6 まとめ
- 本章で学んだことのまとめ
認識精度を高める手法
- Data Augmentation
- 回転や縦横移動をさせて画像データを増幅する
- 層を深くする
- フィルタが小さくでき、パラメータが減る
- 階層的に情報を抽出することで学習が効率化する
DLを使った代表的な画像認識手法
VGG
基本的なCNNだが、小さなフィルタによる畳み込み層が連続しているのが特徴
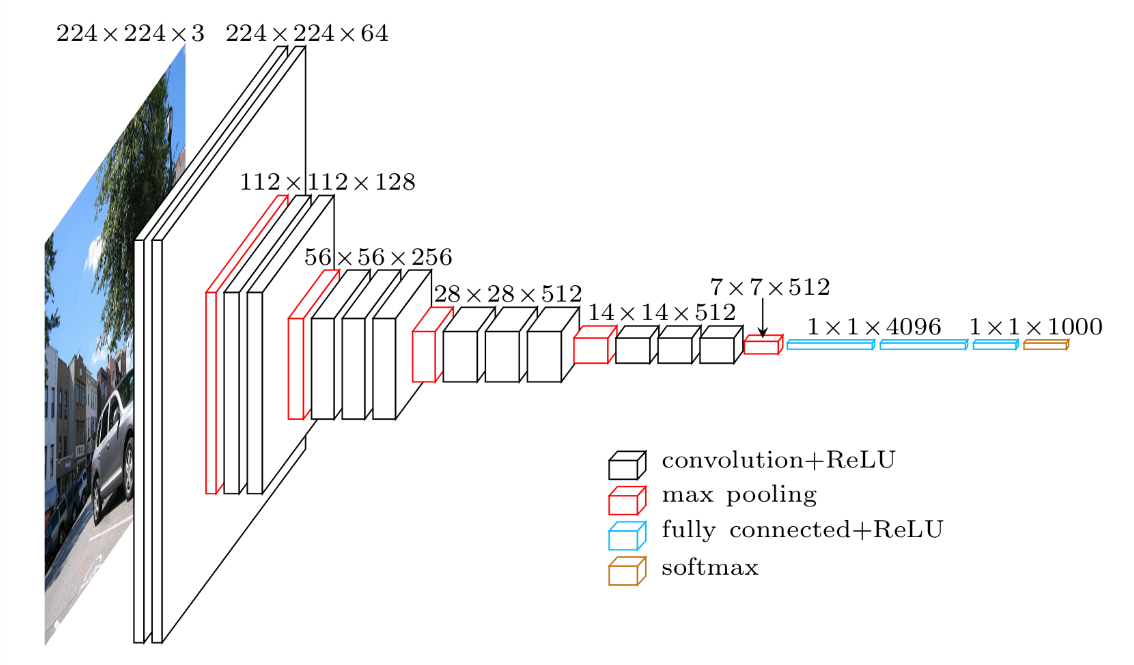
(1より引用)
GoogLeNet
同一階層が並列に存在しているのが特徴(インセプション構造)
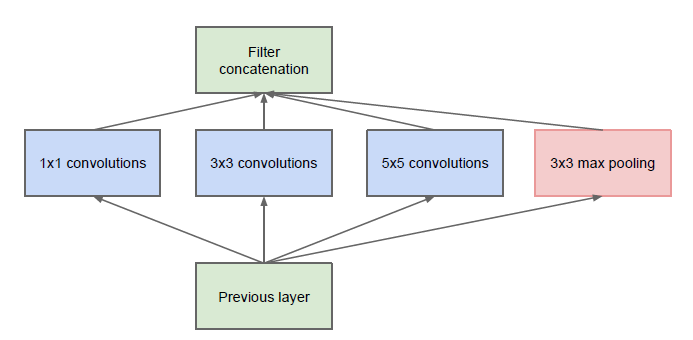
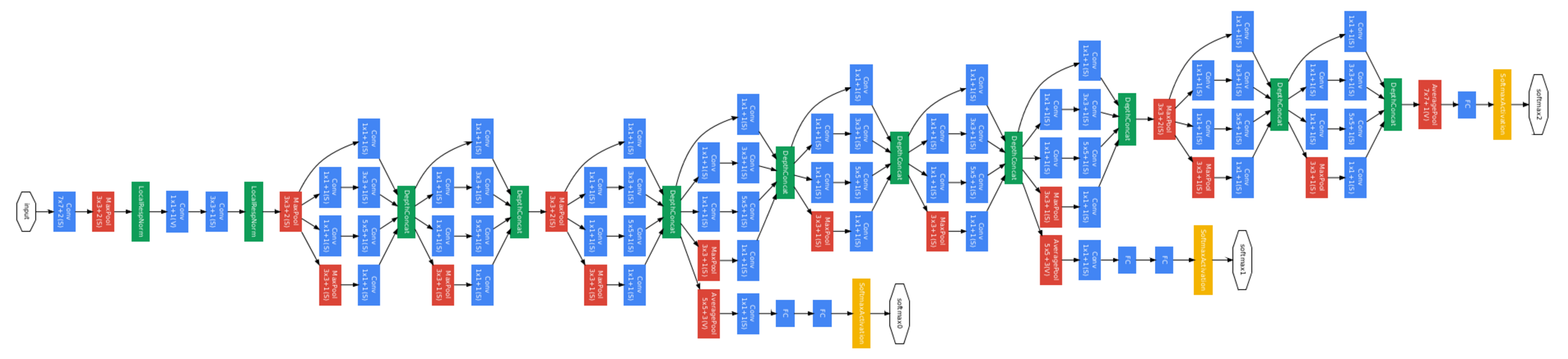
(2より引用)
Residual Network (ResNet)
層をまたいで出力に合算するスキップ構造が特徴
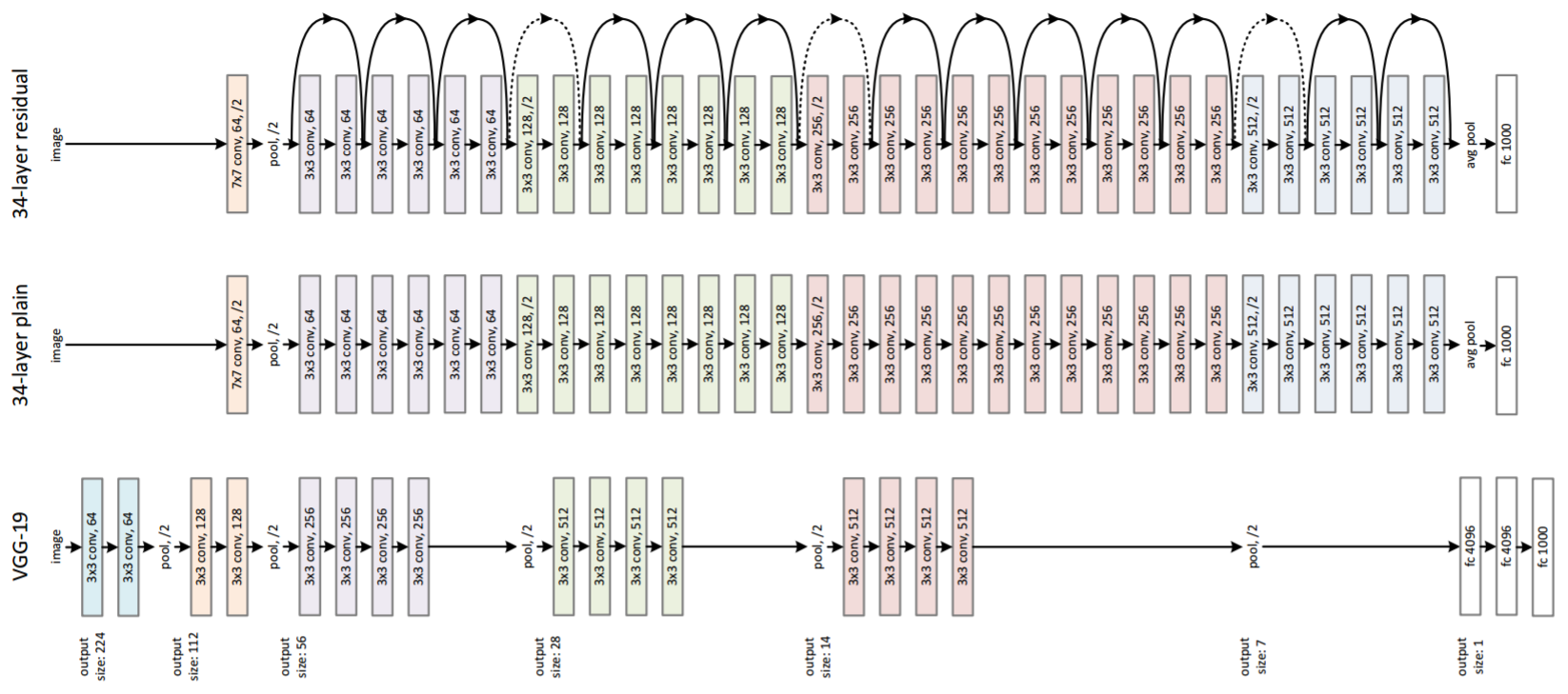
(3より引用)
ディープラーニングの高速化
- GPUによる高速化
- 分散学習
- 演算精度のビット削減
- 通常の64ビットや32ビットの浮動小数点数ではなく、16ビットの半浮動小数点数を使う
- Google TPUは8ビットの計算ユニットで計算を行う
- 最近では重みや中間データを1ビットで表現する手法も提案されている4
書籍で紹介されているディープラーニングの実用例
物体検出
画像中から物体の位置の特定を含めてクラス分類を行う問題(複数のクラスも検出する)
例としてR-CNNは最初に物体と物体以外を識別する「候補領域抽出」を行い、抽出された領域に対してCNNでクラス分類を行っている
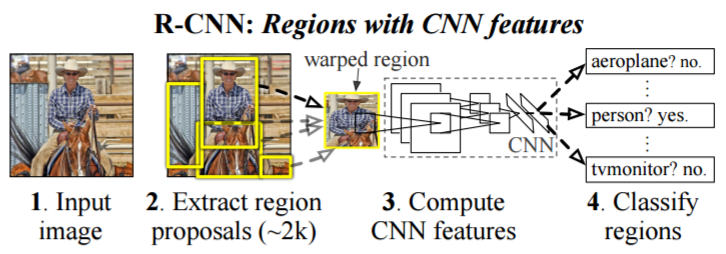
(5より引用)
セグメンテーション
画像に対してピクセルレベルでクラス分類を行う
FCN (Fully Convolutional Network=全てが畳み込み層のネットワーク)を用いることで1回のforward処理ですべてのピクセルに対してクラス分類を行い、中間データの空間ボリュームを保持したまま最後の出力まで処理する。
また、最後にバイリニア補間による拡大をデコンボリューション(逆畳み込み演算)によって実現する。
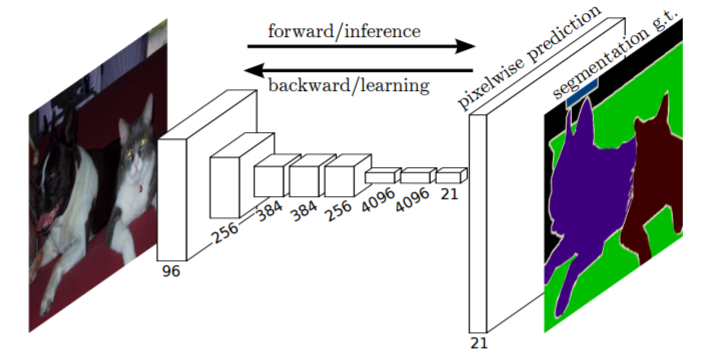
(6より引用)
画像キャプション生成
画像を与えると、その画像を説明する文章を自動で生成する
NIC (Neural Image Caption) ではCNNで画像認識、RNN(再帰的なネットワーク)で言語生成を行っている
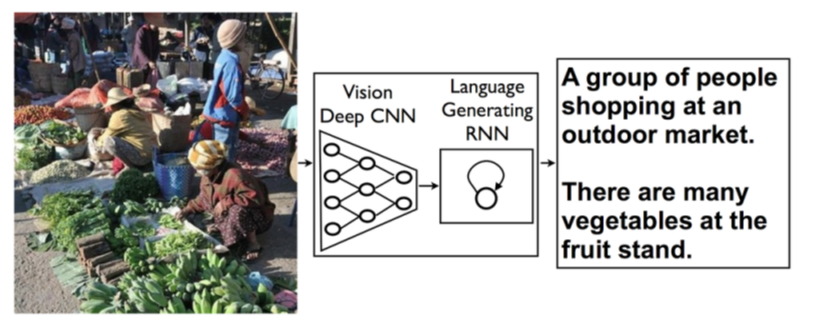
(7より引用)
画像スタイル変換
2つの画像を入力し、新しい画像を生成する

(8より引用)
画像生成
学習データに存在しない画像を新規に生成する
DCGAN(Deep Convolutional Generative Adversarial Network)は画像生成を行うGenerator(生成器)と、画像が本物かどうかを判定するDiscriminator(識別器)が競い合うことで精度の高い画像を生成する(敵対的ネットワークとも呼ばれる)

(存在しない「ベッドルーム」画像を生成した例、9より引用)
自動運転
CNNベースのSegNetは走路環境のセグメンテーションを高精度で行う。

(10より引用)
なお、自動運転には4つのレベルがある。
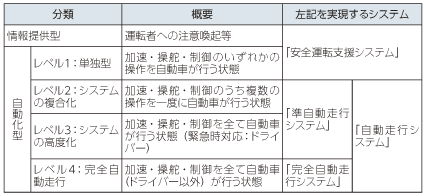
(出典)官民ITS構想・ロードマップ(案)(平成26年)11
強化学習(Deep Q-Network)
DQNは、動作に対する価値観数をCNNで近似することで、画像に対しての動作を最適化する学習を行う
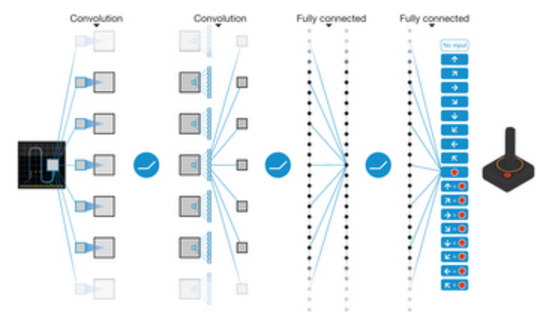
(12より引用)
その他の実用例
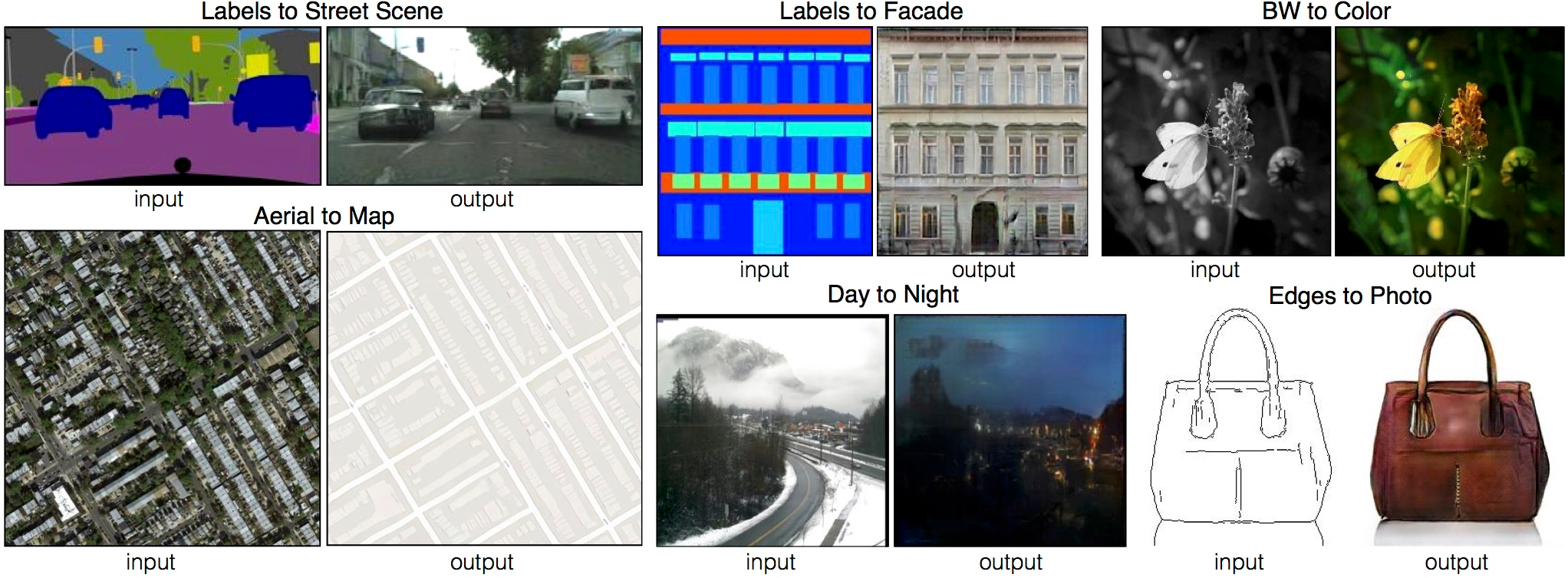
画像から画像生成(pix2pix13, CycleGAN14)
航空画像から地図生成、線画から物品画像生成、白黒写真からカラー写真生成など

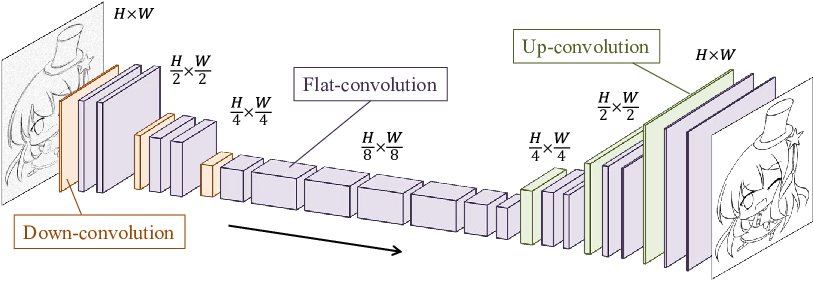
アニメへの応用
ラフスケッチの自動線画化、線画着色、白黒アニメのカラー化、アニメキャラクター生成など15

アイテムピッキングの強化学習
Googleはロボットフィンガーでものを掴む動作を人間よりも速い速度で学習させる実験を公開している16
(14台のロボットアームに分散自己学習させて人間が数年かけて覚える動作を爆速で経験して身につけさせる恐るべきムービーをGoogleが公開 - GIGAZINE)
音声認識
音声テキスト変換や、複数話者のセグメンテーションなど音声データに対してもディープラーニングが採用されている
時系列データなのでRNNがよく使われるが、CNNが使われるケースも多い
自然言語処理(形態素解析、構文解析など)
自然言語の基盤処理である形態素解析(単語分割&品詞判定)や係り受け構文解析などでもディープラーニングが使われているものは精度が高いとの評判がある
機械翻訳
Google翻訳が最近end-to-endのニューラルネットワークベースのもの(NMT: Neural Machine Translation)になったため話題となった
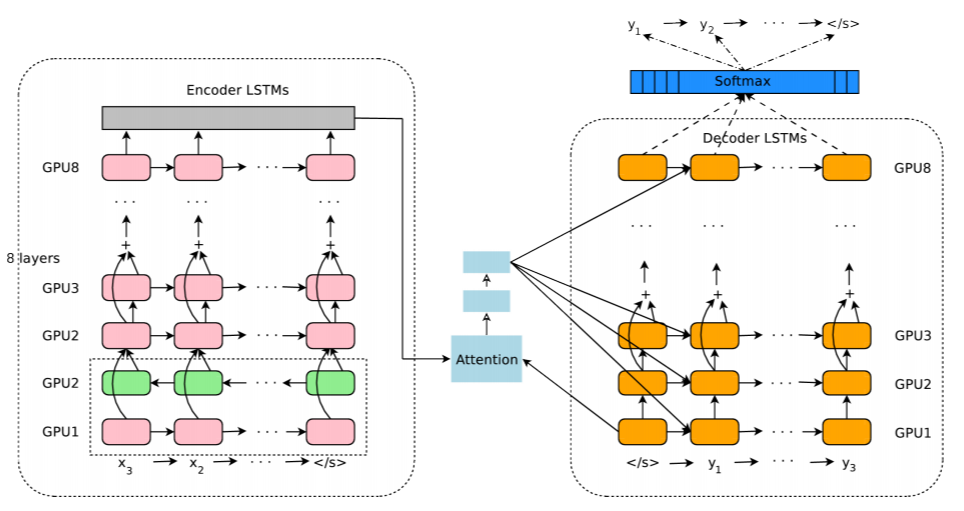
(21より引用)
Attentionメカニズムを用いると、単語と単語の対応関係(アラインメント)を明示的に与える必要がない

(22より引用)
メール返信文生成
Google Smart Replyはメールの内容をRNN(LSTM)で「読み」、簡単な返信文候補を3つ生成する23
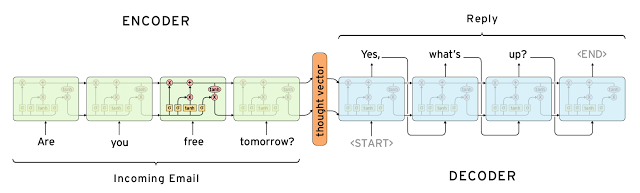
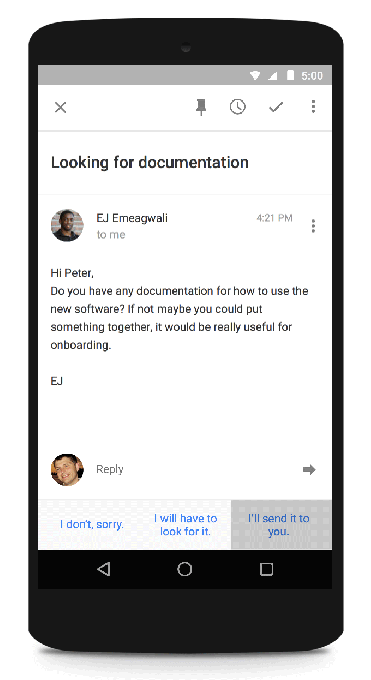
その他の文生成
近年の研究では、数値予報データからの天気予報文の生成24や日経平均株価チャートからの概況文の生成25など、限定されたドメインでの文生成にディープラーニングが用いられている
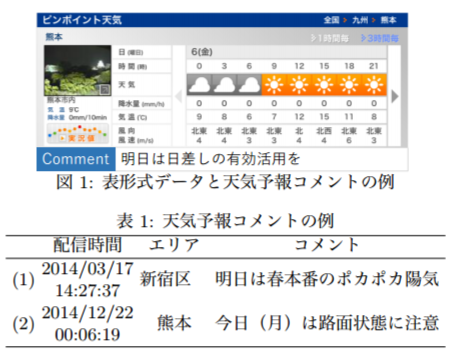
(24より引用)
まとめ
- 認識精度を高める手法として、データの機械的な増幅や層を深くすることが挙げられる
- GPU利用や分散学習、ビット精度の削減によって計算速度を高速化できる
- ディープラーニングを用いたアプリケーションとして、物体検出やセグメンテーション、画像スタイル変換や生成のほか、自動運転、アイテムピッキングの強化学習、音声認識、自然言語処理タスク(形態素解析や係り受け構文解析など)、機械翻訳、メール返信文生成などが挙げられる
ディープラーニングのまとめサイト
参考文献
- GoogleのAI開発を支えるディープラーニング専用プロセッサ「TPU」 - ISCA論文レビュー版から、その仕組みを読み解く (1) ニューラルネット需要を支えるために開発された専用チップ | マイナビニュース
- 最近のDQN(SlideShare)
- Deep Learningの基礎と応用(SlideShare)
- Girl Friend Factory - 機械学習で彼女を創る - - Qiita
- 自然言語処理における畳み込みニューラルネットワークを用いたモデル - Qiita
- リカレントニューラルネットワークの理不尽な効力(翻訳) - Qiita
- seq2seq で長い文の学習をうまくやるための Attention Mechanism について - Qiita
- Inside of Deep Learning あるいは深層学習は何を変えるのか - Qiita
- PaintsChainer -線画自動着色サービス-
-
Karen Simonyan and Andrew Zisserman(2014):Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv:1409.1556[cs](September 2014). ↩
-
Christian Szegedy et al(2015):Going Deeper With Convolutions. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). ↩
-
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun(2015):Deep Residual Learning for Image Recognition. arXiv:1512.03385[cs](December 2015). ↩
-
Matthieu Courbariaux and Yoshua Bengio(2016):Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1. arXiv preprint arXiv:1602.02830 (2016). ↩
-
Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik(2014):Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In 580–587. ↩
-
Jonathan Long, Evan Shelhamer, and Trevor Darrell(2015):Fully Convolutional Networks for Semantic Segmentation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). ↩
-
Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan(2015):Show and Tell: A Neural Image Caption Generator. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). ↩
-
neural-style "Torch implementation of neural style algorithm" ↩
-
Alec Radford, Luke Metz, and Soumith Chintala(2015):Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv:1511.06434[cs](November 2015). ↩
-
Volodymyr Mnih et al(2015):Human-level control through deep reinforcement learning. Nature 518, 7540 (2015), 529–533. ↩
-
phillipi/pix2pix: Image-to-image translation using conditional adversarial nets ↩
-
junyanz/CycleGAN: Software that can generate photos from paintings, turn horses into zebras, perform style transfer, and more (from UC Berkeley) ↩
-
14台のロボットアームに分散自己学習させて人間が数年かけて覚える動作を爆速で経験して身につけさせる恐るべきムービーをGoogleが公開 - GIGAZINE ↩
-
Wu et al., Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation, 2016 ↩
-
Bahdanau et al, Neural Machine Translation by Jointly Learning to Align and Translate, ICLR, 2015 ↩