(題を付けかえました。このページ中の画像は、それぞれの引用先のサイトの画像を表示しているものです。)
最近、Deep Learning関連では、アニメ産業自体にも影響しやすい技術が多数開発されているように思う。
まず、セル画の時代からある輪郭線をラフスケッチからトレースする作業が自動化されてしまうのではないか?


web サービス■全層畳込みニューラルネットワークによるラフスケッチの自動線画化
次の2つの技術によれば、そのような線画画像に基づいて、色指定と着色の工程を自動化できてしまう可能性がないか?

しかも、簡単な方法で色指定をして着色させることもできています。
![初心者がchainerで線画着色してみた。わりとできたの画像の色指定例]
(https://qiita-image-store.s3.amazonaws.com/0/61566/d9cad146-1980-fb8c-059b-d824d527ca9a.jpeg)
作者の方がWEBサービスを提供を開始しました。
線画の着色のデモ
自分のPCで動作させたい方は、以下のリンク先へ
-
PaintsChainer
「ラフな写真を線画化できます」
「自由に色を指定できます」
「着色スタイルを選べます」


さらには、登場人物のキャラクタデザインにおいてさえ、Deep Learningの可能性が示されている。

自動生成を試してみたい方はmattyaさんによる以下のサイトで試してみてください。
Chainer-DCGAN
さらに自動生成される画像の大きさと質が向上している。
2017-08-21
「自動生成」された美少女は、手書き美少女と区別がつくのか?

さらには、「『なぜか我々が放り込まれている世界』を『ほんとうの世界(美少女)』」に直接Deep Learningで変換するにいたっています。
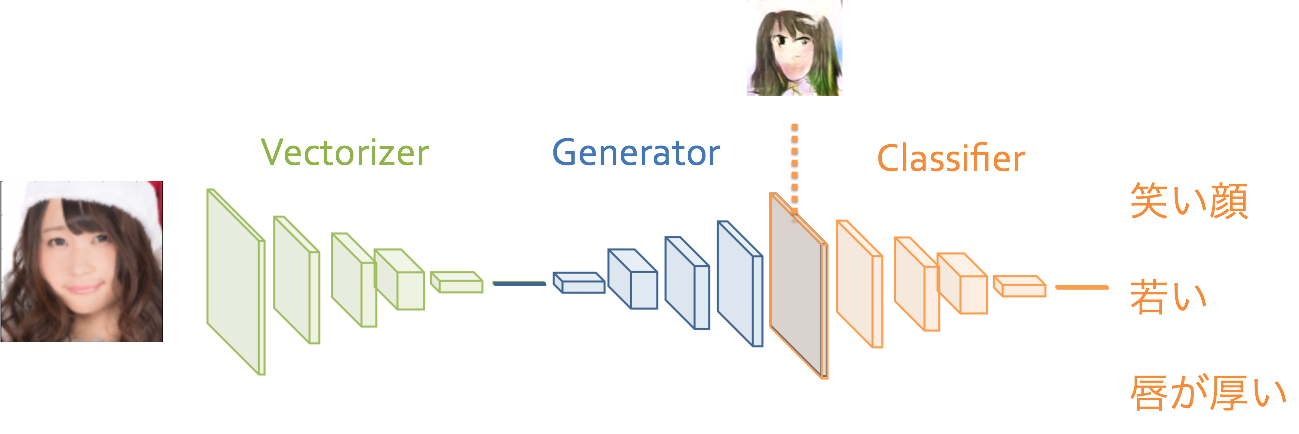
github https://github.com/Hi-king/kawaii_creator
追記:
アニメ画像の特徴としては、背景領域の領域分割がされていて(セル画の輪郭線)、減色処理(セル画では利用できるペイントの数が限られています)がなされていて、単純化されている傾向があると思います(「サザエさん」などのリミテッドアニメの世界。この時代は人がそのような単純化した背景を作画する。)。
セル画の時代から、デジタルでの作成の時代になって、作画の色の使える範囲が大幅に広がったこともアニメを変えています。作画の表現力が広がったことは、一方ではそれだけの作画を手作業でする人の大変さを増しているともいえるのでしょうか。
また、最近のアニメでは、着目している部分にだけピントをあてて、その他の部分にはボケを与える処理がされています。(「響け!ユーフォニアム」など。この時代では、作画した時点で各奥行きごとのレイヤーでデータを持っているので、その特定のレイヤー以外に対してだけピントを合わせ、他のレイヤーに対しては、画像処理によってボケを加えている様子がわかります。「響け!ユーフォニアム2」のオープニングは、カメラの視点が微妙にゆらいでおり、そのことによって机などが3Dとしてつじつまのあう動きをしています。その効果が空間としての存在感を感じさせるものになっています。)
実写画像を元に加工してアニメの背景画像を作る傾向は増えてきているように感じています。(電車から見える町並みのシーン、「3月のライオン」の次回予告に使われている町並みのシーン。ただ、最近はほぼ実写そのものという感じにまで加工が減ってしまっていた。)
背景を実写動画から解釈して、それを元にアニメの背景らしく画像をつくりあげるDeep Learningが出現しても、もはや驚きはないような気がしてきます。次に示すchainer-gogh は、静止画に限る理由はありません。
- chainer-gogh 画風を変換するアルゴリズム
そこで、動画に対してその手法を適用した結果があります。この動画の中で、どのように動画に対してchainer-goghを適用したのかが簡潔に書いてあります。
上の画風の変換では、対象物の理解はないままに行われるアルゴリズムですが、Deep Learningは対象物の理解をした上での処理が日に日に可能になってきているのを感じています。
元論文やPrismaではゴッホの画風変換に取り組んでいましたが、この記事ではもっと皆さんに身近な例と言える、漫画やゲーム・アニメ風のイラストへの画風変換に取り組んだ結果をご紹介します。
上記のような実画像の動画シーンの中からシーンの理解に基づく領域分割はDeep Learningで進んでいく技術の一つですから、それも近いうちにアニメっぽくする技術の中にとりこまれていくのではないかと期待しています。
「最近流行りのディープラーニングで中割もできるようになったらいいのにな。」
自動中割り hanepen β
という記事を見つけました。
「いま、日本のアニメの中に「3DCG」という大きなうねりがうまれています。使いどころ次第では、クオリティを向上させつつコストの削減ができてしまうという3DCG。」の3DCGの部分がDeep Learningに置き換えることができるのではないか。
猫の線画を着色するモデルを学習させた(pix2pix-tensorflow)
2024年追記
研究の進展がすごすぎる。
https://x.com/NaveenManwani17/status/1870158336253190184