概要
一時期話題になった、「猫の線画を書くと自動着色できる」というWeb上のデモを再現できるデータセットを用意して、似たような結果を得られるようにしました。
Webデモ
しばらく動かしておきますが、いずれ止める予定です。
オリジナル(Image-to-Image Demo - Affine Layer)と比較すると出力は異なりますが、一応それっぽく動いています。
オリジナルの出力:
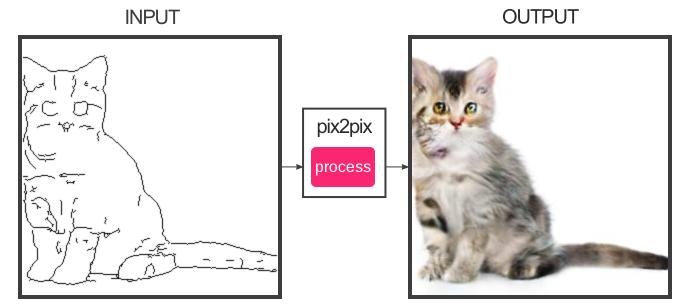
今回構築したモデルの出力:
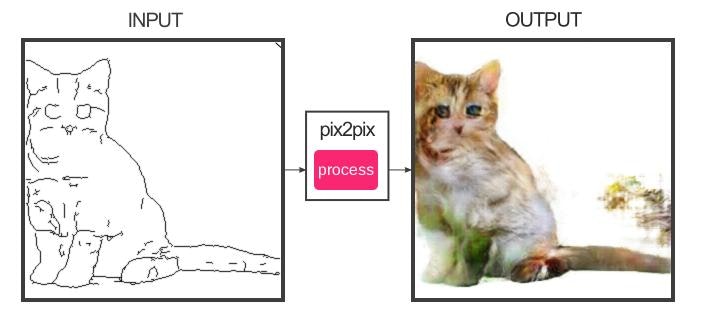
Image-to-Image Translation with Conditional Adversarial Networks (Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros)
通称pix2pixと呼ばれるこのニューラルネットワークは、2つのドメイン間の訓練画像群を用いて、単一の構造でさまざまなタスクに適用できる仕組みです。特にTensorFlowで記述されたWeb上のデモで、「猫の線画を着色してくれる」ということで広く話題になりました。
仕組み
既に多くの方が解説を書かれています。
生成ネットワークはEncoder-Decoderモデルとなっています。入力画像を低次元ベクトルに埋め込み、期待する出力へと復元する構造です。エンコーダ・デコーダ間の同じ階層同士を直接繋げるskip connectionを持ったU-Netという構造を用いています。
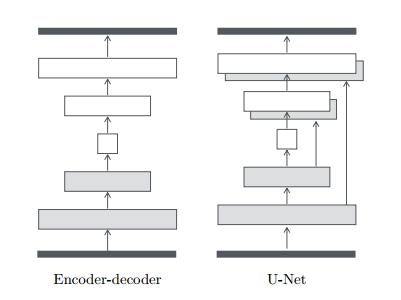
skip connectionをもたせることによって、中間層同士の特徴を直に伝播させ、細部の復元を忠実に行うことができるようになるようです。
また、エンコーダ側の上位の層にはdropoutを設けています。これにより、非決定的な中間ベクトルが得られるようになります。
この生成器の中間層の学習は、条件付きGAN(Conditional GAN)を用いて行われます。
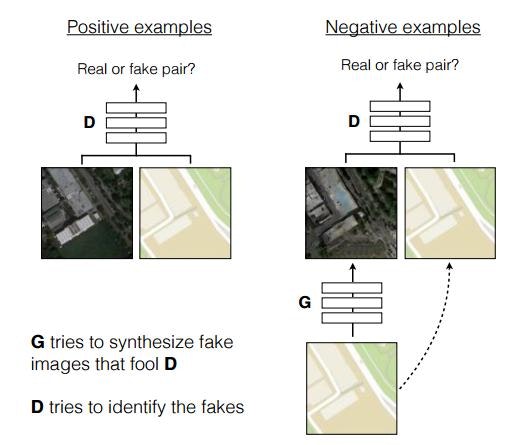
単純に生成画像だけを用いて真贋判定を行うのではなく、入力画像とペアで判定をさせます。これによってdescriminatorは2つの画像間の関係性の特徴を学習することになります。さらにこの結果はU-Net側の学習にも反映されます。実質的にEncoder-Decoderの目的関数の役割をdescriminatorが担うことになるようです。
一般的なGANではなんらかの分布からサンプリングしたベクトルに対して生成モデルを学習させますが、pix2pixではエンコーダによって獲得したベクトル表現を元に生成を行うことになります。ただ、エンコーダ側にdropoutが入っているので、実質的に乱数をサンプリングするのと近い結果になる、と理解しています。
discriminatorも単純な二値を返すのではなく、PatchGANで用いられている手法をとり入れています。出力を設計したパッチサイズ(実装では30x30)の領域ごとにfake/realの判定を行います。これにより、高周波成分の特徴をうまく取られられるようになるそうです。
低周波成分の学習は生成画像と訓練画像とのL1ノルムを求めることにより得ているそうです。この辺りは論文の中で実験的に確かめられています。
データセットの作成
猫画像のデータはPixabayから収集しました。APIで取得できる上限が500枚なので、(それなりにウェイトをいれつつ)スクレイピングで2000枚程度の画像を収集しました。その結果をChainerCVの訓練済みSSDモデルを使ってある程度機械的に猫画像とそうでないものを分類した後、手作業でより正確な分類と、pix2pixに向かない画像の排除を行いました。
この結果、1000枚程度の画像が残りました。この結果から、猫以外の背景部分を排除した画像を作成しました。これにはセマンティックセグメンテーションを用いました。
この結果から、線画抽出を行いました。これにはHolistically-Nested Edge Detection: HEDを用いました。
最終的に出来上がった訓練用画像の例を以下に示します。

出来上がった訓練画像をGoogle Cloud Storageに置き、Cloud Machine Learningを使ってモデルの訓練をしました。GCML用に若干コードを修正しています。
今回は1100枚程度の画像を400epoch回しています。トレーニングユニットの稼働時間は計50時間程度になり、料金は日本円で2,700円程度になりました。学習は200〜300epoch程度で十分だったかなあ、と今になって思います。
結果
それなりのモデルが一応構築することはできました。オリジナルのデモとは猫画像の訓練データが違うので当然出力は異なりますが、おなじようなことを誰もが再現できるような情報(画像データへのポインタ、データ生成処理)を残すという個人的な目的は達成できたかなと思います。
今後
猫画像の前景抽出に古いKerasを使っているという課題が残っています。訓練用データセットも配布されているので、ChainerCVのSegNetで訓練をさせてみたいと思っています。
アノテーションされた画像の大きさが不揃いなので、若干の加工が必要であるというところまではわかっています。これもうまく行ったら情報共有できるようにしたいところです。
進捗とさらにその先(7/19追記)
ChainerCVでのSetNet学習はうまくいっていません。データセットのサイズが不揃いであったり、その点をなんとか揃えても思うように収束しないという問題を抱えています。データによってはSegNetに与えると期待と異なるサイズの出力が出てきたりするので、なんとか調整をしつつ進めているのですが難しいです。
あと、今回の処理済みのデータセットと学習済みモデルを改めて公開することを考えています。
モデルとデータセット配布 (8/3)
github relaseページで配布をはじめました。
手元で再現した場合はこれらのデータを使ってみてください。
FYI
今年度の人工知能学会全国大会の中で、pix2pixに関する言及のある論文がありました。
地図情報にpix2pixを適用したらさまざまなタスクに応用できたという趣旨の内容なのですが、一つ特徴的な試みとして「地図の地形を表現するCS立体情報と地質情報を入力として、地すべり地形の検出」を行うものがありました。単純な地理的情報だけでは地すべり地形の検出ができない(学習できない)ので、地質の情報を新たに入力の追加チャンネルとして与えることで学習ができたそうです。