本記事はDeepLearning Advent Calendar16日目の記事です。
pix2pixについて(何番煎じかわかりませんが)紹介します。
14日目で触れられていてもう心が折れています。
pix2pixとは
先月公開されたGANの一種です。
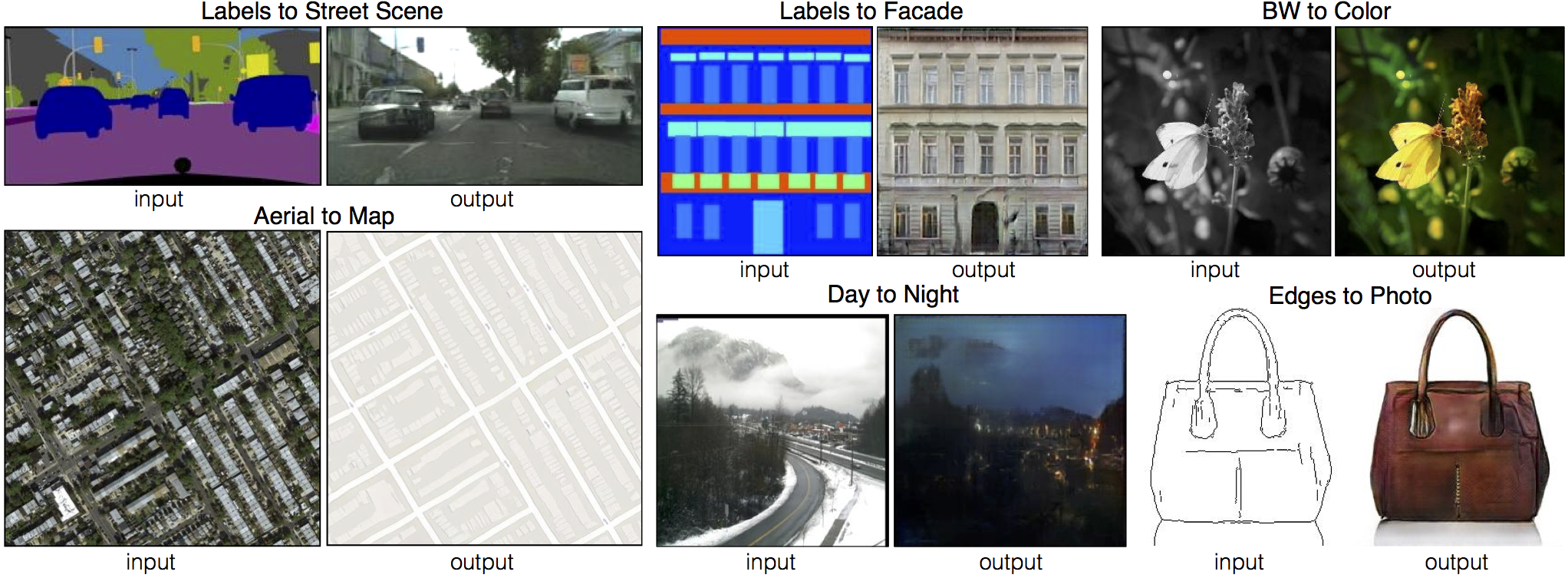
- プロジェクトページ https://phillipi.github.io/pix2pix/
- Experimentsにいろいろな適用例があっておもしろいです
- 論文 https://arxiv.org/pdf/1611.07004v1.pdf
- 実装
- Torch(本家) https://github.com/phillipi/pix2pix
- Tensorflow https://github.com/yenchenlin/pix2pix-tensorflow
- Chainer https://github.com/mattya/chainer-pix2pix
pix2pixでは対になった画像間の変換方法を学習します。
単一のネットワークだけでセグメンテーションやその逆変換、線画の彩色など様々な変換がそれっぽくできてとても興味深いですね。
pix2pixは、より厳密にはConditionalGANの仲間です。最近出たStackGANなんかも同類ですね。普通のGANでは無意味な乱数ベクトルを入力に画像を生成しますが、ConditionalGANでは文字通り何かしら意味を持つベクトル、生成のための条件(Condition)を入力に添えることで生成精度の向上をはかっているわけです。例えばテキストだとか画像だとか。pix2pixでは画像が生成の条件になるわけですね。
ここまでGANの仲間だと説明してきましたが、pix2pixは他のGANとは扱うタスクが異なります。たいていのGANは画像の生成タスクに用いられますが、pix2pixは画像の変換タスクが対象という点で立ち位置が大きく異なります。
ここがpix2pixのおもしろいところで、従来の画像変換タスク(セグメンテーションや白黒画像の自動彩色など)では個別に損失関数を設計していたところを、pix2pixではGANのアプローチを利用してDiscreminatorに損失関数そのものを学習させます。"正しい画像のペア"と”片方がGeneratorによる偽物のペア”をDiscriminatorに食わせることで、Discriminatorがそれっぽく損失を計算してくれるわけです。損失関数そのものも学習してくれるので様々な画像変換タスクに使えてしまう、この万能感が盛り上がりの理由でしょうか。この章めっちゃしたり顔で言ってますが間違ってたら指摘してください。
フレーム補完に使ってみる
論文では専ら1:1の画像変換を扱っているのですが、ネットワークの構造上はn:mも可能です。
今回は教師データを用意しやすいという理由で動画のフレーム補完をやってみたいと思います。
前後フレームを入力とし、その間の5フレームを生成させてみましょう。2:5(6チャンネル:15チャンネル)の変換です。
- コード: https://github.com/pekatuu/pix2pix-tensorflow/tree/multi_A
- tensorflow実装を少しいじっています。ネットワークそのものはほぼいじっていません。
- 教師データ: https://motchallenge.net/
- 手元にあったので。
- 2015, 2016をマージしてこのスクリプトでほげほげしました
- 教師データはこんな感じ

- わかりづらいですが左から5フレームがGeneratorの出力に対応するフレーム、右から2フレームが入力です。時系列でいうと1→2→3→4→5→0→6の順で並んでいて、Generatorは0と6を入力に間の5フレームを生成(補完)するかんじです
- train: 1789
- test: 1938
環境
- Ubuntu 16.04
- CUDA 8.0
- cuDNN 5.0
- Tensorflow r0.12
- GeForce GTX 660 VRAM 2GB
- 途中でドライバ入れ替えたらCUDAがGPU認識しなくなったので結局CPU使ってます
実行方法
python --phase train DATASET_NAME --fine_size 128 --load_size 132 --dataset_name pix3pix --input_nc 15 --output_nc 6 --data_per_image 7
input_ncとoutput_nc逆な気がしますがとりあえずそのままにしてます。
epochは5ぐらいしか回せてません。
実行結果

左がGrandTruth、右が生成した画像です。クリックするとYouTubeで動画みれます。
…どう見てもクロスフェードです。本当にありがとうございました。
クロスフェードとはいえフレーム間を滑らかに切り替えるという点では目的を達成できていると言えなくもないですし悪くないんじゃないですかね。明度がおかしいのは色空間の復元周りなのかもしれません。
pix2pixはあくまでピクセル単位の変換が目的で、変形はスコープ外ということなのでしょうか?Discriminatorをチューニングすればなんかできるのかもしれませんが今回はここまでです。
他のネタ
pix2pixでする必要性を無視すればいろいろネタがありそうです。
- フレーム予測
- 関連研究でConditional GANの利用例として紹介されてましたが、今回も教師データの順をいじればなんかそれっぽくなるんじゃないですかね(適当)
- G-Bufferみたいな中間レンダリング画像からから最終レンダリング画像生成
- 目的と手段が逆転した例
- 天気予報
- 気温とか風向とか地形とかビットマップにして食わせたらなんかわからないんですかね(適当)
ちなみにExperimentsにあったKITTIのセグメンテーションっぽい画像に触発されて、PascalVOCのセグメンテーション画像から元画像の復元を試みたのですが、全体的にすごい精神汚染度たかかったので掲載は自重しました。KITTIは車載カメラなので被写体の姿勢が限定的だったからいい感じだったのでしょうか?
まとめ
- pix2pixのかんたんな紹介
- pix2pixにフレーム補完させたらクロスフェードを学習した
- ちゃんと結果出てからAC参加すべきだと学んだ