皆さん、Word2vec の仕組みはご存知ですか?
Word2vec は gensim や TensorFlow で簡単に試せるので使ったことのある方は多いと思います。しかし、仕組みまで理解している方はそう多くないのではないでしょうか。そもそも本家の論文でも内部の詳細については詳しく解説しておらず、解説論文が書かれているくらいです。
本記事では Word2vec のモデルの一つである Skip-Gram について絵を用いて説明し、概要を理解することを目指します。まずは Skip-Gram がどのようなモデルなのかについて説明します。
※ 対象読者はニューラルネットワークの基礎を理解しているものとします。
どのようなモデルなのか?
Skip-Gram はニューラルネットワークのモデルの一つです。Skip-Gram は2層のニューラルネットワークであり隠れ層は一つだけです。隣接する層のユニットは全結合しています。Skip-Gram のアーキテクチャは以下の図のようになっています。

このニューラルネットワークは**あるタスクを実行するために学習されますが、実際には学習したタスクに対してニューラルネットワークを使うことはありません。実際の目的は隠れ層の重みを学習することにあります。この隠れ層の重みのことを単語ベクトル**と呼び、私たちが真に必要とするものなのです。
あるタスクとは?
では Skip-Gram が行うタスクについて説明します。繰り返しますが、このタスクの結果を使うことはありません。あくまでも重みの学習が目的です。
ではあらためて Skip-Gram で行うタスクについて説明します。Skip-gramでは、ある単語を入力した時、その周辺にどのような単語が現れやすいか予測することをモデル化します。以下の例文を使って考えてみましょう。
I want to eat an apple everyday.
ここで、ある単語が "eat" だったとします。この単語に注目すると、周辺語には食べ物の名前である "apple" や "orange" が現れそうです。つまり、ある単語の周辺語としてどういった単語が出現しやすいかという確率を考えることができます。例えば、訓練済みのネットワークに "eat" という単語を与えるとします。その時、"apple" や "orange" のような関連性の高い単語は周辺に現れる確率が高く、"tank" や "network" のような関連の低い単語は低い確率を取るようにします。この確率をボキャブラリ内のすべての単語に対して計算します。
ここで周辺語として何単語まで考えるのかというのをウィンドウサイズ $C$ として与えます。ウィンドウサイズと周辺語の関係は以下の図のようにするとわかりやすいですね。

学習は教師あり学習で行います。具体的に何を与えるかというと、入力としてある単語を、出力としてその周辺語を与えます。これらの単語は訓練データ内に現れる単語です。これらの単語を与えて、ネットワークに、ある単語に対するその周辺語の確率を学習させます。以下の図は、周辺語の数を1つとした時の入出力のイメージです。
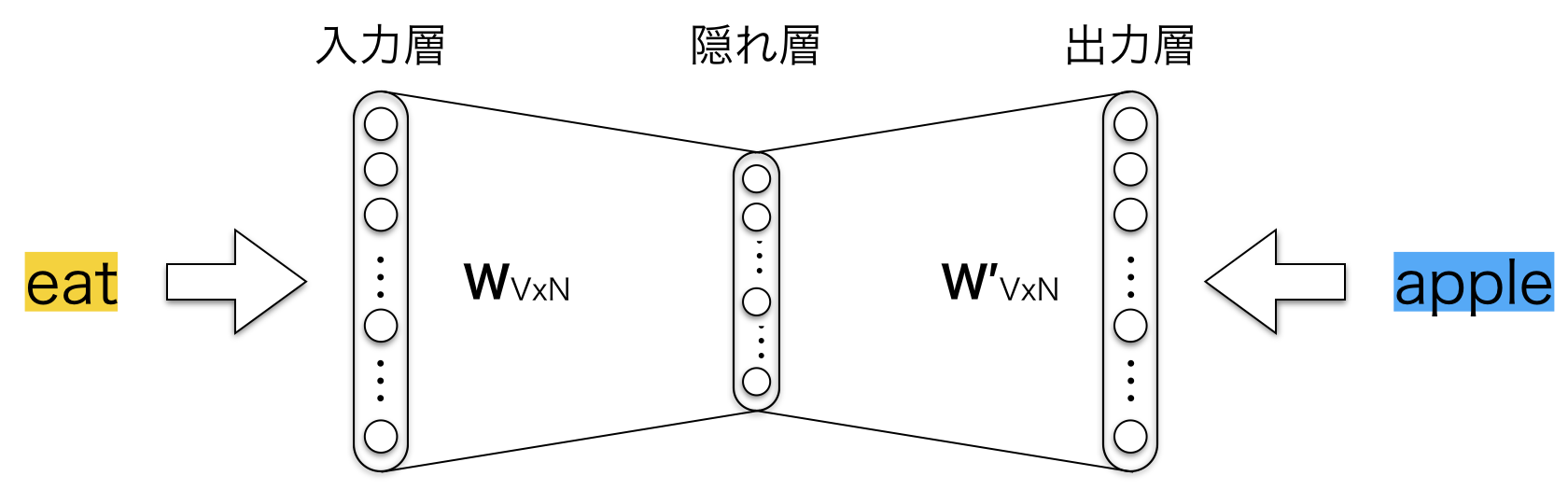
例えば、ネットワークはおそらく (eat, apple) のようなサンプルに対しては (eat, network) より高い確率になるように学習します。学習が終わった時には、"eat" という単語を入力として与えると、"apple" や "orange" は "network" よりはるかに高い確率を出力します。以下がそのイメージです。
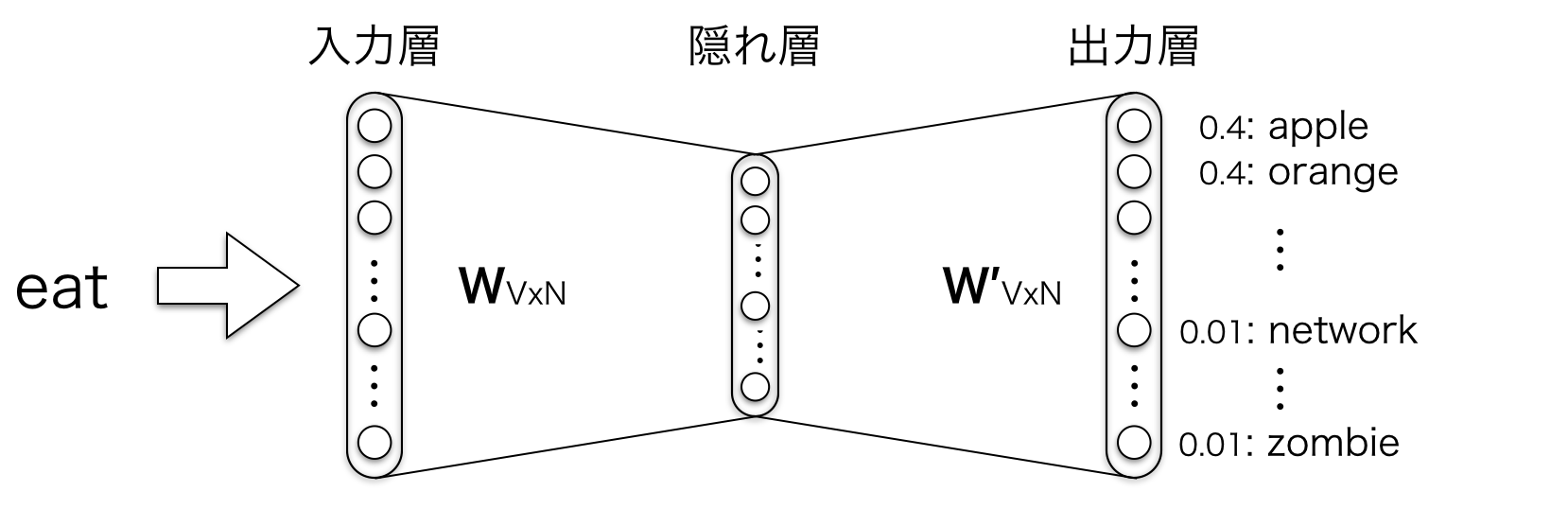
さて、以降ではモデルの詳細について入力層、隠れ層、出力層ごとに見ていきましょう。説明する際は、話を簡単にするために周辺語の数を1つと仮定して説明していきます。
入力層
さて、では入力層の詳細について見ていきましょう。
単語のような可変長の文字列をニューラルネットワークに与えることはできません。そのため、固定長形式で単語を表す必要があります。そのためにまず、学習データからボキャブラリを構築します。ボキャブラリというのは重複のない単語集合のことです。例を挙げてみてみましょう。以下のような学習データがあったとします。
I want to eat apple. I like apple.
この時、この学習データからボキャブラリを構築すると以下のようになります。重複のない単語集合になっていることがわかるでしょうか?
{apple eat I like to want .}
この場合ボキャブラリ数は 7 でした。
ボキャブラリを構築したら、"apple" のような入力語を one-hotベクトル として表します。このベクトルはボキャブラリ数と同じサイズの要素を持ちます。上記ボキャブラリの場合は 7 要素を持ちます。この各要素がボキャブラリ内のすべての単語に対応します。そして "apple" に対応する場所に1を、その他の場所に0を入れます。
たとえば上記のボキャブラリで 単語 "apple" を入力する場合、入力層には以下のベクトルが入力されます。
\left[\begin{array}{l}
1 \cdots apple\\
0 \cdots eat\\
0 \cdots I\\
0 \cdots like\\
0 \cdots to\\
0 \cdots want\\
0 \cdots .\\
\end{array}\right]
隠れ層
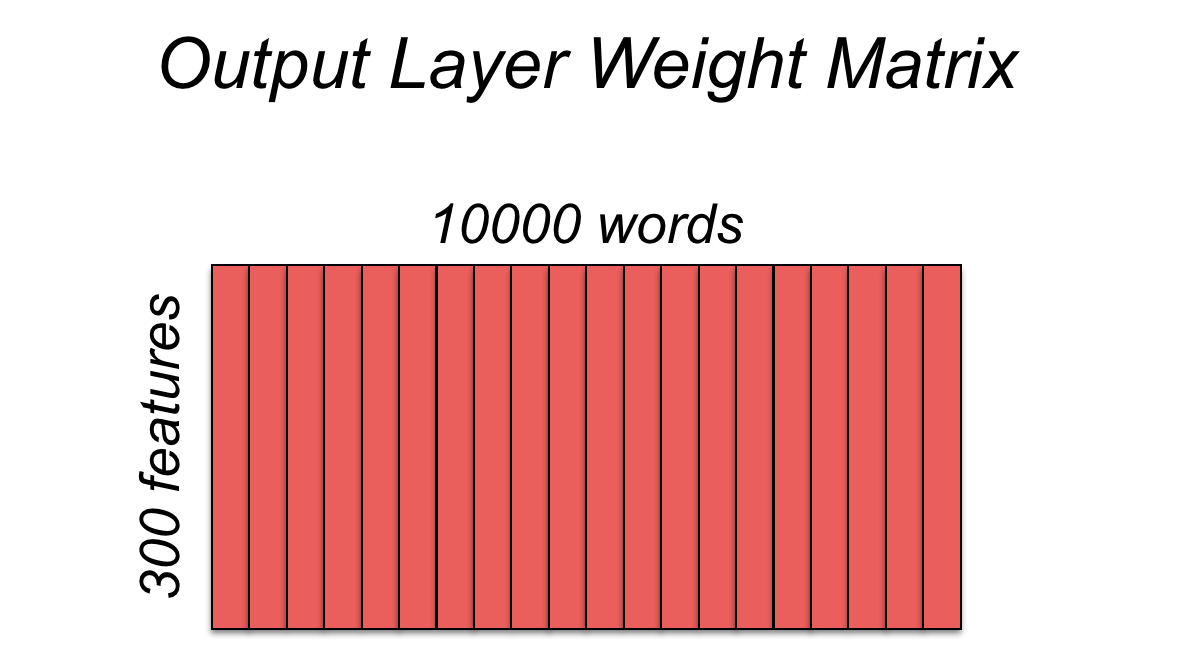
さて、300次元の単語ベクトルを学習することにしましょう。また、ボキャブラリ数は10000としましょう。そうすると隠れ層は 10000 x 300 の重み行列で表されます。10000はボキャブラリ内のすべての単語を表し、300は隠れ層のニューロン数を表します。重み行列は以下のように表されます。

**この重み行列の各行が実は単語ベクトルになっています。**そのため、最終目標は隠れ層の重み行列を学習することなのです。ニューラルネットワークの学習が終わったら出力層は必要ありません。
さて、では入力層と隠れ層の間でどのような計算が行われるかみてみましょう。
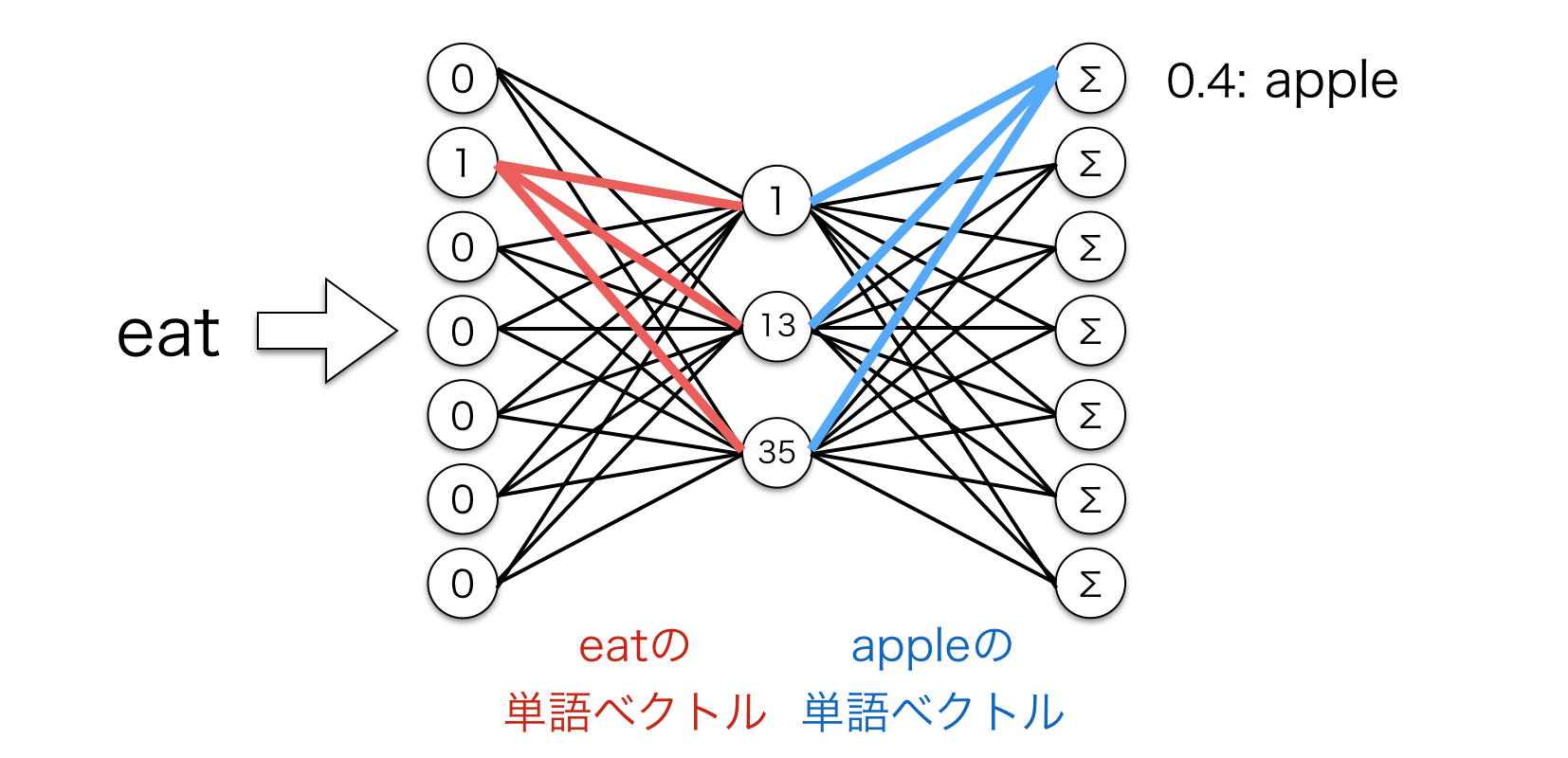
もし 1 x 10000 のone-hotベクトルを 10000 x 300 の行列にかけると、one-hotベクトルの1に対応する箇所の行列の行を効率的に抽出することができます。以下がその例です。先のボキャブラリでいうと "eat" の単語ベクトルを抽出していることになります。

ニューラルネットワーク的にどうなっているかというと以下のような計算をしています。赤線で表される重みが抽出されるわけですね。
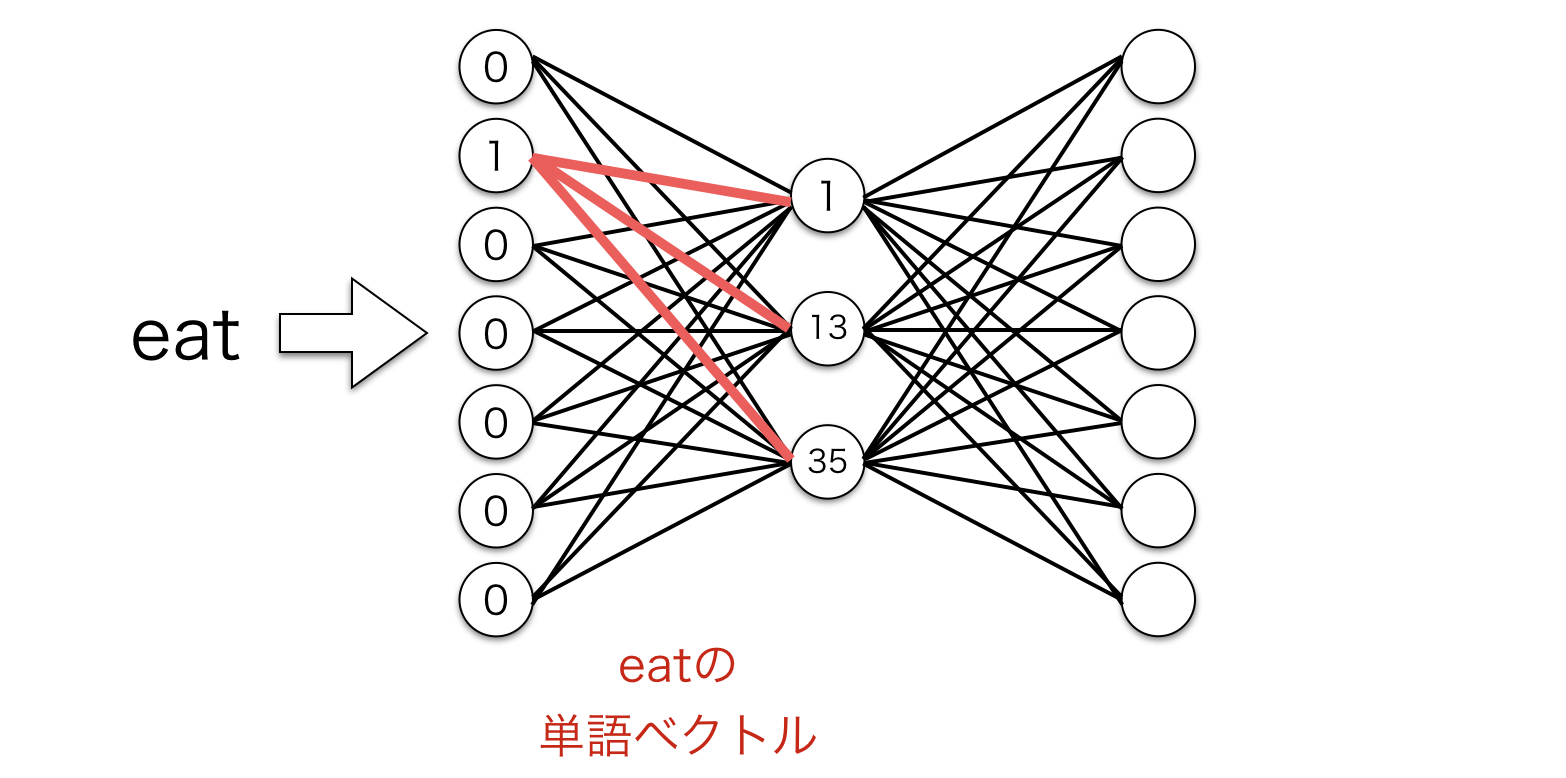
ここまでの話をまとめると、このモデルの隠れ層は実際には入力語の単語ベクトルのルックアップテーブルとして機能することを意味しています。Skip-Gramでは隠れ層に活性化関数を設定しないので、隠れ層の出力は単なる入力語の単語ベクトルになります。
出力層
隠れ層から出力された入力語に対応する 1 x 300 の単語ベクトルは、隠れ層〜出力層間の重みがかけられた後、出力層に入力されます。実はこの隠れ層〜出力層間の重みも単語ベクトルを表しています。重み行列は以下のように表されます。入力層〜隠れ層間と違って重み行列の列が単語ベクトルになっています。
つまり、出力層に入力されるのは結局単語の重みベクトル同士の内積ということになります。図示すると以下のようになります。
そして、出力層に入力された値に対してソフトマックス関数をかませます。これにより、出力層からの出力を確率値に変換しています。出力層の各ニューロンはボキャブラリ内の各単語に対応しますが、それは0から1の値を取り、合計すると1になります。
確率を出力するまでの計算を図示すると以下のような感じになります。
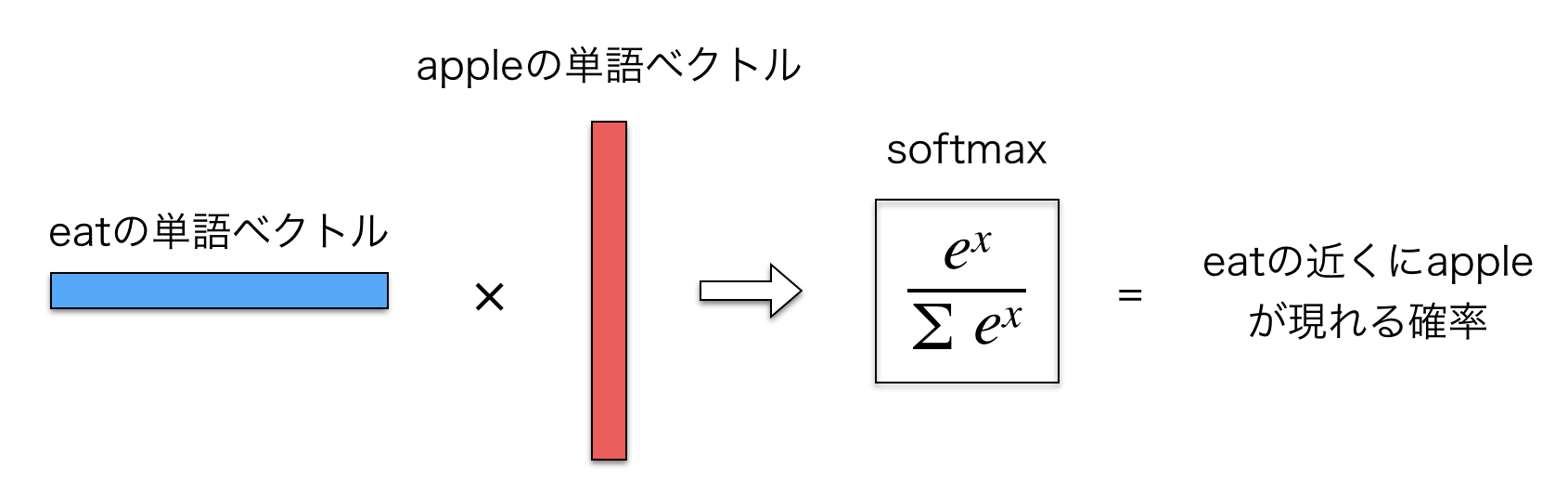
まとめると、Skip-Gram では単語の重みベクトル同士の内積を計算していると見なせます。それが出力層のユニットに入力されます。ここで出力層への入力値にソフトマックス関数を使うのは確率値に変換するためです。結局、学習で行われているのは、ある単語とその単語に対して実際に現れる周辺語の内積が大きくなるように重みを調整していくということでしょう。
おわりに
本記事では Skip-Gram の概要を理解するために絵を用いて説明してみました。
やっていること自体は難しくないと感じてもらえたと思います。
次は実装するために丁寧に数式展開をしてみましょう。
つづく