シリコンバレーのエンジニアが一年ほどをDL(Deep Learning)を追いかけてみて思ったこと、感じたことをまとめてみました。とにかく伝えたいことは、DLはもはやその一言では片付けられないほどに構造やアプローチが多様化しているということ。そしてその進化スピードがえげつないほど速いということです。
将来のプログラミングや問題解決の仕方を変え、人を取り巻く環境を変えていくかもしれないというじりじりとした圧迫感。これを少しでも伝えられればと思っています。
このポストの方針
-
技術部分の説明は初心者向け。各構成要素など基礎から解説します。今からDLをキャッチアップしていく人には多分丁度良いです。
-
最初と最後だけ読むのも良いですが、各部の技術的な部分や難しさはできるだけ短く分かりやすく書くつもりですしここが一番大事なところです。できれば時間のあるときにじっくり読んでもらえればと思います。
内容
__DLは何を変えたか:__あるいはDLとは何か?
__基本要素:__DLを構成する要素とその仕組み。
__DLのデメリット:__DLシステムを構築するのがいかに難しいか。
__各種改善手法・最新事例:__各種のモデルや手法の紹介。ここがメインです。
__DLは何を変えるのか?:__エンジニアを取り巻く環境はどう変わるか?
DLは何を変えたか
DLは各分野で飛躍的な性能を発揮していますが、何故そのようなジャンプが可能になったのでしょうか。ここでは僕の感じるポイントをまとめてみます。
1. ビッグデータへの対応
既存の一般的な機械学習のモデルに対して飛躍的に大きなデータを入力として扱えるようになりました。
例えば碁のAIであるAlphaGoでは従来とは比べものにならない量の対戦データを初期フェーズで学習しています。今までの手法ではメモリやコンピューティングパワーの限界にあったデータしか扱えなかったとしましょう。DLは超大量のデータでも学習できる工夫があります。
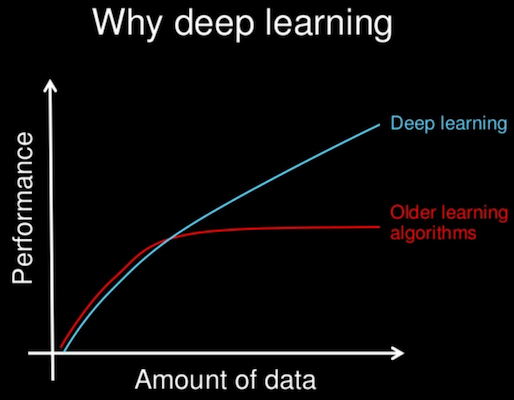
例えば下の図はAndrew先生の有名な図ですが、データの量を増やすことで性能を上げやすくできるという特徴があります。
2. 複雑/多層モデルの実現
極端な例では、例えば今までの機械学習アルゴリズムで人間がパラメータをチューニングしていたとします。これに対して破壊的に複雑なモデルの自動学習が可能になりました。
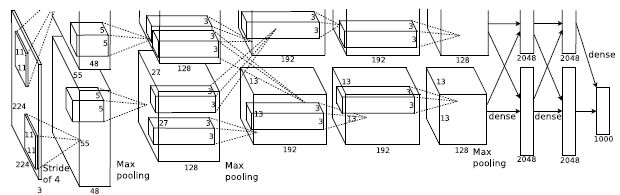
例えば初期の物体認識ネットであるAlexNet ではパラメータが約 6000 万個もあります。表現力の高い複雑なモデルでも学習してしまうことができるのです。(下図はAlexNetのモデル図)
3. 汎化性能(非線形システムへの信頼性)の向上
DLは非線形システムです。これは従来扱いが難しいものでした。さらに過学習という問題があって、例えば学習時に使ったのとは違うシチュエーションの入力データが入った時にとんでもない答えを出す可能性が出てしまうのです。これだと実用のシステムとしては非常に信頼しにくいのです。
DLでは非線形なシステムでも汎化性能を大きく向上させ、過学習を抑え信頼性を上げることができました。
4. 時系列データや多次元データへの拡張
音声や文章、人の行動など、世の中のデータは時系列、可変長、多次元の複雑なデータです。DLではRNNやLSTMなどの構造を持つことで音声認識や自然言語処理などで精度の良い学習を可能にしました。これは従来プログラミング技術的にもいろいろと難しい分野でした。
DLとは何か?何を変えたか?
大枠的には上記で説明したように「非線形で、複雑なモデルあるいは大量のパラメータを持ち、大規模なデータや時系列のデータなどにも対応できるなどの工夫を備えたニューラルネットベースの機械学習システム」という認識で問題ないでしょう。
ただ、当初使われていたDLという言葉が指すモデルとは大きく離れたモデルがどんどん提案されてきています。とにかくここがエキサイティングなところで、後にじっくりと見ていきたいと思います。
何を変えたか?
上記の特徴により画像処理や音声認識、自然言語処理の分野で大きな性能の飛躍を可能にしました。これはいくつかの分野で単に性能を押し上げたということだけでは留まらなかったのです。
上記分野は写真や音声、文章とどれも人間が外界とのインタフェースとして使っているものです。つまりは人間と直接交わる部分であって、人間の生活に関わるものをAIで豊かにしていく可能性が開いたわけです。GoogleやFacebookのような新興企業が技術のあるスタートアップをどんどん買収して、マシンラーニングを使った技術がすぐにサービスとなって世の中へ還元されていくようになりました。
そしてこのロマンと可能性が世界中の優秀な科学者・技術者を大量にDLの道に引き込む導線になりました。この変化がある意味一番大きな変化のようにも思えます。シリコンバレーではほぼ毎日のようにどこかでDLや機械学習のミートアップが開催されています。一過性のブームでは終わらないエンジニアを惹きつけるものがあるのだと感じます。
基本要素
全体が長くなってしまったのでこのパートは分割してもう一つのポストにしました。DLはブラックボックスで性能改善が難しいと良く言われていますが、いろいろな方法論が提唱されています。各要素の持つ特徴や役割を理解しておけばDLモデルの改善はそれほど難解なものではありません。
Inside of Deep Learning (ディープラーニングの基本要素)
DLのデメリット
過学習しやすい
機械学習システムの本質的な問題は
誤:「学習データに対してシステムを最適化する」ことではなく
正:「__学習データに含まれない未知の入力データ__に対してシステムを最適化する」ことです。
過学習と言ってトレーニング用のデータに対して解答を最適化しすぎると逆に実際の性能が落ちてしまうという問題があります。下の図は購入するときの家の大きさと価格のサンプルです。y = ax2 + bx + c の2次式(中央)で推定すれば全体的にフィットしますが、より表現力の高い6次式(右)で推定しようとすると実際とは大きく離れた推定モデルになってしまいます。

from scikit-learn:Machine Learning 101
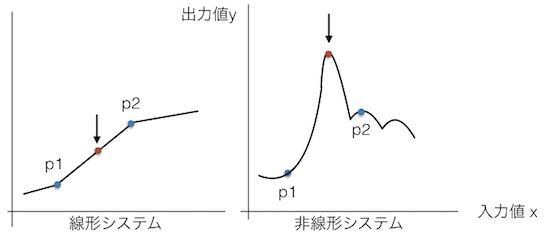
特に非線形システムは線形システムに比べて過学習しやすく、予測範囲外の出力が出る可能性が高くなります。例えば下の図で、線形のシステム(左)ではp1とp2の間の入力に対する出力値はp1とp2の間になりますが、非線形のシステム(右)では予期しない値が出ることがあります。これは自動運転など安全が優先されるシステムでは特に大きな問題となります。
大量の学習用データが必要
教師なし学習や強化学習などもありますが、やはり教師データを与えるシステムが多いです。特にディープラーニングでは汎化性能をあげるためにも従来に比べてかなり多くのデータが必要になります。規模や対象にもよりますが例えば画像認識では最低でも数万件以上の学習データが必要と言われています。
また、例えば年齢や職業などから既婚状態、車の所持、年収(5段階)を予測する場合、出力クラスの全ての組み合わせである2x2x5=20のそれぞれの場合で十分な質と数のデータが必要になります。
正解データの作成に人手が必要な場合では非常にコストがかかりますし、正解データを用意できない場合もあります。__このためにニューラルネットベースのシステムに移行できないという話は非常によく聞きます。__例えばDLのブームの火付け役ともなった物体認識のタスクですが、これは当時に非常に大規模で質の良いデータセットが提供されていたこともあってDLと相性の良いタスクだったのでした。
膨大なコンピューティングリソースが必要
さらにDLではモデルがディープで複雑なものになることが多く、学習用データが多いことも相まって計算に非常に時間がかかります。GPUも必須になりますし、クラウドを使って気軽に分散化できるものではありません。
特に学習フェーズでは実験に数日から一週間ほどかかるような論文も少なくないです。この場合はモデルの改善に何度も試行錯誤しながら試すのが難しくなります。例えば本番環境でソフトを走らせるまでには通常何回テストランやデバッグを走らせるでしょうか。一回のテストランに一日かかると考えればその難しさが伝わるかと思います。
パラメータの収束が難しい
多数のレイヤーを持つ場合など、もともと数百万以上ある多数のパラメータをそれぞれ最適値へ収束させていくのは非常に難しくなります。バックプロパゲーションをかけて出力に近い層から学習させていった場合、正解との誤差がどんどん分散してしまって学習できなくなってしまうからです。またモデルが複雑になればなるほど、鞍点と呼ばれる数次元で損失が極値になる点へ陥り、学習が進みにくくなるポイントも増えるからです。
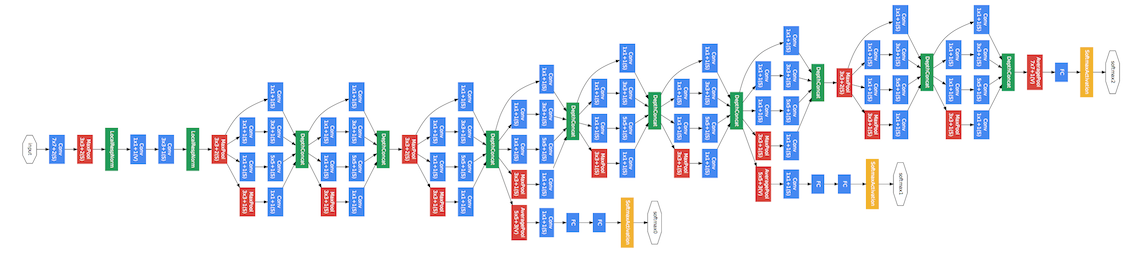

上はInception-Net v1(GoogLeNet)のモデル図でレイヤーは合計で22層、計算要素は100程度あります。下のResNet-152は極端な例ではありますがレイヤー数が152層にもなります。Inception-Netの2年前に物体認識でDLが注目されるきっかけを作ったAlexNetは8層構造でした。まさに"The Deeper, the Better"と言われる所以です。
性能改善が難しい
DLのモデルはブラックボックスであるなどと良く表現されます。例えば下図の物体認識の場合、既存手法では特徴抽出や学習判別機などそれぞれの機能で問題があった場合はそれを検出して各ステップごとに改善を試みることができます。
ところがDLの場合はこれらの処理を全部まとめて学習してしまいます。問題があった場合にどのステップの能力が低いのか判断しにくく、また改善するための方法も多岐に渡るためどれを選択して良いのか分かりません。また問題を把握するために数学的な技術が必要になることも多いです。

同様に__既存手法の場合は人間が持っている知識を組み込むことができますがDLでは非常に難しくなることが多くなってしまいます。__総じて言えばとにかくコストが高いということです。高い技術レベルのエンジニア、学習データ、コンピュータリソース、時間、ほぼ全ての領域において既存技術の数倍〜数十倍のコストがかかり、ハイリスク/ハイリターンのシステムという感覚がぴったりです。
またこれは日本人にしか当てはまらないことですが、最新論文が全て英語であり特にアメリカ、あるいは欧米諸国や中国でしか最新事例が生まれていないこともあると思います。とにかくDLシーンの進化のスピードが早いので、言葉と文化の壁や産業構造の違いが悪い方向へ出てしまっているように感じます。だからこそ、皆でやろうDL!
各種改善手法・最新事例
いろいろなモデルや改善手法をみて見ましょう。ここからがやっと本ポストで書きたかった部分です。改善手法として大まかに4つの項目に分けてみました。
↑ Best
- より表現力があり発散しにくいモデル、フレームワークを考案する
- より多くのデータあるいはより精度の良いデータを使う
- パラメータを収束させるための工夫
- 汎化性能をあげるための工夫
↓ Better
モデルの進化
- Inception Net (GoogLeNet)
Googleが開発し大規模画像認識のコンテストILSVRC 2014で優勝した物体認識のためのモデルです。22層のレイヤーを持ち複数のCNNを並列に並べているのが特徴で、CNNのサイズやパラメータ数を抑える代わりに非常にディープにした構造です。3つの判定結果を使って総合的に判断し非常に高い性能を持っています。
現在では順調に進化を繰り返し、Inception-Net v4やInception-ResNet v2が公開されています。各種Inception-Netはgithub上でソースコードが公開され、AndroidやiPhone上でビルドして世界最高峰の物体認識機能を利用することも可能です。
- Inception in TensorFlow
- TensorFlow-Slim image classification library
- お手軽にrealtime画像認識をAndroid/iOSで動かす
- ResNet
ResNetはDeep Residual Learningという論文でMicrosoft Research Asiaにより発表されたもので、Residual(残差あるいは差分)だけを学習するようにして非常に深いモデルでも効率良く学習できるようにしたモデルです。
2014年のILSVRCではGoogleがInception Netで飛躍的な成果を出して優勝したところをその翌年にはMicrosoftがさらに飛躍的な成果を出してひっくり返すと言う動きの速さがDLシーンの見どころです。(さらに翌年の話題はYoloでしょうか。Dog yearのIT業界のさらに上を行くDog yearぶりです)
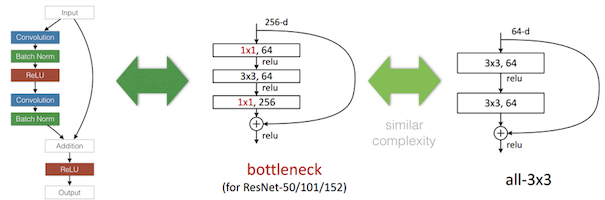
上図 左の画像がResNetの一部を図にしたもので、上図 中央がそれを簡略化したものです。入力データを保持しておいてCNNの結果に加えることで各学習器は入力データとの変化分のみを学習すればよくなります。また上図 右の画像は比較のためのモジュールです。3x3x64のCNNフィルタを2枚重ねるよりも、1x1x64, 3x3x64, 1x1x256の3枚のフィルタを使うことで同等の表現力をもちながらもパラメータの数を抑えています。
直感的な説明にすると次に見るRNNとLSTMの関係に似ています。例えば今までのモデルでは入力されたデータを後ろのレイヤーに伝えるための機能も特徴抽出の為の機能と同時に学習せねばなりませんでした。そうすると両方の機能のためのウェイトが混在し学習の効率が下がります。また例えば特徴抽出のためのウェイトよりも情報伝達のウェイトの値が高くなり層が深くなると発散しやすくなってしまうということが起きるてしまうようです。
Residual Netも他で応用されています。例えば下のリンクにある単眼超解像という画像の解像度を上げる論文では、これを利用することで飛躍的に深く、かつ学習係数を従来の1万倍(!)にして短時間でも学習できてしまうというモデルが提案されています。下の図では横軸が学習エポック数で縦軸が性能です。赤色の線(従来モデル)に対して青色の線(Residual Model)ではほんの数エポックで高い性能が学習できているのが分かります。

- RNN
RNN (Recurrent Neural Network)は前回の出力データ(の一つ前の中間層出力)を保持しておき、次の入力データと共に別の入力値として利用する構造です。

文章や音声のような時系列のデータを処理できます。例えば "a" という単語が入ってきた場合にその直前に "I" と "have" が来ていたら "pen" を返す様にネットワークをトレーニングできます。状態メモリーを持つことに近く、DLのテキストや音声理解への道を開きました。
またRNNは必ずしもテキストや音声のような時系列のものが対象ではありません。例えば下の左の画像はDeepMindにより発表されたもので、住所の地番の画像を見せると注目するべき点の流れをRNNで生成します。人間の目のように左から右下へ順に番号を読んでいくように学習しました。右の画像ではRNNを使って数字の画像を生成するよう学習されたものです。


- LSTM
例えばRNNで文章を処理する場合、ずっと前の段落で言及された内容を整理して覚えておくことは不可能でした。LSTM(Long Short Term Memory) では一度保持した内容をずっと覚えておいて毎回の処理時に入力として与えることができます。さらに忘却ゲートという機構を備え、これを使うことで一度覚えた情報を消去することが可能になります。
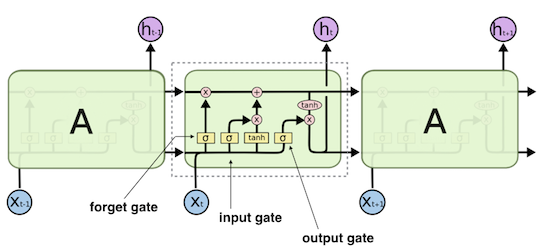
上図は下記のリンクから引用した初代LSTMの図に幾つか説明を加えたものです。input gateでは今回得られた情報から現在の保持情報をどのように変更するかを決定します。forget gateでは現在の保持情報からどの情報を消すかを選択し、output gateでは今回の入力と現在の保持情報からどのような出力を行うかを選択する役割を持っています。
LSTMも内部に覗き窓を持つようになるなどの改良版が考案されており音声認識や機械翻訳で大きな成果を上げています。
実はLSTMが提案されたのは1995年と、結構古くからあるモデルなのでした。
現在でも沢山のRNN/LSTMの派生版が提案されています。例えばBidirectional LSTM, Multi Dimensional LSTM, Hierarchical Subsampling RNN, Convolutional LSTM, PyraMiD LSTM, Grid LSTM などです。時間方向や空間方向に多彩に情報を解析、集約していきます。
例えば3次元の脳のスキャン画像について、PyraMiD LSTMは各方向からローカルな特徴を分析しつつその情報を蓄積したまま集約していって脳内の各領域を推測するというタスクを実現しました。
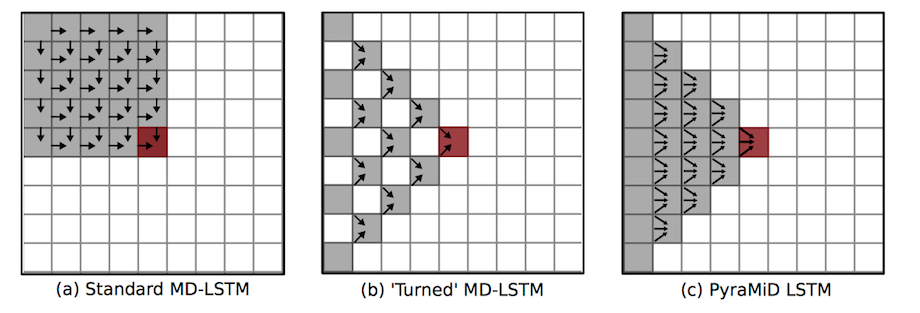
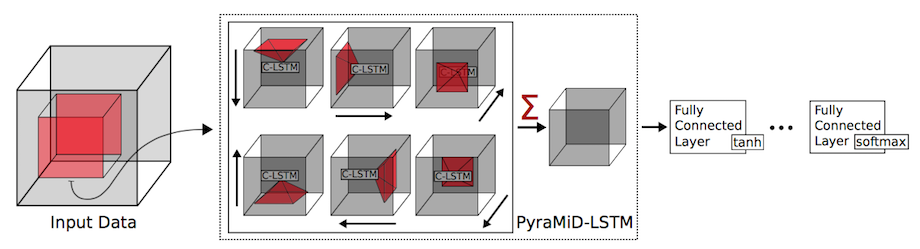
もちろん画像以外でも幅広く活用されていて特にテキストや音声に強く、2015年にはLSTMを使ってIT製品のヘルプデスクの応答を自動で作成するチャットボットが発表され話題となりました。
- DQN
AlphaGoやDeep Dreamを開発したDeepMindの構築したdeep Q-network あるいは Deep Reinforcement Learningと呼ばれるモデルです。
ある状態でエージェントがとれる行動が有限の種類だけあったとします。その場合にどの行動を取れば将来的に最大の報酬が得られるかを経験的に学習していくものです。
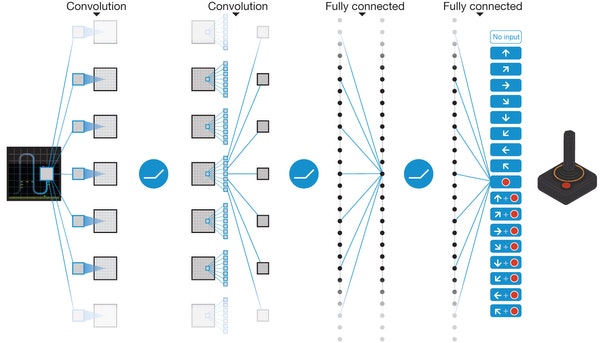
Q Learningと呼ばれる古典的な強化学習の手法に対して、CNNを用いた画像認識や、後に説明するようなミニバッチや最新のオプティマイザなどのDL技術を組み合わせたモデルです。ロボットの制御やボードゲームのAIなどに利用できます。
最近ではさらにLSTMの手法を追加して自分が過去にとった行動を考慮するDeep Recurrent Q-Learningなども提案されています。DQNの強化版は特にGoogle DeepMindが力を入れている分野のようにみえます。
- Human-level control through deep reinforcement learning
- Deep Recurrent Q-Learning for Partially Observable MDPs
- DCGAN
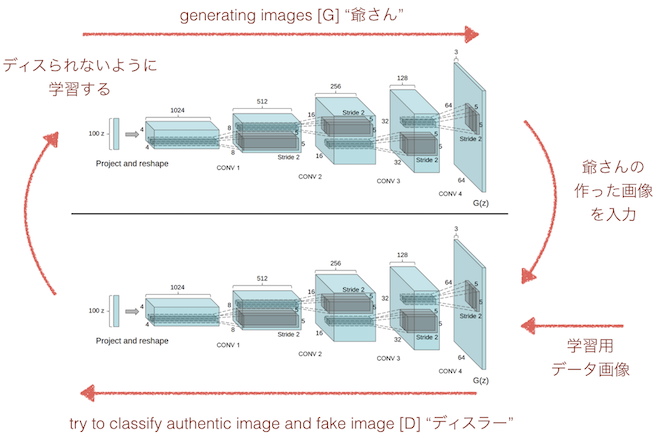
DCGAN = deep convolutional generative adversarial networks です。二つの目的が正反対のモデルを交互に学習させながらお互いを鍛えていき、画像生成で革命的な成果を出したモデルです。IndicoというマシンラーニングのAPIを提供しているスタートアップとfacebookの研究所が出したものです。
Generatorこと"G" (僕の中では"爺さん")と、Discriminatorこと"D" (僕の中では"ディスラー") の2つのモデルを使って画像生成をするGANという技術にDLのCNN技術を利用したものです。ここでは3種類の学習を行います。
-
ディスラー(上図 下) は学習データとして与えられた顔画像を見て正解と答えるように学習します。構造的にはCNNを用いた画像分類器と似ています。
-
爺さん(上図 上) は与えられたランダムなパラメータから画像を生成します。この画像をディスラーに見せたときにディスラーが正解と答えるように学習します。
-
ディスラーは爺さんの作った画像を見たときは正解とせずに正しくディスるように学習します。
上記を繰り返していくことで学習していきます。また、ただCNNを使うというだけでなくてバッチの正規化や伝達関数に工夫などをして精度を高めているようでした。
ここでさらに興味深いのはこの爺さんが獲得した生成機では各パラメータがword2vecのような顔の特徴を掴んだものになることです。学習後にパラメータをランダムではなく手動で変更することで色々な特徴の顔をミックスして自由に画像を生成することができます。
顔以外にも風景などに適用でき、また近年では複数のGeneratorとDiscriminatorを使った複雑なStacked GANなども提案されています。

- SyntaxNet

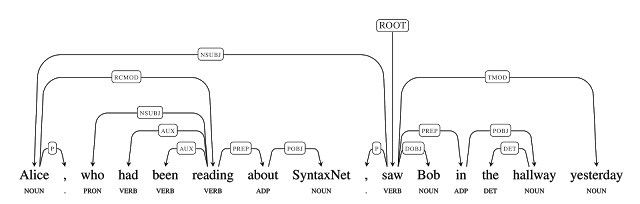
SyntaxNetはGoogleの開発した自然言語用の構文解析器です。残念ながら僕はNLPについては全然分からないのでSyntaxNetの仕組みは説明できません。
ただ簡単に説明を読む限りではRNNのように順に単語を入れていくのではなく、ある程度まとめてタグをつけた上でネットワークに入力するようです。それをどうやって学習させているのかは分かりませんが、従来の構文解析器に比べて非常に高い精度を持ち、さらにどんな言語にでも学習可能というなかなか凄いふれ込みです。実際に最近になってgoogle翻訳の精度が大きく向上したと話題になっていましたが、ここら辺の技術が応用されている可能性も高そうです。
- アンサンブル学習
二つのネットワークを用いて画像生成を行うDCGANもその一種として良いと思います。近年とみに有効な手段として用いられているのがアンサンブル学習です。これは複数のネットワークを作ってそれぞれで個別にトレーニングを行い実行時にはそれらの多数決や協調により判断を行う仕組みです。
例えばAlphaGoでは最初の探索にはディープなネットワークを用いて高精度な予想を行い、その後の手を読むときには返答の速い浅いネットワークを協調させて大きな性能を達成しています。また物体認識のための初期のInception netでは3つの出力を使って多数決で決めていました。一つのモデルを巨大にすると細部までの学習ができなくなるため、別々のケースを各モデルに個別に学習させるアンサンブル学習は分かりやすいです。
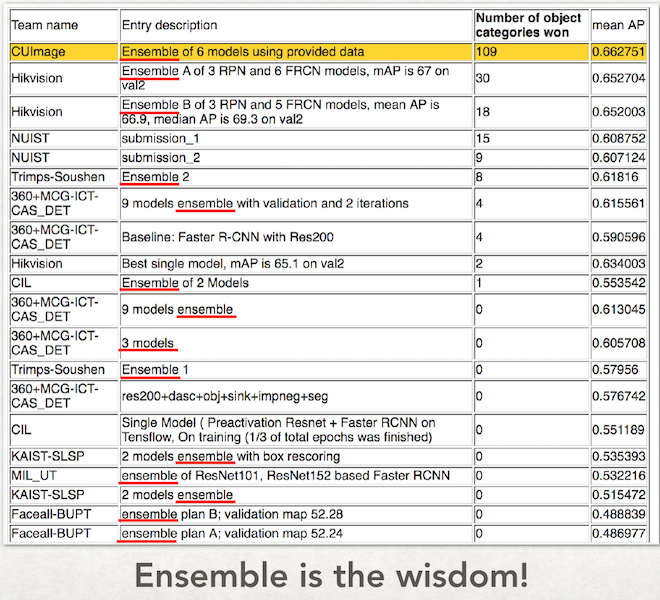
個人的にですが、異なる目的のネットワークが協調動作する様はまさに生命と言って良い面白さがあります。下記は2016年のILSVRCの結果ですが、ほとんどのモデルがアンサンブルモデルとなっていて大きなトレンドをなしている状態です。
フレームの進化
- 学習の仕方(ウェイトの更新方法)を学習するフレームワーク
現在のDLの根幹はバックプロパゲーションによるウェイト/バイアスの学習アルゴリズムです。ただし今の方法だとレイヤーの数が増えた場合に勾配消失が発生して発散してしまいますし、何より利用する関数が微分可能でないといけないという制約があります。
下記の論文はネイチャーにも載って話題になった論文です。今までの手法では後ろの層からウェイトを更新していく時に現在のウェイト(の転置行列)を使っていくのですが、代わりにバックプロパゲーション専用のウェイトを利用します。これは最初はランダムな値ですが、ウェイト値の更新に利用しながら学習させていきます。これによってMNISTのような手書き数字の認識で通常のバックプロパゲーションよりも高い性能が得られたとしています。
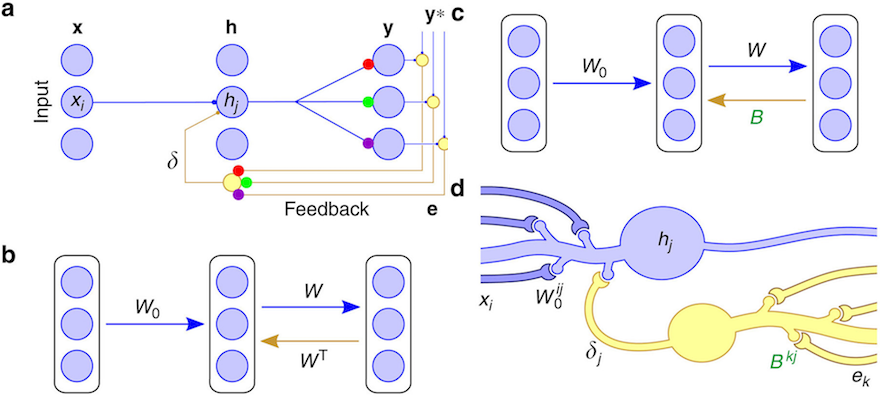
Learning to learn とも言うべき手法で、どのように学習すれば良いかを学習する手法は他にもいろいろと提案されています。上記はFeedback Alignmentと呼ばれる手法ですが、他にもSynthetic Gradientや Target Propという方法が提案されています。
- ネットワークを作るネットワーク
この論文も非常に面白いです。ハイパーパラメータの自動チューニングとも言うべきものではありますが、RNNを用いてネットワークを自動構築・強化していきます。
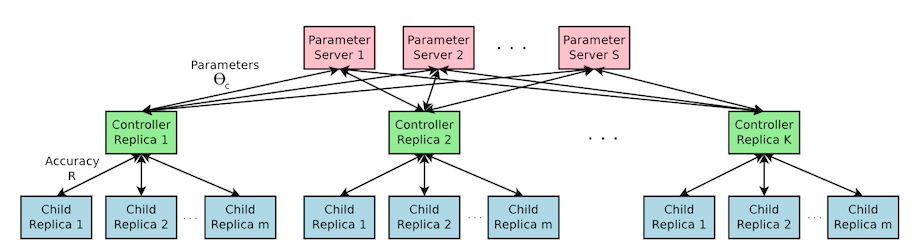
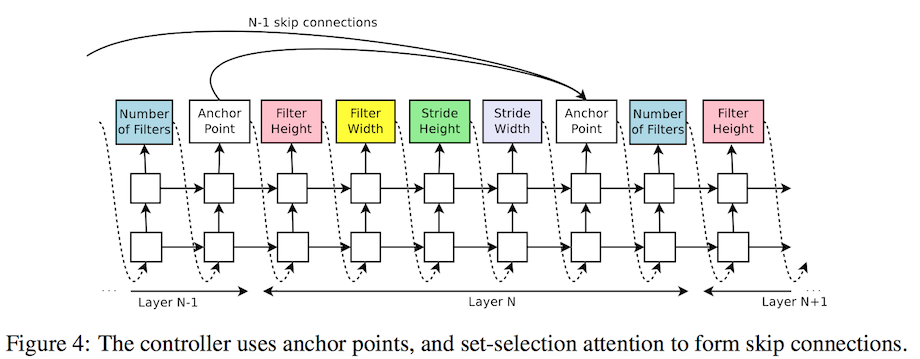
CIFAR-10という、ILSVRCよりも簡単めな物体認識のタスクを解くモデルを生成し強化していきます。結果的に人間が設計し優勝した過去のモデルとほぼ同等のモデルを作成できたとのこと。
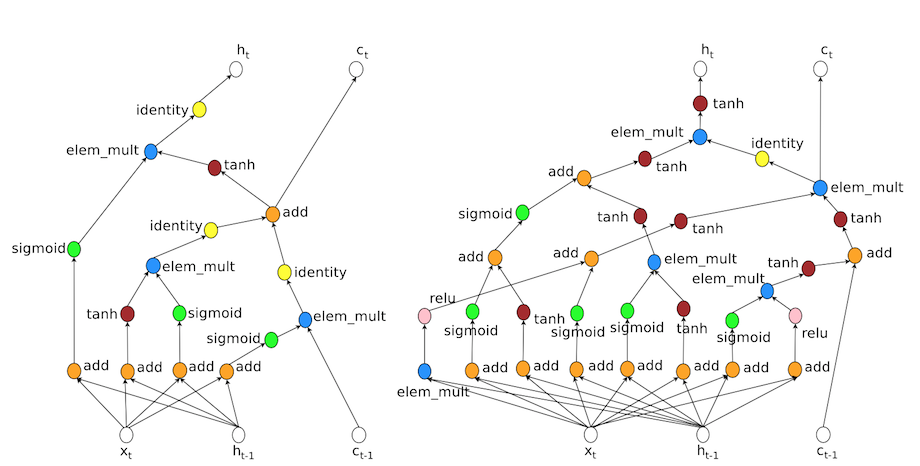
上記は左がLSTMのモデルで、右が生成されたネットワークの一部です。単なるパラメータチューニングの話題ともとれますが、これは応用して行けばより複雑なネットワークを自動構築でき、生成できるモデルの表現力はかなり高くなる可能性があります。強化学習を用いた同様の論文は幾つかあり、面白い可能性を秘めていると思います。
- Differentiable Neural Computer
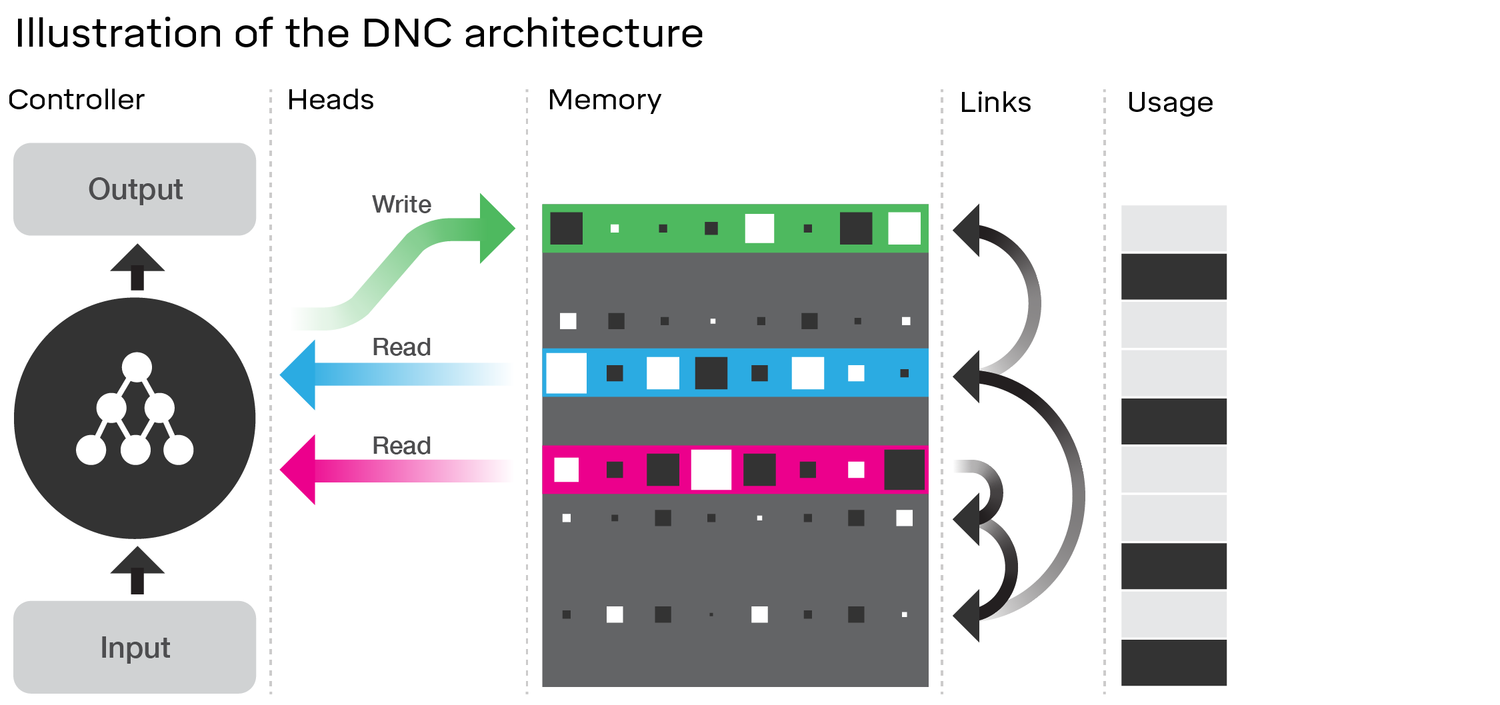
Differentiable Neural Computer もDeepMindから発表されたものです。従来のDLの枠組みにはまらない新しいもので、イメージとしてはチューリングマシンに非常に近いです。大きな特徴として自由なメモリ領域を持ちます。
DNCはデータが入力されるとそれに合わせてヘッドを動かしてメモリからデータを読み込みます。さらにリンク情報に従って順次別のメモリも読んで行きます。読み込みが終わったら出力を出すと同時に空いているメモリを探してそこに情報を書き込んだりメモリの消去を行います。メモリから出力された情報は次に来た入力データと合わせてRNNのように処理されます。
論文ではパズルを解いたり地下鉄の路線図や家系図を解析するなどいろいろなタスクが可能になったとされており今後の大きな可能性を感じます。
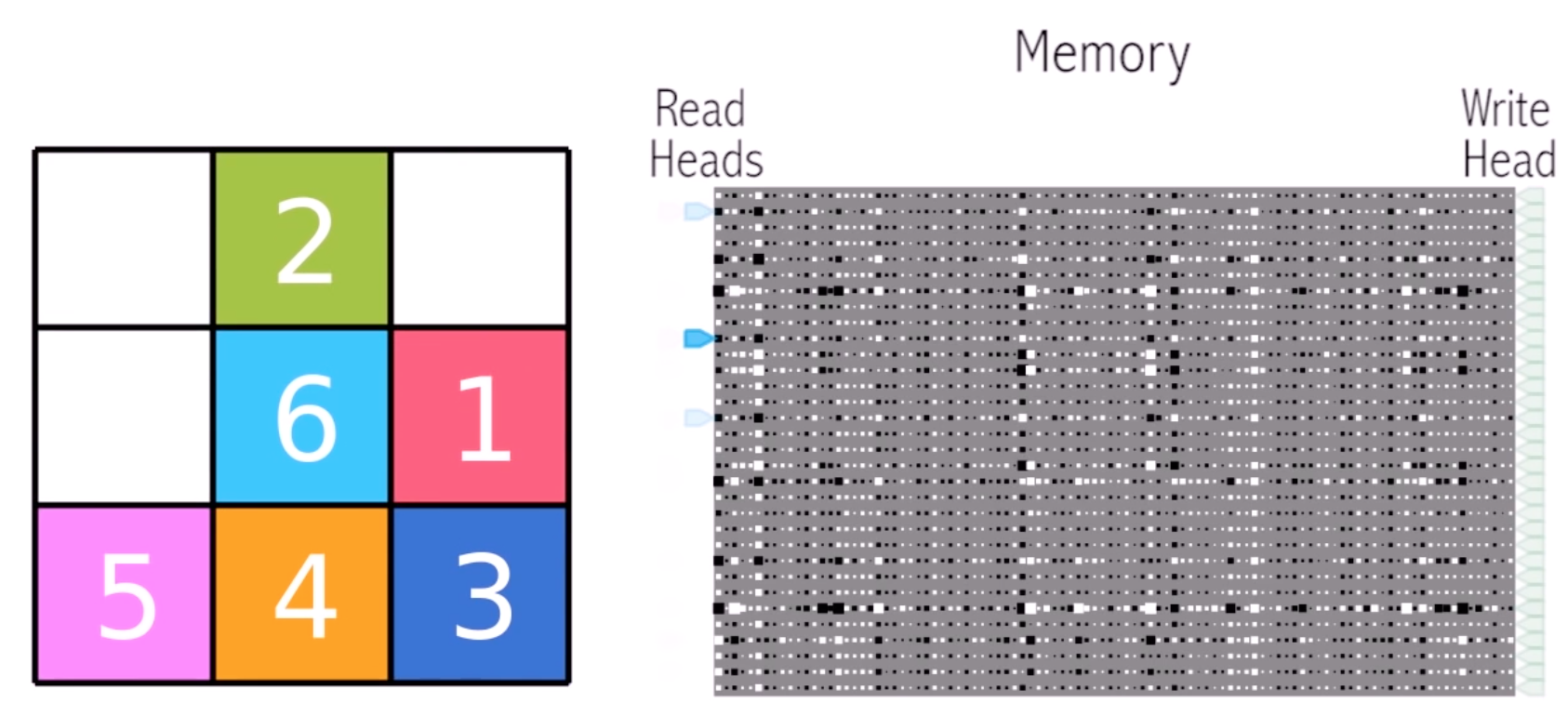
Differentiable Neural Computer
The Deeper, The Better
ここまで見てきたモデルはどれも話題になった有名なものですが、これ以外にも非常に沢山のモデルが考案されています。現在のトレンドとしては2つあり、パラメータを少なくして学習しやすくなる代わりに層を深くしていく方向と、複数のモデルを使っていく方向です。例えば下記の図は各年のILSVRCの優勝モデルの深さの変化です。但しどちらかというと単体のモデル自体は複雑にするのではなくシンプルにしつつ深くしていって、アンサンブルで組み合わせるというのが多いように思います。(そうは言ってもまだまだ湯水のごとく複雑なモデルが考案されていますが)

性能改善手法
ここもちょっと長くなったので別のページとしてまとめました。
Inside of Deep Learning (ディープラーニングの性能改善手法 一覧)
DLは何を変えるのか?
DLの進化は非常に早く、今回紹介したモデルや手法はほとんどが既に過去のものです。それぞれ多くの派生モデルが提案されています。
下記のページがよくまとまっていますが、2016年も恐ろしい数の論文が提出されその話題の幅も非常に幅広いものでした。是非ちらっとでも確認されてみると良いと思います。
DLは本当に"賢い"のか? 弱点は?
大手メディアの記事を読んでいると非常に賢いと思えてしまうDLを利用したAIですが、実際はちょっとイメージが違うと思います。
例えばDQNを用いてブロック崩しを解くAIが発表された時、幾つかのメディアは”ルールを勝手に推測して”プレイすると記事にしていました。ですが実際はルールなどは理解せずにただその状況ではどの行動をとれば良かったかを経験から学習して選んでいるだけです。(もちろんCNNを用いてゲーム中の画像から現在の状態把握ができるようになったという点は大きな進歩ではありますが)
あるいはAlphaGoの時も"棋士が次に打つ手を57%の精度で予測"などと書かれていました。この表現だと__まるで相手の打つ手を高確率で予測できるように聞こえます__が、実際はそうではありません。次にコンピュータが選んだ手が、過去のプロの対戦の中で使われたようなまともな手である確率が57%です。43%の確率で変な手を選んでしまうのです。
とにかく言いたかったことは、メディアの記事は鵜呑みにせず興味がある場合はできるだけ引用元を読みましょうということと、今のAIはあくまで限定的な状況での最適化がメイントピックであるということです。
__そして弱点というとまず思い浮かぶのは、どうしても学習用データが必要になることです。__教師データが作れない分野はまだまだ多く、また教師なし学習でできることは非常に限られているように思えます。
医療革命、生産革命、エネルギー問題、そして...?
知能の実現はまだ難しそうですが、逆に言えば非常に単純なタスクか、あるいはスペシャリストが対応するような限定された問題の両極端なところから実用化が始まっていきそうです。
現在でも既に各種の画像処理、翻訳や文章解析、音声認識などで一気に技術シーンを塗り替えていますが、これからは各種医療技術に応用されガンの予測や遺伝子解析、病気の診断などが一気に進んで行くでしょう。
PFNやnVidiaさんが勧めているIoT機器の知能化も非常に面白いです。モバイルやIoT機器にDL処理用のチップを使って知能化し、ネットに繋がなくても手元で高度なAIが動いたり、あるいはデバイスが得たデータをクラウドに送ってさらなる学習を中央で行って各デバイスにアップデートすることが可能になります。工場や各種の生産技術はさらなる知能化や無人化が進み生産能力が大きく上がるのは間違いなさそうです。
DLは計算量も多く、大量に電気を消費します。最後に残された問題はエネルギー問題でしょうか。ただしそれもAIがエネルギー消費の効率化を進めています。おそらく電力が足りなくなるのは過渡期だけで、最終的には全てが効率化されエネルギーもむしろ余りそうな気もします。需要予測や最適化はAIの得意分野ですし、余ったエネルギーは無駄なく効率よくAIが使ってくれることでしょう。
それで、そんな風に世の中の生産効率が上がり続けて行くとどうなるか?
これはDLが話題になり始めた数年前から考えていたことなのですが、人の時間の使い方としてはより原始的な方向に戻るのではないかと思ってます。
単に自分だけや家族、友人、会社のためだけに時間や労力を割くのではなく、見ず知らずの人にさえ時間を使って貢献するような社会です。AIが世の中を管理すると言ってもそれは恐らく一部の指標に対して社会の中の変更して良い部分を最適化するという話であって、そんなに悪い社会になるとは僕には思えません。
アメリカの人々の生活を見ていると、それよりもむしろ現在進行中の格差の拡大の方が大きな問題に思えます。この拡大を社会が真剣に止めようとできるかどうかが分かれ目で、結局は良い方向にAIを使う道へ進むと信じてます。
ソフトエンジニアの在り方は変わるか?
「深層学習は何を変えるのか」なんていう立派なお題をつけてしまったわりには、実を言うと世の中がどう変わっていくかについてはそんなに良く分かりません。実はエンジニアの身の回りの変化についての考察がメインでした。
一番気になるのは、__「自分の子どもたちにエンジニアになることを勧めるべきか否か」__です。ぱっと見ではAIを作る側にいるエンジニアは安泰なようにも思えますが...
これは究極的に言えば、"AIを作るAI"を作ることは現実的なのかという問題に近いと思います。
例えば現時点で既にLSTMでプログラムコードを読んで実行する”Learning to Execute”という論文があります。
Input:
j=8584
for x in range(8):
j+=920
b=(1500+j)
print((b+7567))
上記のようなテキスト行を入力した場合に、Target: 25011. という答えを予測して出力できるのです(ちなみに正解です)。これはソースコードとその出力を学習させてやるだけでそれぞれの演算子やfor文の意味をシミュレートできるようになったという面白い論文です。(実際はそこまで簡単には実現できなかったっぽいですが)
あるいは「オプティマイザのオプティマイザ」とも言うべきもので、やはりLSTMを用いてオプティマイザ自体を学習してしまう論文も発表されています。上記で説明したような、モデルを自動生成したり学習方法自体を学習するアイデア・実験も沢山あります。(Learning to Learn)
つまりは既にその兆候は現れています。
今まで見てきた進化の速度から考えるに、恐らく子供達が今の僕の年になる30年後には、今のようなソフトウェア職への需要は大きく下がっているのではと感じています。ベイエリアで年収2000万円もらってヒャッハーしてるエンジニアの職は多分なくなりません。問題なのはIT土方なんて言われるような大部分の中産階級のエンジニアです。(僕のようなニートは真っ先に消されます :) )
AIはソースコードを書けるか?
少なくともソースコードを書く部分はかなりの領域をAIが担当すると思います。人間や社会の常識を理解し、ソフトの仕様を定義する"人間"は一定数必要になると思いますが、仕様を箇条書きで整理するだけなので難しい要素はそんなにありません。
つまりは仕様をいかにコンピュータが分かる形の知識表現に落とすか、という問題はそんなに難しくない気がします。人間の書いた仕様テキストをそのまま入力として理解できるようになるのもそう遠くないのではないでしょうか。仕様書ができたら後はAIがコードを生成し、もし矛盾があれば自動で直してくれるか、さらなる仕様を要求してもらいます。もちろんAIはこちらの性格を把握済みですから、気を悪くせずに仕事ができるよう最大限の配慮をしてくれます。もしかしたら人間の上司や同僚よりも気持ちよく仕事ができたりするかもしれません。
AIのチューニングはほとんどAIがやります。人間も一部手伝うとは思いますが、今のようなコードを書くやりかたではなく、何かビジュアルなツールを用いてモデルの構造や組み合わせを変えたりするような感じになるのではないでしょうか。
結論としては、子供にプログラミングを教えるのはちょっと躊躇っています。
僕自身は高校時代からプログラミングを始めて凄いハマったのでちょっと寂しい気はします。もちろん論理的思考やクリエイティビティを刺激するようなものは積極的に与えたいです。かつての僕がしたように、CPUの動作やアドレスバスの動作を理解させてコンピュータの動作原理を理解させていくのも良いと思います。ただし今や車のことを分からなくても運転できるのと同じことが起こるだろうという感覚はあります。
プログラミングの形は大きく変わり、開発に必要な人数も大きく減るだろうなとは感じます。コンピュータの仕組みやサイエンスを教えずにプログラミングだけを教えるのはやはり30年後の子供達にとってリスクになるのではないでしょうか。
最後に
この道を行けば、どうなるものか。
危ぶむなかれ。危ぶめば道はなし。
迷わず行けよ、行けばわかるさ。
みんなでやろう、DL!!