はじめに
最近、畳み込みニューラルネットワーク(CNN)を用いた自然言語処理が注目を集めています。CNNはRNNと比べて並列化しやすく、またGPUを使うことで畳み込み演算を高速に行えるので、処理速度が圧倒的に速いという利点があります。
この記事は、自然言語処理における畳み込みニューラルネットワークを用いたモデルをまとめたものです。CNNを用いた自然言語処理の研究の進歩を俯瞰するのに役立てば幸いです。
文の分類(評判分析・トピック分類・質問タイプ分類)
Convolutional Neural Networks for Sentence Classification(2014/08)
評判分析や質問タイプの分類などの文分類を行うCNNを提案している論文。
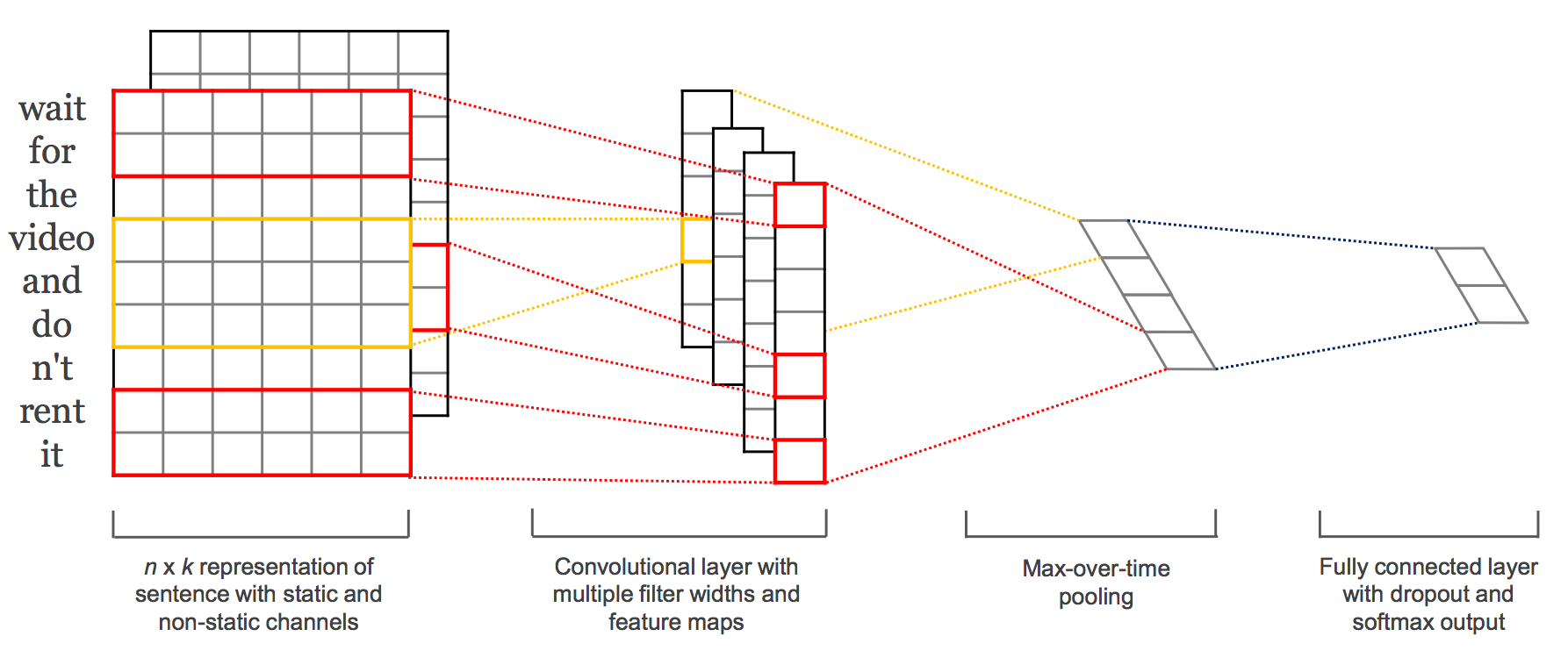
具体的には文を単語ベクトルの列として表し、それに対してCNNを用いて特徴抽出・分類を行っている。論文では事前学習済みの単語ベクトル(Google Newsをword2vecで学習したもの)を使うことで性能が向上したことが報告されている。2つのチャンネルそれぞれで単語ベクトルを表し、一方は学習中に更新、もう一方は更新しないようにすることで性能が上がるのが面白いところ。評判分析や質問タイプ分類を含む7つの文書分類タスクで評価したところ、7つ中4つのタスクで今までで最高の結果になった。
著者によるTheano実装とGoogle BrainのDenny BritzによるTensorFlow実装です:
https://github.com/yoonkim/CNN_sentence
https://github.com/dennybritz/cnn-text-classification-tf
ichiroexさんによる日本語での簡単な解説と実装
【Chainer】畳み込みニューラルネットワークによる文書分類
Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts(2014/08)
映画レビューやTwitterに対する評判分析を行うCNN(CharSCNN)を提案した論文。
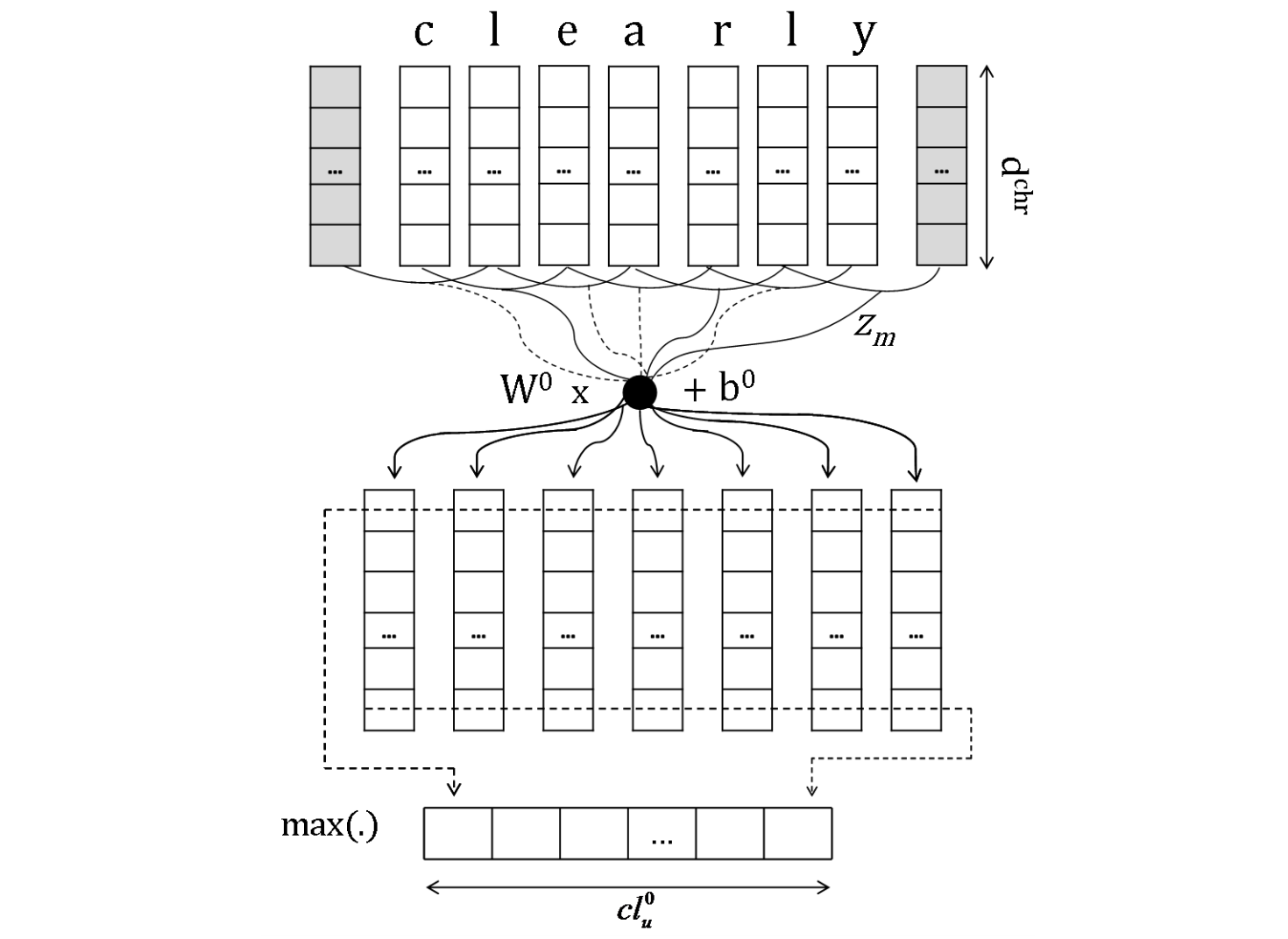
Twitter等の短いテキストに対する評判分析は文脈情報が限られているので難しいという問題がある。その問題に対処するために、評判分析をする際に通常使われる単語レベルのベクトル表現だけでなく、文字レベルのベクトル表現を構築し、それらを用いて文のベクトル表現を得ることで性能を向上させるということを行った。映画レビュー(SSTb)とTwitter(STS)に対するデータセットを用いて実験した結果、今までの手法より良い結果となった。
hogefugabarさんによるTheano実装です:
https://github.com/hogefugabar/CharSCNN-theano
解説記事も書いておられます:
深層学習でツイートの感情分析
#TAGSPACE: Semantic Embeddings from Hashtags(2014/10)
SNSに使われるハッシュタグを教師として短いテキストの表現を学習するCNNを提案した論文。
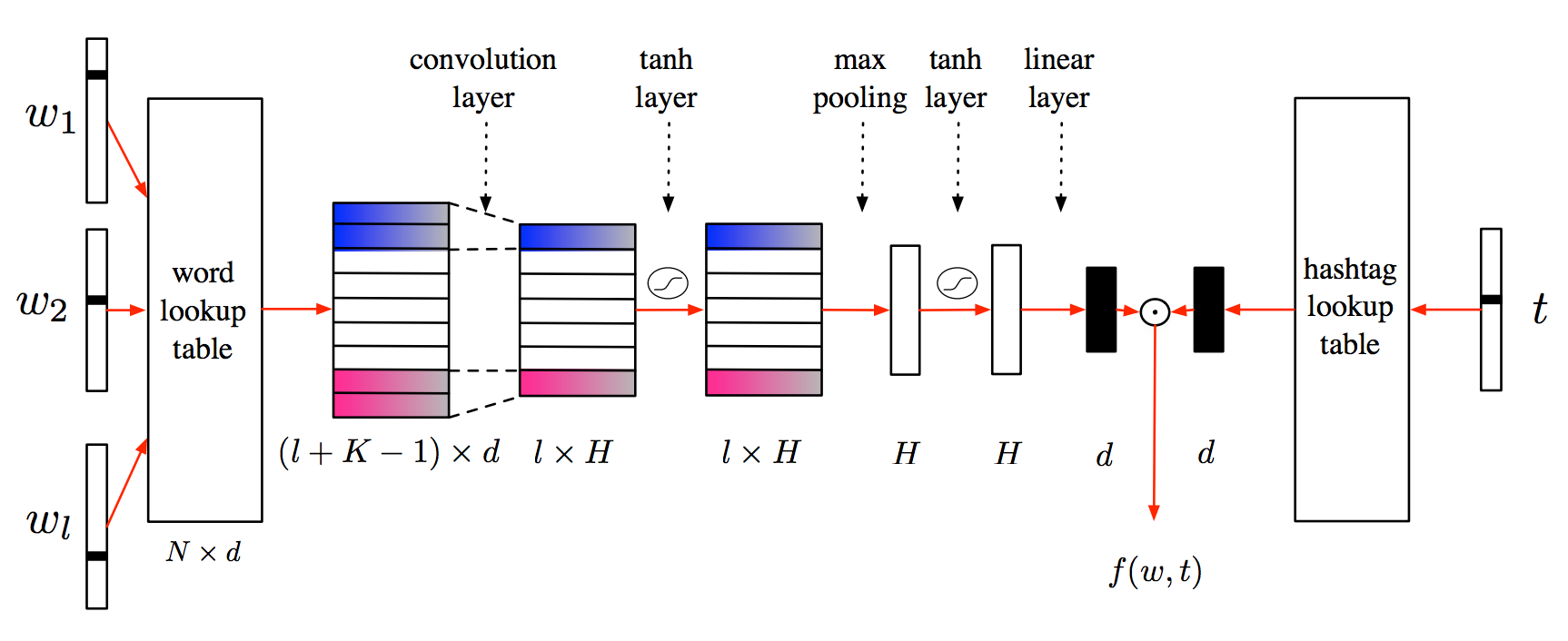
具体的にはCNNを用いて、入力テキストと対応するハッシュタグのペアに対してスコアを出力し、ハッシュタグのランク付けを行う過程でテキストの表現を学習する。ハッシュタグの予測と文書推薦タスクで評価を行った結果、ベースラインの手法よりも良い結果となった。
Effective Use of Word Order for Text Categorization with Convolutional Neural Networks(2014/12)
語順を考慮したテキスト分類を行うためのCNNを提案した論文。
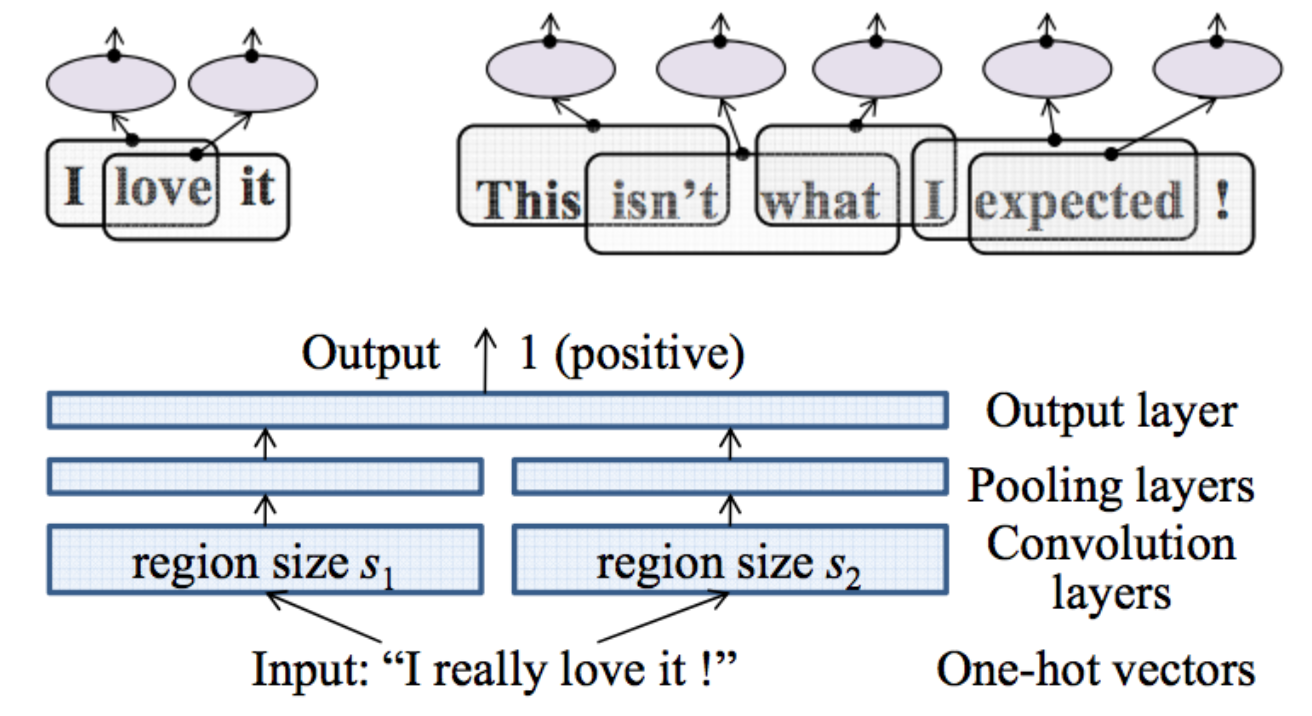
文書分類には様々なタスクがあるが、評判分析のようなタスクでは語順を考慮しないと高い性能が出ない。その問題に対処するために語順を考慮した文書分類を行うことのできるCNNを提案している。具体的には、たいていのCNNの手法では入力としてword embeddingを入力するが、この研究では高次元のone-hotベクトルをそのまま入力して、小さなテキスト領域のembeddingを学習する。評判分析(IMDB含む)とトピック分類に関する3つのデータセットでSOTAな手法と比較した結果、提案手法の有効性を示せた。
論文著者による実装です:
http://riejohnson.com/cnn_download.html
Semi-supervised Convolutional Neural Networks for Text Categorization via Region Embedding(2015/04)

テキスト分類のためにCNNを使った半教師あり学習のフレームワークを提案した話。従来モデルでは事前学習済みのword embeddingを畳み込み層の入力に使っていたが、本研究では小さいテキストの領域から教師なしでembeddingを学習し、教師ありCNNにおける畳み込み層の入力の一部として使う。評判分析(IMDB, Elec)とトピック分類(RCV1)で実験したところ、先行研究より高い性能を示した。
論文著者による実装です:
http://riejohnson.com/cnn_download.html
Character-level Convolutional Networks for Text Classification(2015/09)

文字レベルの畳み込みニューラルネットワークをテキスト分類に使った話。シソーラスを使ってテキスト中の単語を同義語で置換することでデータを増やしている。比較は、伝統的な手法としてbow、bag-of-ngram、bag-of-means、Deep Learning手法として、単語ベースのCNN、LSTMを対象に行っている。8つのデータセットを作成してベースの手法と比較した結果、いくつかのデータセットでは有効性を示せた。
論文著者によるLua実装です:
https://github.com/zhangxiangxiao/Crepe
A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification(2015/10)

CNNのモデルは文分類でいい結果を残しているけど、熟練者がアーキテクチャ決めたりハイパーパラメータを設定する必要がある。これらの変更がどのような結果を及ぼすのかよくわからないので、一層のCNNを使って検証した話。最後に、CNNで文分類するときにモデルのアーキテクチャやハイパーパラメータをどう設定すべきか実践的なアドバイスをしている。
系列ラベリング(品詞タグ付け・固有表現認識・チャンキング)
Natural Language Processing (almost) from Scratch(2011/03)
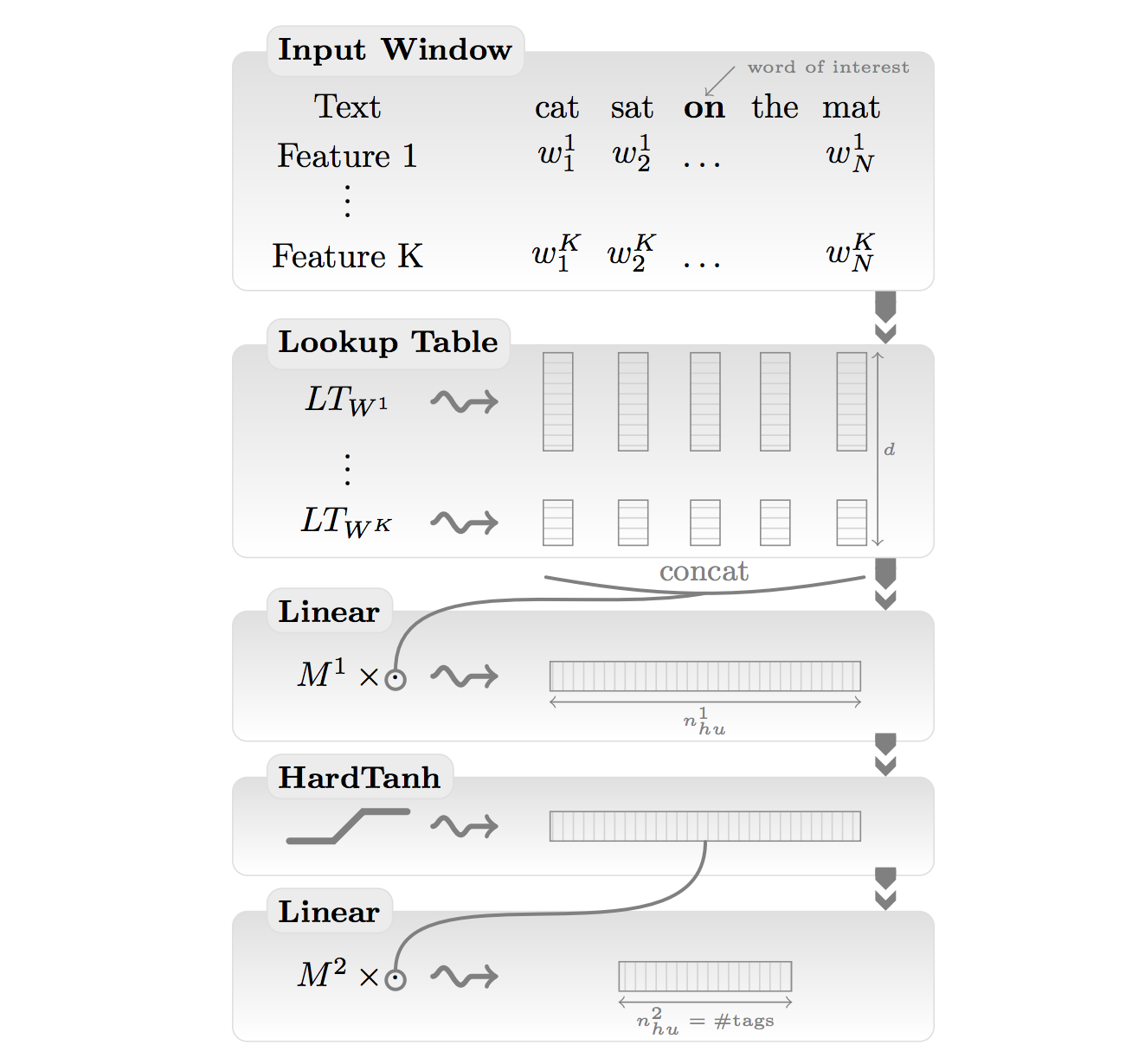
品詞タグ付け、チャンキング、固有表現抽出、意味役割付与を学習できるニューラルネットワークを提案した話。単純に学習させるだけではベンチマークより性能が下回ったが、ラベルなしデータを用いて言語モデルの学習を事前に行うことで、質の良い単語ベクトルが性能向上に寄与することを示した。さらに各タスクを解くためのモデル間でパラメタを共有してマルチタスク学習を行うことで性能がより向上することも示した。
日本語によるまとめスライドです:
Natural Language Processing (Almost) from Scratch(第 6 回 Deep Learning 勉強会資料; 榊)
Learning Character-level Representations for Part-of-Speech Tagging(2014/07)

品詞タグ付けをCNN(CharWNN)を使って行う話。具体的には、単語レベルと文字レベルのembeddingsを統合して単語のベクトル表現を構築し、構築したベクトルを入力することで品詞のスコアを出力するCNNを構築した。英語とポルトガル語に対するデータセット(WSJとMac-Morpho)を用いて実験した結果、SOTAな結果となった。
言語モデル
Language Modeling with Gated Convolutional Networks(2016/12)

言語モデルのタスクで、CNNでLSTM同等以上の精度を出したという話。畳み込んだ結果をGRUに近い機構で処理し、過去の情報が消失しないようにしている。Google Billion Wordのデータセットでは、LSTMと同等の精度を出す一方計算効率が20倍程度改善された。
TensorFlowによる実装です:
Language-Modeling-GatedCNN
おわりに
機械学習・自然言語処理・コンピュータビジョンの最新の論文情報のまとめを以下のTwitterアカウントで配信しています。この記事を読んでくれた方にとって興味深い内容を配信していますので、フォローお待ちしています。
arXivTimes