はじめに
本記事は弊社の Intelligent Data Management Cloud (IDMC) でデータカタログをこれから始めたい人向けに書いています。例えば、既に IDMC でデータ統合 (CDI) などは使っているけど、Cloud Data Governance and Catalog(CDGC, データガバナンス&データカタログ) は使った事がなかった、もしくは IDMC で契約したばかりで、「これから CDGC を触ろう、触らないといけないけども、何すればいいの?」という立場の方を想定しています。
というのも、製品もしくは機能を触り始めた段階でマニュアルの最初から読んでいく、というのはオーソドックスで王道なアプローチではあると思うのですが、時間もかかりますし、大変ですよね。
なので、本記事では "もっとざっくり流れやどんな感じか知りたいんだ!" 派の皆様へ、最短で、ざっくりと「CDGCのはじめ方」をお伝えできればと思っています。
目次
まずは全体の作業の流れを以下にざっくり纏めてみました。基本的には初期設定から基本的な情報を CDGC で検索できるようになるまでの流れを説明しています。各項目での個別の細かな手順は以降で説明しつつ、かつ、本記事が長くなりすぎないように日本語の KB や他の Qiita の記事を交えて紹介させて頂きます。
- ユーザー、ロールの作成
- CDGC をプロビジョニング
- Secure Agent の作成
- Secure Agent の設定
- ソースシステムへの接続を作成
- メタデータ抽出用の定義を作成
- カタログを検索
では、さっそく IDMC でデータカタログを最短コースで始めていきましょう!
1.ユーザー、ロールの作成
まずは IDMC にログインして CDGC を操作できるユーザーを作成する必要があります。アカウント管理者様へ相談し、以下の様なロールを持ったユーザーを作成してもらいましょう。
- ガバナンスユーザー
- ガバナンス管理者
以下はユーザーの設定画面のサンプルです。
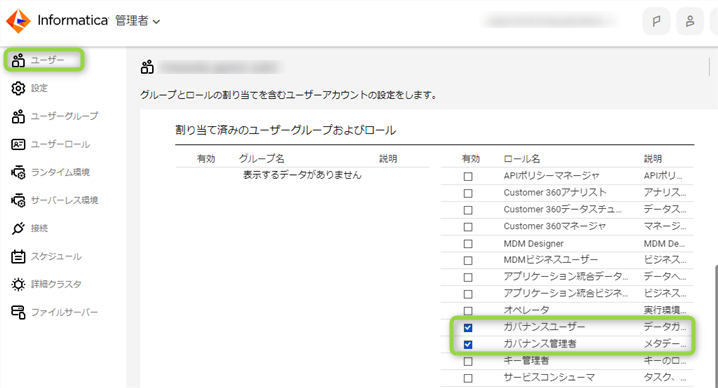
以降で説明する予定の SA の管理や接続定義などもひっくるめて行いたい方は上記に加え、"デザイナ" を追加して下さい。
2.CDGC をプロビジョニングする
それでは早速 IDMC にログインして CDGC にアクセスしてみましょう。"マイサービス" から "データガバナンス&データカタログ" をクリックします。
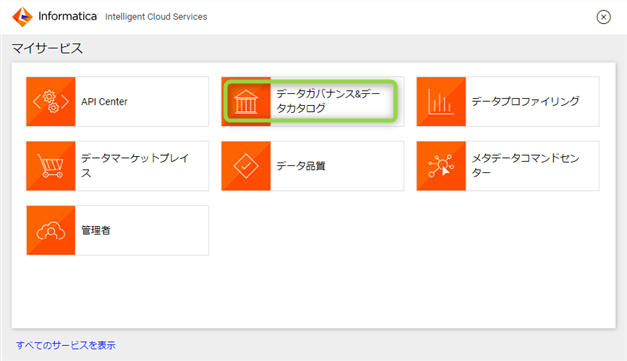
すると、以下の様な画面が出てきたのではないかと思います。
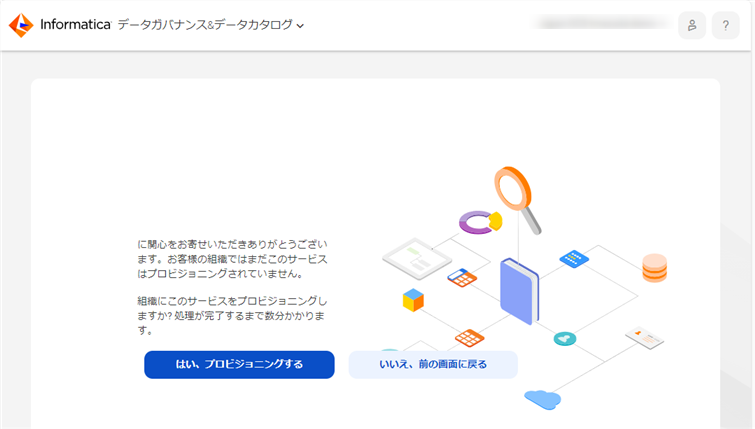
CDI や他のサービスと少し違い CDGC は初回アクセス時に利用開始の手続き(プロビジョニング)が必要です。ですので、上記画面で "はい、プロビジョニングする" をクリックしてください。プロビジョニングに関しては少しお時間が掛かります。 もし、数時間たっても変わらないなどがあれば、サポートまでお問い合わせください。
3.Secure Agent の作成
CDGC のプロビジョニングを待っている間に Secure Agent をインストールしてしまいましょう。インストール手順はどうしても少し手順が長めなので、詳細は以下の画面ショット付きの記事を参考にしてみてください。
[IDMC] Secure Agent のインストール手順(Linux編)
[IDMC] Secure Agent のインストール手順(Windows編)
注1
本記事に関してはあくまでも "現行環境" で "始める、試す" 事にフォーカスしていますので、開発・検証環境のような運用に影響のない環境での作業を想定しています。評価、テストのみであれば CDI が使用している SA で CDGC を有効にして使い始めることも選択肢の一つかと思いますが、一方で、本番もしくはそれに準ずる環境の場合、下記ドキュメントなども参考にしていただき、サイジング、性能評価を実施をするようにお願いします。
Sizing recommendation and performance optimization for Metadata Command Center
注2
現時点で共有エージェントはサポートしていない点に注意が必要です。
FAQ: Is metadata extraction supported using the shared secure agent group in the sub orgs CDGC?
仮に共有エージェントでスキャンを実行した場合にはエラーになります。
FAQ: Why does running a Metadata extraction job on a shared secure agent fails in CDGC?
4.Secure Agent の設定
4-1.サービスの有効化
Secure Agent のインストールが完了するとデフォルトではデータ統合に必要なサービス(Data Integration Service など)の幾つかが自動で起動してきます。ただ、CDGC が必要とするサービスはデフォルトでは有効化されませんので、手動でサービスを有効にする必要があります。下記の様に "管理者" => "ランタイム環境" で対象の SA を選択し、右側の "・・・" から、"サービス、コネクタの有効化または無効化" を選択します。
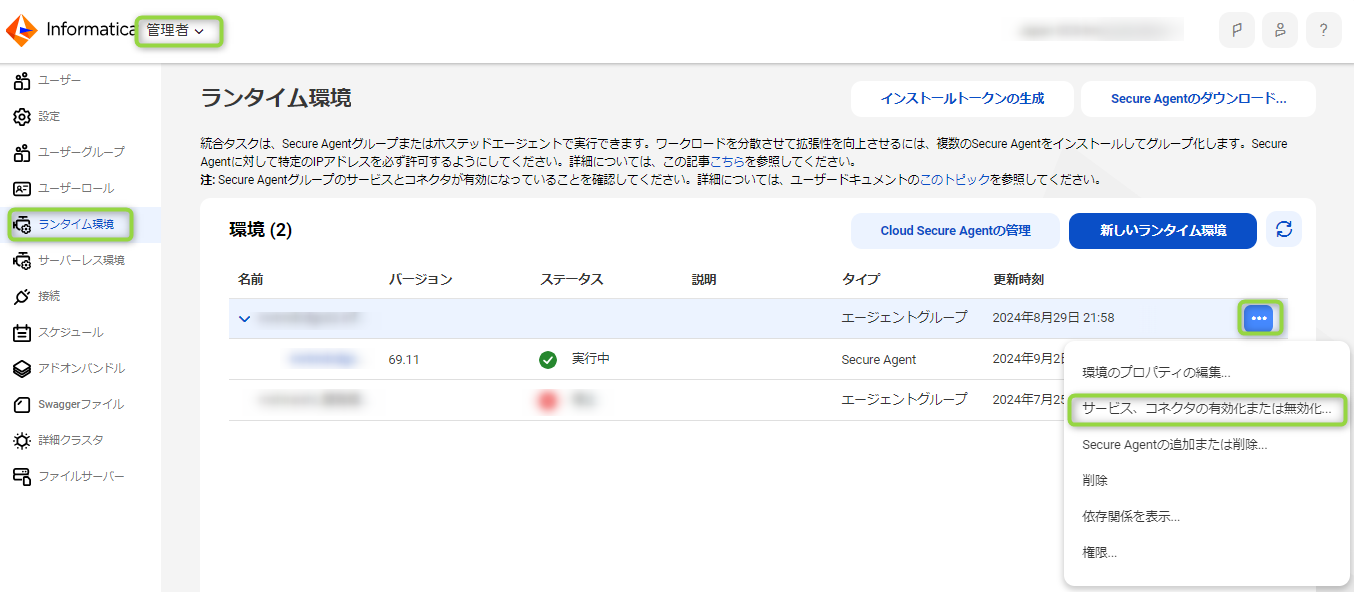
上記の順で選択すると以下の画面が出てきますので、"Data Governance and Catalog" を選択します。同手順は KB 000220795(日本語) でも紹介しておりますので、確認頂ければと思います。
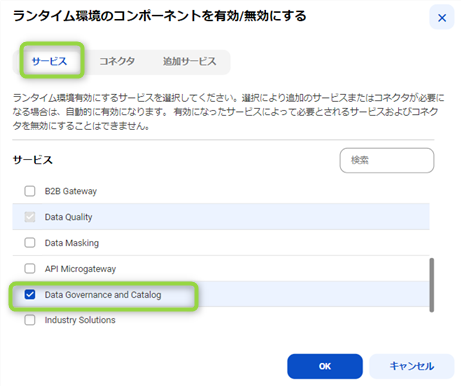
Secure Agent は IDMC が提供している各アプリケーションに対応するサービスをマイクロサービスとして実装している為、使う機能を選んで有効化する必要があります。
4-2.コネクタの有効化
また、今度は "コネクタ" タブに移動し、下記画面の様に抽出したいカタログリソースへの接続も有効にしておく必要があります。今回は Azure Synapse Analytics 接続を使用してみます。
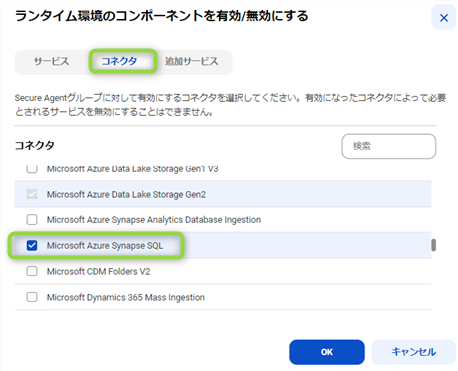
デフォルトでも Oracle Database 及び Microsoft SQL Server などのいくつかのコネクタは使用できるようになっていますが、それ以外のコネクタは必要に応じて手動で有効にする必要があります。
5.ソースシステムへの接続を作成
次にメタデータを抽出したい対象システムへの接続を定義する必要があります。接続に関してはマイサービスの "管理者" から "接続" をクリック、"新しい接続" で作成できます。先程、Azure Synapse Analytics コネクタを有効化しましたので、以下は Azure Synapse Analytics で接続情報を設定した例になります。
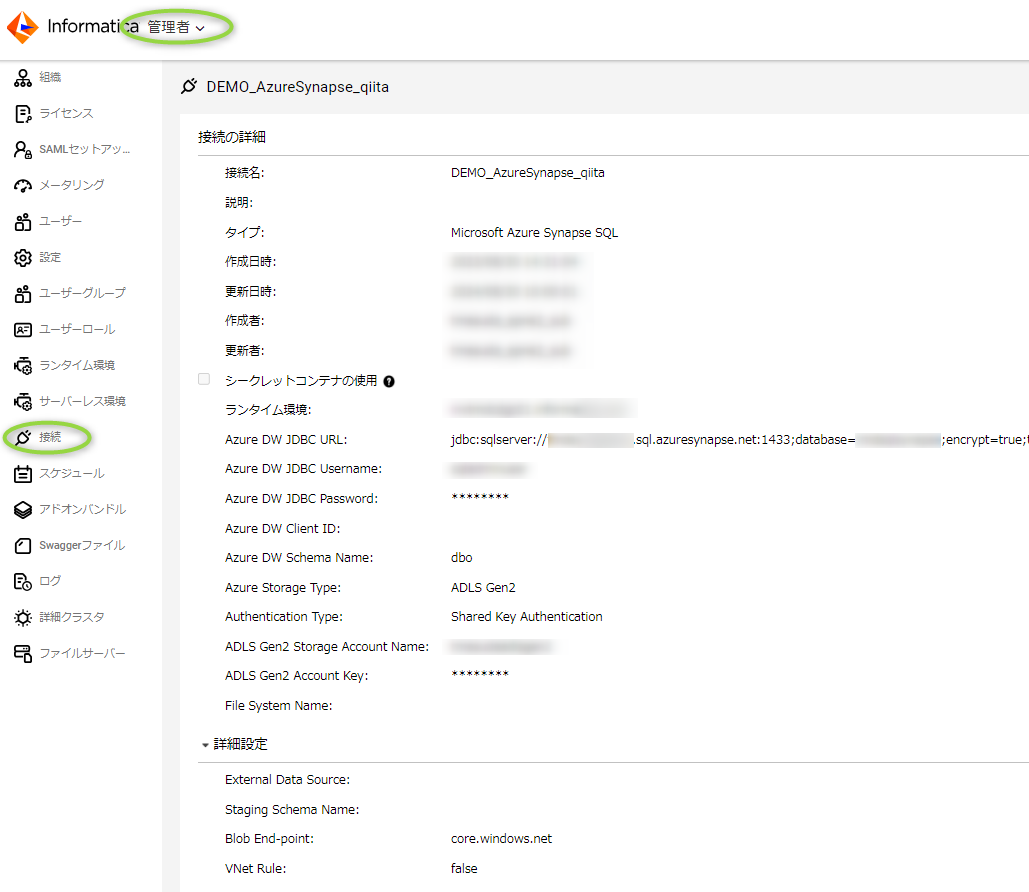
"接続のテスト" で問題なければ設定はこれで完了です。別のソースシステムに接続したい場合、項目、手順の詳細は製品ごとに異なりますので、マニュアルを参照してください。
6.メタデータ抽出用の定義を作成
ここからは対象のシステムからデータをカタログ化するための設定を行います。IDMC のマイサービスから "メタデータコマンドセンター"(以降、MCC)をクリックします。
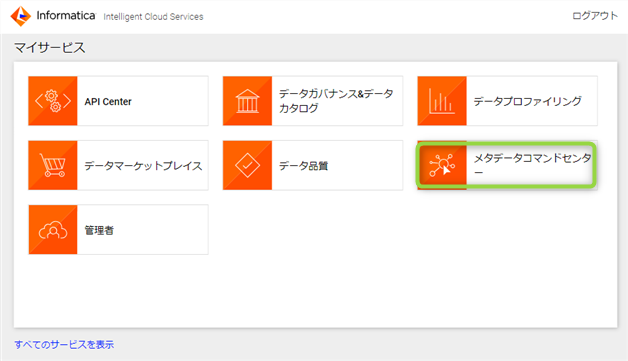
え、"データガバナンス&データカタログ" をクリックするんじゃないの?と思われた方もいるんじゃないでしょうか。なので、ここで用語、機能について補足をさせて下さい。データカタログと用語では一括りにされていても IDMC のサービスレベルで見てみると、役割ベースで以下の 2 つの機能に分れて実装されています。
| サービス名 | 省略名 | 役割 |
|---|---|---|
| Metadata Command Center | MCC | どのリソースからメタデータを取得するのか、プロファイルしてデータ分析をするのかなどを定義するサービス。なので、この UI では対象リソースへの接続を指定したり、スキャンしたいスキーマを指定したり、どういったデータを抜き出し、カタログ化するかを定義する。 |
| Data Governance and Catalog | CDGC | MCC の定義を元にスキャンされたメタデータや、プロファイルの結果を確認できるサービス。また、スキャンしたアセットに対して説明や用語を補足したり、データを分類したり、カタログで検索するユーザーに向けて分かりやすく補足、エンリッチさせる事が出来る。 |
つまり、カタログ化したいソースシステムの定義は MCC で、カタログ化した結果は CDGC で確認する流れになります。
6-1. リソースの新規作成
それでは改めて、"メタデータコマンドセンター" をクリックして、メタデータ抽出用の設定を行いましょう。以下は MCC にログイン後、左上にある "+新規" ボタンをクリック、"カタログソース" タブをクリックした際の画面です。

この画面では様々な利用可能なタイプのスキャナが表示されていますが、今回は接続と同じ Azure Synapse Analytics を選択します。任意の "名前" を入力し、"接続"をドロップダウンリストから選択します。
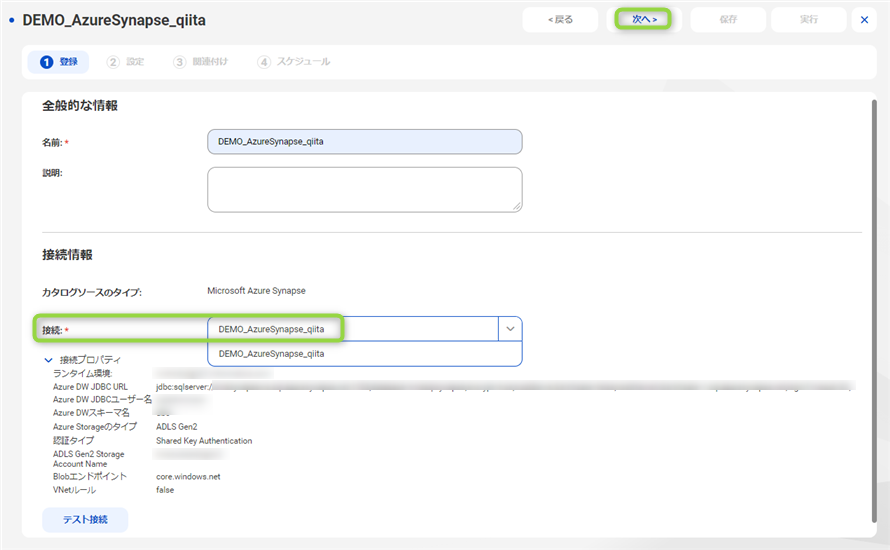
ドロップダウンリストにはリソースタイプに応じた接続のみが表示されますので、先程作成した接続が見えているかと思います。そちらを選択すると、"テスト接続"が有効になりますが、先程、テスト接続しているのでスキップして、右上の "次へ" をクリックします。
6-2. "メタデータの抽出"の設定
"メタデータの抽出" 画面で "ランタイム環境" から 4.Secure Agent の設定 で作成した Secure Agent を選択し、他の設定は今回デフォルトのままとします。
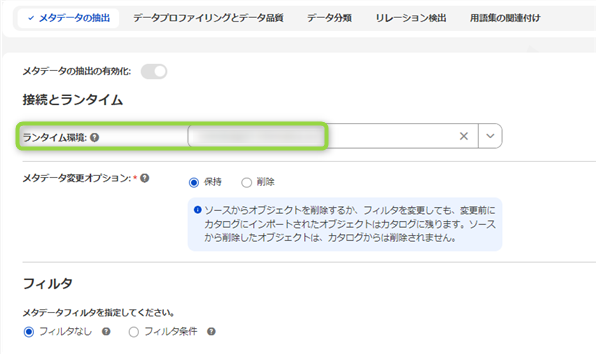
※今回、フィルタ条件は設定しませんが、何らかの抽出条件がある場合には "フィルタ条件" にチェックを入れて条件付きで抽出する事が出来ます。また、チェックを入れるとリソースに応じたフィルタの設定例を表示してくれますので、必要に応じてフィルタ条件を設定してみてください。

6-3. "データプロファイリングとデータ品質" の設定
こちらについては必須ではありません。まずはお使いのシステムからメタデータを抽出したい、という要件の場合にはこの手順をスキップできます。
ただ、メタデータの抽出に加え、含まれるアセットのデータの分布など、データの特徴も把握したい場合には "データプロファイリングとデータ品質" タブをクリックします。最初、"データプロファイリングの有効化" が有効化されていませんので、クリックして有効化します。また、ランタイム環境はメタデータ抽出と同様に 4.Secure Agent の設定 で作成した Secure Agent を選択します。
こちらにあるフィルタは抽出されてきたメタデータからプロファイルしたいメタデータに条件を付けることができます。今回も特に条件を付けずに全体をプロファイルします。
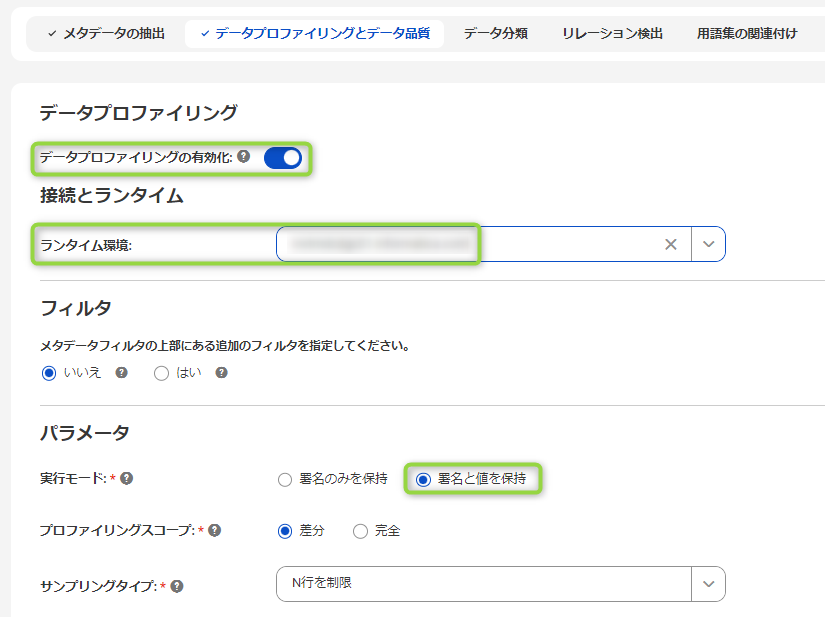
"パラメータ" では主に以下の項目を設定します。
| パラメータ名 | 値の説明 |
|---|---|
| 実行モード | 列が持つデータの分布(値の頻度)を見たい場合、"署名と値を保持" を選択します。"値の頻度" は CDGC の UI より以下のようにどのような値があるのか、その分布を確認できるようになっています。 
|
| プロファイリングスコープ | "差分"を設定した場合、前回のスキャンから変化がないテーブルはプロファイル用のジョブがスキップされます。一方で "完全" にした場合には常に毎回全てのアセットに対してプロファイル用ジョブが実行されます。 |
| サンプリングタイプ | "全ての行" もしくは "N行を制限" もしくは "カスタムクエリ" を選択できます。全データに対してサンプリングをしたい場合、"全ての行" を選択します。一方で、LIMIT N 句の様な一定行数で制限したい場合に "N行を制限" を指定します。 |
その他、データ分類やリレーション検出、用語集の関連付け等もありますが、本記事では一旦スキャンして結果を見えるようにするまでをスコープとしていますので、これらはスキップさせて頂きます。

上記の様に右上の "次へ" をクリックし、"保存" を実行して頂く事で UI の "実行" がアクティベートされるかと思いますので、"実行" をクリックし、しばらく待機してみましょう。
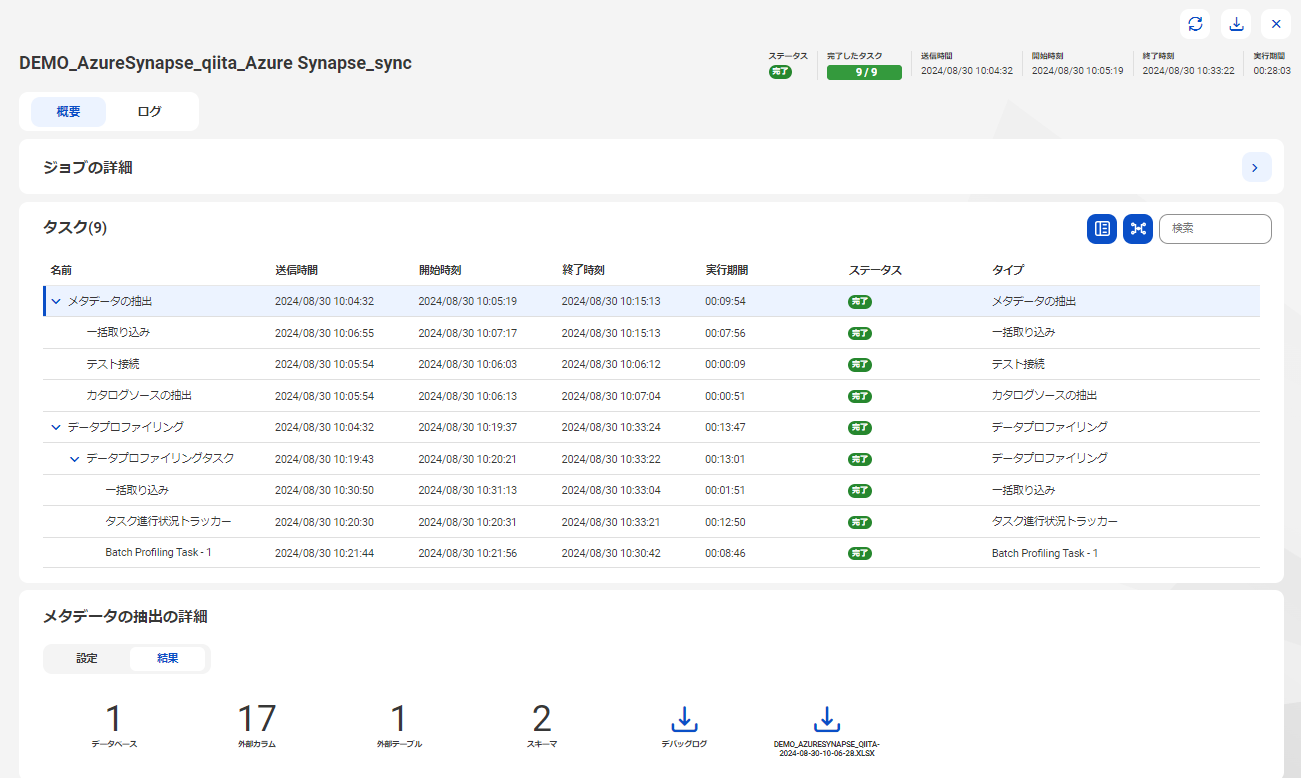
上記は弊社側で実行した際の結果です。もし、想定と異なり、何らかのエラーになる場合、このKBに従い、情報を集めて弊社サポートまでご連絡ください。
7.CDGC でスキャンした結果を確認する
スキャンが正常に完了したら、データベースから取得したメタデータの情報を見てみましょう。"マイサービス" から "データガバナンス & データカタログ" をクリックします。
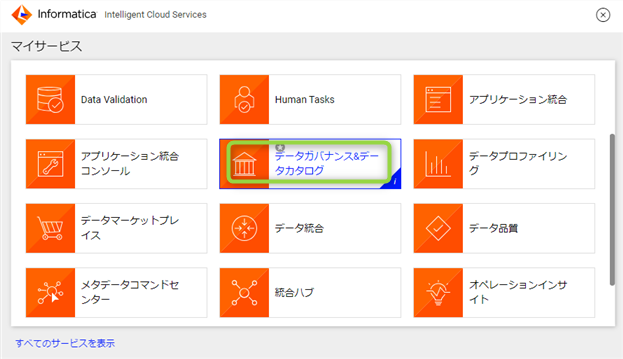
クリックすると "マイダッシュボード" の画面が表示されるかと思います。ダッシュボードの上にある検索ウィンドウからキーワードで検索する事が出来ます。

もしくは、今時点でキーワードはないけどもスキャンしたリソースから自身で何があるか確認したい、などであれば、"テクニカルアセット" からスキャン済みのリソース一覧を確認できますので、そちらからドリルダウンしていくことも出来ます。
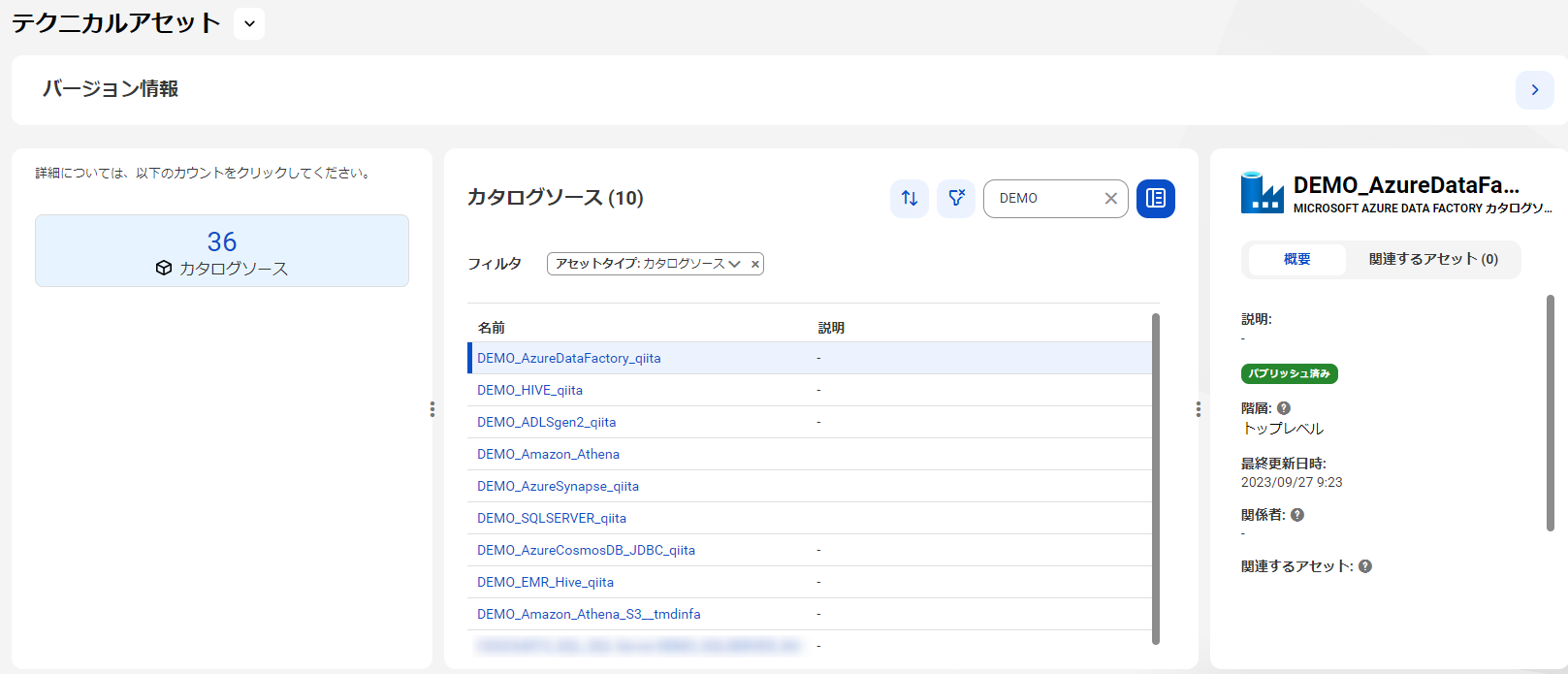
それでは今回スキャンした、Azure Synapse Analytics のリソースを開いてみましょう。環境の都合上、ちょっとシンプルすぎるメタデータになっていますが、実際の環境ではテーブル、ビューなど、多数のアセットが見えている事と思います。
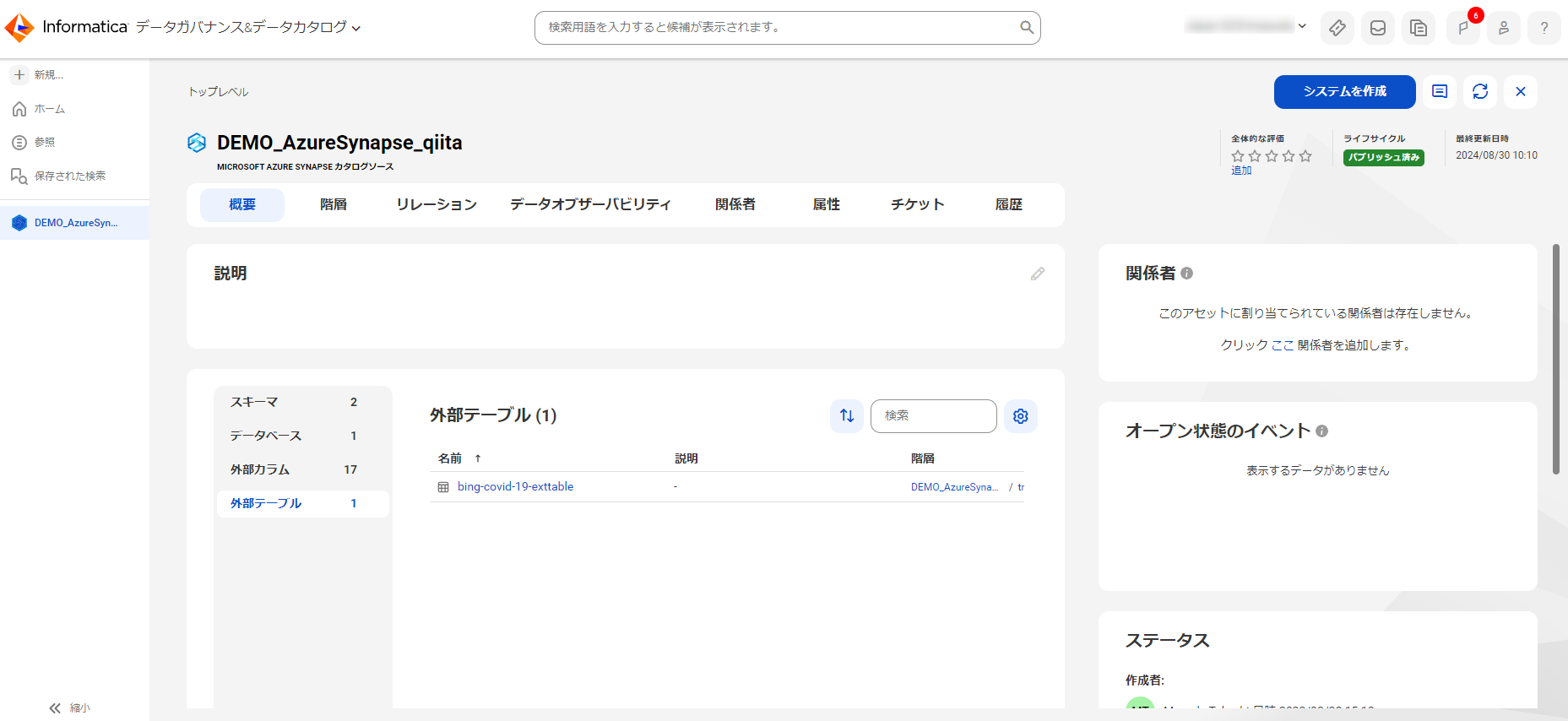
お使いの環境で抽出された任意のテーブルを開いて頂ければと思いますが、以下の様にテーブルの基本情報が表示されます。列などの詳細は "含まれる項目" タブから確認ができます。
"含まれる列" とかの方がわかりやすいかとは思うのですが、テーブルの場合には列、テキストの場合にはフィールド、また他のは別の何か、という形になりますので、汎用化して今開いているアセットに "含まれる項目" というラベルになった経緯があります。

それでは "含まれる項目" をクリックして、列の一覧を見てみましょう。以下の例では id 列を選択中ですが、右側には id 列の値の一部や、データ型、また、各列のデータがNullを含むか、一意か、どの程度重複を含むかなども確認が出来るかと思います。
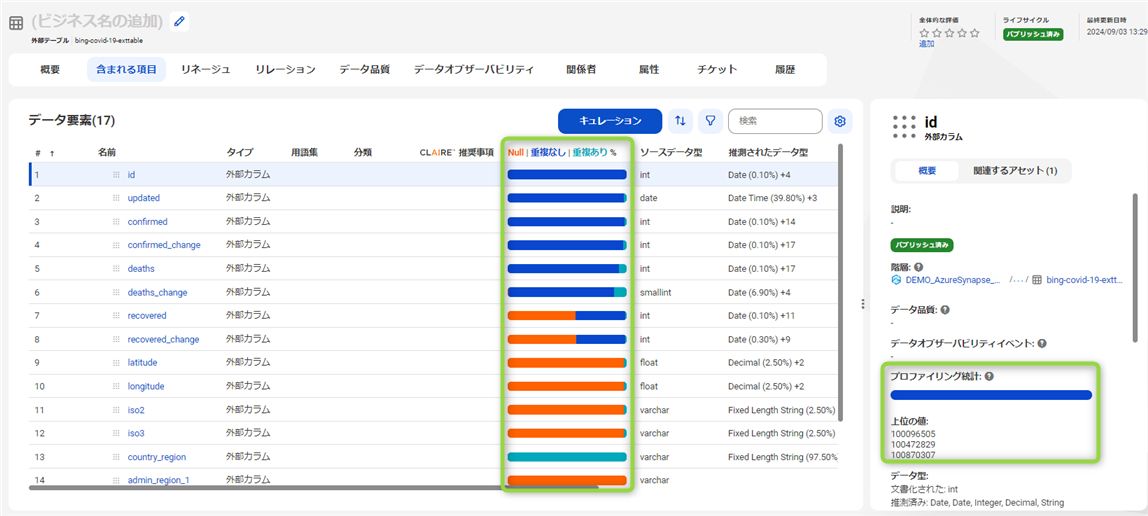
もう1つ、別の列も見てみましょう。confirmed_change 列を見てみると、データのパターンや "値の頻度" から、データの分布などの直感的なデータの情報を得ることが出来ます。
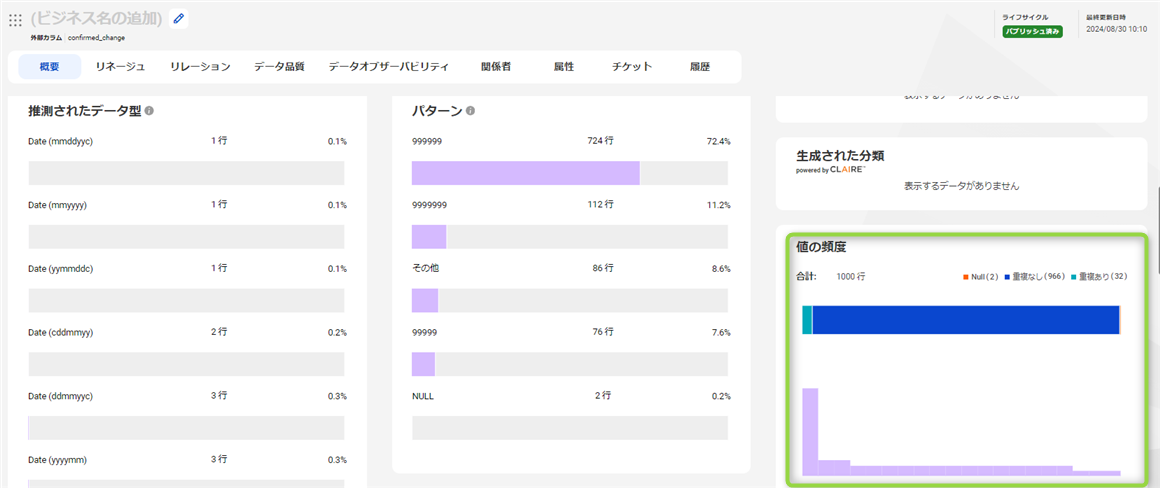
今回のデータ自体は単なるデモデータになりますが、実際のビジネスで使用されているデータを見える化していけばデータから多くの情報を得ることが出来るのではないかと思います。ぜひ、多くのリソースをスキャンしていただき、IDMC/CDGC を使ってデータを活用頂ければと思います。
参考
今回は Microsoft 社の Azure Synapse Analytics のスキャンをベースに説明をしてきましたが、他にも メジャーなリソースについていくつか Qiita で手順をまとめています、是非、それらについても確認していただければと思います。
Microsoft 関連
[CDGC] Microsoft SQL Server のスキャン
[CDGC] Azure Synapse Analytics のスキャン
[CDGC] ADLS gen2 のスキャン
[CDGC] Azure Data Factory のスキャン
[CDGC] JDBC のスキャン(JDBC scanner で Azure Cosmos DB からメタデータを取得する)
その他、システムリソースのスキャン関連
[CDGC] Google BigQueryのスキャン
[CDGC] Snowflakeのスキャン
[CDGC] Oracle のスキャン
[CDGC] Oracle PL/SQL スクリプトのスキャン
[CDGC] Amazon S3のスキャン
[CDGC] Amazon Redshiftのスキャン
[CDGC] Talend のスキャン
[CDGC] File System のスキャン
[CDGC] MySQL のスキャン
[CDGC] Apache Hive のスキャン