はじめに
複雑な問題を最適化を使ってスマートに解きたい、でも問題が複雑すぎて普通の最適化手法は適用できない、ということは多いです。そんなときに使えるのが、入力に対する出力だけ分かればその間にあるメカニズムがわからなくても「いい感じ」に最適な入力を探してくれる、ブラックボックス最適化手法です。
今回、複雑な問題の例として機械学習モデルのハイパーパラメータ(パイプライン)最適化問題を考え、ベイズ最適化をしてくれるOptuna、遺伝的プログラミングをしてくれるTPOTの2つのツールを触ってみたので、
- ツールの使い方の簡単な解説
- 実装例
- 最適化の様子の観察結果
を記事にまとめます。
扱う問題と手法(ツール)
ブラックボックス最適化手法は、最大化or最小化したい具体的な目的関数の形がわからなくても、ある入力に対する出力がわかればそれをもとにいい感じに次の探索点として適切な入力を決定し、再び出力を得て次の探索点を探す……というプロセスを繰り返すことで、最終的にはそこそこ良い結果を自動的に見つけてくれるという手法です。
本記事ではひとまずよくある問題として、機械学習のハイパーパラメータ最適化を扱ってみます。
# 本当はもっとややこしい問題が手元にあるんですが、今回はひとまず手法の検証という位置づけでベタな問題設定を試してみます。
# なので、機械学習の性能どうこうの話にはそこまで深入りしないです。
# そもそもの探索空間が全然違うので、OptunaとTPOTの性能比較ということでもないです。ご了承ください。
問題
kaggleでおなじみのTitanicデータを使用し、生か死かの二値分類を考えます。
手法
ハイパーパラメータ最適化のナイーブな手法としては、
- GridSearch:候補となる全組み合わせをしらみ潰しに探す
- RandomSearch:候補となる組み合わせをランダムに探す
があります。
ここではより賢そうな手法として、以下の2つを試してみます。
ベイズ最適化
参考:ベイズ最適化入門
超ざっくり言うと、各ステップまでに実験した値をもとにして、探索対象の変数から目的関数の値を得る関数の形を推定しながら、次のステップで調べる値を決めていきます。この際、推定したい関数の平均と分散を考慮して、推定される目的関数の値の
・平均が大きい点(最大化の場合)
・分散が大きい点
ほど、次の探索対象として選ばれやすくなるようにします。つまり、「結果が良くなりそうなところ」だけでなく、「まだあまり探索していないからひょっとすると良いかもしれないところ」も重視して探索していくわけです。探索(exploration)と活用(exploitation)のバランスを取るというやつです。
Pythonでベイズ最適化を行うライブラリとしては、GPyOptやHyperoptなど色々出てきますが、今回はPFNが公開しているOptunaを試してみます。ベイズ最適化と一口に言っても具体的な手法にはいろいろありますが、これはその中でもTPEと呼ばれるものを用いています。
・参考:Optuna(TPE)のアルゴリズム理解 ー Part 1 ー
遺伝的プログラミング
別のアプローチとして、遺伝的プログラミングもブラックボックス最適化に利用できそうです。遺伝的プログラミングとは、遺伝的アルゴリズムを木構造を扱えるように改良したもの、だと思っています。
機械学習用途に限定されてしまいますが、TPOTというツールがあります。
・参考:TPOTで自動機械学習(回帰)を試した
こちらの強い点は、単なるハイパーパラメータの最適化に留まらず、特徴エンジニアリングや特徴選択といった前処理まで含めたパイプラインの最適化を行ってくれるというところです。パイプラインを木構造で表現し、その構造と各要素で用いるハイパーパラメータの最適化を合わせて行ってくれます。
その他?
最近だと、強化学習をこういったブラックボックス最適化に活用するという手法もあるようですが、まだよくわかっていません……
環境
- Mac OS X Mojave 10.14.4
- Python 3.6.8 (64-bit)
- Optuna 0.19.0
- TPOT 0.11.0
1. ベイズ最適化:Optuna
Optunaとは
オープンソースのハイパーパラメータ自動最適化フレームワークOptuna™は、ハイパーパラメータの値に関する試行錯誤を自動化し、優れた性能を発揮するハイパーパラメータの値を自動的に発見します。オープンソースの深層学習フレームワークChainerをはじめ、様々な機械学習ソフトウェアと一緒に使用することが可能です。
ブラックボックス最適化を実行するために必要なのは、最適化対象(今回はハイパーパラメータ)の探索空間の設定と、目的関数の実装です。この2つを与えてやれば、あとはいい感じに探索を行ってくれます。
Optunaの特筆すべき特徴として、Define-by-Runスタイルを採用しているという点があります。パラメータの探索空間は、目的関数と独立に定義するのではなく、目的関数を定義する中で合わせて定義していく形になります(下記objective内)。つまり、あるパラメータの値に依存して別のパラメータの設定の仕方を変える、といった動的な設定が可能になっています。
公式のチュートリアルでは以下のような例が紹介されています。
- 学習モデルの種類を候補の中から選択した上で、種類によってそれぞれに固有のハイパーパラメータを最適化する
- ニューラルネットワークの層の数をハイパーパラメータとして選択し、各層のユニット数を個別に最適化する
これをうまく使えば、それこそパイプライン構造の最適化のような複雑な問題設定への対応も可能だと思います。
実験
では実際に、Titanicデータを使った二値分類をやってみます。実装は、公式のexampleをもとに、データをTitanicに対応させる・評価にcross validationを用いるようにする、といった変更を加えています。
モデルにはシンプルなLightGBMを用いています。
import numpy as np
import matplotlib.pyplot as plt
import lightgbm as lgb
import sklearn.metrics
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
import optuna
def objective(trial):
data = pd.read_csv('data/titanic/train.csv')
# Titanicデータの前処理
# PassengerId、Nameは削除
# その他のカテゴリ変数はintに変換
data = data.drop(['PassengerId', 'Name'], axis=1)
cat_columns = ['Sex', 'Ticket', 'Cabin', 'Embarked']
for cat_col in cat_columns:
target_column = data[cat_col].fillna('0')
le = preprocessing.LabelEncoder()
le.fit(target_column)
label_encoded_column = le.transform(target_column)
data[cat_col] = pd.Series(label_encoded_column).astype('category')
data_y = data['Survived']
data_x = data.drop('Survived', axis=1)
dtrain = lgb.Dataset(data_x, label=data_y)
param = {
'objective': 'binary',
'metric': 'binary_logloss',
'verbosity': -1,
'boosting_type': 'gbdt',
'lambda_l1': trial.suggest_loguniform('lambda_l1', 1e-8, 10.0),
'lambda_l2': trial.suggest_loguniform('lambda_l2', 1e-8, 10.0),
'num_leaves': trial.suggest_int('num_leaves', 2, 256),
'feature_fraction': trial.suggest_uniform('feature_fraction', 0.4, 1.0),
'bagging_fraction': trial.suggest_uniform('bagging_fraction', 0.4, 1.0),
'bagging_freq': trial.suggest_int('bagging_freq', 1, 7),
'min_child_samples': trial.suggest_int('min_child_samples', 5, 100),
}
cv_result = lgb.cv(param, dtrain, nfold=5, metrics='auc')
return cv_result['auc-mean'][-1]
このobjectiveが最適化する目的関数になります。この中で、trial.suggest_int等で探索空間を定義しています。
このように、目的関数内で探索空間を定義することで、条件付きパラメータ等も柔軟に設定することが可能になります(ここでは、全部まとめて設定するシンプルな形になっています)。
データをもとにLightGBMで学習を行い、cross validationの結果のAUCの値を返します。これを最大化することが目的になります。
このobjectiveを使って最適化を実行します。
今回はAUCを最大化したいので、direction='maximize'を指定してstudyオブジェクトを生成しています。ステップ数は200に設定します。
study.optimizeを呼び出すと最適化が実行され、その過程と結果はstudyオブジェクト内に格納されます。
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=200)
print(f'Number of finished trials: {len(study.trials)}')
print('Best trial:')
trial = study.best_trial
print(f' Value: {trial.value}')
print(' Params: ')
for key, value in trial.params.items():
print(f' {key}: {value}')
Number of finished trials: 200
Best trial:
Value: 0.8746183253734463
Params:
lambda_l1: 6.04386664092051e-07
lambda_l2: 0.2406416092392933
num_leaves: 103
feature_fraction: 0.661309206008689
bagging_fraction: 0.670194374502007
bagging_freq: 1
min_child_samples: 25
探索の中で最も良かった試行(trial)のスコアと、その時のパラメータが確認できました。
探索によってスコア(各ステップまでの目的関数の最大値)がどんな風に遷移してきたのか見てみます。
result_values = [trial.value for trial in study.trials]
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(range(1, len(study.trials)+1), result_values)
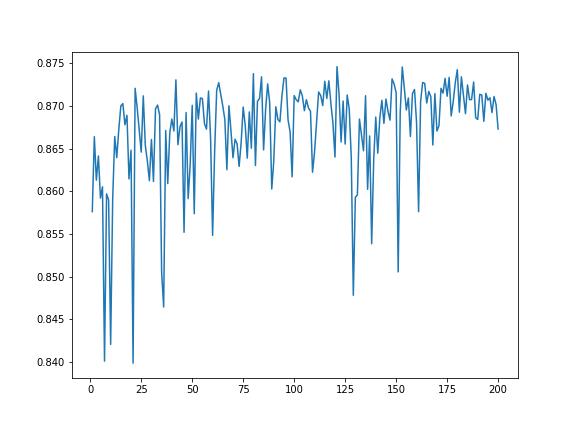
割と荒ぶってますが……
ベイズ最適化では「探索(exploration)」と「活用(exploitation)」の双方を意識しながら最適化を進めていくわけで、「荒ぶりながらも着実に改善に向かっている」状態が良いのではないかと思います。そういう意味では悪くなさそう。
実際には各ステップまでで最良の結果を採用することになるので、それをプロットするとこうなります。
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(range(1, len(study.trials)+1), pd.Series(result_values).cummax())
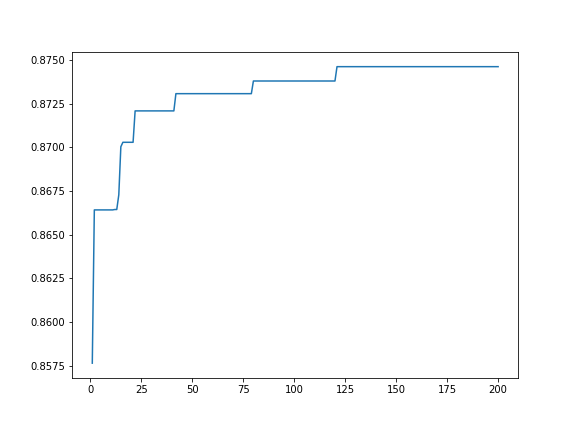
いい感じですね。
次に、探索空間をどのように探索しているのか、可視化してみます。
以下では試しに2つのハイパーパラメータ(num_leaves、min_child_samples)を選び、200回の試行の中で探索された点をプロットしています。赤い点が、最終的に選択された、最も良かった点です。
ベイズ最適化の気持ちの通り、最適なものの周りを特に重点的に探索しつつ、それ以外の部分もそこそこは試してみる感じ……になっている気がしなくもないです。
searched_params = np.array([[trial.params['num_leaves'], trial.params['min_child_samples']] for trial in study.trials]).T
best_trial = study.best_trial
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.scatter(searched_params[0], searched_params[1])
ax.scatter(best_trial.params['num_leaves'], best_trial.params['min_child_samples'], color='r')
ax.set_xlabel('num_leaves')
ax.set_ylabel('min_child_samples')
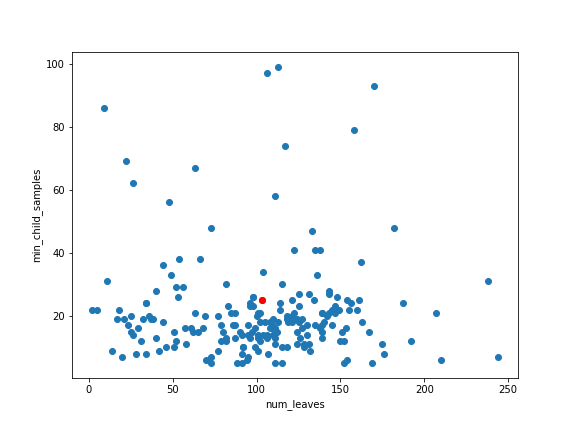
というわけで、Optunaの最適化により、AUCが0.856...→0.874...と改善しました!
Submitしてみる
テストデータに対する予測を行ってkaggleにsubmitしたスコア(accuracy)も参考までに比較してみます。
- 特に最適化せずにデフォルトのパラメータを使ってLightGBMで学習したモデルのスコア:0.746
- Optunaで最適化したモデルのスコア:0.741
ちょっと悪化している……。
LightGBM自体、それほどハイパーパラメータの値に影響を受けやすい手法ではないので、むしろ過学習気味になってしまっている感じかな、と思います。
2. 遺伝的プログラミング:TPOT
TPOTとは
TPOT is a Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.
別のアプローチとして、遺伝的アルゴリズムによってブラックボックス最適化を行う手法も試してみます。
Pythonで遺伝的アルゴリズムを使うライブラリとしてDEAPというものがあります。TPOTは、内部的にはDEAPを用い、特に機械学習のパイプラインを最適化するツールです。
Optuna(TPE)を始めとするベイズ最適化による手法と比べたときのアピールポイントとして、TPOTは前処理のパイプラインそのものを最適化してくれるという点が挙げられます。パイプラインの構成要素として、特徴エンジニアリングや特徴選択、学習モデルの構築といったものが予め用意されており、その中から何をどのような順番で実行するのか、ハイパーパラメータはどうするのか、といったことを全部ひっくるめていい感じに探索してくれるというのです。パイプラインを木構造で表現し、その構造含めて最適化するとのこと。すごそう。
Optunaで似たようなことをやろうとしたら、条件付きパラメータを駆使して非常に複雑なobjectiveの定義をする必要がありそうです。
ただし、TPOTの構成要素はツールに用意されているものだけなので、もっと柔軟に異なるタスクに対して同様のアプローチを取るには直接DEAPを叩く必要がありそう。
実験
先ほどと同様にデータを準備します。
先ほどはLightGBMを使いましたが、TPOTは複数のモデル(xgboostがインストールされている環境なら、xgboostを含む)の中から適切なものを探してくれます。ただしLightGBMは候補に含まれていないので使えません。
from tpot import TPOTClassifier
tpot = TPOTClassifier(generations=100, population_size=50, cv=5, verbosity=2)
# 先ほどと同じ条件でデータ準備
data = pd.read_csv('data/titanic/train.csv')
# Titanicデータの前処理
# PassengerId、Nameは削除
# その他のカテゴリ変数はintに変換
data = data.drop(['PassengerId', 'Name'], axis=1)
cat_columns = ['Sex', 'Ticket', 'Cabin', 'Embarked']
for cat_col in cat_columns:
target_column = data[cat_col].fillna('0')
le = preprocessing.LabelEncoder()
le.fit(target_column)
label_encoded_column = le.transform(target_column)
data[cat_col] = pd.Series(label_encoded_column).astype('category')
# target列の名前を「class」にしておく必要があるらしい
data.rename(columns={'Survived': 'class'}, inplace=True)
data_y = data['class']
data_x = data.drop('class', axis=1)
tpot.fit(data_x, data_y)
TPOTClassifierを利用し、遺伝的プログラミングにおけるパラメータを適宜設定して、あとはデータを与えてfitを呼んでやることで最適化を実行してくれます。こちらも、cross validationしたAUCを評価指標としています。
100世代分計算を回しましたが、各世代で50個のモデルを個別に評価しているので、そこそこ時間はかかります。
最適化の結果得られたパイプラインは以下のようにして.pyファイルとして出力できます。
tpot.export('tpot_titanic_pipeline.py')
import numpy as np
import pandas as pd
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline, make_union
from tpot.builtins import OneHotEncoder, StackingEstimator, ZeroCount
from xgboost import XGBClassifier
from sklearn.impute import SimpleImputer
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'], random_state=None)
imputer = SimpleImputer(strategy="median")
imputer.fit(training_features)
training_features = imputer.transform(training_features)
testing_features = imputer.transform(testing_features)
# Average CV score on the training set was: 0.858602724248321
exported_pipeline = make_pipeline(
make_union(
ZeroCount(),
StackingEstimator(estimator=make_pipeline(
OneHotEncoder(minimum_fraction=0.2, sparse=False, threshold=10),
GradientBoostingClassifier(learning_rate=0.1, max_depth=6, max_features=0.8500000000000001, min_samples_leaf=9, min_samples_split=19, n_estimators=100, subsample=0.8500000000000001)
))
),
XGBClassifier(learning_rate=0.001, max_depth=5, min_child_weight=17, n_estimators=100, nthread=1, subsample=0.6000000000000001)
)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
今回も、スコアの推移を見てみます。
探索の経過はtpot.evaluated_individuals_に保存されているんですが、どうも十分な情報が保存されておらず……(試行の履歴はあるけど順序が保存されてないのでそれぞれが何世代目のものなのかわからない→スコアの推移も調べられない)
・参考:もっとTPOTで自動機械学習を試した
仕方ないので標準出力から泥臭く情報を復元した結果が以下です。ちゃんと探索が進んでる感じ。
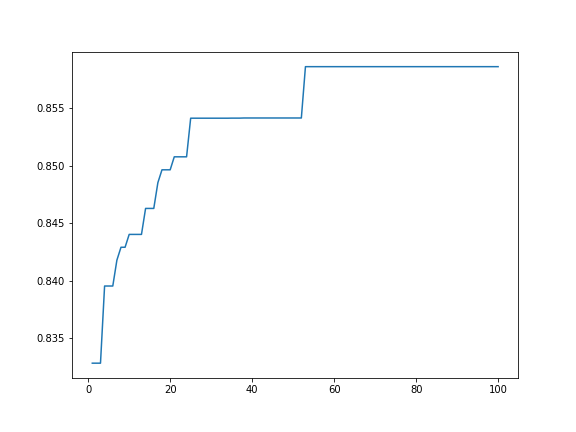
というわけで、TPOTの最適化により、AUCが0.832...→0.858...と改善しました!
Submitしてみる
こちらも、テストデータに対する予測を行ってsubmitしたスコア(accuracy)を見ます。
- デフォルトのパラメータを使ってxgboostのみで学習したモデルのスコア:0.799
- TPOTで最適化したモデルのスコア:0.770
こちらもちょっと悪化。
悪化度合いはOptunaの場合よりも大きいですが、TPOTはパイプラインを最適化する分、探索空間も大きくなるので、より過学習しやすいんでしょうか。
というかそもそもデフォルトのxgboostがだいぶ強い。
まとめ
いずれの場合も訓練データに過学習している感はありましたが、目的関数の最大化という意味ではうまく探索を進めている様子が確認できました。
- ベイズ最適化をしたいなら、Optunaをうまく使えば柔軟な設定で複雑な問題に対応できそう
- 遺伝的アルゴリズムを使いたいなら、
- 機械学習パイプラインの最適化という目的に限れば、TPOTは非常に手軽に扱えて便利
- 別の問題を扱いたいならDEAPを直接使おう