更新履歴
2019年1月18日:リンクが一部間違っていたのを修正しました。
この記事の目的
TPOTで自動機械学習(回帰)を試したという記事を書きました。
この時は簡単に使い方を確かめた程度だったのですが、いろいろ試すと、いろいろ便利な使い方が見つかりました。
前回は基本編ということで、今回は応用編をお届けします
(ほとんどはただ、オプション引数を使っただけですが)。
今回も基本的に、TPOTのHPを参考にしています。
環境
- Windows 10
- Python 3.7.2 (64bit)
- TPOT 0.9.5
データの準備
今回も回帰学習をしますので、またボストン住宅価格をDLしてきます。
そして、train_test_splitでトレーニングデータとテストデータを分けます。
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
housing = load_boston()
X_train, X_test, y_train, y_test = train_test_split(housing.data, housing.target,
train_size=0.75, test_size=0.25,
random_state=2018)
結果に再現性をもたせる
前回の記事で、推定の結果などを載せました。
しかしあれ、再現性がなく、実行するたびに結果が変わります。
再現性をもたせるためには、random_stateの引数を入れましょう。
from tpot import TPOTRegressor
tpot = TPOTRegressor(generations=5, population_size=50,
verbosity=2, n_jobs=-1, random_state=2018)
何度か実行するとわかりますが、同じ結果を返してくれます。
同じTransformを省略させる
機械学習では、Transformer -> Estimator というPipelineで解析をすることが多々あるかと思います。
- Transformer: PCAなどによりデータを変換(Transform)して、次元削減・特徴選択をする
- Estimator: SVMなどのモデルで、分類や回帰(Estimate)をする
TPOTはこれらの組み合わせをあれこれ試すわけです。
ここで例えば、PCA->SVR というPipelineを試したあと、PCA->LassoというPipelineを試すとします。
この場合、データにPCAをかけるという、まったく同じ計算を2回やることになります。
これは計算コスト的にもったいない。
そこで、データをTransformした結果を保存して、使いまわしてしまいましょう。
memory='auto'にするだけです。
tpot = TPOTRegressor(generations=5, population_size=50,
verbosity=2, random_state=2018, n_jobs=-1, memory='auto')
t0 = time.time()
tpot.fit(X_train, y_train)
print(time.time() - t0)
時間を比較したところ、デフォルトでは38秒かかったのに対し、
memory='auto'では39秒かかりました。
この程度の試行数では、むしろ遅くなるということでしょうか。
途中経過を随時保存する
前回の最後に紹介しましたが、TPOTにはPipelineを.pyファイルとして出力する機能があります。
このファイル出力を、一定間隔で行ってくれる設定があります。
periodic_checkpoint_folderという引数にディレクトリを設定します。
試しにproc_folderというフォルダを同じディレクトリに作り…
dire = 'proc_folder'
tpot = TPOTRegressor(generations=5, population_size=50,
verbosity=2, n_jobs=-1, random_state=2018, periodic_checkpoint_folder=dire)
t0 = time.time()
tpot.fit(X_train, y_train)
print(time.time() - t0)
…を走らせます。
すると、フォルダの中に.pyファイルが複数生成されます。
世代が進むたび(ただし経過時間が30秒未満の場合はスキップ)に.pyファイルを作ってくれているようです。
これを設定しておけば、途中でTPOTが死んだとしても結果を残せます。
一定処理ごとにTPOTを.pickleとして保存できたら色々便利だと思うのですが、今のところできないようです(参照)。
代替策として、こちらの引数を使ってくださいといったことを開発者が言っています。
前回の続きからFittingする
warm_start=Trueとすることで、一度.fit()をした後のインスタンスを、再度.fit()することができます。
この時、Fittingを前回の続きから行ってくれます。
これを使えば、
「とりあえず100世代回してみたけど、まだまだ改善できそうだからもう100世代!」
なんていうおかわりができます。
t0 = time.time()
tpot = TPOTRegressor(generations=5, population_size=50,
verbosity=2, n_jobs=-1, random_state=2018, warm_start=True)
tpot.fit(X_train, y_train)
print(time.time() - t0)
からの
t0 = time.time()
tpot.fit(X_train, y_train)
print(time.time() - t0)
で、合計10世代計算できます。
しかし、やはり合計時間はいっぺんに10世代やった方が早いようです。
各世代のCV scoreを出力する
verbosity=2にしていると、世代ごとのCV scoreを出力してくれます。
これをプロットできると、精度の改善が収束しているか一目でわかりますね。
しかしこのスコアを取得する方法がどーーしてもわかりません。
前回は、この出力をエクセルにコピペするというダッッッセェ方法でプロットしました。
これよりは若干スマートな方法でプロットしてみたのでご報告します。
出力を.txtへするようにする
Fittingをする前に、sys.stdoutを使って、出力を.txtファイルに行うようにします。
この記事を見ながらやりました。
import sys
sys.stdout = open('temp.txt', 'w')
で、いつもと同じように
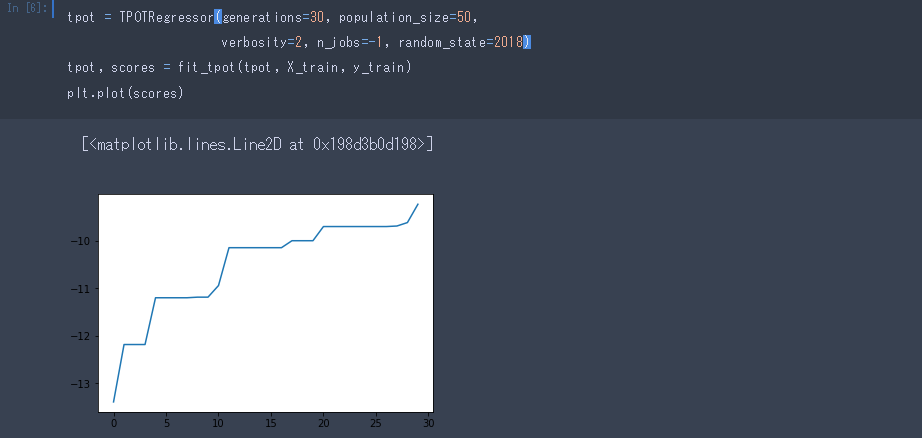
tpot = TPOTRegressor(generations=30, population_size=50,
verbosity=2, n_jobs=-1, random_state=2018)
tpot.fit(X_train, y_train)
そのあとは、
sys.stdout.close()
sys.stdout = sys.__stdout__
とします。
これで、通常画面に出力される内容が、temp.txtに吐き出されました。
ちなみに、tqdmによるプログレスバーは通常通り表示されるので安心です。
出力を.txtから読み取る
txt = open('temp.txt', 'r').read()
とすると、txtに.txtファイルの中身が、str型として入ります。
まず、/n/nで区切ってやりましょう。
outs = txt.split('\n\n')[1:-1]
このリストのうち、ひとつ目と最後を除きましょう。
その上でリストの各要素について、' 'でsplitして、最後の要素を取ってくればいいですね。
Pythonらしく、内包表記で。
scores = [float(out.split(' ')[-1]) for out in outs[1:-1]]
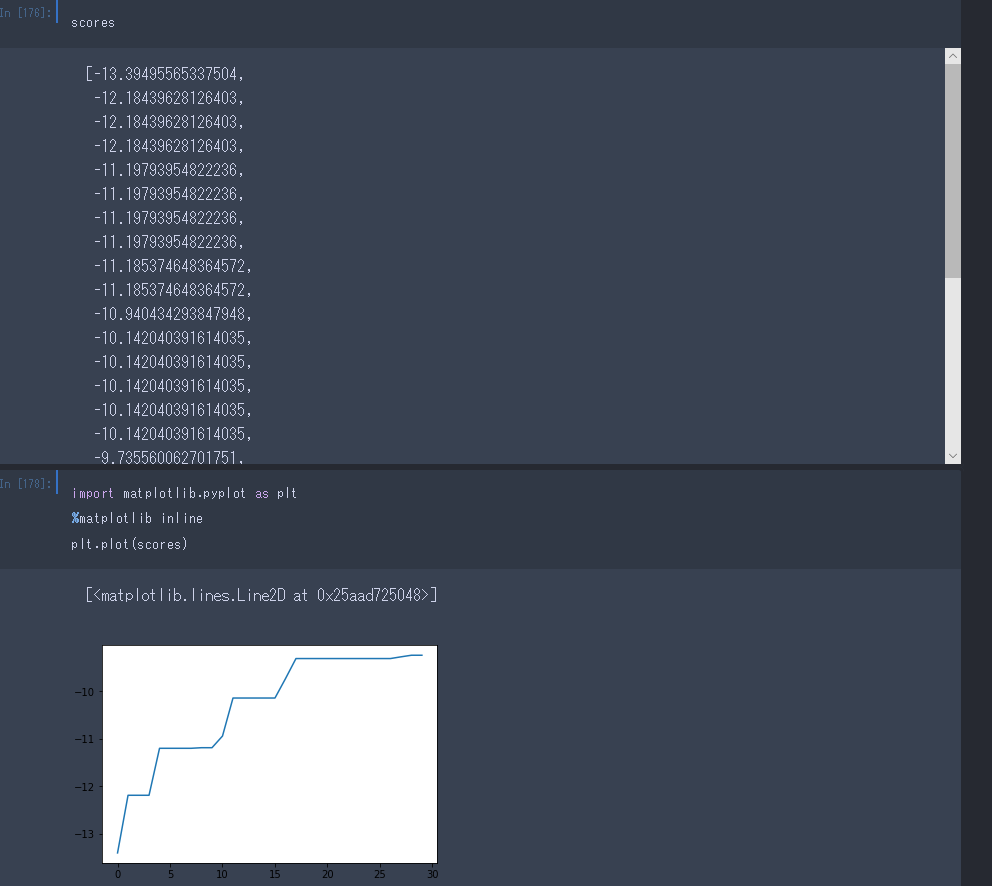
やったぁ!
後から使いやすいように、関数としてまとめておきます。
def fit_tpot(tpot, X_train, y_train):
import sys
sys.stdout = open('temp.txt', 'w')
tpot.fit(X_train, y_train)
sys.stdout.close()
sys.stdout = sys.__stdout__
outs = open('temp.txt', 'r').read().split('\n\n')
scores = [float(out.split(' ')[-1]) for out in outs[1:-1]]
return tpot, scores
こんな感じで使えます。
文字列からPipelineを生成
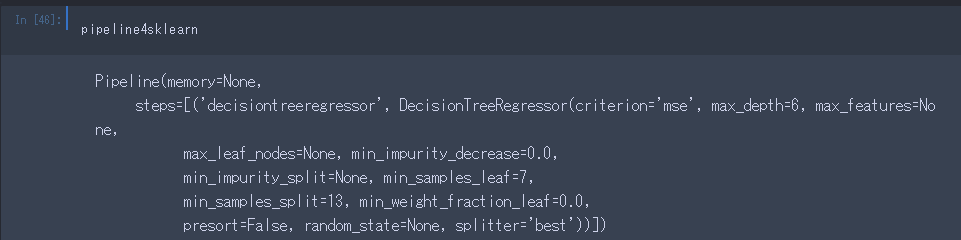
.evaluated_individuals_を使うことによって、検討されたPipelineの一覧を取得することができます。
このとき、Pipelineの内容は、文字列で取得されます。
これを、scikit-learnのPipelineオブジェクトに変換する方法がこちらで紹介されていました。
strs_pipeline = list(tpot.evaluated_individuals_.keys())
このようにすることで、使用したPipelineが文字列のリストとして手に入ります。
中身は、こんな感じです。

deap.creatorを使うことで、これを文字列に変換します。
from deap import creator
pipeline4deap = creator.Individual.from_string(strs_pipeline[1], tpot._pset)
pipeline4sklearn = tpot._toolbox.compile(expr=pipeline4deap)
自分のデータに適用する
自身の研究のデータにもTPOTを試しました。
詳細は省きますが、189の特徴と120のサンプルからなる、比較的スモールなデータです。
PCAからのSVR(linear)で試すと、テストデータでの精度はr=.49くらいでした。
これをTPOTにかけて、とりあえず100世代回しました。
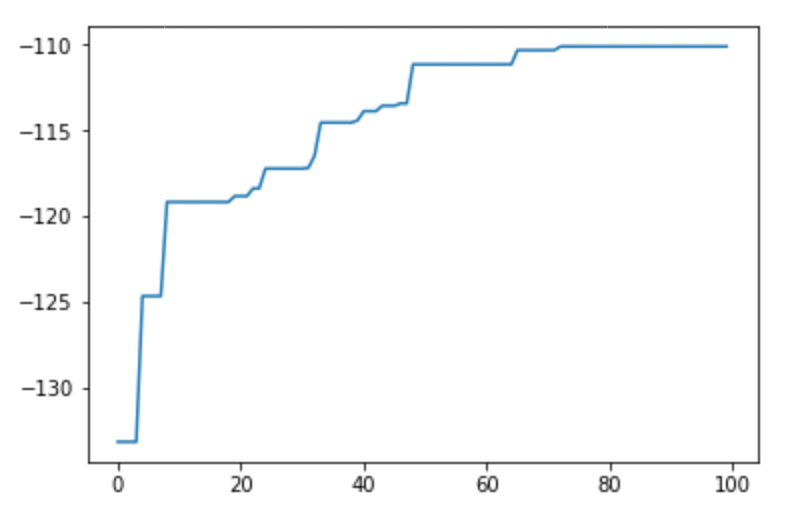
収束しているように見えますね。
しかしテストデータで精度をみてみると、r=.28と、イマイチな結果でした。
もう100世代ほど回します。
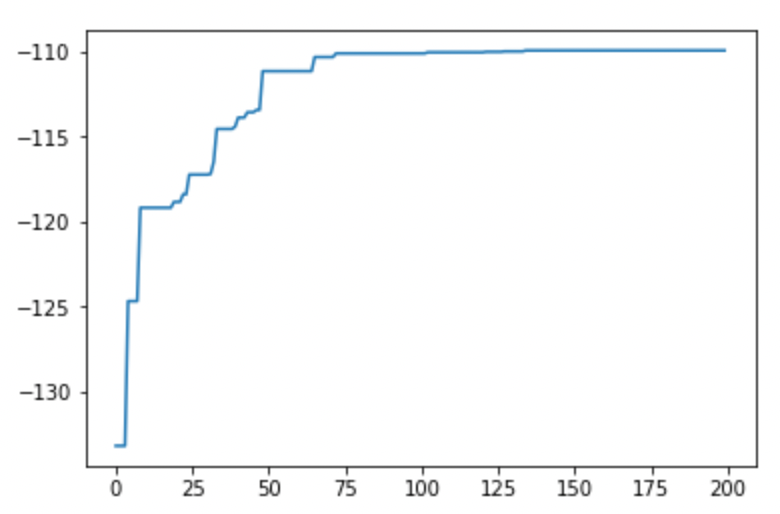
やはりこれ以上の改善は望めないか…
と思いきや、合計500世代回すと、
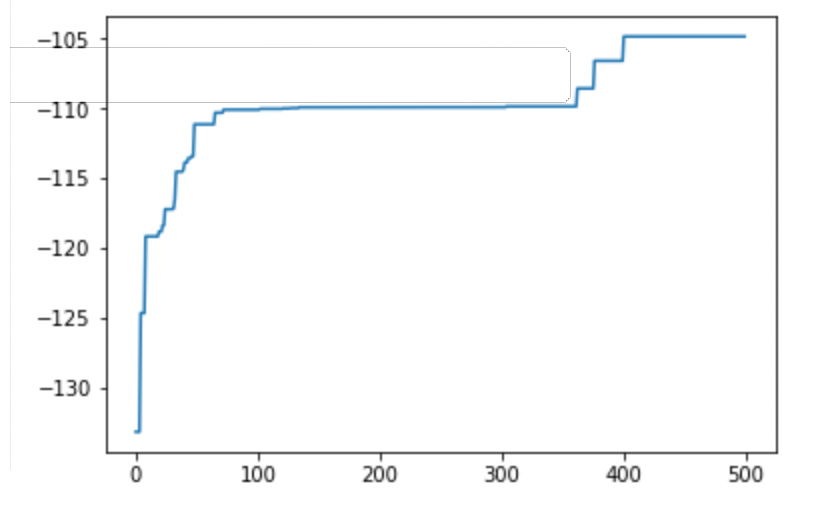
またぐんと精度が上がってます。
さらに、合計1,000世代回します。
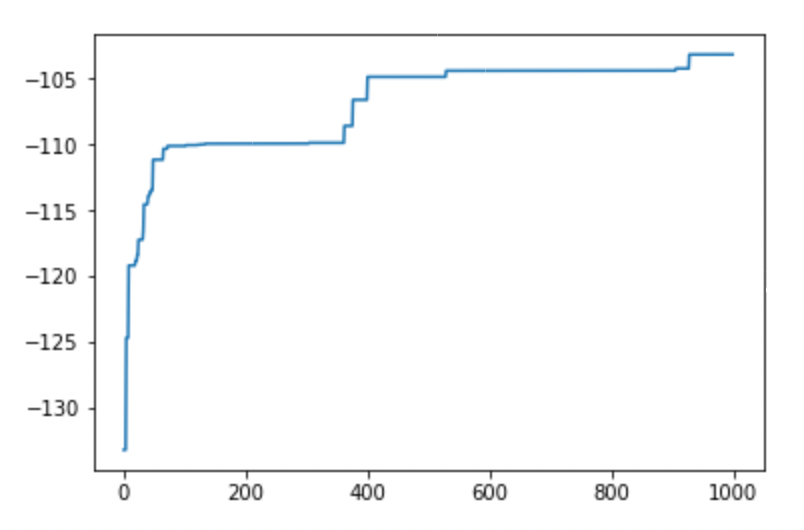
テストデータで精度検証すると、r=.447でした。
自身で組んだPipeline(PCA->SVR)に近い精度です。
もうしばらく回せば、もうちょっと良くなる気もします。
2,000世代やってみました。
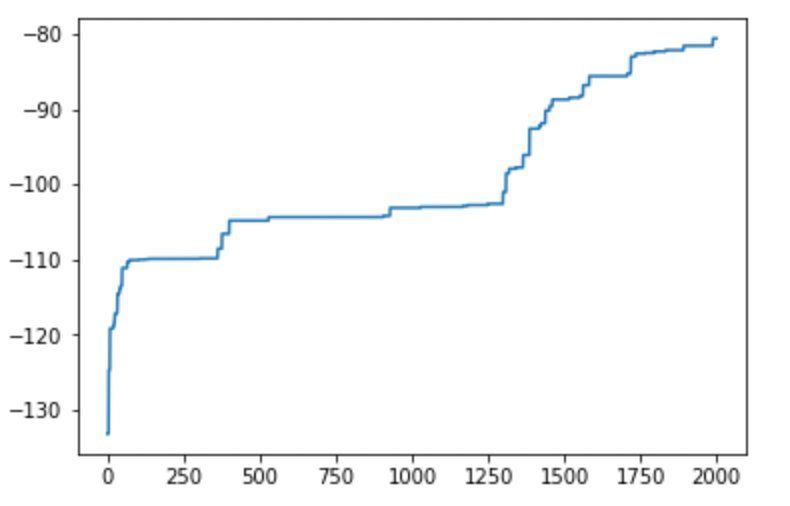
また大きく改善しました。
精度改善が収束するということは、そうそうないのかもしれません。
遺伝的プログラミングという仕組みを(よく知らないなりに)考えると、今回のように階段状に改善していくのが通常に思えます。
適応的な突然変異がたまたま起きたタイミングで精度が改善するわけですからね。
ちなみに、テストデータで精度検証すると、r=.378でした。
1,000世代のときよりも悪化しています。
過学習が生じているのでしょうか。
まとめ
100世代くらいの計算ならともかく、丸一日かけて演算するような使い方をするとなると、いろいろ工夫をしたくなりますね。
またなにかいい使い方が見つかったら、こちらの記事に追記します。
TPOTインスタンスをシリアライズして保存できれば、もっと便利な使い方ができそうです。
一定世代計算するごとに 中断→インスタンス保存→スコアプロット→再開 するとか。
まだまだ開発中のパッケージだそうですし、今後バージョンアップで対応してくれたりするかもしれません。