作ったもの
指定したユーザーのツイートから画像の自動収集自動分類を行うシステム
・ツイートの自動収集にはTwitterAPIのTweepyを使用
・画像の自動分類には深層学習(keras+tensorflow)を使用
・ユーザーIDの記録にはSQLite3を使用
ソースコードはGitHubに公開しています。
https://github.com/tf0101/img_autosearch
背景・動機
Twitter上の画像の保存と分類が面倒だったので作成(つまり、エロ画像だけ自動で保存したい)
機械学習を勉強していたのでDeepLearningを使って何か作ってみたかった
環境
Anconda3
python:3.6.7
Keras:2.2.4
tensorflow:1.12.0
システム概要図
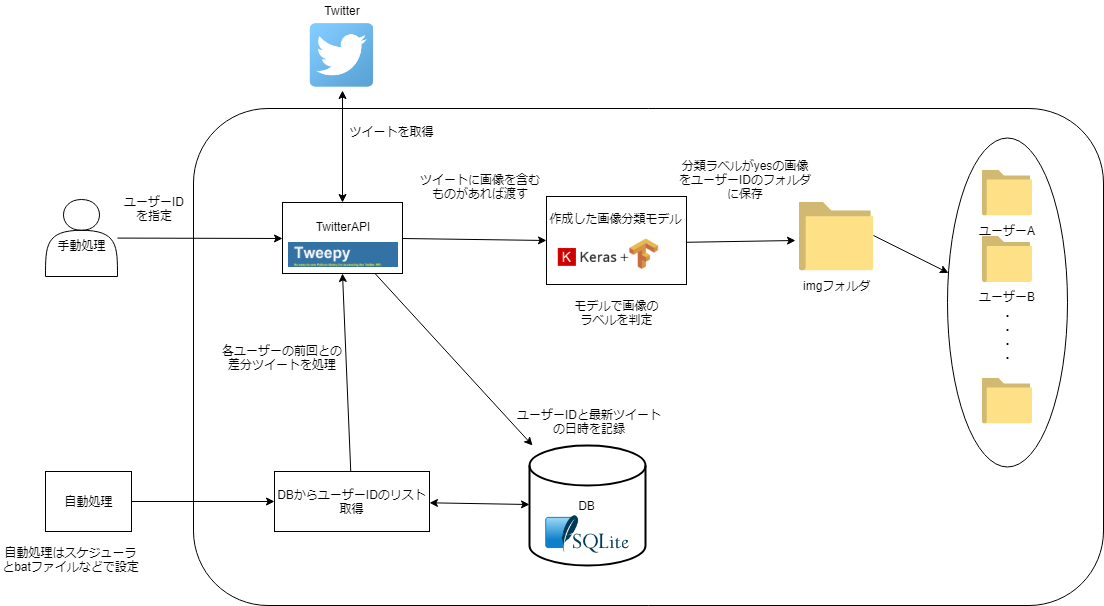
ツイートから画像を含むものを取得
API使用の準備
まずTwitterAPIを使用するのにトークンなどを取得する必要がある
以下のページを参考にしてキーとトークンを作成した
参考にしたサイト
ログイン時に使用するログインメソッドを作成、Consumer_key = ''、Consumer_secret = ''、Access_token = ''、Access_secret = ''に自身で取得したキーとトークンを入れる
import tweepy
import os
import time
# アクセスpathとトークン
Consumer_key = ''
Consumer_secret = ''
Access_token = ''
Access_secret = ''
# loginメソッド
def login(acount):
if acount=="自分のユーザーID":
auth = tweepy.OAuthHandler(Consumer_key, Consumer_secret)
auth.set_access_token(Access_token, Access_secret)
api = tweepy.API(auth)
return api
else:
exit()
ツイートから画像取得
APIはpythonで使えるtweepyを使用
以下のコマンドでインストール
pip install tweepy
tweepyのtimelineメソッドである api.user_timeline()では1ページにつき200ツイートしか取得できず、合計3200ツイート、つまり最初のページから16回しかページをめくれないのでそのページを数えるためリストを使う
コードが長いので重要な所だけ記載
pages=[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17]
api=login.login("自分のユーザーID")#login.pyで作成したログインメソッドを使用してログイン
#画像を含むツイート取得するループ
for page in pages:
#Accountは検索するユーザID、countは1ページあたり取得するツイートの数(最大200)、pageはページの番号
tweets=api.user_timeline(Account, count=200, page=page)
for tweet in tweet:
try:
#画像のurl取得
url=tweet.extended_entities['media'][0]['media_url']
extended_entitiesの構造
media keyのなかに要素が1のlistがあって、そのなかにmedia_urlのkeyがある
extended_entities={
'media':{
[
'media_url' :'http://pbs.twimg.com/media/hogehoge.jpg'
]
}
}
画像分類モデルの作成
モデル作成にはkerasを使用した、バックエンドはtensorflow、GPU搭載PCを持っていなかったのでAWSのDeep Learning AMI (Ubuntu)のp2.xlargeを使用、理由は料金設定が一番安いから
以下の記事を参考にインスタンスを作成した
参考にした記事
モデル作成の手法
VGG16をFine-tuningして目的の画像か否かを分類できる2クラス分類のニューラルネットワークを学習した
VGG16というのはImageNetと呼ばれる大規模画像データセットで学習された,16層からなるCNNモデル
Fine-tuningというのは既存のモデルの一部を再利用して、新しいモデルを構築する手法
Fine-tuningはニューラルネットワークが学習する時に、入力に近い層では点や線のような単純な模様を学習し、出力に近い層で複雑な模様を学習する性質を利用している。
つまり、入力に近い層は単純な内容を学習しているのでここは学習させず、出力に近い層のみ学習させることで、少ない学習データで早く学習が完了し精度が出せる。
学習データ
目的の画像か否かの(yes,no)の2クラスのデータを用意した。主にgoogle_images_downloadで収集
・(yesラベル)イラストとか目的の画像
・(noラベル)それ以外の画像
yesラベルで学習したのはイラストなど(つまりエロ画像)
noラベルで学習したのはその他ツイートとして想定される画像(料理とか風景とかイラストのラフ画とか、とにかく目的じゃない画像全般)
それぞれ訓練用と検証用に分けてフォルダ作成
訓練用データ(train)にyes,noそれぞれ450枚ずつ
検証データ(validation)にyes,noそれぞれ60枚ずつ
以下にディレクトリ構造図を示す。以下のdeepフォルダを作成したAWSのp2インスタンスに転送し実行してモデルを作成した。
deep
├── yes_no.py
└── img
├── train
│ ├── yes
│ └── no
└── validation
├── yes
└── no
コード
VGG16モデルと構築したFC層を繋げて学習を行う
import keras
from PIL import Image, ImageFilter
from keras.utils import Sequence
from keras.models import Model
from keras.layers import Dense, GlobalAveragePooling2D,Input
from keras.layers.core import Dropout
from keras.applications.vgg16 import VGG16
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import SGD
from keras.callbacks import CSVLogger
from keras.models import model_from_json
n_categories=2#クラス数、yes,noの2クラスなので2
batch_size=32
train_dir='img/train'
validation_dir='img/validation'
file_name='yes_no'
# VGG16imagenet
base_model=VGG16(weights='imagenet',include_top=False,
input_tensor=Input(shape=(224,224,3)))
# FC層
x=base_model.output
x=GlobalAveragePooling2D()(x)
x=Dense(1024,activation='relu')(x)
# 過学習を防ぐ為にDropout
x=Dropout(0.5)(x)
# 複数クラスの場合はsoftmax、今回は2クラスなのでsigmoid
prediction=Dense(n_categories,activation='sigmoid')(x)
model=Model(inputs=base_model.input,outputs=prediction)
# 最後の畳み込み層より前の層の再学習を防止
for layer in base_model.layers[:15]:
layer.trainable=False
# Fine-tuningをする場合の最適化関数は学習率を抑えたSGDを使用
model.compile(optimizer=SGD(lr=0.0001,momentum=0.9),
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()#CNNの層を出力
# 画像の前処理
train_datagen=ImageDataGenerator(
rescale=1.0/255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
validation_datagen=ImageDataGenerator(rescale=1.0/255)
train_generator=train_datagen.flow_from_directory(
train_dir,
target_size=(224,224),
batch_size=batch_size,
class_mode='categorical',
shuffle=True)
validation_generator=validation_datagen.flow_from_directory(
validation_dir,
target_size=(224,224),
batch_size=batch_size,
class_mode='categorical',
shuffle=True)
hist=model.fit_generator(train_generator,
steps_per_epoch= 900 // batch_size,
epochs=150,
verbose=1,
validation_data=validation_generator,
validation_steps= 120 // batch_size,
callbacks=[CSVLogger(file_name+'.csv')])
# モデル保存
json_string = model.to_json()
open(file_name+'.json', 'w').write(json_string)
model.save_weights(file_name+'.h5')
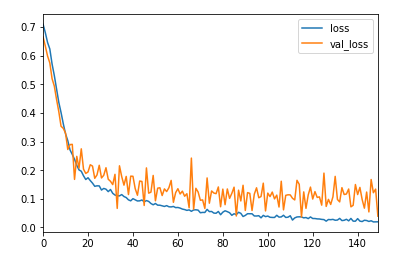
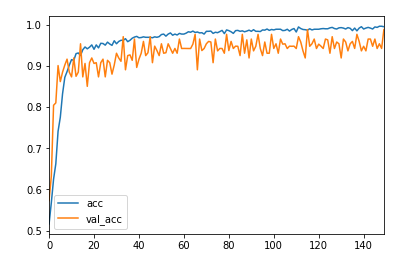
学習結果
yes、noの2クラス分類なことに加えてファインチューニングをしたので精度は出ている、損失関数が横這い状態なのでエポック数はもう少し減らしていいかもしれない
実際にユーザーIDを指定して試してみる、(第三者の画像なのでモザイクをかけています)
yesラベルで取れた画像↓

noラベルで取れた画像↓

他にもいくつかのユーザーIDで試したが、狙い通りイラストのラフ画などをnoに分類できていたのでまずまずだと思う
モデルのロードとラベル判定
from keras.preprocessing import image
import numpy as np
import sys
from PIL import Image
from keras.models import model_from_json
class Model:
#コンストラクタでモデルのロードを行う
def __init__(self):
#モデルファイル名
model_filename='yes_no'
#分類するクラス
self.classes = ['no','yes']
# モデルロード
self.model = model_from_json(open(model_filename+'.json').read())
self.model.load_weights(model_filename+'.h5')
#取得画像を前処理し、読み込んだモデルでラベル(yes or no)を予測し返すメソッド
def modellabel(self,filename):
#入力画像の前処理
img = image.load_img(filename, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
#学習時に正規化してるので、ここでも正規化
x = x / 255
#predict:入力サンプルに対する予測値の出力生成
pred = self.model.predict(x)[0]
#画像のラベルを返す
top = 1
top_indices = pred.argsort()[-top:][::-1]
result = [(self.classes[i], pred[i]) for i in top_indices]
print(filename+':====>'+result[0][0])
return result[0][0]
プログラム一覧
長いのでGitHubにまとめました GitHub
img 画像が保存されるフォルダ
auto.py ログインとかツイートの読み込みとか
db.py データベース全般の処理
login.py ログイン全般の処理
main.py 実行ファイル
model.py 分類モデルのロードとラベル判定
startauto.bat 自動処理を行う時に使うbatファイル
yes_no.csv 分類モデルのlossとaccデータ(分類モデルの精度確認のためのファイル)
yes_no.h5 分類モデルのデータ
yes.no.json 分類モデルのデータ
img_auto_search_end
├── img
├── auto.py
├── db.py
├── login.py
├── main.py
├── model.py
├── startauto.bat
├── yes_no.csv
├── yes_no.h5
└── yes_no.json
手動処理、自動処理
・手動処理
指定したユーザーの画像を集めたい場合は実行時にコマンドライン引数としてmanualを指定する、その後、画像を集めたいユーザーのIDを入力
python main.py manual
・自動処理
手動処理で記録したDB内のユーザーリストの前回との差分ツイートのみ処理する。batファイルとタスクスケジューラ―などを用いて日時を設定すれば自動で実行できる、こっちはbatファイルから起動することを想定している
コマンドライン引数としてautoを指定している
python main.py auto
デモ
こんな感じでラベルがyesの画像がフォルダに保存されていく(ユーザーIDにはモザイクをかけています)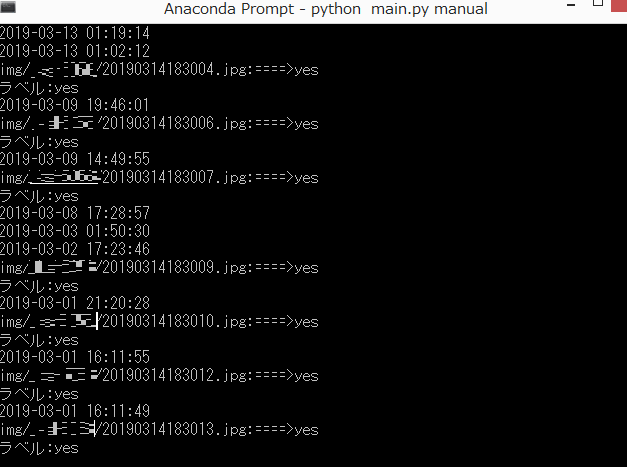
追記
学習データを精査すればもっと自分の趣味趣向にあった分類モデルが作成できるかも
参考文献
tweepyでTwitterの画像検索
python3のrequestsを使って画像を保存
TweepyでTwitterの特定のユーザから3200ツイートの取得
Googleから画像を一括でダウンロードできるコマンドラインツール「google-images-download」
kerasドキュメント
Keras(Tensorflow)の学習済みモデルのFine-tuningで少ない画像からごちうさのキャラクターを分類する分類モデルを作成する
VGG16を転移学習させて「まどか☆マギカ」のキャラを見分ける
少ない画像から画像分類を学習させる方法(kerasで転移学習:fine tuning)
VGG16のFine-tuningによる17種類の花の分類