ターゲット
機械学習、ディープラーニングに興味を持ち、チュートリアル通りにMNISTを動かしてみて機械学習の入り口に立ってみたものの、さて次は何をしようか?という方。
CNNを使った画像認識を勉強したものの、自分のローカル環境(CPU)では待てど暮らせど学習が進まない、ディープラーニングにはどうやらGPUなるものが必要らしい。という方。
ディープラーニングを勉強するためにわざわざGPU環境を構築するのは如何なものか。クラウドで手軽にテストをしてみたい。という方。
自分でGPU環境を構築すると、学習を始めるまでに必要な環境構築にうんざりしてしまうのですが、ディープラーニングに必要な環境がプリインストールされた、AWSのAMI(Amazon マシンイメージ)を使うことでとても簡単にGPUを使った学習を行うことができます。
プロセス
- AWSのアカウントを作る
- インスタンスを作成する
- インスタンスに接続する
- kerasを使ったMNISTのサンプルファイルを動かしてみる
- インスタンスを削除する
今回はクラウド環境でGPUを使った機械学習を行うという目的にフォーカスし、機械学習の理論や各フレームワーク、ツールの説明は省きます。
AWSのアカウントを作る
https://aws.amazon.com/jp/register-flow/
まずはAWSのアカウントが必要です。こちらのページの手順に沿って行えば特に問題はありません。アカウント作成の際、クレジットカード情報の登録が必要になります。
リージョンは「米国東部 (バージニア北部)」を選択しましょう。

インスタンスを作成する
アカウントを作成し、無事コンソール画面にログインできたら、画面左上「サービス」からコンピューティング > EC2を選択します。
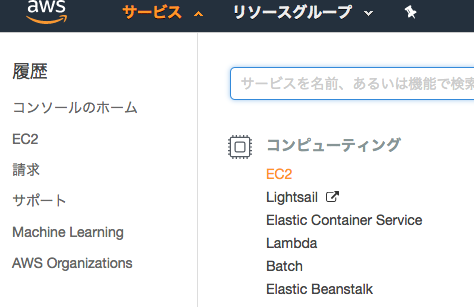
EC2ダッシュボードに移動したら、「インスタンスの作成」ボタンをクリックします。

ステップ1:AMI(Amazon マシンイメージ)の選択
たくさんのAMIが表示されます。この中から「Deep Learning AMI (Ubuntu)」を選択しましょう。

ステップ 2: インスタンスタイプの選択
次はインスタンスタイプの選択です。利用用途に応じて様々なインスタンスが用意されています。
今回は「p2.xlarge」を選択します。
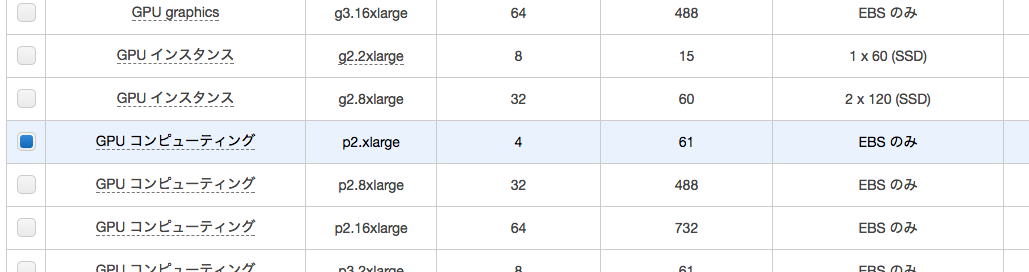
ステップ3以降は今回特に設定の必要はありませんので、右下の「作成」ボタンをクリックします。
キーペアの作成
以下のようなポップアップが表示されますので、キーペアを作成、または既存のキーペアを作成します。
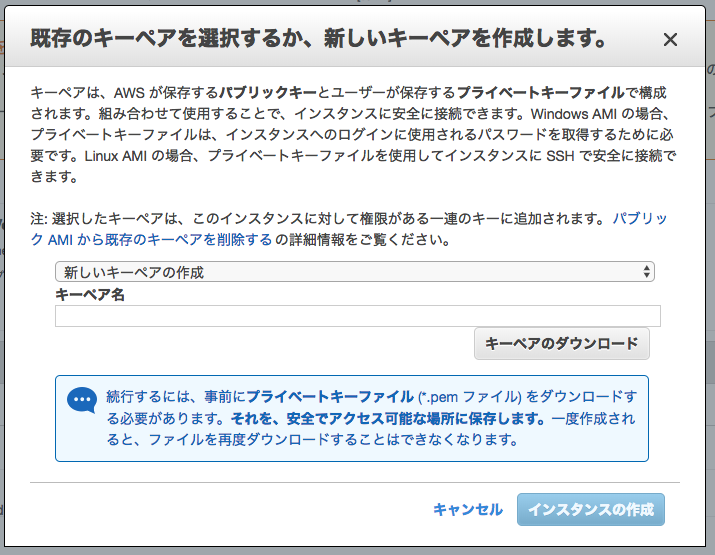
キーペアを設定したら、「キーペアのダウンロード」をクリックして.pemファイルをダウンロードし、ローカル環境に保存しましょう。こちらのファイルは後ほどインスタンスに接続する際に必要となります。
以上が終了したら「インスタンスの作成」をクリックします。
しばらく待つと以下の画面が表示されます。
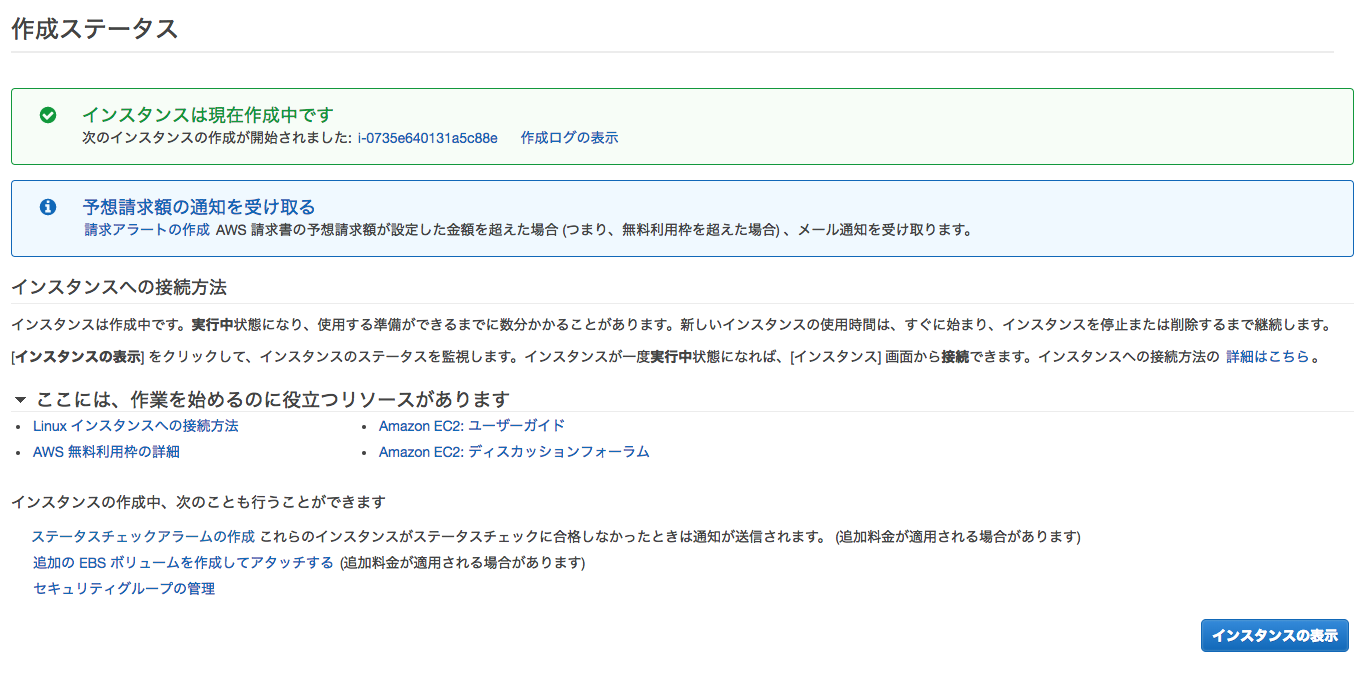
インスタンス作成時にエラーが出た時
私の環境ではインスタンス作成時に以下のエラーが出ました。
You have requested more instances (1) than your current instance limit of 0 allows for the specified instance type. Please visit http://aws.amazon.com/contact-us/ec2-request to request an adjustment to this limit.
現在のインスタンス数上限が0とのこと。メッセージに従い、http://aws.amazon.com/contact-us/ec2-requestから以下のようにリクエストを送りました。
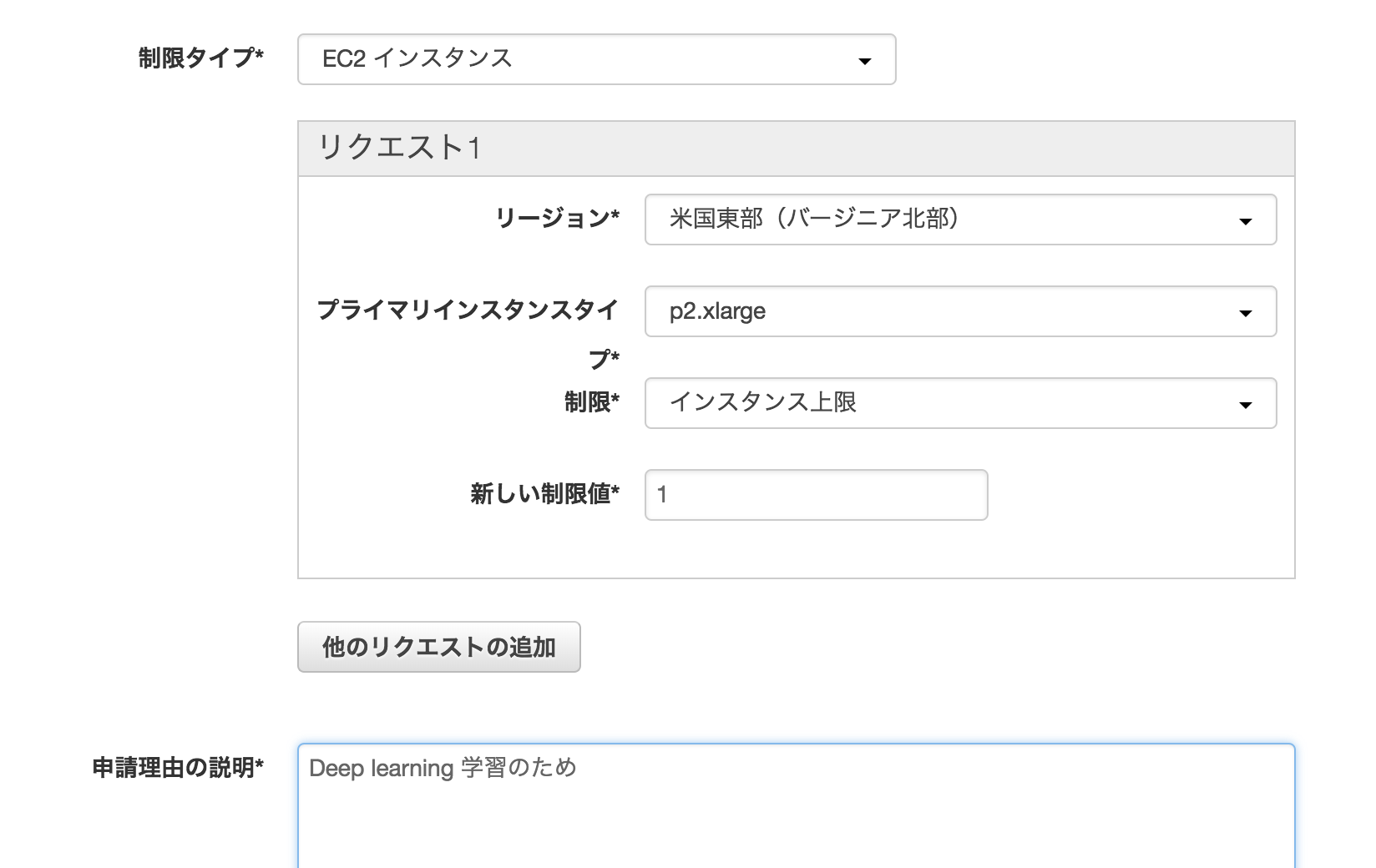
私の場合、30分ほどでリクエストを承認していただき、その後無事にインスタンスを作成することができるようになりました。
インスタンスへの接続
インスタンスが作成できたら、画面右下の「インスタンスの表示」をクリックします。
インスタンスが表示されたら、先ほど作成したインスタンスを選択し、「接続」をクリックしましょう。
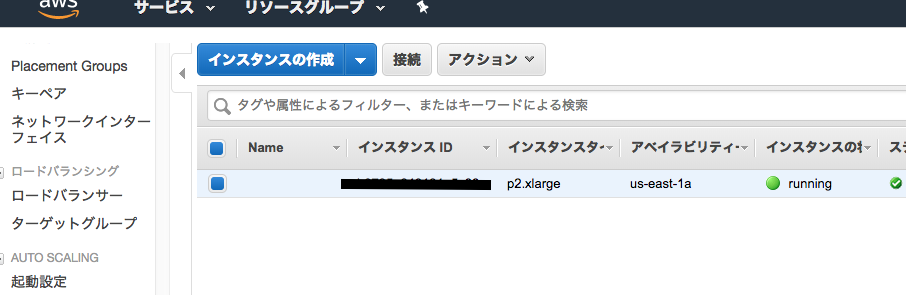
すると以下のポップアップが表示されます。
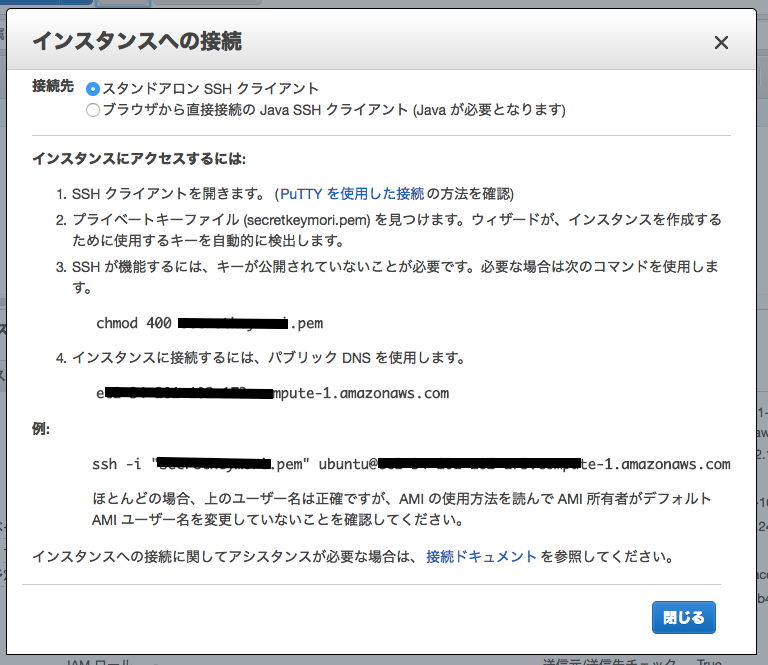
こちらに従い、インスタンスに接続します。
pemファイル アクセス権限の変更
ターミナルを開き、先ほどダウンロードした.pemファイルの権限を変更します。
$ chmod 400 ファイル名.pem
インスタンスに接続
以下のコマンドでインスタンスに接続します。
$ ssh -i [.pemファイルの場所].pem ubuntu@[パブリックDNS]
例:$ ssh -i pemkey.pem ubuntu@ec2-12-345-678-910.compute-1.amazonaws.com
接続途中でAre you sure you want to continue connecting (yes/no)?と表示されたらyesと入力しましょう。
ターミナルのプロンプト表記がubuntu@ip-123-45-67-890:~$のようになれば接続成功です。
kerasのサンプルコードを試してみる
Deep Learning AMIでは様々なディープラーニング環境があらかじめ用意されています。
Please use one of the following commands to start the required environment with the framework of your choice:
for MXNet(+Keras1) with Python3 (CUDA 9) _____________________ source activate mxnet_p36
for MXNet(+Keras1) with Python2 (CUDA 9) _____________________ source activate mxnet_p27
for TensorFlow(+Keras2) with Python3 (CUDA 8) ________________ source activate tensorflow_p36
for TensorFlow(+Keras2) with Python2 (CUDA 8) ________________ source activate tensorflow_p27
for Theano(+Keras2) with Python3 (CUDA 9) ____________________ source activate theano_p36
for Theano(+Keras2) with Python2 (CUDA 9) ____________________ source activate theano_p27
for PyTorch with Python3 (CUDA 9) ____________________________ source activate pytorch_p36
for PyTorch with Python2 (CUDA 9) ____________________________ source activate pytorch_p27
for CNTK(+Keras2) with Python3 (CUDA 8) ______________________ source activate cntk_p36
for CNTK(+Keras2) with Python2 (CUDA 8) ______________________ source activate cntk_p27
for Caffe2 with Python2 (CUDA 9) _____________________________ source activate caffe2_p27
for Caffe with Python2 (CUDA 8) ______________________________ source activate caffe_p27
for Caffe with Python3 (CUDA 8) ______________________________ source activate caffe_p35
for base Python2 (CUDA 9) ____________________________________ source activate python2
for base Python3 (CUDA 9) ____________________________________ source activate python3
今回はTensorFlow(+Keras2) with Python3を使用して、kerasのサンプルコードを動かしてみましょう。
環境を有効化する
以下コマンドを入力して、仮想環境を有効化します。
$ source activate tensorflow_p36
すると、ターミナルのプロンプト表記が(tensorflow_p36) ubuntu@ip-123-45-67-890:~$のように変わります。
サンプルコードをダウンロードする
今回はこちらのサンプルコードを使用させていただきます。
git cloneを使用してダウンドロードします。
$ git clone https://github.com/keras-team/keras.git
ダウンロードが成功したら、サンプルコードのディレクトリに移動します。
$ cd keras/examples/
サンプルファイルで学習してみる
examplesディレクトリにはたくさんのサンプルファイルがありますが、今回はおなじみのMNISTmnist_cnn.pyを使用します。
(tensorflow_p36) ubuntu@ip-123-45-67-890:~/keras/examples$ ls
addition_rnn.py conv_lstm.py lstm_seq2seq_restore.py mnist_mlp.py pretrained_word_embeddings.py
antirectifier.py deep_dream.py lstm_stateful.py mnist_net2net.py README.md
babi_memnn.py image_ocr.py lstm_text_generation.py mnist_siamese.py reuters_mlp.py
babi_rnn.py imdb_bidirectional_lstm.py mnist_acgan.py mnist_sklearn_wrapper.py reuters_mlp_relu_vs_selu.py
cifar10_cnn_capsule.py imdb_cnn_lstm.py mnist_cnn.py mnist_swwae.py variational_autoencoder_deconv.py
cifar10_cnn.py imdb_cnn.py mnist_dataset_api.py mnist_tfrecord.py variational_autoencoder.py
cifar10_cnn_tfaugment2d.py imdb_fasttext.py mnist_denoising_autoencoder.py mnist_transfer_cnn.py
cifar10_resnet.py imdb_lstm.py mnist_hierarchical_rnn.py neural_doodle.py
conv_filter_visualization.py lstm_seq2seq.py mnist_irnn.py neural_style_transfer.py
以下のコマンドで学習を開始します。
$ python3 mnist_cnn.py
動いた!速い!どうやらTesla K80というGPUが動いているようです。
60000 train samples
10000 test samples
Train on 60000 samples, validate on 10000 samples
Epoch 1/12
I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:895] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1105] Found device 0 with properties:
name: Tesla K80 major: 3 minor: 7 memoryClockRate(GHz): 0.8235
pciBusID: 0000:00:1e.0
totalMemory: 11.17GiB freeMemory: 11.10GiB
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1195] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: Tesla K80, pci bus id: 0000:00:1e.0, compute capability: 3.7)
60000/60000 [==============================] - 11s 188us/step - loss: 0.2583 - acc: 0.9198 - val_loss: 0.0633 - val_acc: 0.9790
Epoch 2/12
60000/60000 [==============================] - 10s 160us/step - loss: 0.0882 - acc: 0.9744 - val_loss: 0.0396 - val_acc: 0.9878
Epoch 3/12
60000/60000 [==============================] - 10s 160us/step - loss: 0.0662 - acc: 0.9806 - val_loss: 0.0352 - val_acc: 0.9877
Epoch 4/12
60000/60000 [==============================] - 10s 160us/step - loss: 0.0530 - acc: 0.9843 - val_loss: 0.0295 - val_acc: 0.9901
Epoch 5/12
60000/60000 [==============================] - 10s 160us/step - loss: 0.0461 - acc: 0.9857 - val_loss: 0.0316 - val_acc: 0.9897
Epoch 6/12
60000/60000 [==============================] - 10s 160us/step - loss: 0.0409 - acc: 0.9871 - val_loss: 0.0289 - val_acc: 0.9911
Epoch 7/12
60000/60000 [==============================] - 10s 159us/step - loss: 0.0353 - acc: 0.9894 - val_loss: 0.0299 - val_acc: 0.9904
Epoch 8/12
60000/60000 [==============================] - 10s 160us/step - loss: 0.0343 - acc: 0.9894 - val_loss: 0.0272 - val_acc: 0.9915
Epoch 9/12
60000/60000 [==============================] - 10s 160us/step - loss: 0.0315 - acc: 0.9906 - val_loss: 0.0311 - val_acc: 0.9903
Epoch 10/12
60000/60000 [==============================] - 10s 160us/step - loss: 0.0298 - acc: 0.9906 - val_loss: 0.0282 - val_acc: 0.9918
Epoch 11/12
60000/60000 [==============================] - 10s 160us/step - loss: 0.0270 - acc: 0.9917 - val_loss: 0.0266 - val_acc: 0.9918
Epoch 12/12
60000/60000 [==============================] - 10s 160us/step - loss: 0.0264 - acc: 0.9920 - val_loss: 0.0284 - val_acc: 0.9916
Test loss: 0.028353183139187194
Test accuracy: 0.9916
約2分ほどで学習が完了しました。私のローカル環境(CPU)で同じファイルを動かしたところ、1エポックあたり3〜4分、終了までに30分以上かかりましたのでその差は歴然です。
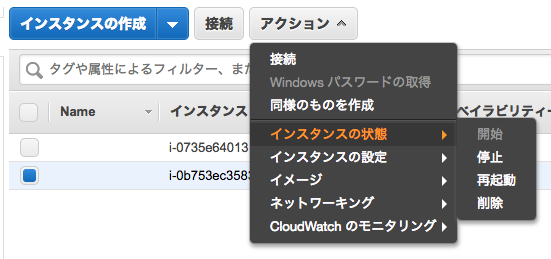
インスタンスを削除する
作成したインスタンスをそのままにしておくと料金が発生するため、EC2のダッシュボードから該当のインスタンスを削除します。
最後に
様々な工程をすっ飛ばして、AWSでGPUを使った機械学習を実装しました。GPUを使うとやっぱり速いんだな〜と感じていただくことができれば幸いです。