はじめに
私は現在大学で機械学習を用いて医療データの分析を行っています.
しかし,分析対象が表形式データであるため,深層学習に触れたことはありませんでした.
さすがに今どき深層学習に全く触れたことがないのはまずいと思い,春休み期間を利用して勉強してみました.
今回は勉強内容のアウトプットとして深層学習の定番(?)である顔分類に挑戦してみました.
分類対象は私の大好きなウマ娘です!(ちなみに一番好きなウマ娘はシンボリルドルフです)
顔画像の分類に使用するCNNモデルはPytorchを利用して構築し,アプリケーション部分はStreamlitを利用して作成しました.
実際に使用したソースコードはコチラ(アプリケーションの実行方法等の記載もあります)![]()
アプリケーション実行例
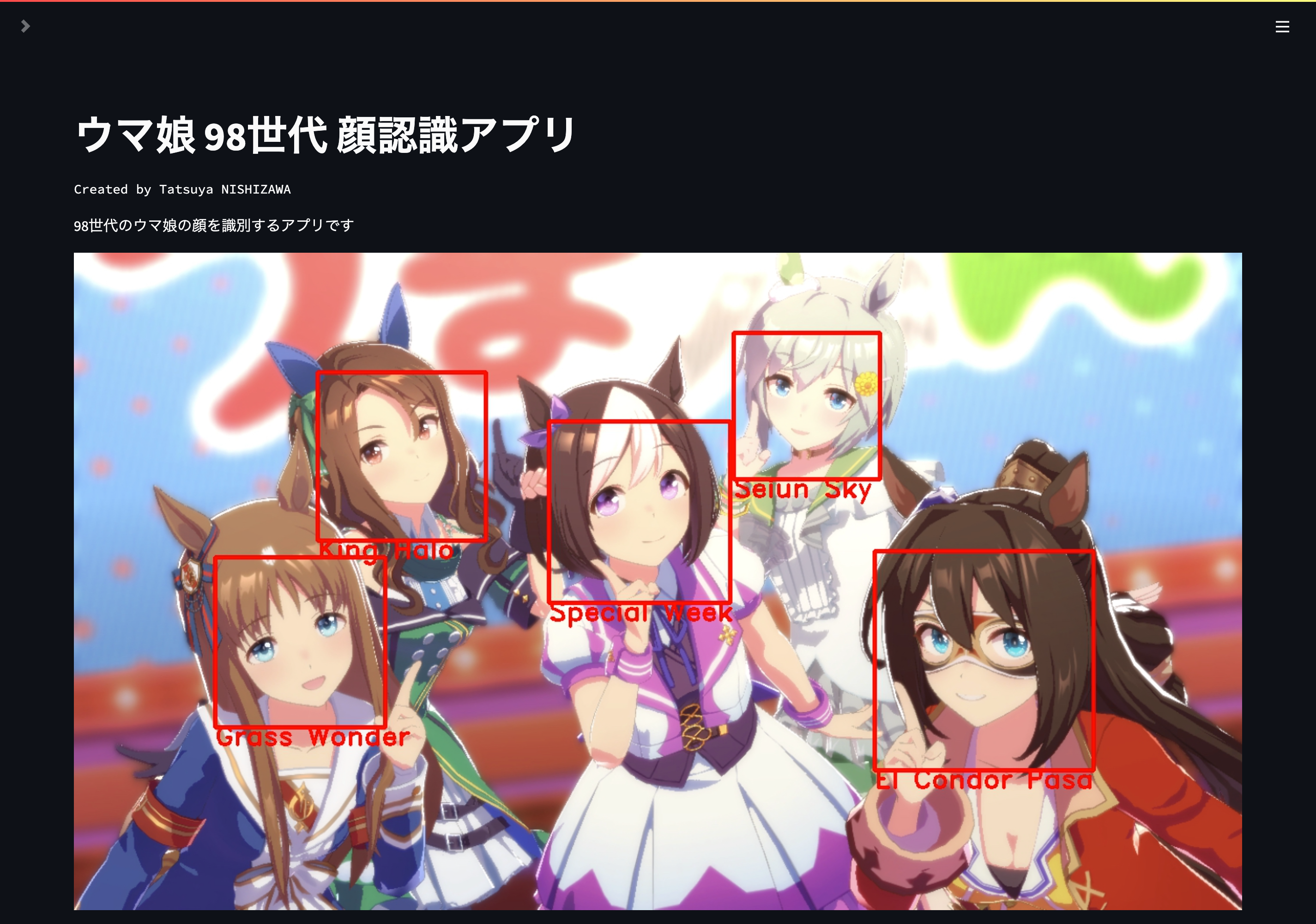
下図のようにウマ娘の画像を読み込むと,顔を四角枠で囲み,対応するウマ娘の名前を表示します.
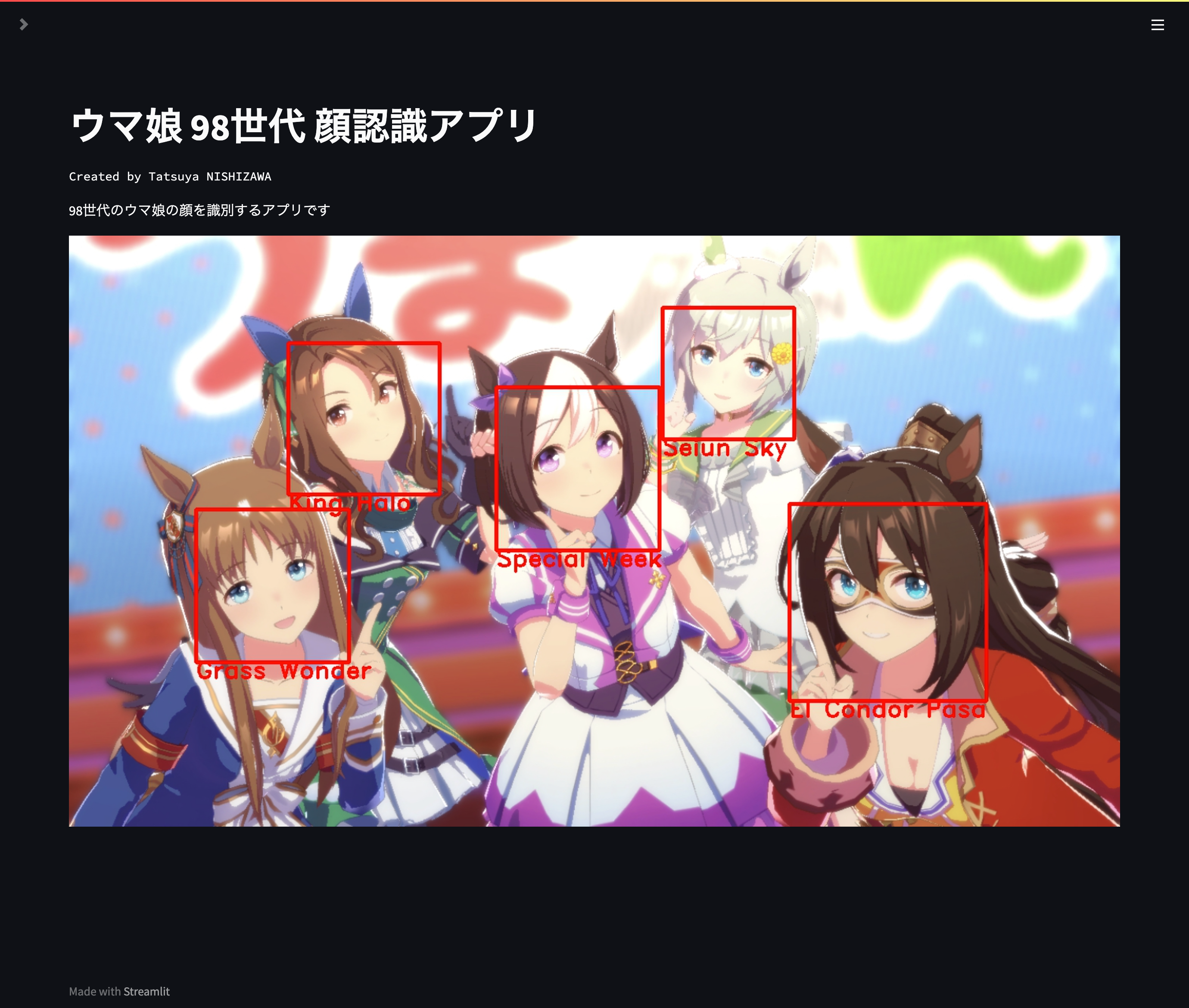
今回は初めてだったので,ちょうど5人でキリが良い98世代のウマ娘(スペシャルウィーク,セイウンスカイ,キングヘイロー,エルコンドルパサー,グラスワンダー)に絞って分類を行うアプリケーションとしました.
環境
アプリケーション部分(自分のマシン上で動かす部分)
- Python 3.8.3
- numpy 1.21.4
- opencv-python 4.5.5.64
- Pillow 7.2.0
- torch 1.9.0
- torchvision 0.11.3
- streamlit 1.5.1
顔画像の収集やCNNモデルの構築はGoogle Colaboratory上で行いました.(特に後者はGPUが必須なため)
Google ColaboratoryではPytorchを含む主要なライブラリを最初から利用できるため,非常に便利です.また,深層学習にはGPUが必須ですが,なんとGoogle Colaboratoryでは無料でGPUを利用できます!(ただし,使用量に制限あり.ただ個人開発規模であれば全然問題ないレベルだと思います.)
そのため,GPUが搭載されていないPCでも手軽に深層学習を行うことができます.
作成の手順
- 顔画像を集める
- ウマ娘ごとに顔画像を振り分け
- 顔画像を訓練データとテストデータに分割
- 訓練データの水増し
- データローダの作成
- モデルの学習・評価・保存
- アプリケーション部分の作成
1つずつ順を追って説明していきます.
1. 顔画像を集める
まず,モデルの学習に使用するための顔画像を集めます.
ウマ娘の顔画像を集める方法として,以下の記事が大変参考になりました.
ウマ娘のゲームアプリでは,ライブシアターという機能でウマ娘を指定してウイニングライブを見ることができます.ウイニングライブは3人や5人など少人数をフォーカスして映すため,今回のように特定のウマ娘の画像を集めるにはもってこいでした.
ちなみに,ライブシアター機能で指定できるのは所持している(ガチャで当てた)ウマ娘のみです.今回の場合,スペシャルウィークとセイウンスカイはレア度が高く中々当たらないので注意してください!(私もセイウンスカイはキャラ引換券でやっと手に入りました)
ウマ娘のポジションや曲を変更しながら6つのライブアニメーションをiPhoneの画面収録機能を用いて録画し,Googleドライブ上に保存します.
次に録画した動画から顔画像の切り抜きを行います.顔画像の切り抜きにはカスケード分類器を使用します.
今回はアニメ顔なので,以下のアニメ顔検出用の分類器を使用していきます.
まず,Google ColaboratoryでGoogleドライブにアクセスできるようにします.
#Googleドライブにアクセスできるようにする
from google.colab import drive
drive.mount("/content/drive")
上記のコードをGoogle Colaboratoryで実行することにより,自身のGoogleドライブにアクセスできるようになります.これにより,Googleドライブ上に保存したファイルにアクセスしたり,逆に生成したファイルをGoogleドライブ上に保存したりすることが可能になります.
Googleドライブ上の作業フォルダに移動します.
% cd /content/drive/MyDrive/UmaMusume_detection
今回はGoogleドライブ上にUmaMusume_detectionというフォルダを作成しています.
このフォルダの中身は以下のようになっています.先ほどのライブアニメーションはimgフォルダに保存してあります.
.
├── faces
│ ├── elcondorpasa
│ ├── grasswonder
│ ├── kinghalo
│ ├── seiunsky
│ └── specialweek
├── img
├── test_data
│ ├── elcondorpasa
│ ├── grasswonder
│ ├── kinghalo
│ ├── seiunsky
│ └── specialweek
├── tmp
├── train_data
│ ├── elcondorpasa
│ ├── grasswonder
│ ├── kinghalo
│ ├── seiunsky
│ └── specialweek
└── train_data_augment
├── elcondorpasa
├── grasswonder
├── kinghalo
├── seiunsky
└── specialweek
アニメ顔検出用の分類器のxmlファイルを取得します.
! wget https://raw.githubusercontent.com/nagadomi/lbpcascade_animeface/master/lbpcascade_animeface.xml
imgフォルダに保存したライブアニメーションを0.5秒ごとに読み込み,顔画像の切り抜きを行います.
このソースコードは上記の記事のものをほぼ引用させて頂きました.
#必要なライブラリをインポート
import cv2
from google.colab.patches import cv2_imshow # パッチファイルインポート
#顔検出器の準備
classifier = cv2.CascadeClassifier("lbpcascade_animeface.xml")
#画像につけるナンバー
ver = 5 #読み込む動画を変える毎に変更する(生成する画像ファイルの名前が被らないようにするため)
img = 0
msec = 0 #動画内の時間
output_dir = "tmp/"
#動画の読み込み
cap = cv2.VideoCapture("img/1.MP4")
while(cap.isOpened()):
cap.set(0, msec*1000)
ret, frame = cap.read()
if ret:
#グレースケール化して顔検出し座標を取得
frame = cv2.rotate(frame, cv2.ROTATE_90_COUNTERCLOCKWISE) #なぜか読み込む動画が90度回転してしまっていたため,元に戻す
gray_image = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = classifier.detectMultiScale(gray_image)
for i, (x, y, w, h) in enumerate(faces):
#表示している画像の時間
print(str(msec) + "[sec]")
face_image = frame[y:y+h, x:x+w]
#画像サイズを64*64にリサイズ
face_image_resize = cv2.resize(face_image, (64, 64))
#切り出した顔の表示
cv2_imshow(face_image_resize)
#生成した画像の保存先を指定
output_path = output_dir + "{}_{}.jpg".format(ver, img)
img += 1
#生成した画像の保存
print("save " + output_path)
cv2.imwrite(output_path, face_image_resize)
msec += 0.5
else:
break
cap.release()
切り抜かれた顔画像はtmpフォルダに保存されます.
2. ウマ娘ごとに顔画像を振り分け
先ほど切り抜いた顔画像をfacesフォルダ内のウマ娘ごとのフォルダに移していきます.
この際,顔以外の画像やぼやけていて不明瞭な画像もあるため削除していきます.
振り分け終了後に各ウマ娘の顔画像の枚数を確認すると以下のようになりました.
elcondorpasa : 261 枚
grasswonder : 223 枚
kinghalo : 226 枚
seiunsky : 228 枚
specialweek : 225 枚
他と比べてエルコンドルパサーの顔画像が少し多いですが,大体均等な枚数となりました.
3. 顔画像を訓練データとテストデータに分割
先ほど振り分けた顔画像をモデルの訓練データとテストデータに分けます.
今回は訓練データとテストデータの比率が8:2となるようにしました.
#顔画像を訓練データとテストデータに分割
import shutil
import random
import glob
import os
#訓練データ画像格納用のディレクトリを生成
if not os.path.exists("train_data"):
shutil.copytree("faces", "train_data")
#ウマ娘の名前のリスト
names = ["specialweek", "seiunsky", "kinghalo", "elcondorpasa", "grasswonder"]
for name in names:
#顔画像のデータを取得
faces_list_train = glob.glob("train_data/" + name + "/*")
#顔画像をシャッフル
random.shuffle(faces_list_train)
#訓練用データフォルダから2割のデータをテスト用のデータフォルダに移動
for i in range(int((len(faces_list_train))/5)):
shutil.move(str(faces_list_train[i]), "test_data/" + name)
訓練データとテストデータ分割後の顔画像の枚数を確認すると,以下のようになりました.
元データ:
elcondorpasa : 261 枚
grasswonder : 223 枚
kinghalo : 226 枚
seiunsky : 228 枚
specialweek : 225 枚
訓練データ:
elcondorpasa : 209 枚
grasswonder : 179 枚
kinghalo : 181 枚
seiunsky : 183 枚
specialweek : 180 枚
テストデータ:
elcondorpasa : 52 枚
grasswonder : 44 枚
kinghalo : 45 枚
seiunsky : 45 枚
specialweek : 45 枚
きちんと訓練データとテストデータの比率が8:2となっていることが確認できました.
4. 訓練データの水増し
訓練データの枚数が心許ないので,水増し(Data Augmentation)を行います.
水増しをどのようにやったら良いかがよく分からなかったので,以下の記事のコードを使用させて頂きました.
以下がソースコードです.
#訓練データの水増しを行う
import shutil
from scipy import ndimage
import cv2
#水増しした訓練データを格納するディレクトリを生成
if not os.path.exists("train_data_augment"):
shutil.copytree("train_data", "train_data_augment")
#ウマ娘の名前のリスト
names = ["specialweek", "seiunsky", "kinghalo", "elcondorpasa", "grasswonder"]
#1人ずつ顔画像を水増し
for name in names:
#訓練データを取得
face_list_train = glob.glob("train_data_augment/" + name + "/*")
for i in range(len(face_list_train)):
path = str(face_list_train[i])
img = cv2.imread(path)
#回転処理
for ang in [-10, 0, 10]:
img_rot = ndimage.rotate(img, ang)
img_rot = cv2.resize(img_rot, (64,64))
cv2.imwrite(path[:-4]+"_"+str(ang)+".jpg", img_rot)
#閾値処理
img_thr = cv2.threshold(img_rot, 100, 255, cv2.THRESH_TOZERO)[1]
cv2.imwrite(path[:-4]+"_"+str(ang)+"_thr.jpg", img_thr)
#ぼかし処理
img_filter = cv2.GaussianBlur(img_rot, (5, 5), 0)
cv2.imwrite(path[:-4]+"_"+str(ang)+"_filter.jpg", img_filter)
水増し終了後の訓練データの枚数を確認すると以下のようになりました.
elcondorpasa : 2090 枚
grasswonder : 1790 枚
kinghalo : 1810 枚
seiunsky : 1830 枚
specialweek : 1800 枚
訓練データを10倍の量に水増しすることができました.
5. DataLoaderの作成
(正直,ここの部分はあまり理解していないため,詳しい説明を書くことができないです.すみません.)
次にDataLoaderの作成を行っていきます.
DataLoaderは,深層学習では一般的なミニバッチ学習を実装する上で必要です.
以下にDataLoaderを作成するためのソースコードを示します.
transforms
transformsを用いることにより,画像の前処理を行うことができます.
特にPytorchでは扱う画像をTensor型に変換しないといけないのですが,それもtransformsで簡単に行うことができます.
from torchvision import transforms
#Transformを作成する。
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
ImageFolder
Pytorchでは読み込むデータをDatasetとして定義する必要があります.
このDatasetをDataLoaderに渡すことで,ミニバッチを取り出すことができます.
今回顔画像はウマ娘ごとにフォルダ分けされているので,ImageFolderクラスを使用することにします.
from torchvision.datasets import ImageFolder
#訓練用の画像とテスト用の画像が格納されているディレクトリのパス
train_path = "train_data_augment/"
test_path = "test_data/"
#ImageFolderのインスタンス生成
train_set = ImageFolder(root=train_path, # 画像が保存されているフォルダのパス
transform=transform) # Tensorへの変換
test_set = ImageFolder(root=test_path, # 画像が保存されているフォルダのパス
transform=transform) # Tensorへの変換
DataLoader
先ほど定義したDatasetを使用して,DataLoaderを作成します.
from torch.utils.data import DataLoader, Dataset
#DataLoaderを作成する。
train_loader = DataLoader(train_set, batch_size=64)
test_loader = DataLoader(test_set, batch_size=64)
6. モデルの学習・評価・保存
いよいよモデルの構築を行っていきます.
既存のモデルを使用する手法(ファインチューニング)もありますが,今回は1からモデルを構築することにしました.
プログラムを書くにあたって以下の記事を参考にしました.(非常に分かりやすかったです!)
構築したモデルの構造
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 6, 60, 60] 456
MaxPool2d-2 [-1, 6, 30, 30] 0
Conv2d-3 [-1, 16, 26, 26] 2,416
MaxPool2d-4 [-1, 16, 13, 13] 0
Conv2d-5 [-1, 32, 10, 10] 8,224
Dropout2d-6 [-1, 32, 10, 10] 0
Linear-7 [-1, 120] 384,120
Linear-8 [-1, 84] 10,164
Linear-9 [-1, 5] 425
================================================================
Total params: 405,805
Trainable params: 405,805
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.05
Forward/backward pass size (MB): 0.36
Params size (MB): 1.55
Estimated Total Size (MB): 1.95
----------------------------------------------------------------
以下に使用したソースコードを示します.
モデルの定義
#必要なライブラリの読み込み
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets
from torchsummary import summary
import numpy as np
#モデルの定義
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.cn1 = nn.Conv2d(3, 6, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.cn2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.cn3 = nn.Conv2d(16, 32, 4)
self.dropout = nn.Dropout2d()
self.fc1 = nn.Linear(32*10*10, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 5)
def forward(self, x):
x = F.relu(self.cn1(x))
x = self.pool1(x)
x = F.relu(self.cn2(x))
x = self.pool2(x)
x = F.relu(self.cn3(x))
x = self.dropout(x)
x = x.view(-1, 32*10*10)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
1エポック分の学習を行う関数を定義
学習が終了したモデルをここで保存するようにしました.
#1エポックの学習を行う関数
def train_epoch(model, optimizer, criterion, train_loader, epoch):
train_loss = 0
model.train()
for i, (images, labels) in enumerate(train_loader):
images, labels = images, labels
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
#train lossを計算
train_loss = train_loss / len(train_loader.dataset)
#学習済みのモデルを保存
outfile = "cnn-" + str(epoch) + ".model"
torch.save(model.state_dict(), outfile)
print(outfile," saved")
return train_loss
推論を行うための関数を定義
#推論を行うための関数
def inference(model, optimizer, criterion, test_loader):
model.eval()
test_loss=0
correct=0
with torch.no_grad():
for i, (images, labels) in enumerate(test_loader):
images, labels = images, labels
outputs = model(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
pred = outputs.argmax(dim=1, keepdim=True)
correct += pred.eq(labels.view_as(pred)).sum().item()
#test lossを計算
test_loss = test_loss / len(test_loader.dataset)
#Accuracyを計算
accuracy = correct / len(test_loader.dataset)
return test_loss, accuracy
学習・推論を行う関数を呼び出す関数を定義
先ほど定義したモデルの学習と推論を行う関数を呼び出す関数を定義します.
各エポックのtrain_lossやtest_lossをリストで格納しているのは,後で結果の可視化を行うためです.
モデルの構築を行う際はこの関数を呼び出します.
#学習と推論を行うための関数
def run(num_epochs, model, optimizer, criterion, train_loader, test_loader):
train_loss_list = [] #各エポックごとのtrain lossを格納するリスト
test_loss_list = [] #各エポックごとのtest lossを格納するリスト
accuracy_list = [] #各エポックごとのAccuracyを格納するリスト
epoch_list = [] #エポック数を格納するリスト
#学習と推論を行う関数を呼び出す
for epoch in range(num_epochs):
train_loss = train_epoch(model, optimizer, criterion, train_loader, epoch)
test_loss, accuracy = inference(model, optimizer, criterion, test_loader)
print(f'Epoch [{epoch+1}], train_Loss : {train_loss:.4f}, test_Loss : {test_loss:.4f}, Accuracy : {accuracy:4f}')
#それぞれのリストに実行結果を格納
train_loss_list.append(train_loss)
test_loss_list.append(test_loss)
accuracy_list.append(accuracy)
epoch_list.append(epoch+1)
return train_loss_list, test_loss_list, accuracy_list, epoch_list
学習・推論を実行
モデルの最適化関数にはAdam,損失関数にはCrossEntropyLoss(分類問題用)を設定しました.
#モデルの定義
model = CNN()
#最適化手法を設定
optimizer = optim.Adam(model.parameters(), lr=1e-5)
#損失関数の設定
criterion = nn.CrossEntropyLoss()
#モデルの学習と推論を開始
train_loss_list, test_loss_list, accuracy_list, epoch_list = run(100, model, optimizer, criterion, train_loader, test_loader)
学習・推論の結果を確認
Google Colaboratory上のGPUを使用してモデルの学習を行いました.
全ての学習が終了するのに2時間程度かかった気がします.
Epoch [1] : train_loss 0.0254, test_loss 0.0280, Accuracy 0.1905
Epoch [2] : train_loss 0.0253, test_loss 0.0280, Accuracy 0.1905
Epoch [3] : train_loss 0.0252, test_loss 0.0279, Accuracy 0.1905
Epoch [4] : train_loss 0.0252, test_loss 0.0279, Accuracy 0.1905
Epoch [5] : train_loss 0.0251, test_loss 0.0278, Accuracy 0.2121
Epoch [6] : train_loss 0.0250, test_loss 0.0276, Accuracy 0.3550
Epoch [7] : train_loss 0.0248, test_loss 0.0273, Accuracy 0.4199
Epoch [8] : train_loss 0.0244, test_loss 0.0269, Accuracy 0.4242
Epoch [9] : train_loss 0.0239, test_loss 0.0263, Accuracy 0.4242
Epoch [10] : train_loss 0.0233, test_loss 0.0256, Accuracy 0.4113
Epoch [11] : train_loss 0.0225, test_loss 0.0249, Accuracy 0.4113
Epoch [12] : train_loss 0.0217, test_loss 0.0242, Accuracy 0.4113
Epoch [13] : train_loss 0.0208, test_loss 0.0234, Accuracy 0.4242
Epoch [14] : train_loss 0.0199, test_loss 0.0226, Accuracy 0.4459
Epoch [15] : train_loss 0.0189, test_loss 0.0216, Accuracy 0.4935
Epoch [16] : train_loss 0.0180, test_loss 0.0204, Accuracy 0.5152
Epoch [17] : train_loss 0.0170, test_loss 0.0193, Accuracy 0.5541
Epoch [18] : train_loss 0.0159, test_loss 0.0181, Accuracy 0.6017
Epoch [19] : train_loss 0.0151, test_loss 0.0168, Accuracy 0.6234
Epoch [20] : train_loss 0.0142, test_loss 0.0157, Accuracy 0.6753
Epoch [21] : train_loss 0.0132, test_loss 0.0145, Accuracy 0.7013
Epoch [22] : train_loss 0.0123, test_loss 0.0135, Accuracy 0.7143
Epoch [23] : train_loss 0.0116, test_loss 0.0126, Accuracy 0.7316
Epoch [24] : train_loss 0.0109, test_loss 0.0118, Accuracy 0.7532
Epoch [25] : train_loss 0.0103, test_loss 0.0110, Accuracy 0.7879
Epoch [26] : train_loss 0.0097, test_loss 0.0104, Accuracy 0.8009
Epoch [27] : train_loss 0.0092, test_loss 0.0098, Accuracy 0.7965
Epoch [28] : train_loss 0.0088, test_loss 0.0092, Accuracy 0.8052
Epoch [29] : train_loss 0.0083, test_loss 0.0088, Accuracy 0.8052
Epoch [30] : train_loss 0.0079, test_loss 0.0083, Accuracy 0.8139
Epoch [31] : train_loss 0.0077, test_loss 0.0081, Accuracy 0.8139
Epoch [32] : train_loss 0.0074, test_loss 0.0077, Accuracy 0.8139
Epoch [33] : train_loss 0.0071, test_loss 0.0074, Accuracy 0.8312
Epoch [34] : train_loss 0.0069, test_loss 0.0071, Accuracy 0.8355
Epoch [35] : train_loss 0.0066, test_loss 0.0068, Accuracy 0.8355
Epoch [36] : train_loss 0.0064, test_loss 0.0066, Accuracy 0.8355
Epoch [37] : train_loss 0.0063, test_loss 0.0064, Accuracy 0.8355
Epoch [38] : train_loss 0.0061, test_loss 0.0062, Accuracy 0.8355
Epoch [39] : train_loss 0.0060, test_loss 0.0060, Accuracy 0.8485
Epoch [40] : train_loss 0.0058, test_loss 0.0058, Accuracy 0.8615
Epoch [41] : train_loss 0.0057, test_loss 0.0057, Accuracy 0.8615
Epoch [42] : train_loss 0.0055, test_loss 0.0055, Accuracy 0.8658
Epoch [43] : train_loss 0.0054, test_loss 0.0055, Accuracy 0.8658
Epoch [44] : train_loss 0.0053, test_loss 0.0053, Accuracy 0.8701
Epoch [45] : train_loss 0.0052, test_loss 0.0052, Accuracy 0.8701
Epoch [46] : train_loss 0.0052, test_loss 0.0051, Accuracy 0.8831
Epoch [47] : train_loss 0.0050, test_loss 0.0050, Accuracy 0.8831
Epoch [48] : train_loss 0.0049, test_loss 0.0049, Accuracy 0.8918
Epoch [49] : train_loss 0.0048, test_loss 0.0047, Accuracy 0.9004
Epoch [50] : train_loss 0.0047, test_loss 0.0046, Accuracy 0.9048
Epoch [51] : train_loss 0.0047, test_loss 0.0046, Accuracy 0.9048
Epoch [52] : train_loss 0.0046, test_loss 0.0045, Accuracy 0.9048
Epoch [53] : train_loss 0.0045, test_loss 0.0043, Accuracy 0.9048
Epoch [54] : train_loss 0.0045, test_loss 0.0043, Accuracy 0.9048
Epoch [55] : train_loss 0.0043, test_loss 0.0042, Accuracy 0.9048
Epoch [56] : train_loss 0.0043, test_loss 0.0041, Accuracy 0.9048
Epoch [57] : train_loss 0.0042, test_loss 0.0041, Accuracy 0.9048
Epoch [58] : train_loss 0.0042, test_loss 0.0040, Accuracy 0.9091
Epoch [59] : train_loss 0.0041, test_loss 0.0039, Accuracy 0.9134
Epoch [60] : train_loss 0.0039, test_loss 0.0038, Accuracy 0.9091
Epoch [61] : train_loss 0.0040, test_loss 0.0037, Accuracy 0.9134
Epoch [62] : train_loss 0.0039, test_loss 0.0037, Accuracy 0.9134
Epoch [63] : train_loss 0.0039, test_loss 0.0036, Accuracy 0.9134
Epoch [64] : train_loss 0.0038, test_loss 0.0036, Accuracy 0.9134
Epoch [65] : train_loss 0.0038, test_loss 0.0035, Accuracy 0.9177
Epoch [66] : train_loss 0.0037, test_loss 0.0035, Accuracy 0.9177
Epoch [67] : train_loss 0.0036, test_loss 0.0034, Accuracy 0.9177
Epoch [68] : train_loss 0.0036, test_loss 0.0033, Accuracy 0.9177
Epoch [69] : train_loss 0.0036, test_loss 0.0033, Accuracy 0.9177
Epoch [70] : train_loss 0.0035, test_loss 0.0032, Accuracy 0.9177
Epoch [71] : train_loss 0.0035, test_loss 0.0032, Accuracy 0.9221
Epoch [72] : train_loss 0.0034, test_loss 0.0031, Accuracy 0.9264
Epoch [73] : train_loss 0.0034, test_loss 0.0031, Accuracy 0.9307
Epoch [74] : train_loss 0.0033, test_loss 0.0030, Accuracy 0.9264
Epoch [75] : train_loss 0.0032, test_loss 0.0030, Accuracy 0.9264
Epoch [76] : train_loss 0.0032, test_loss 0.0030, Accuracy 0.9264
Epoch [77] : train_loss 0.0032, test_loss 0.0029, Accuracy 0.9307
Epoch [78] : train_loss 0.0031, test_loss 0.0029, Accuracy 0.9351
Epoch [79] : train_loss 0.0031, test_loss 0.0028, Accuracy 0.9351
Epoch [80] : train_loss 0.0031, test_loss 0.0028, Accuracy 0.9351
Epoch [81] : train_loss 0.0031, test_loss 0.0027, Accuracy 0.9351
Epoch [82] : train_loss 0.0030, test_loss 0.0027, Accuracy 0.9437
Epoch [83] : train_loss 0.0030, test_loss 0.0026, Accuracy 0.9437
Epoch [84] : train_loss 0.0030, test_loss 0.0026, Accuracy 0.9394
Epoch [85] : train_loss 0.0030, test_loss 0.0026, Accuracy 0.9437
Epoch [86] : train_loss 0.0028, test_loss 0.0025, Accuracy 0.9437
Epoch [87] : train_loss 0.0028, test_loss 0.0025, Accuracy 0.9437
Epoch [88] : train_loss 0.0027, test_loss 0.0024, Accuracy 0.9437
Epoch [89] : train_loss 0.0027, test_loss 0.0025, Accuracy 0.9481
Epoch [90] : train_loss 0.0026, test_loss 0.0024, Accuracy 0.9524
Epoch [91] : train_loss 0.0027, test_loss 0.0024, Accuracy 0.9524
Epoch [92] : train_loss 0.0027, test_loss 0.0023, Accuracy 0.9567
Epoch [93] : train_loss 0.0026, test_loss 0.0024, Accuracy 0.9481
Epoch [94] : train_loss 0.0026, test_loss 0.0023, Accuracy 0.9567
Epoch [95] : train_loss 0.0025, test_loss 0.0023, Accuracy 0.9567
Epoch [96] : train_loss 0.0025, test_loss 0.0022, Accuracy 0.9567
Epoch [97] : train_loss 0.0026, test_loss 0.0022, Accuracy 0.9610
Epoch [98] : train_loss 0.0026, test_loss 0.0022, Accuracy 0.9610
Epoch [99] : train_loss 0.0025, test_loss 0.0021, Accuracy 0.9610
Epoch [100] : train_loss 0.0024, test_loss 0.0021, Accuracy 0.9610
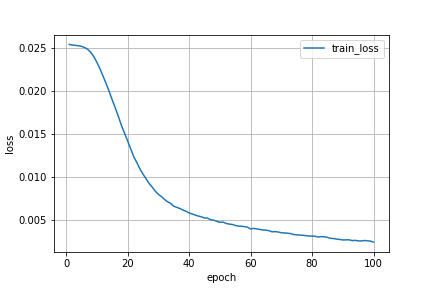
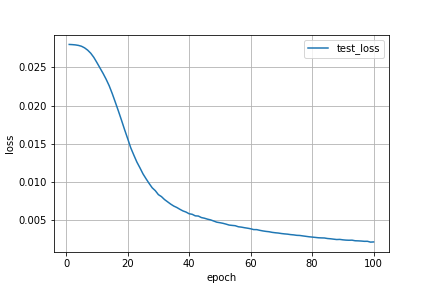
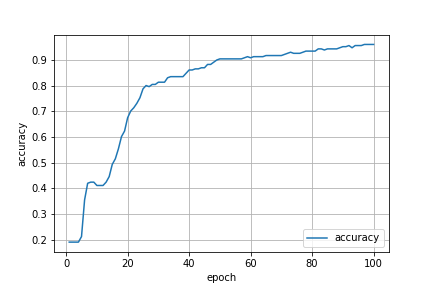
最終的に正答率は96%まで上がりました!
train_loss(訓練誤差)とtest_loss(検証誤差)の値も離れていないので,過学習が起こっていないことも確認できます.
上記のログを可視化すると,以下のようになります.
7. アプリケーション部分の作成
ここからは実際に画像を読み込んで顔を検出するアプリケーションを作成していきます.
完成イメージは以下のようになります.
 <\p>
<\p>
Pythonでアプリケーション作成といえばFlaskやDjangoが有名ですが,StreamlitだとPythonスクリプトのみで手軽にアプリケーションを作成できるためこちらを採用しました.(ただし,細かい調整はできない)
以下がアプリケーション部分のソースコードです.
#必要なライブラリをインポート
import streamlit as st
import numpy as np
from PIL import Image
import cv2
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
#ロードするモデルの定義
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.cn1 = nn.Conv2d(3, 6, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.cn2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.cn3 = nn.Conv2d(16, 32, 4)
self.dropout = nn.Dropout2d()
self.fc1 = nn.Linear(32*10*10, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 5)
def forward(self, x):
x = F.relu(self.cn1(x))
x = self.pool1(x)
x = F.relu(self.cn2(x))
x = self.pool2(x)
x = F.relu(self.cn3(x))
x = self.dropout(x)
x = x.view(-1, 32*10*10)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
#読み込んだ画像の中からウマ娘の顔を検出し,名前とBoxを描画する関数
def detect(image, model):
#顔検出器の準備
classifier = cv2.CascadeClassifier("lbpcascade_animeface.xml")
#画像をグレースケール化
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#画像の中から顔を検出
faces = classifier.detectMultiScale(gray_image)
#1人以上の顔を検出した場合
if len(faces)>0:
for face in faces:
x, y, width, height = face
detect_face = image[y:y+height, x:x+width]
if detect_face.shape[0] < 64:
continue
detect_face = cv2.resize(detect_face, (64,64))
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
detect_face = transform(detect_face)
detect_face = detect_face.view(1,3,64,64)
output = model(detect_face)
name_label = output.argmax(dim=1, keepdim=True)
name = label_to_name(name_label)
cv2.rectangle(image, (x,y), (x+width,y+height), (255, 0, 0), thickness=3) #四角形描画
cv2.putText(image, name,(x,y+height+20), cv2.FONT_HERSHEY_DUPLEX, 1, (255,0,0),2) #人物名記述
return image
#ラベルから対応するウマ娘の名前を返す関数
def label_to_name(name_label):
if name_label == 0:
name = "El Condor Pasa"
elif name_label == 1:
name = "Grass Wonder"
elif name_label == 2:
name = "King Halo"
elif name_label == 3:
name = "Seiun Sky"
elif name_label == 4:
name = "Special Week"
return name
def main():
st.set_page_config(layout="wide")
#タイトルの表示
st.title("ウマ娘 98世代 顔認識アプリ")
#制作者の表示
st.text("Created by Tatsuya NISHIZAWA")
#アプリの説明の表示
st.markdown("98世代のウマ娘の顔を識別するアプリです")
#サイドバーの表示
image = st.sidebar.file_uploader("画像をアップロードしてください", type=['jpg','jpeg', 'png'])
#サンプル画像を使用する場合
use_sample = st.sidebar.checkbox("サンプル画像を使用する")
if use_sample:
image = "sample.jpeg"
#保存済みのモデルをロード
model = CNN()
model.load_state_dict(torch.load("cnn-99.model"))
model.eval()
#画像ファイルが読み込まれた後,顔認識を実行
if image != None:
#画像の読み込み
image = np.array(Image.open(image))
#画像からウマ娘の顔検出を行う
detect_image = detect(image, model)
#顔検出を行った結果を表示
st.image(detect_image, use_column_width=True)
if __name__ == "__main__":
#main関数の呼び出し
main()
実行結果
ここからは実際に顔分類を行った結果を示します.
成功例


 <\p>
<\p>




複数人の場合でも正しく分類ができています.
失敗例
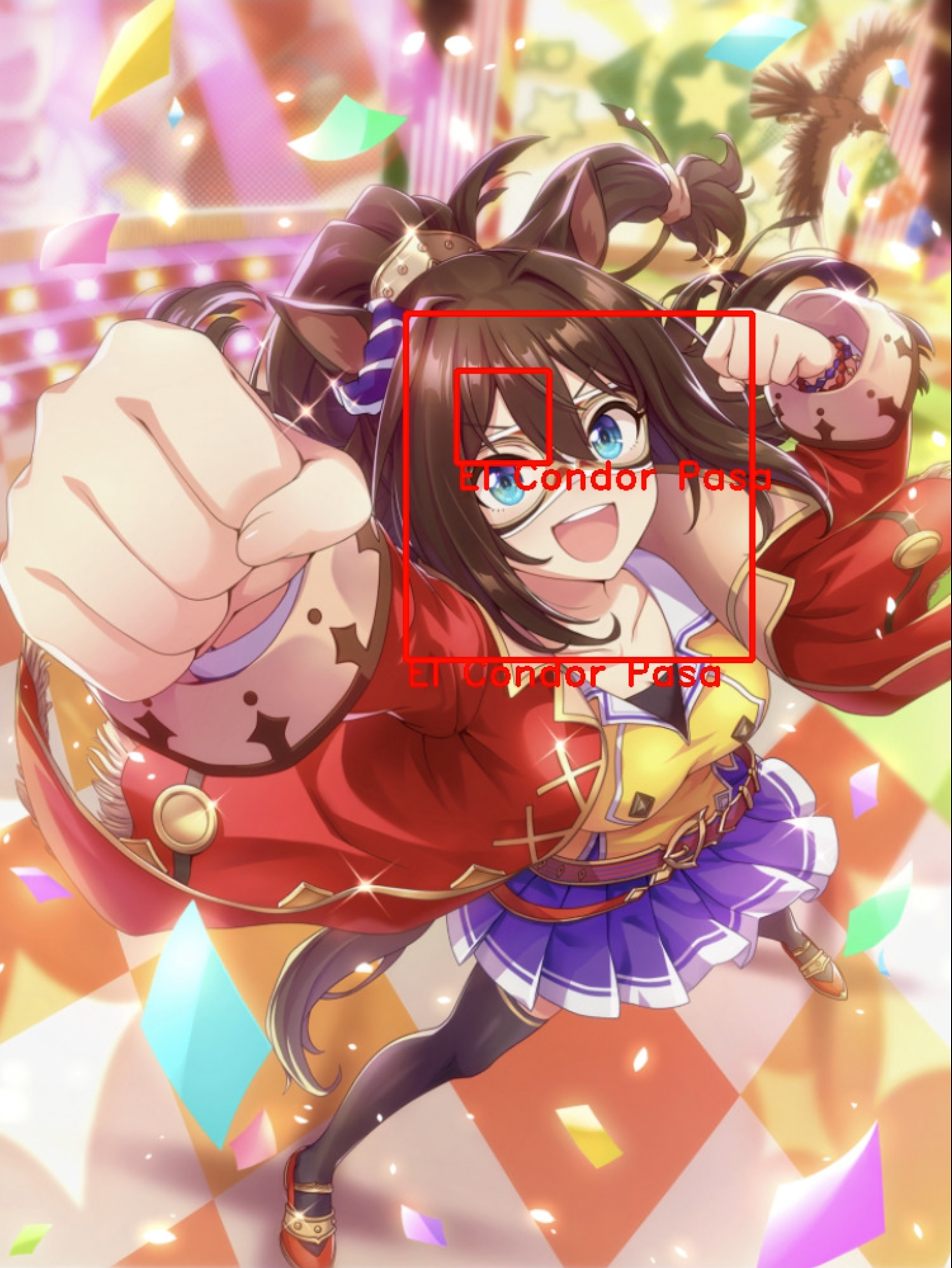
以下に分類に失敗した例を示します.
エルコンドルパサーは合っているのだけど,2人いる判定になっています笑
また,横顔の分類は難しいようです.
 <\p>
<\p>

ちなみに...
一部の界隈でサイレンススズカとグラスワンダーは似ていると言われているようですが...


AIから見てもサイレンススズカとグラスワンダーは似ているそうです笑
サイレンススズカとグラスワンダーの顔分類器を作成したらどうなるのだろうか.
まとめ
今回深層学習やPytorchを初めて扱いましたが,思いの外正しく顔分類を行うモデルを構築することができて良かったです.
まだまだ理解が足りていない部分も多いので,今後も勉強を続けていきたいと思います!
(次はスピカメンバーの顔分類をするモデルを作ろうかな)
参考文献(再掲)
https://qiita.com/bianca26neve/items/19085841c9ac6209fe91
https://qiita.com/nirs_kd56/items/bc78bf2c3164a6da1ded
https://dreamer-uma.com/pytorch-cnn/
https://qiita.com/coper/items/b1fd51062642d624e26f