環境
Jupyter Notebook(6.1.4)を用いて作業を進めました。
主要なライブラリのバーションは以下の通りです。
OpenCV(4.5.3), Tensorflow(2.5.0)
また、ディレクトリの構成は後述します。
きっかけ
前回mediapipeを使って手の検出を行いました。OpenCVが不慣れすぎて画像や動画の取り扱いに苦戦しながらの作業でしたが、結果が画像や動画で確認できるのが楽しかったので、何か好きなものを使って練習したいと思ったのがはじまりです。ちょうど同僚の方がアイドルの顔の検出をアプリ化されていたので、私も推しの顔検出にチャレンジしてみました。アプリ化まではちょっとハードル高かったので、ひとまず画像数やキャラ数など小規模で簡単にチャレンジしました。ひとまず形にする、を目標にしているので適当な部分も多いですがご容赦ください。
概要
やったことは下の動画のように、動画の中からキャラの顔を検出して、それが誰なのかを表示することです。

これの作成のために、以下のようなことを行いました。
- 判別する愛馬を選ぶ
- ライブアニメーションから顔画像を集めてラベルをつける
- CNNモデルを作って学習する
- 別のライブアニメーションに結果を描画する
一番苦しかったのは初めの作業です。ライブが3人構成のものが多かったことと最初から規模を大きくするのにチキったのでまずは3人とその他の分類をしようと考えたのですが、みんなかわいいので3人なんて選べません。苦肉の選択でした。
また、特に2番目の作業が地道な作業でしたが、小規模だった上、推しの顔が並ぶ最高のフォルダが出来上がったので2番目以降はわりと常に幸せな気持ちで行うことができました。OpenCVの練習にも多少はなったはず。。。
というわけでやったことの詳細をまとめておきます。
①判別する愛馬を選ぶ
取り敢えず作業環境を整えるために以下のファイル構造を作りました。
file/
├─ notebook.ipynp <-コードはすべてここで実行
├─ lbpcascade_animeface/ <- 後ほどGithubからクローンさせていただきました
└─ lbpcascade_animeface.xml
├─ uma/
│ └─ ライブアニメーションなどのmp4ファイルを保存
└─ faces/
├─ tokaiteio/
├─ tmoperao/
├─ agnestachyon/
└─ other/
用意した動画はumaフォルダに保存し、加工したデータはfacesフォルダの配下に保存していきます。ラベル付けの際に楽をするために泣く泣く選んだ愛馬の名前のフォルダを用意しておきます。テイエムオペラオーの英語名の綴りが意外でした。
②ライブアニメーションから顔画像を集めてラベルをつける
まずはスマホでスクリーンレコードしながらうまぴょいしてテンションをあげます。センターを変更したり曲を変えたりしながら計4つのライブアニメーションをmp4形式で用意し、PCの方に移してumaフォルダに保存します。
次に顔画像の切り抜きの作業に移ります。この作業は以下の記事を参考にさせていただきました。
~~ノラと皇女と野良猫ハートのVita版のオープニングムービーを見ましたがめっちゃ可愛い。。。~~面白く丁寧に書かれていて大変ありがたかったです。
というわけでGithubからアニメ版顔検出のxmlファイルを取得します。
あとはJupyter Notebookを開き、OpenCVを使って動画を0.5秒毎に読込、顔検出で切り出した顔を表示させ、入力したキーによって保存先を決めて保存していきます。
# Opencvをインポート
import cv2
# アニメ顔検出器の準備
classifier = cv2.CascadeClassifier('./lbpcascade_animeface/lbpcascade_animeface.xml')
output_dir = './faces/'
# 画像につけるナンバーの初期化
teio = 0
operao = 0
tachyon = 0
other = 0
msec = 0
# 動画の読込(このコードはumapyoi.mp4を読込)
cap = cv2.VideoCapture('./uma/umapyoi.mp4')
while(cap.isOpened()):
cap.set(0,msec*1000)
ret, frame = cap.read()
if ret:
#グレースケール化して顔検出し座標を取得
gray_image = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = classifier.detectMultiScale(gray_image)
for i, (x, y, w, h) in enumerate(faces):
#表示している画像の時間
print(str(msec)+'[sec]')
#入力指示
#表示される顔を見て対応する数字を入力する
print('9:teio 0:operao 2:other 3:tachyon q:noface')
#画像全体の表示
cv2.imshow('FRAME', frame)
face_image = frame[y:y+h, x:x+h]
face_image_resize = cv2.resize(face_image, (64, 64))
#切り出した顔の表示
cv2.imshow('DETECT', face_image_resize)
flg = cv2.waitKey(0)
if flg == 48: #0が入力されたらtmoperaoフォルダへ
output_path = output_dir + 'tmoperao/{}.jpg'.format(operao)
operao += 1
elif flg == 50: #2が入力されたらotherフォルダへ
output_path = output_dir + 'other/{}.jpg'.format(other)
other += 1
elif flg == 51: #3が入力されたらagnestachyonフォルダへ
output_path = output_dir + 'agnestachyon/{}.jpg'.format(tachyon)
tachyon += 1
elif flg == 57: #9が入力されたらtokaiteioフォルダへ
output_path = output_dir + 'tokaiteio/{}.jpg'.format(teio)
teio += 1
elif flg == 113: #qが入力されたら保存しない
exit(-1)
print('save'+output_path)
cv2.imwrite(output_path, face_image_resize)
msec += 0.5
else:
break
cap.release()
これで出てくるウインドウを見ながらポチポチと入力していきます。普通に打ち間違えたりするので間違えたものはあとで手動で消去しました。4動画分でしたが2分前後かつ0.5秒間隔なのでそんなに量はなかったように思います。試しにtokaiteioのフォルダを覗くとこんな感じになってます。

かわいい。。。既に満足感があります。。。そして消し忘れているオペラオーがいますね。。。
ライブの画像なので検出されうる角度でいろいろな表情が取れているように思えます。
これで学習用の顔画像が用意できたので、次のステップに移っていきます。
③CNNモデルを作って学習する
覚えたてのTensorFlowを使ってCNNモデルを作り学習していきます。まずは用意した画像のパスとラベルのデータフレームを用意します。
import pandas as pd
import numpy as np
import cv2
import os
import glob
face_path = './faces/'
# facesフォルダ内のフォルダ名のリストを取得
file_list = os.listdir(face_path)
df = []
# フォルダごとに中にある画像のパスを取得
for foldername in file_list:
imgs_path = face_path + foldername
imgs = sorted(glob.glob(imgs_path + '/' + '*.jpg'))
#画像とフォルダ名をタプルにして保存
for name in imgs:
df.append((str(name), str(foldername)))
# Dataframe化
df = pd.DataFrame(df, columns=['img', 'label'])
# 各キャラの画像数の確認
print(df['label'].value_counts())
# 先頭3行を確認
df.head(3)
実行結果は以下のようになっていました。画像の数はそんなにバランス悪くなさそうな印象です。
| 1 | 2 |
|---|---|
| tokaiteio | 282 |
| tmoperao | 275 |
| agnestachyon | 263 |
| other | 217 |
| img | label |
|---|---|
| ./faces/agnestachyon\0.jpg | agnestachyon |
| ./faces/agnestachyon\0.jpg | agnestachyon |
| ./faces/agnestachyon\10.jpg | agnestachyon |
このデータフレームを使って特徴量の配列を作っていきます。また、ラベルの方も数値化しておき、学習のために訓練データと検証データに分けておきます。
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
img_list = []
for i in range(len(df)):
image = cv2.imread(df['img'][i], 1)
image = image.astype('float32') / 255
img_list.append(image)
X = np.array(img_list)
le = LabelEncoder()
y = df['label']
y = le.fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X_train, y, test_size=0.2, stratify=y)
次にTensorflowを使ってCNNを構築します。どうしたらよくなるかがわからないので取り敢えずいい感じに構築してみてダメそうなら考えることにします。
import tensorflow as tf
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, kernel_size=(3, 3), padding='same', activation='relu', input_shape=(64, 64, 3)))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(rate=0.25))
model.add(tf.keras.layers.Conv2D(32, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(rate=0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(612, activation='relu'))
model.add(tf.keras.layers.Dense(256, activation='relu'))
model.add(tf.keras.layers.Dropout(rate=0.33))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(4, activation='softmax'))
model.summary()
出来上がったサマリーがこちら。
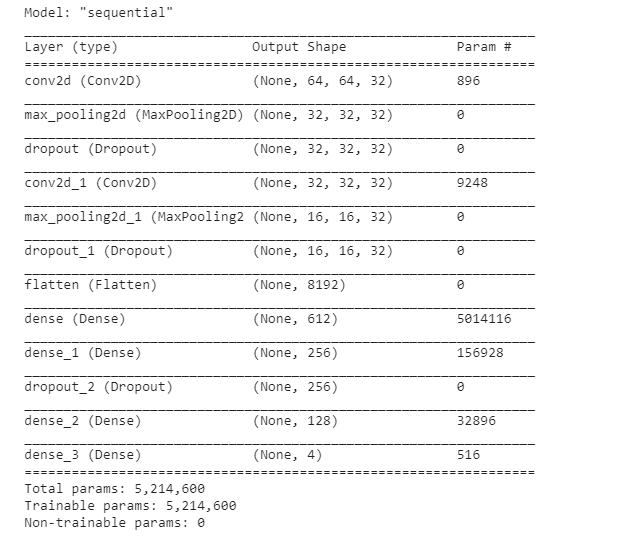
どんなもんかとコンパイルして学習させてみます。バッチ処理もしていないのでどうなんでしょうね。。
model.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy'])
callbacks = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=5)
model.fit(X_train, y_train, validation_data=(X_test, y_test), callbacks=[callbacks], epochs=20)

...もういいかこれで。9割でそれなりに満足しました。
試しに検証データの1つを表示してみます。
import matplotlib.pyplot as plt
%matplotlib inline
pred = model.predict_classes(X_test[0].reshape(-1, 64, 64, 3))
pred = le.inverse_transform(pred)[0]
cor = le.inverse_transform(y_test)[0]
print('correct:', cor)
print('predict:', pred)
plt.imshow(cv2.cvtColor(X_test[0], cv2.COLOR_BGR2RGB))
plt.show()
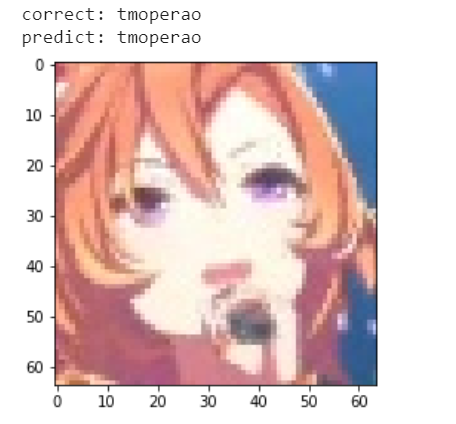
かわいい。。。ちゃんと予測できてそうです。これでモデル作成と結果の表示ができたので、次のステップに進みます。
④別のライブアニメーションに結果を描画する
再びスマホでスクリーンレコードを行い、別のライブアニメーションのmp4を用意してumaフォルダに保存しました。今回は全フレームで行いたいので5秒くらいにしておきました。
mediapipeいじったときのコードを参考にしながら新しい動画に対して顔認識してマーク、予測値を描画する処理を施し、facesフォルダに保存します。
classifier = cv2.CascadeClassifier('./lbpcascade_animeface/lbpcascade_animeface.xml')
cap = cv2.VideoCapture('./uma/specialrecord_test.mp4')
# 保存のための設定
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
size = (width, height)
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
frame_rate = int(cap.get(cv2.CAP_PROP_FPS))
save = cv2.VideoWriter('./faces/test.mp4', frame_count, frame_rate, size)
while cap.isOpened():
ret, image = cap.read()
if not ret:
break
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
faces = classifier.detectMultiScale(gray_image)
for x,y,w,h in faces:
#顔の部分を四角で囲む
cv2.rectangle(image, (x,y), (x+w,y+h), color=(0,0,255), thickness=5)
#分類器モデルに入れるための処理
face_image = image[y:y+h, x:x+h]
face_image_resize = cv2.resize(face_image, (64, 64))
X = face_image_resize.astype('float32') / 255
#モデルの予測ラベルを取得
label = model.predict_classes(X.reshape(-1, 64, 64, 3))
label = le.inverse_transform(label)[0]
#元画像の顔の上(x, y)地点に予測ラベルを描画
cv2.putText(image, label, (x, y), cv2.FONT_HERSHEY_COMPLEX, 2, (0, 0, 200), 3, cv2.LINE_AA)
save.write(image)
cap.release()
save.release()
そうして成果物が生まれました。

かわいい。。。私の愛馬3人をそれぞれ判別できているし、テイオーと前髪が似ている会長も別のキャラであると判断されています。
ただ、テイオーの横顔は別キャラと認識されているし、顔じゃない部分が判定されたときにキャラ判定がされています。学習データに誤認識を入れなかったからですね。学習データの用意段階での反省点です。
改善したいところ
目標のひとまず形にする、が達成されましたが、今後取り組みたいところもまとめておきます。
- キャラ数の増加
- より整理された描画
- アプリケーション化
- モデルへの理解と精度改善
- 顔認識部分の別モデルの利用または自作
もっと頑張って勉強していきたいと思います。