画像を取り扱う練習として面白そうなものを探していたところ、Mediapipeを使った検出が面白そうだったので、下の公式ガイドを見ながら手の検出をPythonで実装してみました!
準備
作業環境のファイル構造は下記のようにしています。コードはJupyter Notebookで行っています。
file/
├─ notebook.ipynp
├─ hands/
│ └─ hand1.jpgなどの静止画データ
├─ annotated_hand/
└─ hand_movie/
└─ hand_movie.mp4などの動画データ
notebookを開いて必要なライブラリをインポートしました。
# ファイル名の取得に使用
import os
# 画像処理に使用
import cv2
import mediapipe as mp
# 静止画表示に使用
import matplotlib.pyplot as plt
%matplotlib inline
自分の手の写真を使って検出する
ひとまず自分の手を撮影し、手袋した場合や暗い場所で撮影した場合の画像を用意し、hand1.JPGとしてhandsフォルダの中に入れておきます。

次に検出器のインスタンス化をします。このとき以下のオプションを設定しました。
| 変数名 | 意味や使い方 |
|---|---|
| static_image_mode | 静止画を取り扱うかどうかをブール値で設定 |
| max_num_hands | 1枚の画像の中で検出する手の最大数 |
| min_detection_confidence | 手かどうかを判断する際に用いる値で、1に近い値を入れるほど手と判断される画像が少なくなり、0に近づけるほど手と判断されることが多くなる |
hands = mp.solutions.hands.Hands(
static_image_mode=True,
max_num_hands=2,
min_detection_confidence=0.5)
次にOpenCVを使って読み込み、手の検出を行いresultsに保存します。
image = cv2.flip(cv2.imread('./hands/hand1.JPG'), 1)
results = hands.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
保存された結果から主に以下の2つを確認します。
| 内容 | |
|---|---|
| multi_handedness | index, score, labelの3つが返される。indexが0ならlabelは'Left'、1なら'Right'を返し、scoreはそのラベルが当てはまるであろう確率を与える。 |
| multi_hand_landmarks | 手が検出されると、21個の検出ポイントの座標(x, y, z)が表示される。x, yはそれぞれ画像の幅と高さによって正規化されており、zは手首を原点として値が大きほど遠い場所になり、xに合わせてスケーリングされる。手が検出されないとNoneになる |
なお、検出ポイントは公式ガイドにもある以下の画像を参考にしています。

実際に確認してみます。
results.multi_handedness
# --->
# [classification {
# index: 0
# score: 0.9999979734420776
# label: "Left"
# }]
# 検出ポイントの名前のリスト
landmark_list = ['WRIST', 'THUMP_CMC', 'THUMB_MCP', 'THUMB_IP', 'THUMB_TIP', 'INDEX_FINGER_MCP', 'INDEX_FINGER_PIP', 'INDEX_FINGER_DIP', 'INDEX_FINGER_TIP', 'MIDDLE_FINGER_MCP', 'MIDDLE_FINGER_PIP', 'MIDDLE_FINGER_DIP', 'MIDDLE_FINGER_TIP', 'RING_FINGER_MCP', 'RING_FINGER_PIP', 'RING_FINGER_DIP', 'RING_FINGER_TIP', 'PINKY_MCP', 'PINKY_PIP', 'PINKY_DIP', 'PINKY_TIP']
for hand_landmarks in results.multi_hand_landmarks:
for i in range(21):
print(landmark_list[i])
print(hand_landmarks.landmark[i])
# --->
# WRIST
# x: 0.29388704895973206
# y: 0.2464490830898285
# z: -5.091690400149673e-05
#
# THUMP_CMC
# x: 0.3243947923183441
# y: 0.23927538096904755
# z: -0.006033017300069332
#
# THUMB_MCP
# x: 0.3465648889541626
# y: 0.2057970017194748
# z: -0.019823197275400162
# :
# (省略)
また、mediapipeにはこの検出ポイントを描画する方法も用意されているので、これを使って描画してみました。(画像は見やすくするため拡大しています)
annotated_image = image.copy()
for hand_landmarks in results.multi_hand_landmarks:
mp.solutions.drawing_utils.draw_landmarks(
annotated_image,
hand_landmarks,
mp_hands.HAND_CONNECTIONS,
mp.solutions.drawing_styles.get_default_hand_landmarks_style(),
mp.solutions.drawing_styles.get_default_hand_connections_style()
)
plt.imshow(cv2.cvtColor(annotated_image, cv2.cv2.COLOR_BGR2RGB))

手の形をちゃんと検出できているようです!
いろいろな画像で手の検出を試してみる
どういう画像なら手の形を検出かどうか知りたかったので、いろいろな画像で試してみることにしました。
自分の左手で成功したので、右手の写真と両手が写った写真や、手袋をしたり部屋を暗くしたりして撮った
写真を用意しました。また、肌の色が明るい人や暗い人はどうか、アニメキャラはどうかということを確かめたかったので有名人や推しの画像を用意しました。
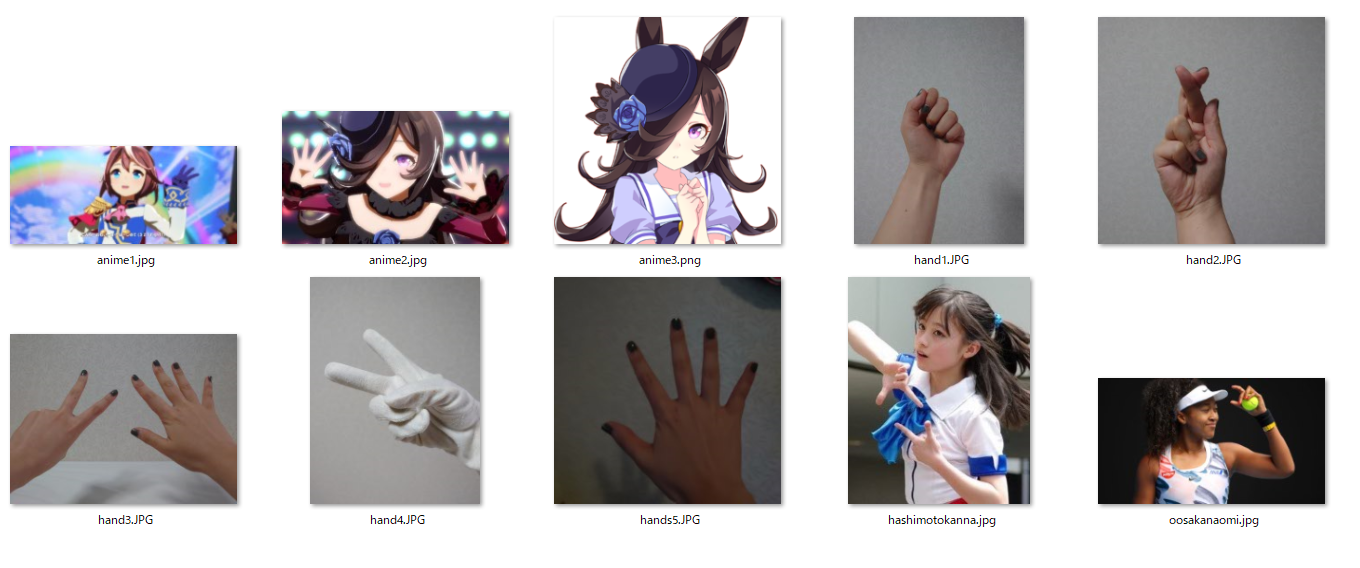
そして以下のようにファイル名のリストを作成し、次々に読み込む準備をします。
IMAGE_FILES = []
for file in os.listdir('./hands/'):
IMAGE_FILES.append('./hands/' + file)
IMAGE_FILES
# --->
# ['./hands/anime1.jpg',
# './hands/anime2.jpg',
# './hands/anime3.png',
# './hands/hand1.JPG',
# './hands/hand2.JPG',
# './hands/hand3.JPG',
# './hands/hand4.JPG',
# './hands/hands5.JPG',
# './hands/hashimotokanna.jpg',
# './hands/oosakanaomi.jpg']
これを使って以下の手順で手の検出を行い、検出できた画像をannotated_handフォルダに保存していきました。
- OpenCVを使ってカラー画像を読み込み、左右反転する。また、色のチャネルの順番をBGRからRGBに変更する。
-
hands.processで手の検出を行い、resultsに保存する。 - 手が検出されない場合は
No Handを表示する。手が検出された場合は左手か右手かどちらかの結果を表示し、画像に検出された地点を描画、annotated_handフォルダに保存する。
for idx, file in enumerate(IMAGE_FILES):
print('file name:', file)
#ファイルを読み込んで左右反転
image = cv2.flip(cv2.imread(file), 1)
#色をRGBにして手の検出を実行
results = hands.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
#手が検出されなければ'No Hand'を表示して次の画像へ
if not results.multi_hand_landmarks:
print('No Hand')
print('-------------------------')
continue
#手が検出された場合は検出ポイントを描画して保存
print('Hand label:', results.multi_handedness)
annotated_image = image.copy()
for hand_landmarks in results.multi_hand_landmarks:
mp.solutions.drawing_utils.draw_landmarks(
annotated_image,
hand_landmarks,
mp.solutions.hands.HAND_CONNECTIONS,
mp.solutions.drawing_styles.get_default_hand_landmarks_style(),
mp.solutions.drawing_styles.get_default_hand_connections_style()
)
cv2.imwrite('./annotated_hand/annotated_hand' + str(idx) + '.jpg', cv2.flip(annotated_image, 1))
print('-------------------------')
コードを実行すると以下のような出力になりました。
file name: ./hands/anime1.jpg
Hand label: [classification {index: 0 score: 0.9999991059303284 label: "Left"}]
-------------------------
file name: ./hands/anime2.jpg
Hand label: [classification {index: 1 score: 0.9847505688667297 label: "Right"},
classification {index: 0 score: 0.979974091053009 label: "Left"}]
-------------------------
file name: ./hands/anime3.png
No Hand
-------------------------
file name: ./hands/hand1.JPG
Hand label: [classification {index: 0 score: 1.0 label: "Left"}]
-------------------------
file name: ./hands/hand2.JPG
Hand label: [classification {index: 1 score: 0.9999518394470215 label: "Right"}]
-------------------------
file name: ./hands/hand3.JPG
Hand label: [classification {index: 0 score: 0.9999997615814209 label: "Left"},
classification {index: 0 score: 0.9835185408592224 label: "Left"}]
-------------------------
file name: ./hands/hand4.JPG
No Hand
-------------------------
file name: ./hands/hands5.JPG
Hand label: [classification {index: 0 score: 0.9993670582771301 label: "Left"}]
-------------------------
file name: ./hands/hashimotokanna.jpg
Hand label: [classification {index: 1 score: 0.9999998807907104 label: "Right"}, classification {index: 1 score: 0.9998670220375061 label: "Right"}]
-------------------------
file name: ./hands/oosakanaomi.jpg
Hand label: [classification {index: 0 score: 0.9999979734420776 label: "Left"}]
-------------------------
出力結果を見ると、写真のうち2つは手が検出されていないことがわかります。検出されなかったのは手袋をつけた自分の手の写真とアニメキャラのイラストです。イラストについてはこの画像以外にも何枚か試しましたがほとんど検出されませんでした。また、annotated_handフォルダには以下のように検出ポイントが描画された写真が保存されています。

いくつかの結果を観察します。

この画像はどちらも左手と判断されています。各指の検出ポイントには誤りがないので、表向きか裏向きかが判断できていないようです。また、左手は隠れている指まで推定して検出することができています!

この画像は人差し指と中指の検出ポイントに誤りがあります。あまりない複雑な手の形をしていると検出ポイントを追うのは難しいのかな、と思います。

この画像では、手袋をしている手の部分は検出されずに肩章の部分が手と判断されてしまっています。色合いと形が似ていると言われれば似ているかもしれません。
結果から感じたこととして、標準的な形をした人の手の画像はちゃん検出することができ、写っていない部分も上手に推定してくれているようです。逆にアニメキャラ、奥行が感じにくい、標準的な肌色でない、などの条件がつくと上手に検出できないようでした。
動画で手を検出する
今度は自分の手の動画と手がわかりやすそうなアニメ動画で検出を行い、検出ポイントを描画して保存しました。検出器をインスタンス化する際に静止画のときと異なるのは以下の2点です。
-
static_image_modeをFalseにする -
min_tracking_confidenceを設定すると、一つ前のフレームで検出された手を追跡するようになります。1に近づけるほど検出に時間はかかりますがよりロバスト性のある検出ができる
cap = cv2.VideoCapture('./hand_movie/hand_movie.mp4')
# 動画を保存するための設定
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
size = (width, height)
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
frame_rate = int(cap.get(cv2.CAP_PROP_FPS))
save = cv2.VideoWriter('./hand_movie/annotated_uma.mp4', frame_count, frame_rate, size)
# 検出器のインスタンス化
hands = mp.solutions.hands.Hands(
static_image_mode=False,
max_num_hands=2,
min_detection_confidence=0.5,
min_tracking_confidence=0.5)
while cap.isOpened():
ret, image = cap.read()
if not ret:
break
image = cv2.cvtColor(cv2.flip(image, 1), cv2.COLOR_BGR2RGB)
results = hands.process(image)
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
mp.solutions.drawing_utils.draw_landmarks(
image,
hand_landmarks,
mp.solutions.hands.HAND_CONNECTIONS,
mp.solutions.drawing_styles.get_default_hand_landmarks_style(),
mp.solutions.drawing_styles.get_default_hand_connections_style())
save.write(cv2.flip(image, 1))
cap.release()
保存された動画を確認してみると自分の手はもちろん、アニメ画像もわりとうまく検出できています!


描画だとわかりにくいですがカメラからの距離も推定できるのがすごいところだと思います。簡単なうえにわかりやすく見れるので実装していて楽しかったです!