はじめに
研究室に所属してからというもの、独学が正義の情報系学問の世界(偏見?)。とりあえず機械学習ライブラリ「PyTorch」の勉強をしなければ…と思い、最近推している日向坂46の顔分類に挑戦しました!下記のように、入力された画像に対して、画像内の人物の名前を特定することを目指します。
| 入力 | 出力 |
|---|---|
 |
 |
| 基本的には、 |
mnist examples(GitHub)
Pytorch Tutorials(Training a Classifier)
機械学習で乃木坂46を顏分類してみた
[乃木坂メンバーの顔をCNNで分類]
(https://qiita.com/nirs_kd56/items/bc78bf2c3164a6da1ded)
を参考にしながら作成して行きます。偉大なる先人達との差別化としては、
- 流行の機械学習ライブラリであるPyTorchの利用
- 遭遇したエラー達
- DeepLearningに対して素人である筆者の奔走
- 乃木坂じゃなくて日向坂
あたりでしょうか。
「とりあえずゼロから作るDeepLeraning(O'REILLY)は読んでみたけど…」みたいな方や「おひさま」の方には刺さるかもしれません。玄人の方は、ゆるゆると読んでくださいね。日向坂で会いましょうは至高。
環境
- macOS Mojave ver 10.14.16(MacBook Pro(2017))
- python 3.7.0
- OpenCV 3.4.2
- PyTorch 1.1.0
環境の確認は、ターミナルを開いて
python
import torch
torch.__version__
で行えます。自分は、Anacondaで構築しているのにpip install XXみたいなことして15分くらい捨てました(そのレベル)
顔分類の手順とディレクトリ構成
顔分類の手順
以下のような手順で行います。
- Google画像検索から分類したいメンバーの画像を収集
- 画像から顔の部分を抽出
- データの水増し(反転処理/閾値処理/ぼかし処理)
- データローダの作成
- モデルの作成・学習
- 新規画像を用いて、学習済みモデルから名前を特定し新規画像に描画
ディレクトリ構成
ディレクトリ構成は以下のようになります。メンバーは、5人で失礼致す。各ファイル、フォルダの意味は追々わかるはずです。
.
├── __pycache__
│ ├── my_dataset.cpython-37.pyc
│ └── network.cpython-37.pyc
├── cut_face.py
├── data
│ ├── 丹生明里
│ ├── 富田鈴花
│ ├── 松田好花
│ ├── 河田陽菜
│ └── 金村美玖
├── detect_hinatazaka.py
├── face_data
│ ├── 丹生明里
│ ├── (…)
├── her_name_is
│ ├── IMG_1196.jpg
│ ├── (…)
├── hinatazaka_cnn.pt
├── main.py
├── make_dataset2.py
├── make_test_train.py
├── my_dataset.py
├── network.py
├── progress
│ ├── test_accuracy.png
│ ├── test_loss.png
│ └── train_loss.png
├── test_data
│ ├── 丹生明里
│ ├── (…)
├── train_data
│ ├── 丹生明里
│ ├── (…)
└── who_is_this_member?
├── IMG_1196.jpg
├── (…)
1.Google画像検索から分類したいメンバーの画像を収集
API を叩かずに Google から画像収集をする
これです。先人に感謝を。最初はGoogleCustomSearchを使ってみたんですが、無料では一人の画像を100枚収集した時点で制限がかかってしまいました。自分は、image_collecter.pyをコピーさせて貰ってmake_dataset2.pyに貼り付けて使っています。以下のコマンドでにぶちゃんの画像を500枚収集できます。
python make_dataset2.py -t 丹生明里 -n 500
画像は、[./data/各メンバー]ディレクトリに格納されます。
2.画像から顔の部分を抽出
続いて、収集した画像から顔の部分を抽出します。余計な情報をモデルに学習させないためです。顔の抽出には、カスケード分類機を利用します。顔を抽出した後、モデルを通過させる画像のサイズ(64*64)にリサイズして[./face_data/各メンバー]ディレクトリにひたすら保存して行きます。


カスケード分類機ってなんぞや
結局は顔が存在する画像(正例)と存在しない画像(負例)の特徴を学習させる機械学習です。正面から見た顔の中で、例えば鼻筋は鼻側面に比べて明るかったり、目は頬(すぐ下の)より暗かったりするという特性を学習することで、この部分が顔なのかを判断しています。また、このようにいくつかの判断基準を設けているため、Cascade(多段フィルタ)分類という名称が付いています。厳密には、Haar-like特徴量の話から始めないといけないとは思いますが…
cascade分類はopencvを用いて簡単に行えます。cv2.CascadeClassifier()にhaarcascade_frontalface_alt.xmlのディレクトリを渡してあげれば、CascadeClassifierクラス内のdetectMultiScale()関数が利用できます。xmlは自分のPCの中をfindコマンドでひたすら捜索。この関数は、画像内の顔の部分を四角形で囲み、その四角形の左上角の座標、幅、高さの4つの値を返してくれます。顔が複数ある場合は、顔毎に4つの値をリストに入れてくれます。
さて、当然他の日向坂メンバーとのツーショットもgoogle画像検索ではヒットするはずなので、[./face_data/河田陽菜]ディレクトリには濱岸ひよりの顔画像も含まれてしまいますね。これらは、ひたすら手動でカットして行きます。別人の画像に加えて横顔や顔の一部しか写ってない画像もカットしましょう。メンバーの集合写真に遭遇して絶望したり、オードリー春日さんの画像が出てきて少し和んだりなんかしたりして。そんなこんなで、メンバー1人当たりに顔が250枚ほど集まりました。す、少ない…!
コードは以下です。osモジュールやglobモジュールを使ってみたくてこんな設計になりました。便利ですね。
cut_face.py
import numpy as np
import cv2
import os
import glob
in_dir="./data/*" # 入力用のディレクトリ
out_dir="./face_data/" # 出力用(顔だけ画像)のディレクトリ
in_jpg=glob.glob(in_dir) # [./data/各人物]のリスト
in_jpg_member=[]
for i in range(len(in_jpg)):
in_jpg_member.append(glob.glob(in_jpg[i]+"/*")) # [./data/各人物/XXX.jpg]のリスト
in_fileName=os.listdir("./data") # 各人物のリスト
for member_num in range(len(in_fileName)):
OutputPath=out_dir+"/"+in_fileName[member_num]
if not os.path.exists(OutputPath):
os.makedirs(OutputPath)
#print(len(in_fileName))
#print(in_fileName)
#print(member_num)
for num in range(len(in_jpg_member[member_num])):
image=cv2.imread(in_jpg_member[member_num][num])
if image is None:
print("Not open:")
continue
image_gs=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
cascade=cv2.CascadeClassifier("/Users/shimo/.pyenv/versions/anaconda3-5.3.1/share/OpenCV/haarcascades/haarcascade_frontalface_alt.xml")
#cascade=cv2.CascadeClassifier("/usr/local/Cellar/opencv/4.1.2/share/opencv4/haarcascades/haarcascade_frontalface_alt.xml")
# ↑findかけた時にxmlが二つあったので両方試してみた。こっちはハズレ。
face_list=cascade.detectMultiScale(image_gs, scaleFactor=1.1, minNeighbors=2,minSize=(64,64))
count=0
if len(face_list)>0:
for rect in face_list:
count+=1
x,y,width,height=rect
print(x,y,width,height)
image_face=image[y:y+height,x:x+width]
if image_face.shape[0]<64:
continue
image_face = cv2.resize(image_face,(64,64))
fileName=os.path.join(out_dir+str(in_jpg_member[member_num][num][7:-4])+"_"+str(count)+".jpg")
print(fileName)
cv2.imwrite(str(fileName),image_face)
else:
print("no face")
continue
さて、ここで苦しめられた事件が一つ。 #### .DS_Store邪魔すぎ問題 cut_face.pyの実行中に下記のエラーに遭遇しました。
Traceback (most recent call last):
File "cut_face.py", line 28, in <module>
for num in range(len(in_jpg_member[member_num])):
IndexError: list index out of range
エラー内容は、単純ですね。listにおいて存在しない要素にアクセスしようとしてしまっているということです。そのlistはというと、[./data]ディレクトリの中身から作られるlistのようです。そこでFinderでdataフォルダの中身をのぞいて見ることにしました。異常なし、だと…?余計なファイルが含まれているということもなかったのです。そこでlistをプリントデバッグしていくと、何やら[./data/.DS_Store]というディレクトリが存在する模様…。さっきなかったよな?なんと、このディレクトリは、ターミナルからでしか見つからないものだったのです。色々調べているとMacの仕様上、os.makedirsで新しいディレクトリを作るときに勝手に作られるみたいです。.DS_Storeが作成されないようにする方法を色々と試したのですが、結局根本的な解決には至らず、rmコマンドで.DS_Storeを削除することでことなきを得ました。
.DS_Storeは、後述するmain.pyの実行中にも悪さをすることがあります。その時のエラー内容はこちら。
Traceback (most recent call last):
File "main.py", line 115, in <module>
main()
File "main.py", line 77, in main
train_loss_perEpoch = train(args,model,trainloader,criterion,optimizer,epoch)
File "main.py", line 25, in train
for batch_idx,(data,target) in enumerate(train_loader):
File "/Users/shimo/.pyenv/versions/anaconda3-5.3.1/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 582, in __next__
return self._process_next_batch(batch)
File "/Users/shimo/.pyenv/versions/anaconda3-5.3.1/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 608, in _process_next_batch
raise batch.exc_type(batch.exc_msg)
AttributeError: Traceback (most recent call last):
File "/Users/shimo/.pyenv/versions/anaconda3-5.3.1/lib/python3.7/site-packages/torch/utils/data/_utils/worker.py", line 99, in _worker_loop
samples = collate_fn([dataset[i] for i in batch_indices])
File "/Users/shimo/.pyenv/versions/anaconda3-5.3.1/lib/python3.7/site-packages/torch/utils/data/_utils/worker.py", line 99, in <listcomp>
samples = collate_fn([dataset[i] for i in batch_indices])
File "/Users/shimo/Documents/DeepLearning/face_ditectのコピー/my_dataset.py", line 35, in __getitem__
img=Image.fromarray(img)
File "/Users/shimo/.pyenv/versions/anaconda3-5.3.1/lib/python3.7/site-packages/PIL/Image.py", line 2453, in fromarray
arr = obj.__array_interface__
AttributeError: 'NoneType' object has no attribute '__array_interface__'
こちらは、cv2.imreadが上手くいっていないときに出るエラーとのこと。
色々と調べてみると、[train_data/各メンバー]ディレクトリのなかに、'.DS_0_1.jpg'、'.DS_0_2.jpg'、'.DS_0_3.jpg'といったお邪魔トリオが存在。データの水増し段階で名前まで変更されてさらに発見しずらくなってました。無論rmコマンドで突破できます。
3.データの水増し(反転処理/閾値処理/ぼかし処理)
face_data内のデータを単純にtraining用データとtest用データに分配すると流石にデータ数が心もとない。そこでデータの水増し(augmentation)を行います。opencvが全部やってくれます。これでデータ数は4倍!なお、水増しを行うのはtraining用のデータだけですので、水増し前にtraining用とtest用にデータを分配しておきます。
| オリジナル画像 |
|---|
 |
| 反転処理 | 閾値処理 | ぼかし処理 |
|---|---|---|
 |
 |
 |
この部分は、機械学習で乃木坂46を顏分類してみたのコーディングがすごくかっこよくて結構似ちゃってます。True/Falseを使ってリストを取捨選択できるように設計しているところが美しい。以下の部分です(make_test_train.pyより抜粋)。func変数へaugmentation配列のTrueの要素だけが読み出され、ループして行きます。
for func in augmentation[methods]:
images.append(func(img))
コード全体は以下です。
make_test_train.py
import numpy as np
import cv2
import os
import glob
import shutil
import random
if not os.path.exists("./train_data"):
shutil.copytree("./face_data","./train_data")#./face_dataを./train_dataにコピー
in_dir="./train_data/*"
out_dir="./test_data/"
member_dir=glob.glob(in_dir)
def augmentation_image(img,flip=True,thr=True,filt=True):
methods=[flip,thr,filt]
augmentation = np.array([
lambda x: cv2.flip(x,1),
lambda x: cv2.threshold(x,100,255,cv2.THRESH_TOZERO)[1],
lambda x: cv2.GaussianBlur(x,(5,5),0)
])#上から、反転処理、閾値処理、ぼかし処理
images=[]
for func in augmentation[methods]:
images.append(func(img))
return images
# test datasetを抜き出し
for num1 in range(len(member_dir)):
temp_image_list=os.listdir(member_dir[num1])
random.shuffle(temp_image_list)#listのshuffle
temp_member_name=member_dir[num1].split("/")[-1]
TEST_PATH=out_dir+temp_member_name
if not os.path.exists(TEST_PATH):
os.makedirs(TEST_PATH)
#train:10→train:8,test:2
for i in range(int((len(temp_image_list))/5)):
shutil.move(str(member_dir[num1]+"/"+temp_image_list[i]),TEST_PATH)
for num2 in range(len(member_dir)):
temp_image_list2=os.listdir(member_dir[num2])
for p in range(len(temp_image_list2)):
TRAIN_IMAGE_PATH=os.path.join(member_dir[num2]+"/"+temp_image_list2[p])
img=cv2.imread(TRAIN_IMAGE_PATH)
#print(img.shape)
augmentation_face_image=augmentation_image(img)
for method in range(len(augmentation_face_image)):
AUGMENTATION_PATH=os.path.join(TRAIN_IMAGE_PATH[:-4]+"_"+str(method)+".jpg")
cv2.imwrite(AUGMENTATION_PATH,augmentation_face_image[method])
4.データローダの作成
割とこの章がキモと言えるかもしれません。PyTorchなら簡単に「データの前処理」と「データセットのロード」を行うことができます。transforms・Dataset・Dataloaderのモジュールを正しく定義することができれば…ですが。各モジュール毎に見て行きます。
transforms
データの前処理を行うモジュールです。画像に関する前処理は、torchvision.transformsにまとまっているので、それをimportすれば記述も簡単です。行いたい前処理の内容をtransforms.Compose()にまとめて記載し、Datasetモジュールに引数として渡します。下記の例は、前処理として画像をTensor型に直すこと(PyTorchでは、numpy配列をネットワークに通すことはできません)と画像の明るさの正規化を行なうことを示しています(main.pyより抜粋)。
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
Dataset
データとそれに対応するラベルを1組返すモジュールです。後述するDataLoaderモジュールを使うためには、Datasetクラスの実装が必要です。MNISTやCIFAR10といった有名なデータセットのクラスは、torchvision.datasetsにあらかじめ実装されています。自前のデータを使う場合は、規則に沿って自作Datasetクラスを作る必要があります。規則は、下記の3つです。
- torch.utils.data.Datasetの継承
- __len__(self)の実装
- __getitem__(self,index)の実装
__len__(self)は、全体のデータの個数を返す関数、__getitem__(self,index)は、指定されたindexのデータと対応するラベルを返す関数です。getitemに関しては、index用の引数がマストです。
以下が自作の日向坂Datasetクラスになります。相変わらずディレクトリ関係がややこしいですね…。コンストラクタでは、指定されたディレクトリ内の画像を1枚づつ読み出してself.dataリストに追加、加えてその画像の人物に対応した数字(5人なので0~4。富田鈴花の画像なら0みたいな感じです。)をラベルとしてself.targetsリストに追加しています。続いて、先ほどの役割通りにlen、getitemを定義しています。データの前処理は、getitem関数内で行なっています。今回の前処理内容に関しては、データの形式をnumpyからPILに変換する必要はないですが、結構変換してる実装例を見かけたのでPIL変換してみました。
my_dataset.py
import torch
import os
import glob
import cv2
from PIL import Image
class Mydataset(torch.utils.data.Dataset):
def __init__(self,root,transform=None):
self.root=root#./train_data or ./test_data
self.transform=transform
self.data=[]
self.targets=[]
member_dir=glob.glob(self.root+"/*")
print(len(member_dir))
print(member_dir)
for member in range(len(member_dir)):
image_list=os.listdir(member_dir[member])
print(member_dir[member])
for i in range(len(image_list)):
if 'DS' in image_list[i]:
print(image_list[I])#.DS_Storeを検知できるように
for num in range(len(image_list)):
IMAGE_PATH=os.path.join(member_dir[member]+"/"+image_list[num])
#print(IMAGE_PATH)
self.data.append(cv2.imread(IMAGE_PATH))
#ラベルは、富田:0,金村:1,松田:2,丹生:3,河田:4
self.targets.append(member)
if type(self.data[num]) == type(None):
print(IMAGE_PATH)
def __len__(self):
return len(self.data)
def __getitem__(self,index):
img,target=self.data[index],self.targets[index]
img=Image.fromarray(img)#numpyからPILに
if self.transform is not None:
img=self.transform(img)
return img,target
DataLoader
データをバッチ毎にまとめて返すモジュールです。あらかじめ実装されているtorch.utils.data.Dataloaderクラスを使うだけです。先ほど定義した自作Datasetクラス、バッチサイズを引数とします。また、様々なオプションがあり、例えば、shuffleによってデータのシャッフルを行うかどうか、num_workersによって使用するpcのコア数を指定できます。下記が実装例です(main.pyより抜粋)。
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=64,shuffle=True, num_workers=2)
参考になる偉大な先人。 [PyTorch transforms/Dataset/DataLoaderの基本動作を確認する](https://qiita.com/takurooo/items/e4c91c5d78059f92e76d)
5.モデルの作成・学習
今回は、下記のようなモデルを設計します。入力はtorch.size([64,3,64,64])のデータ(バッチサイズ:64、チャネル数:3(RGB)、画像サイズ:64*64)、出力はtorch.size([64,5])のデータです。
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 6, 60, 60] 456
MaxPool2d-2 [-1, 6, 30, 30] 0
Conv2d-3 [-1, 16, 26, 26] 2,416
MaxPool2d-4 [-1, 16, 13, 13] 0
Conv2d-5 [-1, 32, 10, 10] 8,224
Dropout2d-6 [-1, 32, 10, 10] 0
Linear-7 [-1, 120] 384,120
Linear-8 [-1, 84] 10,164
Linear-9 [-1, 5] 425
================================================================
Total params: 405,805
Trainable params: 405,805
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.05
Forward/backward pass size (MB): 0.36
Params size (MB): 1.55
Estimated Total Size (MB): 1.95
----------------------------------------------------------------
例えば、本実装例では、松田好花のラベルは'2'となっているので、出力される[0]~[4]の5つの要素の中で[2]の要素の値が一番大きくなるようにモデル内の重みを最適化していくわけですね。厳密には、交差エントロピー誤差(損失関数)をネットワークに対して逆伝播することで損失関数の勾配を求め、勾配降下法で損失関数が最小になるようにパラメータを更新して行きます。パラメータの更新手法にはAdamを用いることとします。
以下に、モデル、mainのコードをまとめて示します。
network.py
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1=nn.Conv2d(3,6,5)
self.pool=nn.MaxPool2d(2,2)
self.conv2=nn.Conv2d(6,16,5)
self.conv3=nn.Conv2d(16,32,4)
self.dropout=nn.Dropout2d()
self.fc1 = nn.Linear(32 * 10 * 10, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 5)
def forward(self,x):
x=F.relu(self.conv1(x))
x=self.pool(x)
x=F.relu(self.conv2(x))
x=self.pool(x)
x=F.relu(self.conv3(x))
x=self.dropout(x)
x=x.view(-1,32*10*10)
x=F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
x=self.fc3(x)
return x
main.py
import torch
import torchvision
import torchvision.transforms as transforms
import os
import argparse
from my_dataset import Mydataset
from network import Net
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchsummary import summary
import matplotlib.pyplot as plt
def parser():
parser =argparse.ArgumentParser(description='Pytorch_Hinatazaka')
parser.add_argument('--epochs','--e',type=int,default=2,help='number of epochs to train (default: 2)')
parser.add_argument('--lr','--l',type=float,default=0.001,help='learning rate (default: 0.001)')
parser.add_argument('--save-model', action='store_true', default=False,help='For Saving the current Model')
args = parser.parse_args()
return args
# training用の関数
def train(args,model,train_loader,criterion,optimizer,epoch):
model.train()
running_loss=0.0
for batch_idx,(data,target) in enumerate(train_loader):
optimizer.zero_grad()#Adam初期化
output=model(data)#model出力
loss=criterion(output,target)#交差エントロピー誤差
loss.backward()#逆誤差伝搬
optimizer.step()#Adam利用
running_loss+=loss.item()
if batch_idx%5==4:
print('[%d,%5d] loss:%.3f'%(epoch,batch_idx+1,running_loss/5))
train_loss=running_loss/5
running_loss=0.0
return train_loss
# test用の関数
def test(args,model,test_loader,criterion):
model.eval()
test_loss=0
correct=0
with torch.no_grad():
for data,target in test_loader:
output=model(data)
test_loss += criterion(output,target).item()
pred=output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = correct / len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * accuracy))
return test_loss,accuracy
def main():
args=parser()
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])#transforms
trainset=Mydataset(root='./train_data',transform=transform)#Dataset
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,shuffle=True, num_workers=2)#Dataloader
testset=Mydataset(root='./test_data',transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64,shuffle=True, num_workers=2)
model=Net()#modelの定義
summary(model,(3,64,64))#modekを出力する便利ツール
criterion=nn.CrossEntropyLoss()#lossの定義
optimizer=optim.Adam(model.parameters(),lr=args.lr)#optimizerの定義
#以下でtrain loss、test loss、test accuracyをグラフ化できるように設定
x_epoch_data=[]
y_train_loss_data=[]
y_test_loss_data=[]
y_test_accuracy_data=[]
for epoch in range(1,args.epochs+1):
train_loss_perEpoch = train(args,model,trainloader,criterion,optimizer,epoch)
test_loss_perEpoch,test_accuracy_perEpoch = test(args,model,testloader,criterion)
x_epoch_data.append(epoch)
y_train_loss_data.append(train_loss_perEpoch)
y_test_loss_data.append(test_loss_perEpoch)
y_test_accuracy_data.append(test_accuracy_perEpoch)
plt.plot(x_epoch_data,y_train_loss_data,label='train_loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(loc='upper right')
plt.show()
plt.plot(x_epoch_data,y_test_loss_data,label='test_loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(loc='upper right')
plt.show()
plt.plot(x_epoch_data,y_test_accuracy_data,label='test_accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(loc='lower right')
plt.show()
if (args.save_model):
torch.save(model.state_dict(),"hinatazaka_cnn.pt")#args.save_modelがTrueなら最適化されたモデルを保存
if __name__ == '__main__':
main()
さて、ここでいくつか問題が発生します。上記に記載してあるコード達は正しく修正されたコードですので悪しからず。
nn.CrossEntropyLoss()について
遭遇したエラーはこちら。
Traceback (most recent call last):
File "main.py", line 117, in <module>
main()
File "main.py", line 79, in main
train_loss_perEpoch = train(args,model,trainloader,criterion,optimizer,epoch)
File "main.py", line 28, in train
loss=criterion(output,target)
File "/Users/shimo/.pyenv/versions/anaconda3-5.3.1/lib/python3.7/site-packages/torch/nn/modules/module.py", line 493, in __call__
result = self.forward(*input, **kwargs)
File "/Users/shimo/.pyenv/versions/anaconda3-5.3.1/lib/python3.7/site-packages/torch/nn/modules/loss.py", line 942, in forward
ignore_index=self.ignore_index, reduction=self.reduction)
File "/Users/shimo/.pyenv/versions/anaconda3-5.3.1/lib/python3.7/site-packages/torch/nn/functional.py", line 2056, in cross_entropy
return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
File "/Users/shimo/.pyenv/versions/anaconda3-5.3.1/lib/python3.7/site-packages/torch/nn/functional.py", line 1871, in nll_loss
ret = torch._C._nn.nll_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
RuntimeError: multi-target not supported at /Users/distiller/project/conda/conda-bld/pytorch_1556653464916/work/aten/src/THNN/generic/ClassNLLCriterion.c:20
意味不明!!!!!!!!!!
ググってみても大量の英語の記事を読まされるのみ。もう頭の中ぐるぐるピーマン君です。multi-targetって何やねん…。
結構ハマりましたが、英文を読んでいると、どうやらCrossEntropyLoss()で問題が起きてるらしいということにたどり着きます。
結局問題は、my_dataset.pyにおける正解ラベルのつけ方でした。如何せん自作のデータセットを使っているので、データに対するラベルの付け方は自分次第です。自分はてっきり、松田好花の画像に対しては、int型の整数'2'をラベルにするのではなくて、numpy配列の'[0,0,1,0,0]'をラベルにしなければいけないと思っていたんですね。だって、交差エントロピー誤差ってそういう計算するじゃん…。答えを見ると単純なのですが、割と真剣に悩みました。
test accuracyが上がらない
main.pyを最初に実行した時の結果は以下のようになりました。
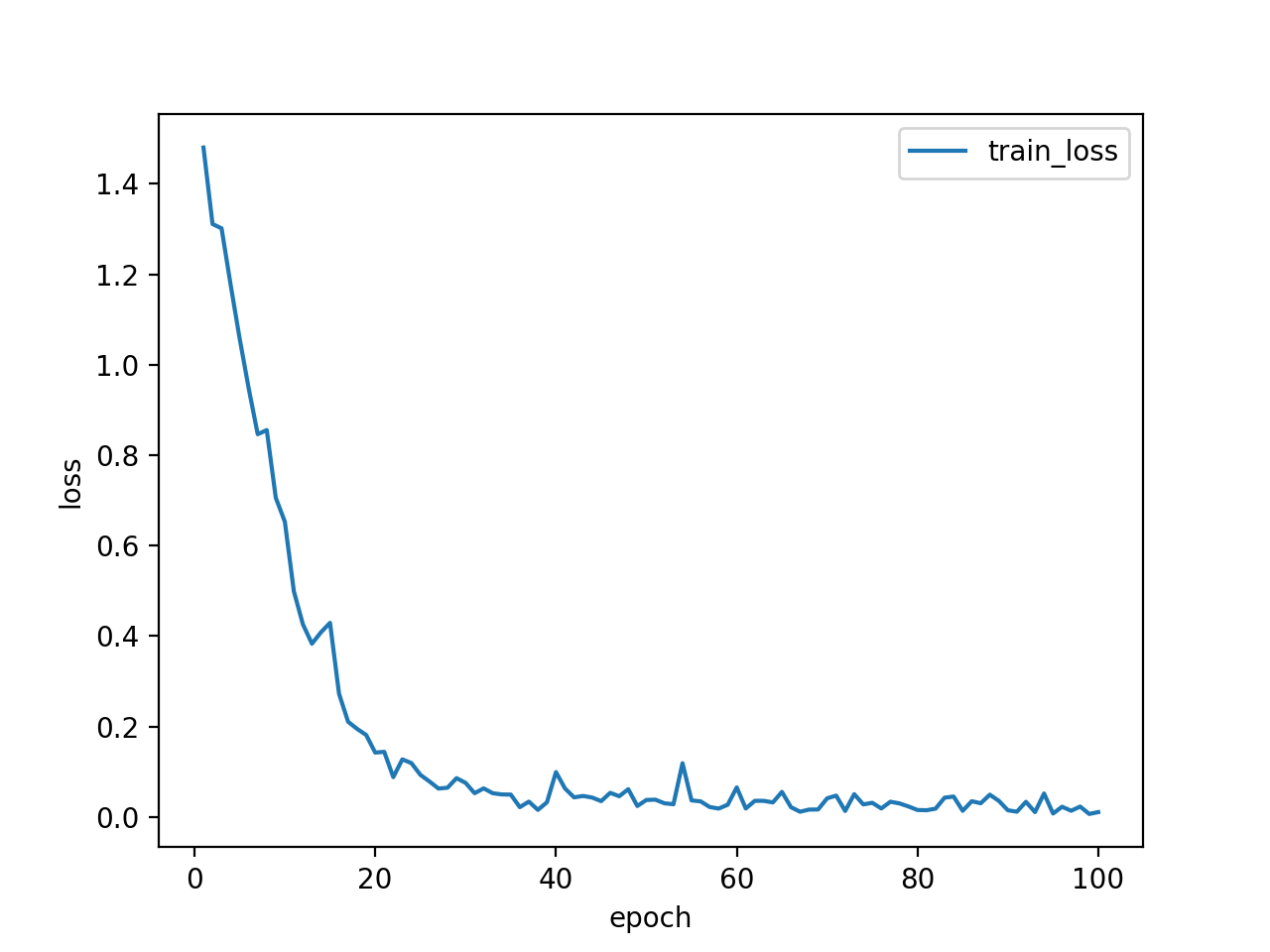
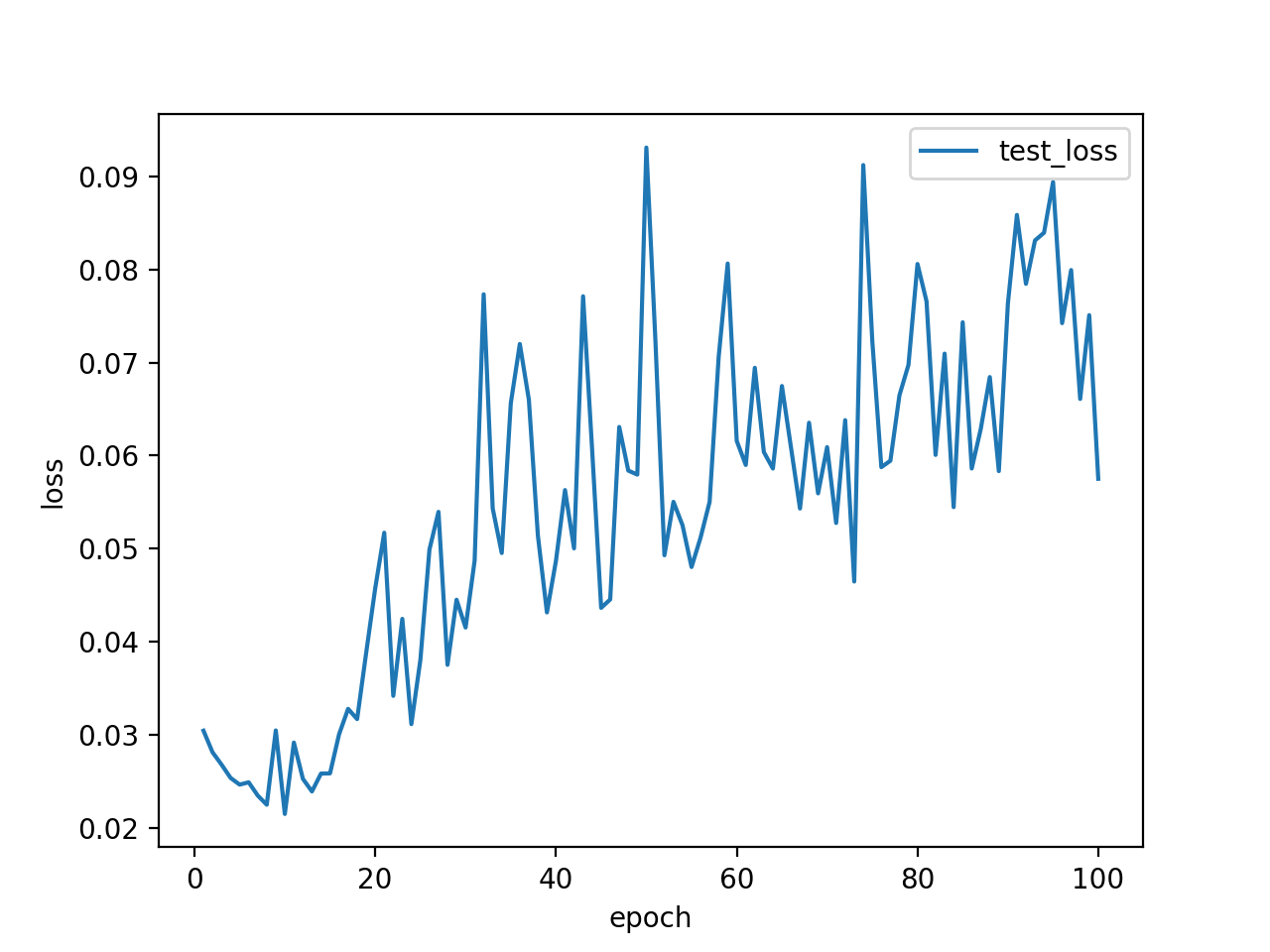
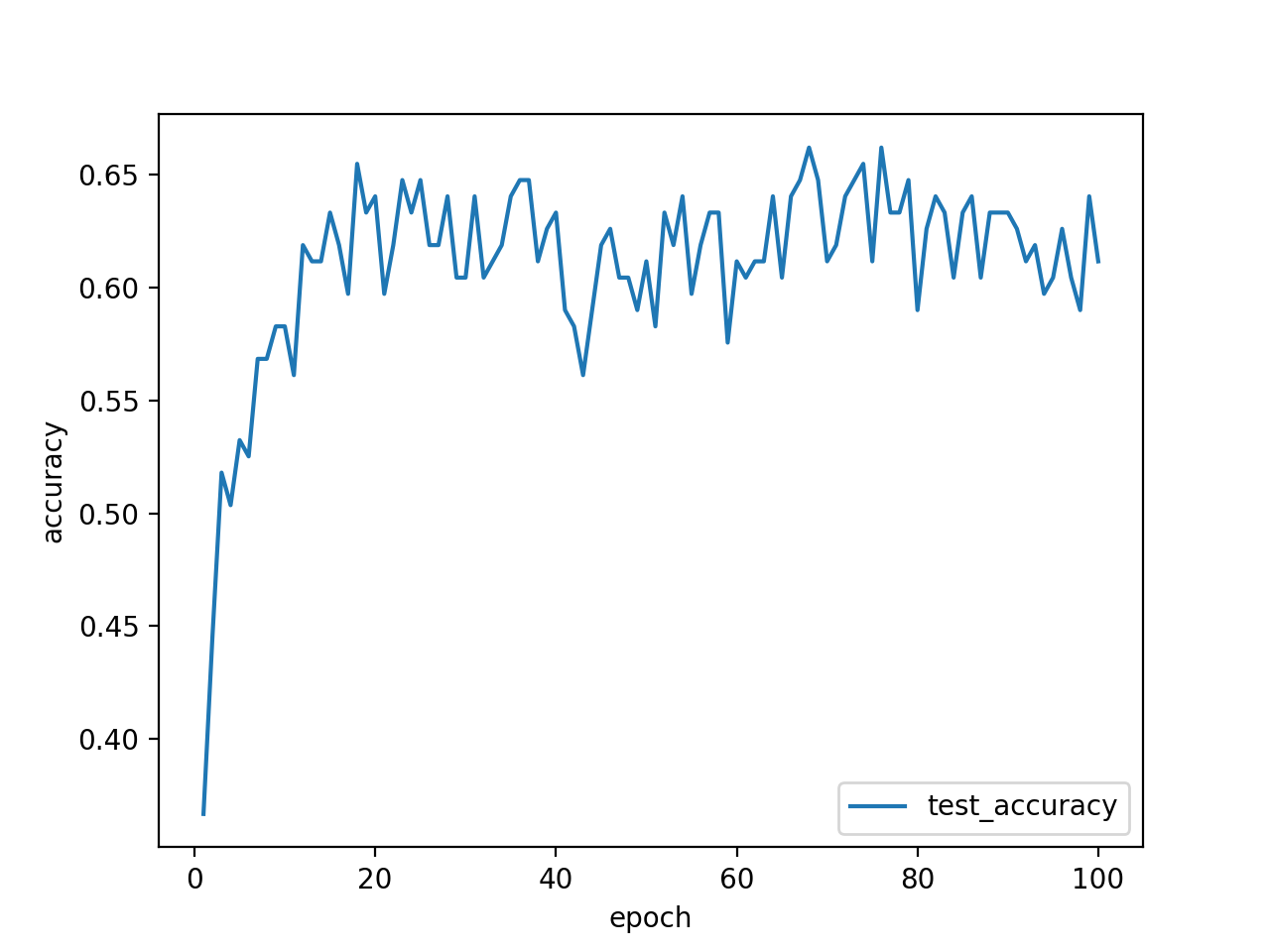
train lossが順調に下がり、「良かったんじゃない?今日も、みんな。イイね!」と思ったのもつかの間。test lossは上がるし、test accuracyは60%程度という残念な結果に。しかも、何度か実行してみると、train lossが下がらない時まである始末。
さて、まずはデータ数を増やしてみます。実は元々google画像検索から引っ張ってくる画像の枚数を一人あたり200にしていたので、200→500に。データ選別がものすごくだるい…。その結果、test accuracyが3%くらい上がりました。test lossは相変わらず上昇です。ダメじゃん。
ここで、クロスエントロピー誤差の特性上、test lossが上昇してもtest accuracyが上昇することはあるということに気づきます。あくまで正解ラベルとモデルから出力される配列の最大値の要素番号が等しければ分類成功するので、例えば正解ラベルが'2'の時、出力が[1,2,5,4,1]でも[1,2,100,4,1]でも分類成功となりaccuracyは1ですからね。ということで、問題はtest accuracyが低いということです。
結局問題は、学習率でした。学習率を0.01→0.001にした結果は以下の通りです。まずいじるべきパラメータはこれだったのか…。ちなみに、学習率を0.0001にするとtest accuracyは、0.001より悪くなりました。大きすぎても小さすぎてもダメなようです。
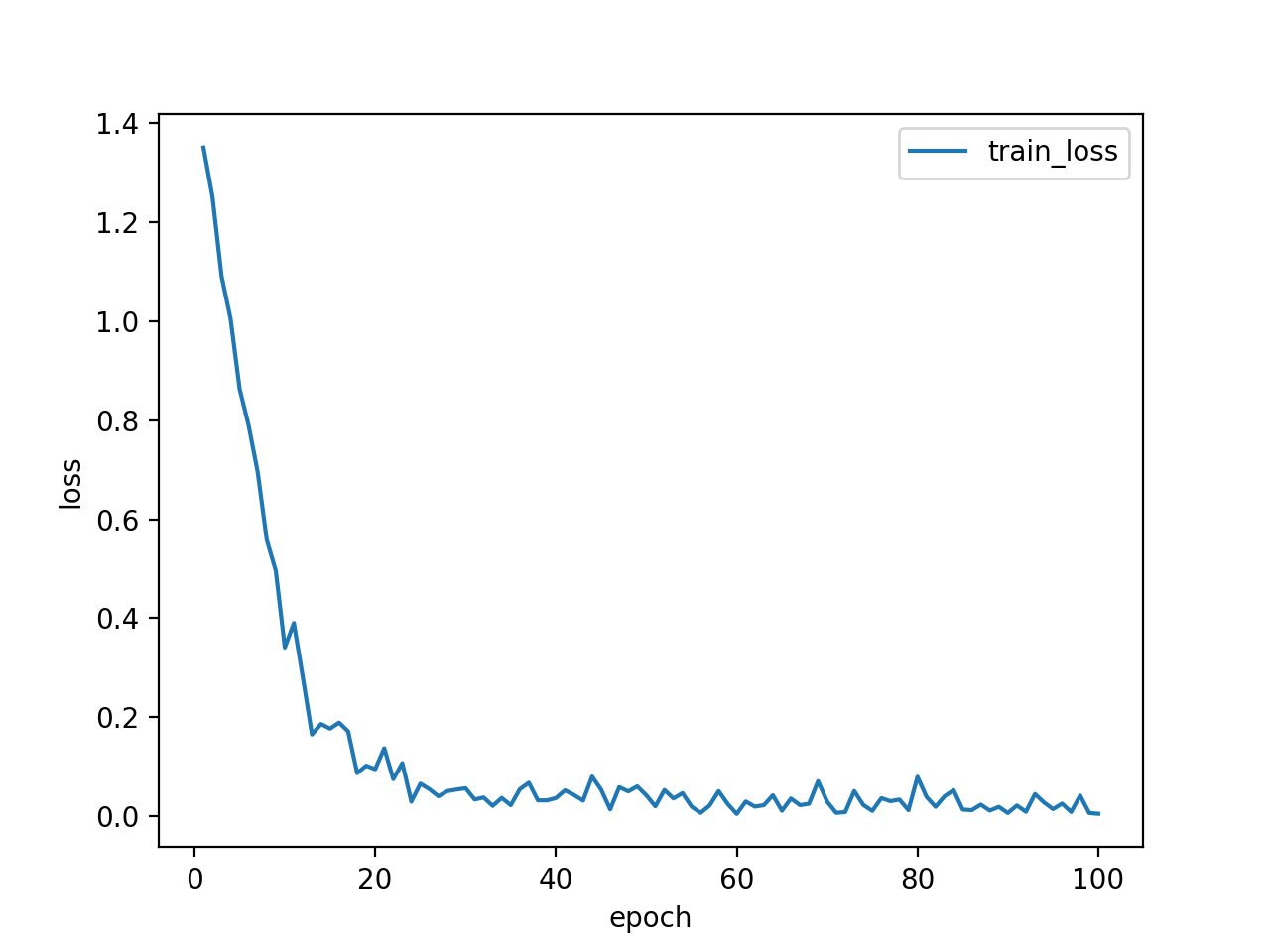
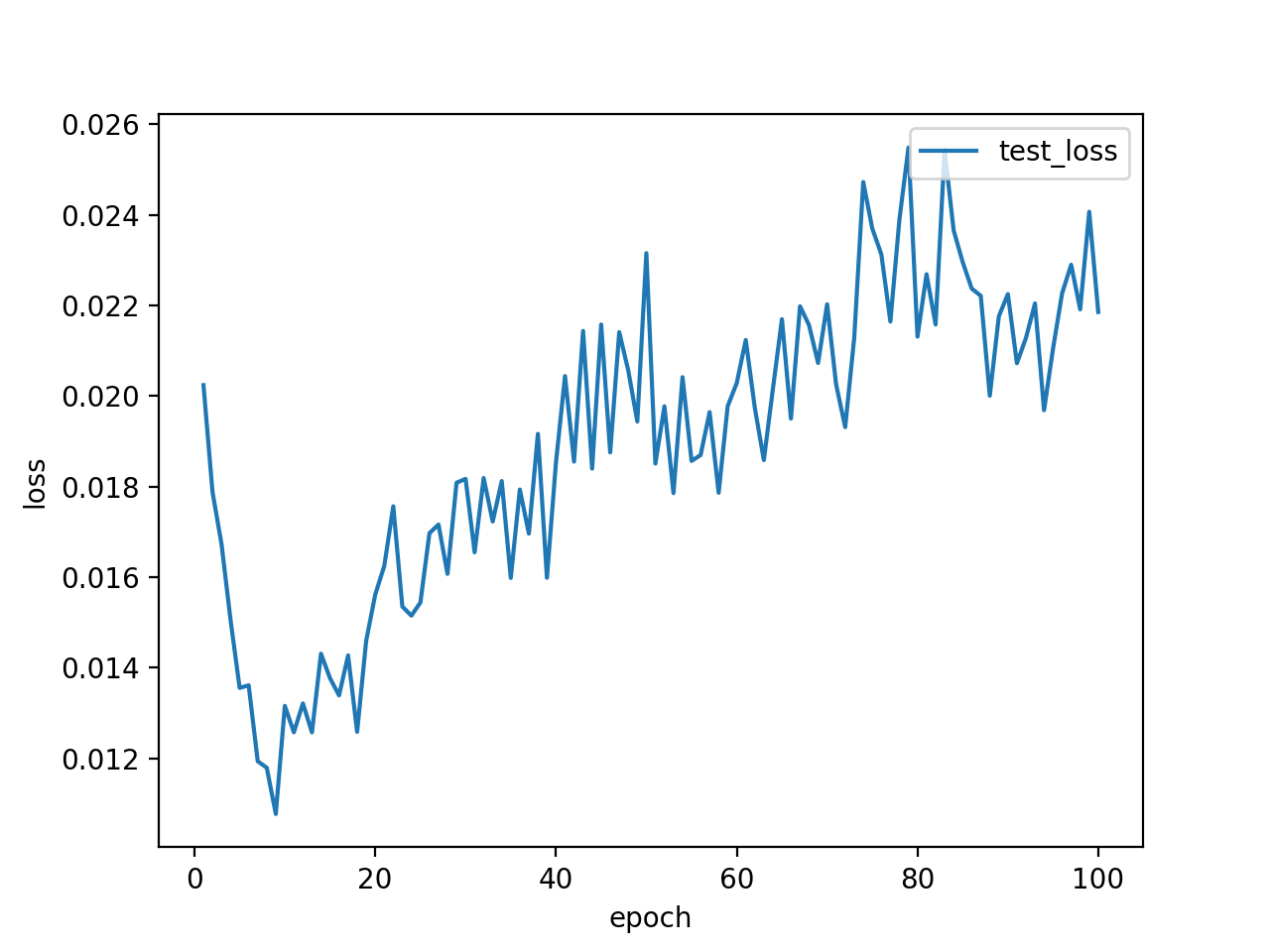
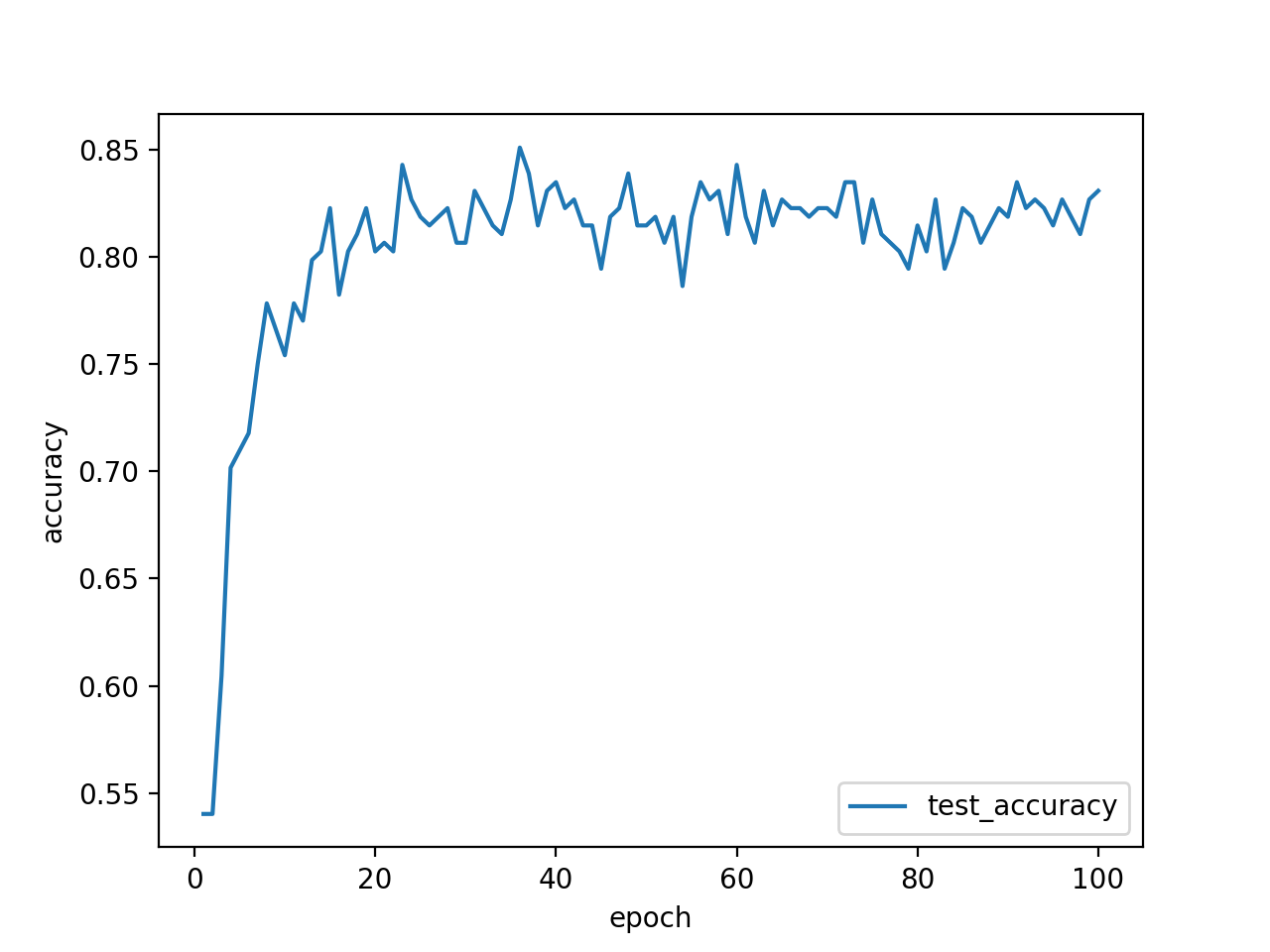
test accuracy80%!!!イイね!!!!!!!!!
6. 新規画像を用いて、学習済みモデルから名前を特定し新規画像に描画
いよいよ最終章です。先ほど学習がうまくいった時のモデルは丸ごと保存してあるので、それを使って顔分類をしていきます。TrainingにもTestにも用いていない日向坂メンバー画像に対して、カスケード分類を行なって顔を抽出し、その画像のモデル出力からメンバーを特定します。その後、元画像に顔の場所と名前を描画します。
以下にコードを示します。注意しなければならないことは、画像を1枚づつモデルに通すということは、あくまでバッチサイズ1の画像をモデルに通すということです。torch.size([3,64,64])ではなくて、torch.size([1,3,64,64])でないといけないということですね。
実際に分類したい画像を[./who_is_this_member?]ディレクトリに入れてください。実行結果は、[./her_name_is]ディレクトリに出力されます。
detect_hinatazaka.py
import torch
import numpy as np
import matplotlib.pyplot as plt
from network import Net
import cv2
import os
import glob
from torchsummary import summary
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
# 画像中の人物を四角で囲んで、名前を追記して返す関数
def detect_who(IMAGE_PATH,model):
image=cv2.imread(IMAGE_PATH)
if image is None:
print("Not open:")
image_gs=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
cascade=cv2.CascadeClassifier("/Users/shimo/.pyenv/versions/anaconda3-5.3.1/share/OpenCV/haarcascades/haarcascade_frontalface_alt.xml")
face_list=cascade.detectMultiScale(image_gs, scaleFactor=1.1, minNeighbors=2,minSize=(64,64))
count=0
if len(face_list)>0:
for rect in face_list:
count+=1
x,y,width,height=rect
print(x,y,width,height)
image_face=image[y:y+height,x:x+width]
if image_face.shape[0]<64:
continue
image_face = cv2.resize(image_face,(64,64))
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
image_face = transform(image_face)
image_face = image_face.view(1,3,64,64)
#print(image_face.shape)
output=model(image_face)
member_label=output.argmax(dim=1, keepdim=True)#model出力の中で要素の値が最大となる要素番号がメンバーのラベルとなる
name = label2name(member_label)#ラベルから人物を特定
print(output)
cv2.rectangle(image, (x,y), (x+width,y+height), (255, 0, 0), thickness=3)#四角形描画
cv2.putText(image,name,(x,y+height+20),cv2.FONT_HERSHEY_DUPLEX,1,(255,0,0),2)#人物名記述
else:
print("no face")
return image
# ラベルから名前を特定する関数。別のデータセットで分類を行う場合は、この部分を変更する必要あり。
def label2name(member_label):
if member_label==0:
name='Party People'
elif member_label==1:
name='Kanemura Miku'
elif member_label==2:
name='Matuda Konoka'
elif member_label==3:
name='Nibu Akari'
elif member_label==4:
name='KAWADA Hina'
return name
def main():
#保存済みのmodelのロードは次の3行で行うことができる
model = Net()
model.load_state_dict(torch.load('hinatazaka_cnn.pt'))
model.eval()
summary(model,(3,64,64))
path_list = glob.glob('who_is_this_member?/*')
print(path_list)
out_dir='./her_name_is'
if not os.path.exists(out_dir):
os.makedirs(out_dir)
for path in path_list:
image_name=path.split('/')[-1]
Who = detect_who(path,model)
SAVE_PATH=os.path.join(out_dir+'/'+image_name)
cv2.imwrite(SAVE_PATH,Who)
if __name__ == "__main__":
main()
ちょっとした問題として、新規画像をどうやって取得する?というのがあります。そもそもGoogle画像検索からデータを集めてしまっているので。あ、3rdSingle特典映像「日向の休日」の画像ならネットに上がってないかも。おい全type必要じゃないか…。みなさん、これを買うしかない!後々、日向坂で会いましょう最新話で十分ということに気づきますが、時すでにお寿司。まぁ研究必要経費だよね!!
結果
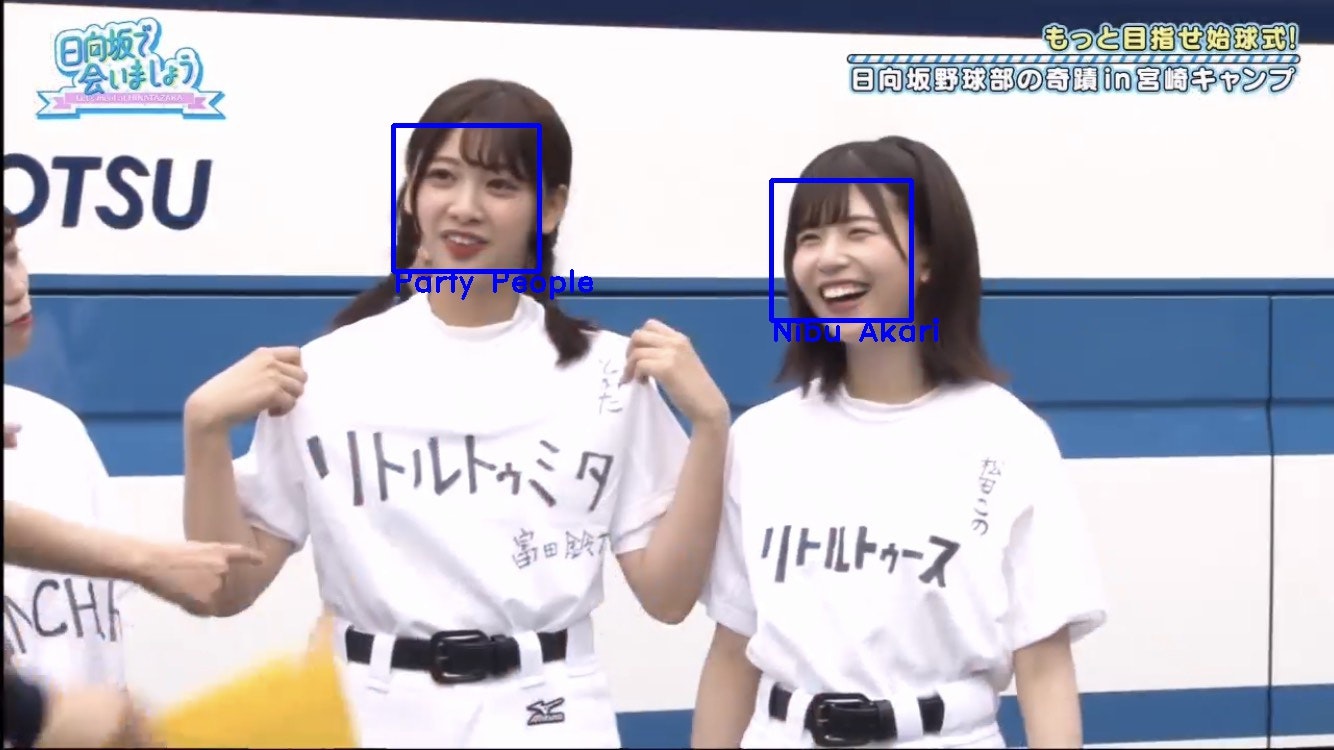
以下に結果を示します。無論、5人しか学習させてないのでそれ以外のメンバーは分類できません。ポイントは、サトミツさんのモノマネをしてる画像でも、傷心してる画像でも、メガネをかけてる画像でも正解できているという点ですね。ワイプでも松田このは当てていますね。若様はにぶちゃんに似てるらしいですが。あーだから春日さんはにぶちゃん推しなのか。
一方、複数のメンバーで成功してるのは数少ない事例です。なかなか綺麗に2人とも正面を向いてる画像がないからでしょうか。失敗事例の3枚目のようにきっちり正面を向いている画像であればそこそこ成功している(富田鈴花を除く4/5人が成功)というのが多少の裏付けになります。また、あっさりとした顔立ちの金村美玖の画像の分類が鬼門と言えるかもしれません。一応保存できないように処理は施します。
パリピ(富田鈴花)


お寿司(金村美玖)

 ##### だーこの(松田好花)
##### だーこの(松田好花)

 ##### ちゃんにぶ(丹生明里)
##### ちゃんにぶ(丹生明里)

 ##### KAWADA(河田陽菜)
##### KAWADA(河田陽菜)


複数

失敗例


最後に
非常にためになるアプリケーション製作でした。PyTorchやDeeplearningに関する理解を深めることに加えて、コーディングスキルやデバッグスキルを高めることができたと思います。
一応、実行手順をまとめて示そうと思います。あらかじめ用意すべきものは、各pythonスクリプトファイルと顔分類を試したい画像が入った「who_is_this_member?」フォルダだけです。それらを同一階層においたのち下記のコマンドを順番に実行してください。
python make_dataset2.py -t 名前 -n データ数
↓
python cut_face.py
↓
python make_test_train.py
↓
python main.py --e エポック数 --save-model
↓
python detect_hinatazaka.py
ここまで読んでくださった皆様に謝辞を。感想がありましたらコメントをいただけると嬉しいです。日向坂に関する話題でも是非に。
最後は、画像を使わせていただいた感謝を込めて、日向坂46の宣伝で締めたいと思います。「日向坂で会いましょう」毎週日曜深夜1:05からテレビ東京で放送中(右拳を高くつき上げて)!