はじめに
とりあえず使いたい方はこちらからどうぞ.
機械学習をするために大量の画像データセットを収集することが往々にしてあります.
画像収集をするためには Google,Yahoo! などの検索エンジンの API を叩く手法がまず考えられますが,API 仕様の変更や枚数制限に苦しむことがよくあると思います.
実際,Google も Yahoo! も画像検索の API は廃止されていますし,Google Custom Search でも無料で使う場合はリクエスト制限が1日100まで,1リクエストあたり10枚までとそこそこ厳しいようです.
そこで今回は,Google 画像検索でスクレイピングすることを目的としました.
Google 画像検索でスクレイピングすることのメリット
- 枚数制限がない.
- 課金の必要がない.
- アカウント登録の必要がない.
実装
image_collector.py
import argparse
import json
import os
import urllib
from bs4 import BeautifulSoup
import requests
class Google(object):
def __init__(self):
self.GOOGLE_SEARCH_URL = "https://www.google.co.jp/search"
self.session = requests.session()
self.session.headers.update(
{
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:10.0) \
Gecko/20100101 Firefox/10.0"
}
)
def search(self, keyword, maximum):
print(f"Begining searching {keyword}")
query = self.query_gen(keyword)
return self.image_search(query, maximum)
def query_gen(self, keyword):
# search query generator
page = 0
while True:
params = urllib.parse.urlencode(
{"q": keyword, "tbm": "isch", "ijn": str(page)}
)
yield self.GOOGLE_SEARCH_URL + "?" + params
page += 1
def image_search(self, query_gen, maximum):
results = []
total = 0
while True:
# search
html = self.session.get(next(query_gen)).text
soup = BeautifulSoup(html, "lxml")
elements = soup.select(".rg_meta.notranslate")
jsons = [json.loads(e.get_text()) for e in elements]
image_url_list = [js["ou"] for js in jsons]
# add search results
if not len(image_url_list):
print("-> No more images")
break
elif len(image_url_list) > maximum - total:
results += image_url_list[: maximum - total]
break
else:
results += image_url_list
total += len(image_url_list)
print("-> Found", str(len(results)), "images")
return results
def main():
parser = argparse.ArgumentParser(argument_default=argparse.SUPPRESS)
parser.add_argument("-t", "--target", help="target name", type=str, required=True)
parser.add_argument(
"-n", "--number", help="number of images", type=int, required=True
)
parser.add_argument(
"-d", "--directory", help="download location", type=str, default="./data"
)
parser.add_argument(
"-f",
"--force",
help="download overwrite existing file",
type=bool,
default=False,
)
args = parser.parse_args()
data_dir = args.directory
target_name = args.target
os.makedirs(data_dir, exist_ok=True)
os.makedirs(os.path.join(data_dir, target_name), exist_ok=args.force)
google = Google()
# search images
results = google.search(target_name, maximum=args.number)
# download
download_errors = []
for i, url in enumerate(results):
print("-> Downloading image", str(i + 1).zfill(4), end=" ")
try:
urllib.request.urlretrieve(
url,
os.path.join(*[data_dir, target_name, str(i + 1).zfill(4) + ".jpg"]),
)
print("successful")
except BaseException:
print("failed")
download_errors.append(i + 1)
continue
print("-" * 50)
print("Complete downloaded")
print("├─ Successful downloaded", len(results) - len(download_errors), "images")
print("└─ Failed to download", len(download_errors), "images", *download_errors)
if __name__ == "__main__":
main()
使ってみる
高校野球を見ながらこの記事を書いているので, baseball の画像を100枚集めることにします.
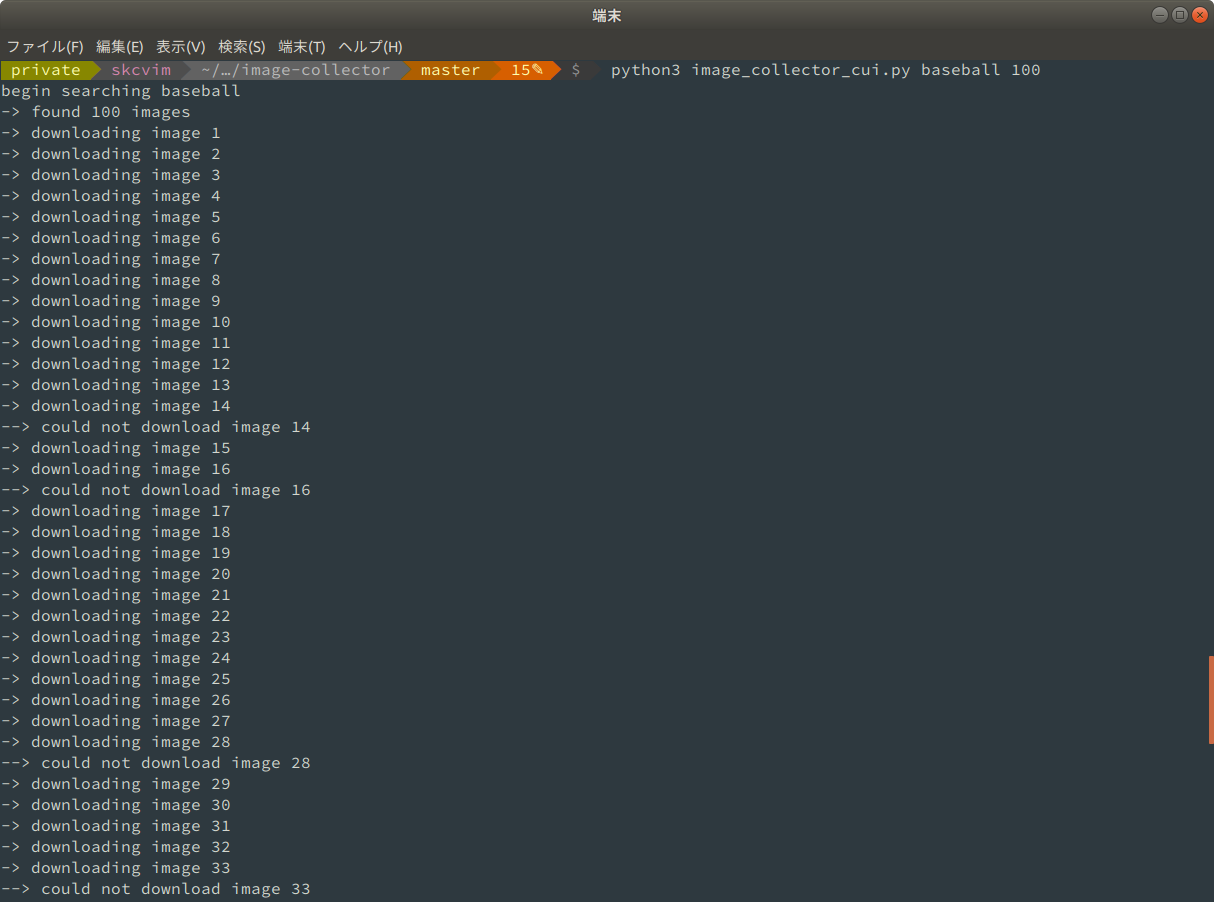
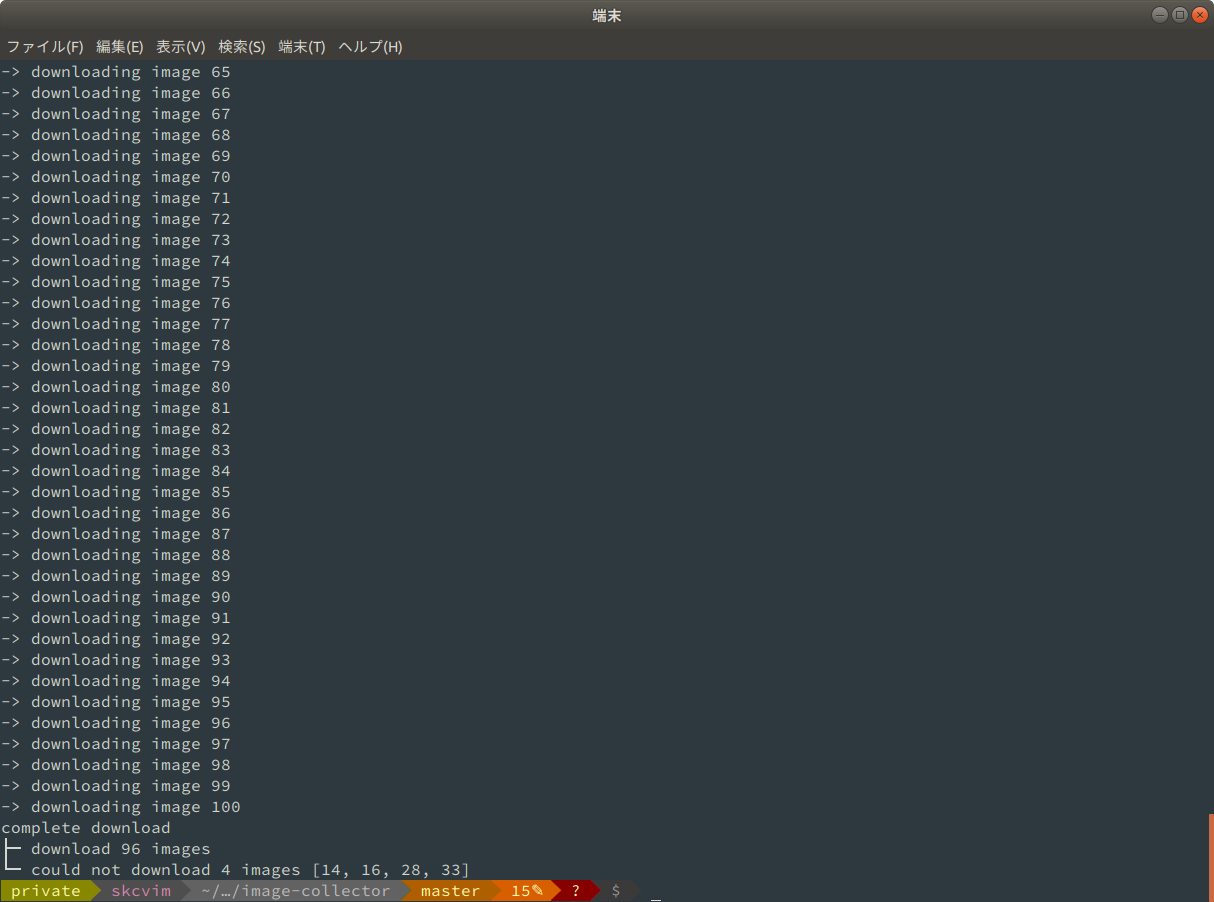
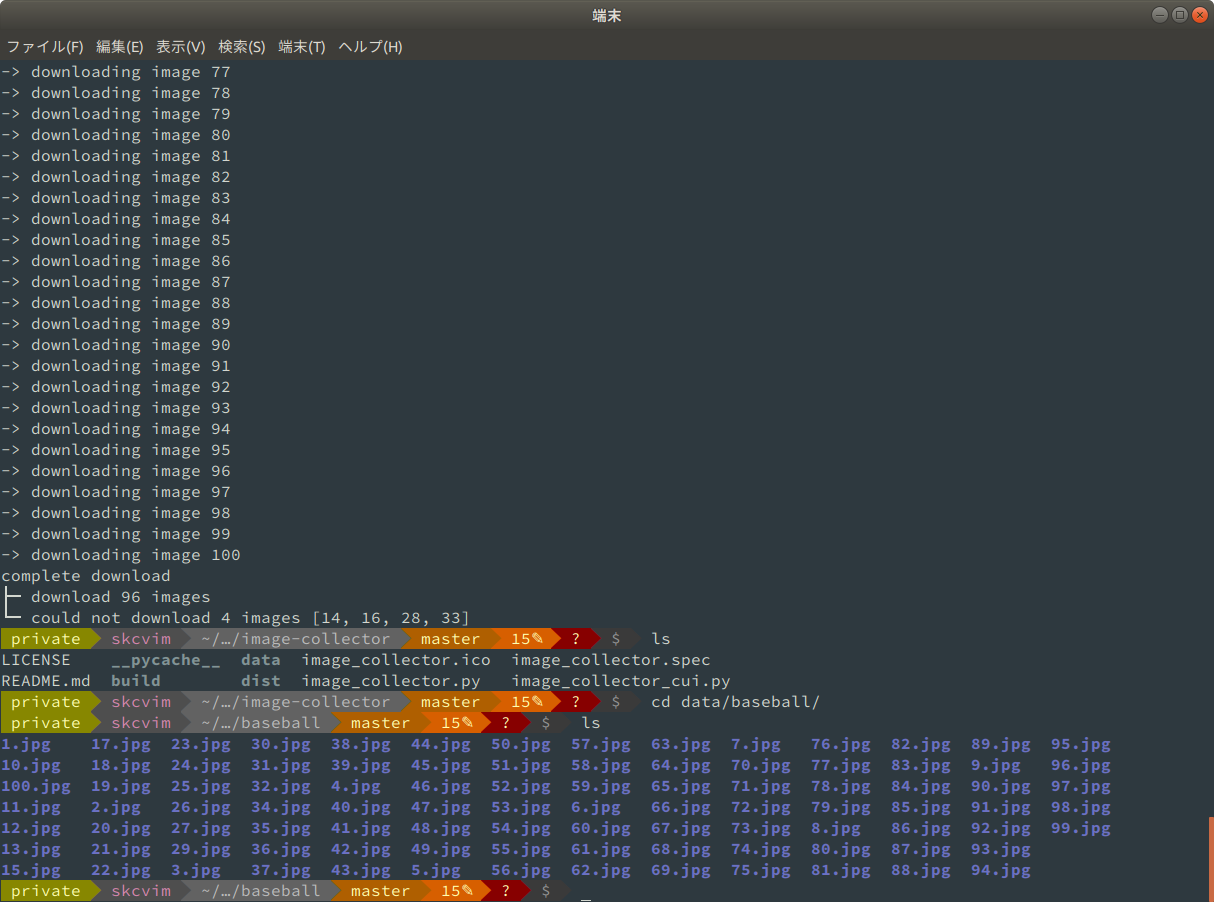
稀にダウンロードできない画像があります.
ネットワーク関係やファイル形式で不都合が生じているのかもしれませんが,そのあたりに疎いのでエラーは無視し,最後に連番の抜けている画像を標準出力するように設計しました.
おわりに
スクレイピングするときはサイトの規約やサーバへの負荷を考えて行うようにしましょう.
また,このソースコードの使用による画像収集におけるいかなる著作権問題に一切の責任を負いませんので悪しからず.
参考文献
https://qiita.com/ysdyt/items/565a0bf3228e12a2c503
https://qiita.com/derodero24/items/949ac666b18d567e9b61