はじめに
この記事では,Kedroというライブラリを使って,Titanic生存予測のワークフローを構築してみます。
最近機械学習ワークフロー管理ツール,構築支援ツールの類が多く出ています。
自分が聞いたことがあるものだけでも,
などがあります。
こうしたツールを,共通の予測プロジェクトを通して性能比較してみよう!というのが今回の記事執筆の発端です。
共通プロジェクトとしては,データ分析を始めたら誰でも必ず通る道,Titanic生存予測を選びました。
ということで,まずはKedroから試してみます。
Kedroを選んだ理由は以下の通りです:
- 使い勝手が良いと一時期twitterで評判になっていた
- Quick StartプロジェクトとTutorialがしっかり書かれていて,着手しやすそうだった
Kedroについて
kedroは,マッキンゼー傘下のデータ分析企業QuantumBlack社が開発しているPython用機械学習ワークフロー管理ツールです。
以下に挙げるように,PoC段階での実験管理に便利なツールですが,一方でプロダクション向けの機能は弱いです。
用途
機械学習モデルの実験開発を円滑に行う
できること
- ディレクトリやPythonコードのテンプレート作成
- フォーマットに沿って記述したpipelineをもとに,データ処理〜モデル構築をコマンドライン実行
- 出力結果や中間データ・オブジェクトの管理
メリット
- ディレクトリ構造やコードフォーマットを統一できる
- データ・中間オブジェクトの管理が楽になる
- catalog.ymlに書いておくだけで,簡単に読み出し・自動保存できる
- テキストベースでのパラメータ指定がしやすい
- parameters.ymlに記述しておけばstringで簡単に読み出せる
できるかわからないこと
- モデルや前処理オブジェクトの再読み込み
- 新たなデータに対する推論をしたい場合,どうすればよい?
- 特に,バージョン指定込みで行えるか?
- ディレクトリ構造などのカスタマイズ
できないこと
- 異なるモデル間の精度の比較
- MLflowと相補できそう
- プロダクション環境へのdeployとジョブの実行管理・監視
- Airflowやluigiあたりとは方向性が異なりそう
Titanic生存予測による実践例
以下,Kedroの使い方を,データ分析でお馴染みのTitanicを例に紹介していこうと思います。
基本的には公式Tutorialを参考に作成しています。
コードはGitHubにアップしてあります。
基本的なワークフロー構築の流れ
- プロジェクト作成
- コマンドラインから
kedro new - 自動的にディレクトリを作成してくれる
- コマンドラインから
- データの準備
- 生データをdata/01_raw/ディレクトリに入れ,catalog.ymlを編集する。
- 以後,stringだけで指定してpandas DataFrameに読み込んでくれる。
- pipelineの構築
- ひとまとまりの処理を関数にまとめ,nodeとして定義しする
- Pipelineクラスにnodeを並べ,処理フローを定義する
- 実行と中間データの保存
- コマンドラインから
kedro run - catalog.ymlで設定しておけば,中間ファイルを保存してくれる。
- モデルのバージョニングも可能。
- コマンドラインから
プロジェクト作成
コマンドラインからkedro newを実行すると,以下のようにプロジェクト名,レポジトリ名,パッケージ名の入力を促されます。
$ kedro new
Project Name:
=============
Please enter a human readable name for your new project.
Spaces and punctuation are allowed.
[New Kedro Project]: Titanic with Kedro
Repository Name:
================
Please enter a directory name for your new project repository.
Alphanumeric characters, hyphens and underscores are allowed.
Lowercase is recommended.
[titanic-with-kedro]: titanic-with-kedro
Python Package Name:
====================
Please enter a valid Python package name for your project package.
Alphanumeric characters and underscores are allowed.
Lowercase is recommended. Package name must start with a letter or underscore.
[titanic_with_kedro]: titanic_with_kedro
Generate Example Pipeline:
==========================
Do you want to generate an example pipeline in your project?
Good for first-time users. (default=N)
[y/N]: N
Repository Nameで入力した名前でプロジェクト用ディレクトリが作成されます。
中を見てみると,以下のようになっています。
titanic-with-kedro
├── README.md
├── conf
│ ├── README.md
│ ├── base
│ │ ├── catalog.yml
│ │ ├── credentials.yml
│ │ ├── logging.yml
│ │ └── parameters.yml
│ └── local
├── data
│ ├── 01_raw
│ ├── 02_intermediate
│ ├── 03_primary
│ ├── 04_features
│ ├── 05_model_input
│ ├── 06_models
│ ├── 07_model_output
│ └── 08_reporting
├── docs
│ └── source
│ ├── conf.py
│ └── index.rst
├── errors.log
├── info.log
├── kedro_cli.py
├── logs
├── notebooks
├── references
├── results
├── setup.cfg
└── src
├── requirements.txt
├── setup.py
├── tests
│ ├── __init__.py
│ └── test_run.py
└── titanic_with_kedro
├── __init__.py
├── nodes
│ └── __init__.py
├── pipeline.py
├── pipelines
│ └── __init__.py
└── run.py
途中で聞かれる'Python Package Name'は,src以下に生成されるpipelineコードを置くディレクトリの名前に使われます(今回はtitanic_with_kedro)。
最後に'Do you want to generate an example pipeline in your project?'と尋ねられますが,ここでyを押すとチュートリアル用のコードがセットで生成されます。
2回目以降は不要なのでNか入力せずエンターを押しましょう。
データの準備
今回はkaggleからAPIを使ってデータを取ってきて,data/01_raw/におきます。
kaggleへの登録や認証Tokenの取得は別途必要です。
$ cd data/01_raw/
$ kaggle competitions download -c titanic
$ unzip titanic.zip
これに加えて,データカタログを下記のように編集します。
train:
type: CSVLocalDataSet
filepath: data/01_raw/train.csv
test:
type: CSVLocalDataSet
filepath: data/01_raw/test.csv
データ名train, testは,データを読み込む際にも使います。
type: では,あらかじめkedroで用意されたデータ読み込み形式を選択できます。1
試しにデータを読み込めるか確認してみましょう。
以下のkedroコマンドを実行し,Jupyter notebook(もしくはIPython)を立ち上げましょう。データ読み込み用のcatalogが予めimportされた状態でnotebookが立ち上がります2。
$ kedro jupyter notebook
df_train = catalog.load("train")
df_train.head()
pipelineの構築
nodeとpipelineの定義
データ前処理pipelineをkedroのフォーマットに沿って記述します。
from kedro.pipeline import node, Pipeline
from titanic_with_kedro.nodes import preprocess
def create_pipeline(**kwargs):
return Pipeline(
[
node(
func=preprocess.preprocess,
inputs="train",
outputs="train_prep",
name="preprocess",
),
],
tags=['de_tag'],
)
kedroで用意されているPipelineクラスに処理単位であるnodeを格納していきます。
node関数には,
- func: 処理を記述した関数
- inputs: 入力データ名
- outputs: 出力データ名
- name: node名
を指定します。
nodeで行う処理は,引数funcに関数オブジェクトを渡すことで指定します。
今回の例では,関数preprocess()を一つのnodeとし,欠損値の補完やラベルエンコーディングを行なっています。
この時,関数preprocess()の入力には,引数inputsで指定したデータが用いらます。
上記の例ですとtrainが指定されていますが,これは前述のデータカタログconf/base/catalog.ymlで定義したtrainデータのことを指し示しており,カタログに記述したデータフォーマットとpathをもとによしなにファイルを読み込んで入力してくれます。
そして出力オブジェクトにはoutputsで指定したラベルが付与されます。後続の処理でこのオブジェクトを利用する際は,このラベルで指定し呼び出すことができます。
今回nodeで指定した前処理関数は,以下のようになっています。pipelineと違って,特別な記述方法を取る必要はありません。
(関数_label_encoding()は補助関数です)
import pandas as pd
from sklearn import preprocessing
def _label_encoding(df: pd.DataFrame) -> (pd.DataFrame, dict):
df_le = df.copy()
# Getting Dummies from all categorical vars
list_columns_object = df_le.columns[df_le.dtypes == 'object']
dict_encoders = {}
for column in list_columns_object:
le = preprocessing.LabelEncoder()
mask_nan = df_le[column].isnull()
df_le[column] = le.fit_transform(df_le[column].fillna('NaN'))
df_le.loc[mask_nan, column] *= -1 # transform minus for missing records
dict_encoders[column] = le
return df_le, dict_encoders
def preprocess(df: pd.DataFrame) -> pd.DataFrame:
df_prep = df.copy()
drop_cols = ['Name', 'Ticket', 'PassengerId']
df_prep = df_prep.drop(drop_cols, axis=1)
df_prep['Age'] = df_prep['Age'].fillna(df_prep['Age'].mean())
# Filling missing Embarked values with most common value
df_prep['Embarked'] = df_prep['Embarked'].fillna(df_prep['Embarked'].mode()[0])
df_prep['Pclass'] = df_prep['Pclass'].astype(str)
# Take the frist alphabet from Cabin
df_prep['Cabin'] = df_prep['Cabin'].str[0]
# Label Encoding for str columns
df_prep, _ = _label_encoding(df_prep)
return df_prep
複数pipelineの統合
複数作成したpipelineを組み合わせることもできます。
今回はモデル構築を別のpipelinesrc/titanic_with_kedro/pipelines/data_science/pipeline.pyで定義しました。
これを先ほどの前処理と組み合わせるには,以下のように行います。
from typing import Dict
from kedro.pipeline import Pipeline
from titanic_with_kedro.pipelines.data_engineering import pipeline as de
from titanic_with_kedro.pipelines.data_science import pipeline as ds
def create_pipelines(**kwargs) -> Dict[str, Pipeline]:
"""Create the project's pipeline.
Args:
kwargs: Ignore any additional arguments added in the future.
Returns:
A mapping from a pipeline name to a ``Pipeline`` object.
"""
de_pipeline = de.create_pipeline()
ds_pipeline = ds.create_pipeline()
return {
"de": de_pipeline,
"ds": ds_pipeline,
"__default__": de_pipeline + ds_pipeline,
}
モデル構築のpipelineは以下のように定義しています。
from kedro.pipeline import node, Pipeline
from titanic_with_kedro.nodes import modeling
def create_pipeline(**kwargs):
return Pipeline(
[
node(
func=modeling.split_data,
inputs=["train_prep", "parameters"],
outputs=["X_train", "X_test", "y_train", "y_test"],
),
node(func=modeling.train_model,
inputs=["X_train", "y_train"],
outputs="clf"),
node(
func=modeling.evaluate_model,
inputs=["clf", "X_test", "y_test"],
outputs=None,
),
],
tags=["ds_tag"],
)
このように,一つのpipelineに複数のノードを配置することもできます。
実行と中間データの保存
pipelineが定義できたら,プロジェクトのrootから実行コマンドを出します。
$ kedro run
こうすることで,src/<project_name>/pipeline.pyが呼び出され,処理が実行されていきます。
この時,前処理後の中間データや作成したモデル(今回はランダムフォレスト)を保存しておきたい場合には,データカタログに以下を追記しておきます。
train_prep:
type: CSVLocalDataSet
filepath: data/02_intermediate/train_prep.csv
clf:
type: PickleLocalDataSet
filepath: data/06_models/classifier.pickle
versioned: true
train_prepとclfはそれぞれ前処理後のデータと学習済みモデルを指しますが,pipeline定義時にnode関数のoutputs引数で指定した名前をそのまま認識し,所定のフォーマット・pathに保存してくれます。
また,versionedをtrueにしておけば実行の都度異なるディレクトリに保存してくれます3。
そのほか便利な機能
基本的な機能は以上な感じですが,そのほかにも以下のような機能もあります。
Jupyter notebookから直接nodeを作成
実行コードを作成する際,初めから.pyファイルで書かずにJupyter notebookで逐一実行しながら書き進める人も多いかと思います。
この場合,後からコードをまとめて.pyに書き直すのが面倒ですが,kedroのcliを使えばコードの指定した部分だけ.pyに吐き出してくれます。
それにはまず,kedroのcliからJupyterを立ち上げます。
$ kedro jupyter notebook
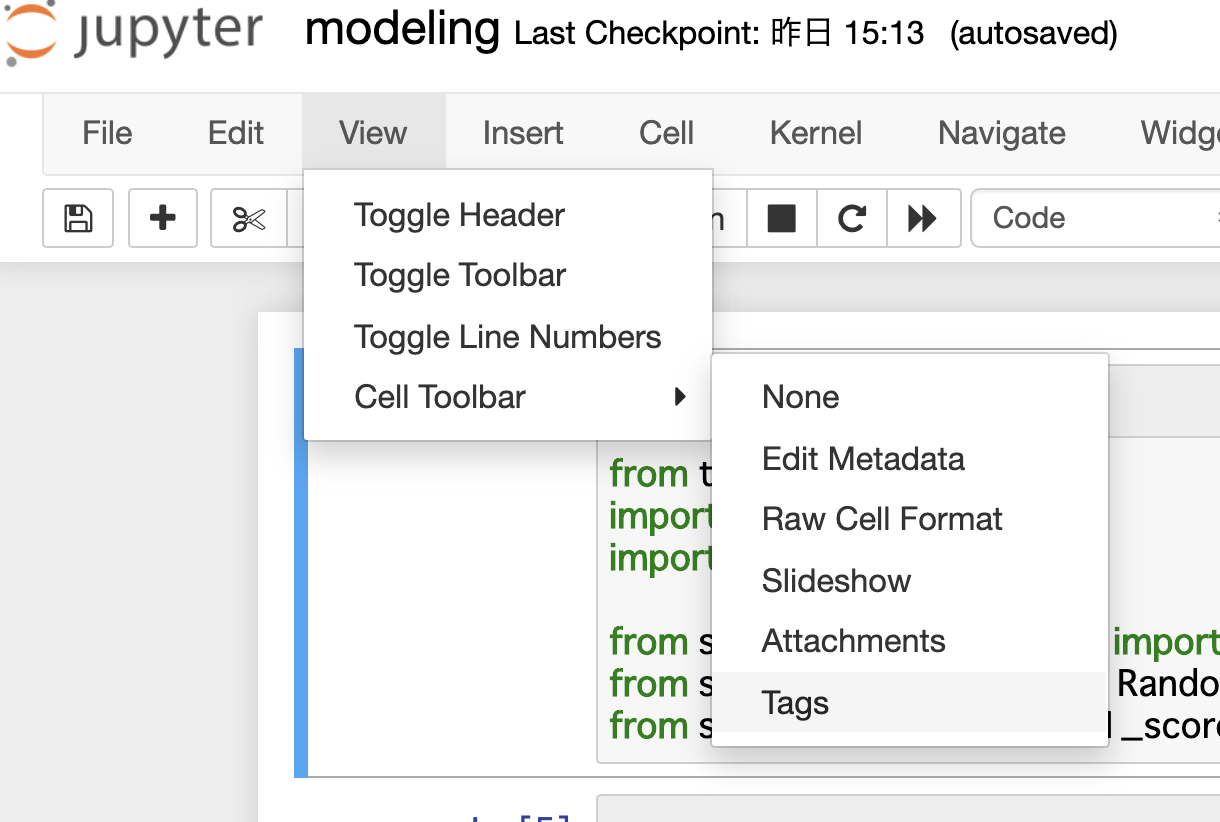
次に,.pyに書き出したいcellにだけnodeタグをつけます。
タグづけには,画面上部メニューのView > Cell Toolbar > Tagsを選択します。各セル上部にタグ入力windowが表示されるので,nodeと打ち込んで付与します。
そのうえでコマンドラインから以下を実行すると,タグづけした部分だけ抜き出してsrc/<project name>/nodes/<notebook name>.pyが生成されます。
kedro jupyter convert notebooks/<notebook name>.ipynb
<参考>
https://kedro.readthedocs.io/en/latest/04_user_guide/11_ipython.html
パラメータ管理
pipelineを定義する際に,外部ファイルで指定したパラメータを読み込むこともできます。
上記のモデル構築パラメータをもう一度見ると,inputsに"parameters"が指定されている箇所があります。
# 省略
def create_pipeline(**kwargs):
return Pipeline(
[
node(
func=modeling.split_data,
inputs=["train_prep", "parameters"],
outputs=["X_train", "X_test", "y_train", "y_test"],
# 省略
上記は,学習データ・テストデータに分割する部分です。
"parameters"は,conf/baseディレクトリ以下のparameters.ymlファイルを参照します。
test_size: 0.2
random_state: 17
こうしておくことで,以下のように自動で辞書型のオブジェクトとしてnode関数の引数に渡し,参照することができます。
# 省略
def split_data(data: pd.DataFrame, parameters: Dict) -> List:
"""Splits data into training and test sets.
Args:
data: Source data.
parameters: Parameters defined in parameters.yml.
Returns:
A list containing split data.
"""
target_col = 'Survived'
X = data.drop(target_col, axis=1).values
y = data[target_col].values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=parameters["test_size"], random_state=parameters["random_state"]
)
return [X_train, X_test, y_train, y_test]
# 省略
まとめ
以上,Kedroの利用方法の紹介がてら,Titanic予測を行ってみました。
課題:前処理オブジェクトの保存とバージョン管理
上記の予測フローは欠陥があります。
データ分析に慣れている方ならお気づきになったかもしれませんが,
- 訓練・テストデータを分ける前に前処理を行なっている
- 新しいデータが与えられた時の推論フローがない
ことが挙げられます。
特に前者については,欠損値の補完とラベルエンコーディングの際にテストデータの情報が訓練データに混ざるので,Leakageの恐れがあります。
いずれの問題点も,前処理部分をクラスで書いておいて,インスタンスをpickleで固めて後から読み出し利用できるようにすれば解決可能です。
解決方法もそこまで難しくなく,nodeの出力に前処理オブジェクトを加えて,catalog.ymlを編集し実行時に保存するようにすれば実現できる見込みです。
ただし,バージョン管理の問題があります。
前処理部分とモデルの両方をバージョン管理ありで保存した場合,各モデルに対応するバージョンの前処理オブジェクトはどのように紐づければよいでしょうか?
例えば前処理部分を書き換えてモデルを作り,後から古いモデルで推論を行いたいとします。
この時,新しい前処理コードが古いモデルと互換性を持たない場合,前処理オブジェクトも古いモデルを作った時のものに置き換える必要があります。
これを手間なく行うには,何かしらのタグ付けか実行IDの付与が必要ですが,それをKedroでできるかは未確認です。4
その他思ったこと
そのほか,Kedroを触ってみて「この機能あったらな...」と思った点をいくつか挙げますと,
- テンプレートとして用意されているディレクトリ構造やコードをカスタマイズできないか?
- 出力した予測精度をまとめて記録し,モデルやパラメータごとに比較できないか?
があります。
前者はもしかしたらいじれるかもしれません。
後者については恐らくKedroのカバー範囲外なので,他のツールと併用するしかなさそうです。
具体的にはDatabricksから出ているMLflowがちょうど良さそうです。
実際,Kedroの開発元QuantumBlackの人が書いた記事でもMLflowとの併用が論じられていますし,両者を合わせたPipelineXというライブラリも存在します。
参考リンク
- Introducing Kedro: The open source library for production-ready Machine Learning code
- PythonのPipelineパッケージ比較:Airflow, Luigi, Gokart, Metaflow, Kedro, PipelineX
-
カスタムで作成したデータ読み込み関数を適用することもできます。 ↩
-
デフォルトでは,モジュール読み込みエラーで実行できないことがあります。その際は,
src/<project-name>/pipeline.pyを開き,Tutorial用のモジュールimportを削除しておきます。 ↩ -
今回の場合,
data/06_models/classifier.pickle/以下に実行時の時刻で新しい時刻が作成され,data/06_models/classifier.pickle/2020-02-22T06.26.54.486Z/classifier.pickleのように保存されます。 ↩ -
MLflowやMetaflowでは実行IDを指定してモデルや中間オブジェクトの読み出しが可能です。これらとうまく組み合わせれば,もしかしたら可能かも... ↩