この記事では、Open-sourceのPipeline/Workflow開発用PythonパッケージのAirflow, Luigi, Gokart, Metaflow, Kedro, PipelineXを比較します。
この記事では、"Pipeline"、"Workflow"、"DAG"の単語はほぼ同じ意味で使用しています。
要約
- 👍: 良い
- 👍👍: より良い
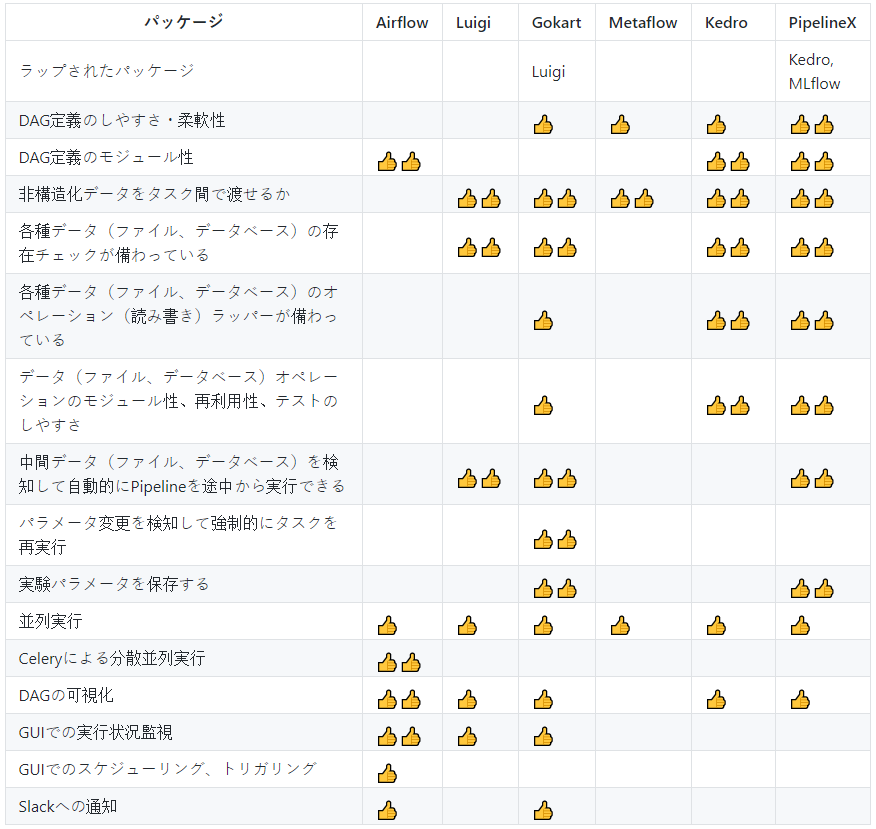
Airflow
2015年にAirbnb社からリリースされました。
Airflowは、Pythonコード(独立したPythonモジュール)でDAGを定義します。
(オプションとして、非公式の dag-factory 等を使用して、YAMLでDAGを定義できます。)
良い点:
- DAGの可視化、実行進捗監視、スケジューリング、トリガリング機能をGUI上で使えます。
- Celeryを使用した分散コンピューティングを使えます。
- DAGの定義はモジュラーで、処理関数とは独立してます。
- Workflowは
SubDagOperatorを使用してネストできます。 - Slackに通知できます。
良いとは言えない点:
- 依存タスク間でデータベースを介さずにデータを渡せるように設計されていません。
Airflow内の依存タスク間で非構造化データ(画像、動画、pickle等)を渡す良い方法がありません。 - ファイルアクセス(読み書き)のためのコードが別途必要になります。
- 中間生成データファイルやデータベースを使用して、自動的にPipelineの途中から実行できません。
Luigi
2012年にSpotify社からリリースされました。
Luigiは、Pythonコードで、3つのクラスメソッド(requires, output, run)を持つTaskの子クラス達によりPipelineを定義します。
良い点:
-
Targetクラスを使用したTask.outputメソッドで定義されたとおり、ローカルかクラウド(AWS, GCP, Azure)上の中間データファイルやデータベースを使用して、
自動的にPipelineの途中から実行できます。 - 依存タスク間で任意のデータを渡すようにコーディングできます。
- DAGの可視化、実行進捗監視機能をGUI上で使えます。
良いとは言えない点:
- ファイルやデータベースアクセス(読み書き)するためのコードを書く必要があります。
- Pipeline定義、タスク処理(ETLのうちのTransform)、データアクセス(ETLのうちのExtract&Load)が密に結合していて、モジュラーではありません。
将来のプロジェクトで再利用するためにタスククラスを修正しないといけません。
Gokart
2018年12月にエムスリー社からリリースされました。
Gokartは内部でLuigiを使用します。
良い点:
Luigiの良い点に追加として:
-
TaskInstanceParameterを使用することにより、Pipeline定義とタスク処理を分離し、将来のプロジェクトで簡単に再利用できるようにすることができます。 - pickle, npz, gz, txt, csv, tsv, json, xml 形式のファイルアクセス(読み書き)ラッパーが
FileProcessorクラスとして提供されます。 - 各実験パラメータを保存する仕組みが備わっています。thunderboltというビューワーが提供されます。
- 中間ファイル名に含まれた、パラメータセットに固有のハッシュ文字列を参照して、パラメータが変更された際にはタスクを再実行します。
様々なパラメータセットで実験するのに有用です。 - クラスデコレータを使用してLuigiの
requiresクラスメソッドを簡潔に書くためのシンタクティックシュガーが提供されます。 - Slackに通知できます。
良いとは言えない点:
- サポートされているデータファイル形式が限られています。
サポートされていない形式を使用するためには、ファイルやデータベースアクセス(読み書き)するためのコードを書く必要があります。
Metaflow
2019年12月にNetflix社からリリースされました。
Metaflowは、Pythonコードで、step デコレータ付きのクラスメソッドを含むFlowSpecの子クラスによりPipelineを定義します。
良い点:
- AWSサービス(特にAWS Batch)とのインテグレーション。
良いとは言えない点:
- ファイルやデータベースアクセス(読み書き)するためのコードを書く必要があります。
- Pipeline定義、タスク処理(ETLのうちのTransform)、データアクセス(ETLのうちのExtract&Load)が密に結合していて、モジュラーではありません。
将来のプロジェクトで再利用するためにタスククラスを修正しないといけません。 - GUIはありません。
- GCP、Azureにあまり対応していません。
- 中間生成データファイルやデータベースを使用して、自動的にPipelineの途中から実行できません。
Kedro
2019年5月にMcKinseyの子会社のQuantumBlack社からリリースされました。
Kedroは、Pythonコード(独立したPythonモジュール)で、3つの引数
(func: タスク処理関数, inputs: 入力データ名(複数の場合はlist or dict), outputs: 出力データ名(複数の場合はlist or dict))
を持つnode 関数のリストによりPipelineを定義します。
良い点:
- ローカル又はクラウド(AWSのS3 GCPのGCS)上のCSV, Pickle, YAML, JSON, Parquet, Excel, textファイル、SQL、Spark等のリソースへのアクセス(読み書き)用の
ラッパーをDataSetクラスとして備えています。 - 対応していないデータ形式へのサポートは、ユーザーにより追加できます。
- Pipeline定義、タスク処理(ETLのうちのTransform)、データアクセス(ETLのうちのExtract&Load)は独立していて、モジュラーです。
将来のプロジェクトで簡単に再利用できます。 - Pipelineはネストできます。(Pipelineは他のPipelineの一部として使用できます。)
- GUI (kedro-viz)でDAGを可視化できます。
良いとは言えない点:
- 中間生成データファイルやデータベースを使用して、自動的にPipelineの途中から実行できません。
- GUI (kedro-viz)で実行進捗監視する機能はありません。
- 大抵の場合は使用しないパッケージ(pyarrow 等)が
requirements.txtに含まれています。
PipelineX:
2019年11月にKedroユーザー(私)によりリリースされました。
PipelineXはKedroとMLflowを内部で使用します。
PiplineXは、YAML(独立したYAMLファイル)で、KedroよりもPipelineを定義します。
良い点:
Kedroの長所に追加として:
- 中間データファイルやデータベースを使用して、自動的にPipelineの途中から実行できます。
- Kedro Pipelineを簡潔に書くためのシンタクティックシュガーを使用できます。
(例:PyTorch (torch.nn.Sequential) や Keras (tf.keras.Sequential) に似たSequential API) - Kedro
DataSetcatalog を簡潔に書くためのシンタクティックシュガーを使用できます。
(例:ファイルパス内のファイル名をデータセットインスタンス名として使用) - Kedroと後方互換性があります。
- 各実験パラメータ、メトリック、モデルその他の生成データファイルを保存するするためのMLflowとのインテグレーションを使用できます。
- PyTorch, Ignite, pandas, OpenCVといったデータサイエンスで一般的なパッケージとのインテグレーションを使用できます。
- コンピュータビジョンアプリケーションで有用な画像セット(画像を含むフォルダ)を扱うための
DataSetクラスを使用できます。 - 元のKedroで提供されているものよりもリーンなプロジェクトテンプレートが提供されます。
良いとは言えない点:
- GUI (kedro-viz)で実行進捗監視する機能はありません。
- 大抵の場合は使用しないパッケージ(pyarrow 等)がKedroの
requirements.txtに含まれています。 - PipelineXは、現時点では一個人(私)により開発、メンテナンスされています。
プラットフォームに特化したパッケージ
Argo
ArgoはKubernetesを使用してPipelineを実行します。
Kubeflow Pipelines
Kubeflow Pipelinesは内部でArgoを使用します。
Oozie
Hadoopジョブを管理できます。
Azkaban
Hadoopジョブを管理できます。
リファレンス
Airflow
- https://github.com/apache/airflow
- https://airflow.apache.org/docs/stable/howto/initialize-database.html
- https://medium.com/datareply/integrating-slack-alerts-in-airflow-c9dcd155105
Luigi
- https://github.com/spotify/luigi
- https://luigi.readthedocs.io/en/stable/api/luigi.contrib.html
- https://www.m3tech.blog/entry/2018/11/12/110000
Gokart
- https://github.com/m3dev/gokart
- https://www.m3tech.blog/entry/2019/09/30/120229
- https://qiita.com/Hase8388/items/8cf0e5c77f00b555748f
Metaflow
- https://github.com/Netflix/metaflow
- https://docs.metaflow.org/metaflow/basics
- https://docs.metaflow.org/metaflow/scaling
- https://medium.com/bigdatarepublic/a-review-of-netflixs-metaflow-65c6956e168d
Kedro
- https://github.com/quantumblacklabs/kedro
- https://kedro.readthedocs.io/en/latest/03_tutorial/04_create_pipelines.html
- https://kedro.readthedocs.io/en/latest/kedro.io.html#data-sets
- https://medium.com/mhiro2/building-pipeline-with-kedro-for-ml-competition-63e1db42d179
PipelineX
Airflow vs Luigi
- https://towardsdatascience.com/data-pipelines-luigi-airflow-everything-you-need-to-know-18dc741449b7
- https://medium.com/better-programming/airbnbs-airflow-versus-spotify-s-luigi-bd4c7c2c0791
- https://www.quora.com/Which-is-a-better-data-pipeline-scheduling-platform-Airflow-or-Luigi
不正確な点
不正確な点がありましたら、お知らせください。
https://github.com/Minyus/Python_Packages_for_Pipeline_Workflow/blob/master/ja/README.md へのプルリクエストを歓迎します。