概要
R言語でtwitterからデータを取得してテキストマイニングにより可視化を行ってみましたので、手法を共有します。
タイトルにもあるワードクラウドとはテキストマイニング手法の一つです。
読み込まれた文章を解析して、使用頻度の高い単語を大きく表示することで、テーマや内容を視覚的・直感的に表すことができる表現手法を指します。
今回、やってみることをイメージでお伝えすると下記のような感じです。
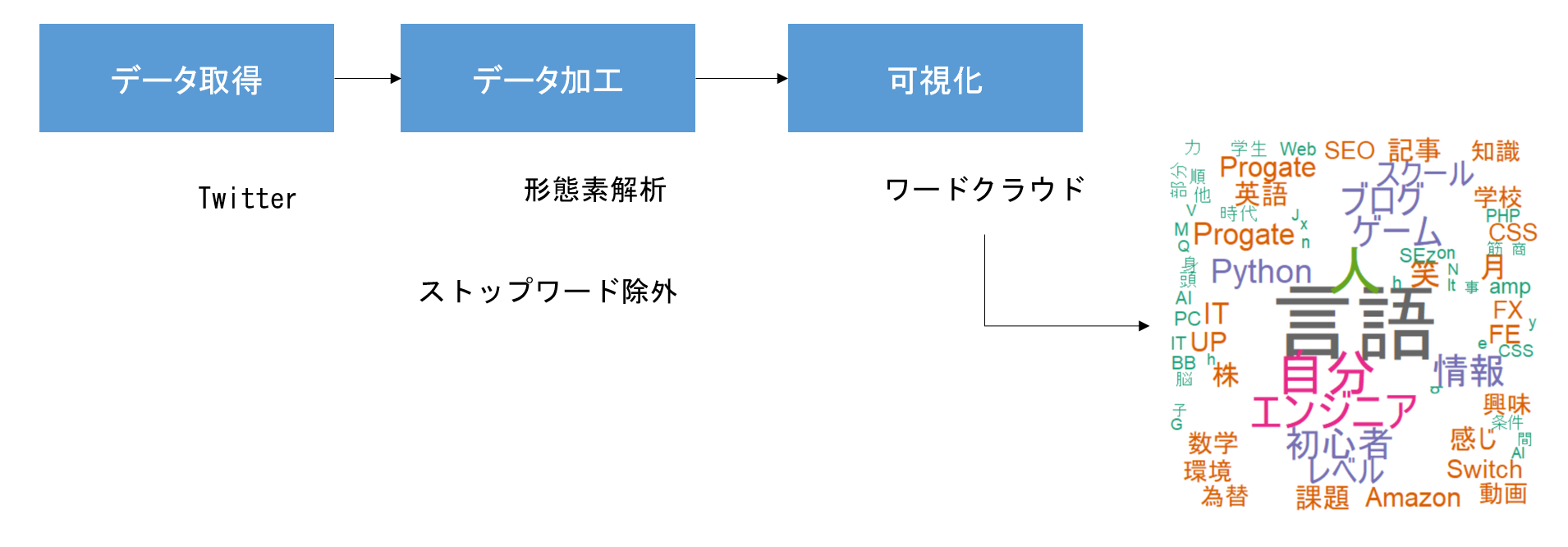
いや本来はTwitterからデータを取得して軽く分析っぽいことして終わりのはずだったんですけどね。どうしてこうなった。
前準備
文章を分析する前には事前に文章を形態素(単語)に分解する必要があります。
そのためにご使用のPCに「RMecab」と呼ばれるパッケージをインストールする必要があるのですが、色々と準備が面倒でして、設定の方法につきましては過去に偉人が詳しく解説してくださっているので、そちらをご参照ください。
・【R】【MeCab】RMeCabのインストールと形態素解析
データ取得(rtweet)
過去にTwitterからデータを取得する方法について記事を書かせていただいたことがありましたが、現在はRのパッケージである「twitteR」の開発は既に終了しておりメンテナンスが行われていません。
ということで主流は「rtweet」パッケージの使用が主流となっておりまして、このパッケージを使用してTwitterからデータを取得します。
「twitteR」はTwitterAPIの登録が必要でしたが「rtweet」はAPI登録が不要になっており、とっても楽にデータを取ることができるようになっています。
# ライブラリの読み込み --------------------------------------------------------------
library(rtweet)
library(devtools)
library(pipeR)
library(wordcloud2)
library(RMeCab)
library(dplyr)
# キーワードで検索(第一引数:検索したいキーワード、第二引数:取得件数、第三引数:リツイートを取得するか、第四引数:どの国のツイートを取得するか
keyword <- search_tweets("FGO",n=3200,include_rts = FALSE,langs = "ja")
# ファイルに書き込み
write.csv(keyword$text,file = "tweets.csv",sep = ",",col.names = T,row.names = F)
search_tweets関数を実行するとブラウザが開かれてTwitterとアプリ連携の認証が行われる画面が表示される場合がありますが、連携します的なボタンを押してしまって問題はないです。
連携に成功すると「Authentication complete.Please close this page and return to R.」(訳:認証が完了しました。このページを閉じてRに戻ってください。)と表示されますので、Rに操作を切り替えましょう。
データ加工(形態素解析、ストップワードの除外)
実は一番面倒な作業がこちらです。
RMecabでテキストを頻出単語(形態素)ごとに分解し、その後に頻出単語に混ざる不要な単語(「あ」、「ああ」、「A」みたいな分析をする上で明らかに無意味な単語のことで、一般にストップワードと呼ばれます)を取り除く作業です。
人力でキーワードの「要る or 要らない」を振り分ける作業なので手間なんですよね。
どうにか楽にならないものか…と思いつつ「要らない」キーワードを除外するためのファイル(stop_words.csv)を作成して手動で要らないキーワードを入力していきます。
こんな感じです。
取れたデータセットと見比べながら「これは要らないな」と思ったキーワードをひたすら手打ちで入力していきます。
入力ができたら次のような関数を作成しておきます。
キーワード除外のファイル(stop_word.csv)を読み込み、入力されたキーワードをデータフレームから除外する関数です。
(中略)
# 自作関数 --------------------------------------------------------------------
# ストップワードの除外
stopwords <- function(df){
data <- df
#ストップワードファイルを読み込む
stop_words <- read.csv("stop_words.csv")
#ストップワードを除外する
for (i in 1:nrow(rc)) {
data <- data[data[,1] != stop_words[i,],]
}
return(data)
}
準備ができたら形態素分解を行います。
RMecabFreq関数はファイルを読み込み、形態素ごとに分解し、その単語がどの頻度で現れているかを表してくれる便利な関数です。
しかし品詞や感動詞、記号など不要な単語も含まれてきますので、これらを除外する必要があります。
ここでは例として名詞の一般か固有名詞に絞って抽出しています。
それから頻出度合いの低いキーワードを抽出してもあまり意味はないので、頻出度合いが10以上のキーワードのみが抽出できるように処理を書いてみます。
それでもなお不要なキーワードは残ってしまうので先ほど準備したストップワードを除外する関数を呼び出して不要なキーワードを除外します。
コード自体の長さは大したことがないのですが、ストップワードの除外は案外大変だということをご理解いただけると幸いです。
(中略)
# データ加工 ------------------------------------------------------------------
# 頻出ワードを抽出
tweetword <- RMeCabFreq("tweets.csv")
# 名詞、一般、固有名詞に絞る
tweetword <- tweetword[tweetword[, 2] == "名詞"&( tweetword[, 3] == "一般" | tweetword[, 3] == "固有名詞" ),]
# 頻出度合いが10以上のキーワードのみを抽出
tweetword <- tweetword[ tweetword[,4] > 10, ]
# ストップワードを除外
tweetword <- stopwords(tweetword)
# Freq(頻度)の降順でソート
tweetword <- tweetword %>>%
arrange(desc(Freq))
可視化(wordcloud2)
ここまで来てようやく可視化を行います。
現在はwordcloud2パッケージの使用が主流のようですので、使ってみましょう。
(中略)
# 可視化 ------------------------------------------------------
tweetword <- tweetword[,c("Term","Freq")]
# ワードクラウドで可視化
wordcloud2(tweetword)
実行結果、以下のようになりました。

イベントはわかりますが、ビンゴって何?って調べたら人権鯖ビンゴと呼ばれる強鯖をどれぐらい所持しているのかビンゴ形式で問う遊びがFGO(流行のソシャゲです)のトレンドだったようです。
時間を置けばまた別のトレンドとなるキーワードが浮かび上がってくるのでしょうが、視覚的に流行が把握しやすいのは良いですね。
以上で終わりです。
興味がある方は触ってみると面白い結果が得られたりするかもしれませんよ。
やっていきましょう。