Rで形態素解析をしてみたので、インストールから簡単なデモまで一通り説明します。
Rを使って形態素解析をすると、いろんなソフトを行ったり来たりせずに一貫して、分析が進められるのでなかなか便利です。
設定した環境
- iMac (27-inch, Mid 2010)
- プロセッサ: 2.8 GHz Intel Core i5
- メモリ: 12 GB 1333 MHz DDR3
- R : 3.3.0
準備
Homebrewを入れる
MacにMeCabを入れるにはいくつか方法がありましたが、
Homebrewで入れるのが比較的簡単だったので、今回はHomebrewでMeCabをインストールします。
まずはHomebrewを入れていない人向けに簡単にHomebrewのインストールからしていきましょう。
以下のサイトに行くと指定のコマンドがあるのでそれをターミナルから実行します。
インストールが完了したら、以下のコマンドを入れて正しくインストールされているか確認してみましょう。
$ brew doctor
何も問題がない場合は以下が表示されます。
$ brew doctor
Your system is ready to brew.
ちょっと問題があって、warningが表示されていても最初に以下のような表示であればとりあえず動きます。
$ brew doctor
Please note that these warnings are just used to help the Homebrew maintainers
with debugging if you file an issue. If everything you use Homebrew for is
working fine: please don't worry and just ignore them. Thanks!
MeCabのインストール
MeCabをhomebrewでインストールしていきます。
ここでは、MeCabの辞書であるmecab-ipadicもまとめてインストールします。
$ brew install mecab
$ brew install mecab-ipadic
この2つが問題無くインストールできれば、MeCabの準備は完了です。
windowsの方へ
バイナリパッケージがあるので、以下のURLからダウンロードします。
インストールしたら、MeCabの準備は完了です。
http://taku910.github.io/mecab/#download
RMeCabのインストール
ここまできたらいよいよRでMeCabを使えるようにするステップです。
Rを起動して以下を実行します。
install.packages("RMeCab", repos = "http://rmecab.jp/R")
自動でRMeCabがインストールされます。
インストールが完了したら、早速試してみましょう!
RMeCabで簡単な形態素解析を実行する
単文で形態素解析ができるかテスト
それでは以下のようなスクリプトを実行してみましょう。
library(RMeCab)
res <- RMeCabC("すもももももももものうち")
unlist (res)
上記を実施すると以下のような結果が得ることができます。
名詞 助詞 名詞 助詞 名詞 助詞 名詞
"すもも" "も" "もも" "も" "もも" "の" "うち"
また、docDF()関数を使うと、結果を行列として取得することも可能。
> (docDF(target = data.frame(X = "すもももももももものうち"), column = "X", type = 1))
number of extracted terms = 5
now making a data frame. wait a while!
TERM POS1 POS2 Row1
1 うち 名詞 非自立 1
2 すもも 名詞 一般 1
3 の 助詞 連体化 1
4 も 助詞 係助詞 2
5 もも 名詞 一般 2
指定可能な引数に関する詳細はこちら
http://rmecab.jp/wiki/index.php?RMeCabFunctions
長文を形態素解析して名詞の個数をカウント
少し発展して次はちょっと長めの文章を形態素解析して、登場する名詞の個数を数えるコードを作ってみようと思います。
今回は日本語訳のスティーブ・ジョブス氏の演説を使ってみようと思います。
RMeCabでデータを読み込むにはテキストファイルになっている必要があるので、
まずは、テキストファイルにして作業ディレクトリに保存しておきます。
library(RMeCab)
library(ggplot2)
# 解析対象となるデータの読み込み
res <- RMeCabFreq("steve-jobs-speech.txt")
# 名詞だけを取り出してデータフレームres_nounへ
res_noun <- res[res[,2]=="名詞",]
# 2回以上登場する名詞の数。res[,4]で"Freq"列を参照
nrow(res_noun <- res[res[,2]=="名詞" & res[,4] > 1,])
# res_nounをFreqで降順ソート
res_noun[rev(order(res_noun$Freq)),]
さらに以下のコードで上位25位の頻出名詞を棒グラフで表します。
# 1列目と4列目を抜き出してデータフレームを作成する
res_noun2 <- data.frame(word=as.character(res_noun[,1]),
freq=res_noun[,4])
# 上位25位に絞り込む
res_noun2 <- subset(res_noun2, rank(-freq)<25)
# ggplotでグラフを描画する
ggplot(res_noun2, aes(x=reorder(word,freq), y=freq)) +
geom_bar(stat = "identity", fill="grey") +
theme_bw(base_size = 10, base_family = "HiraKakuProN-W3") +
coord_flip()
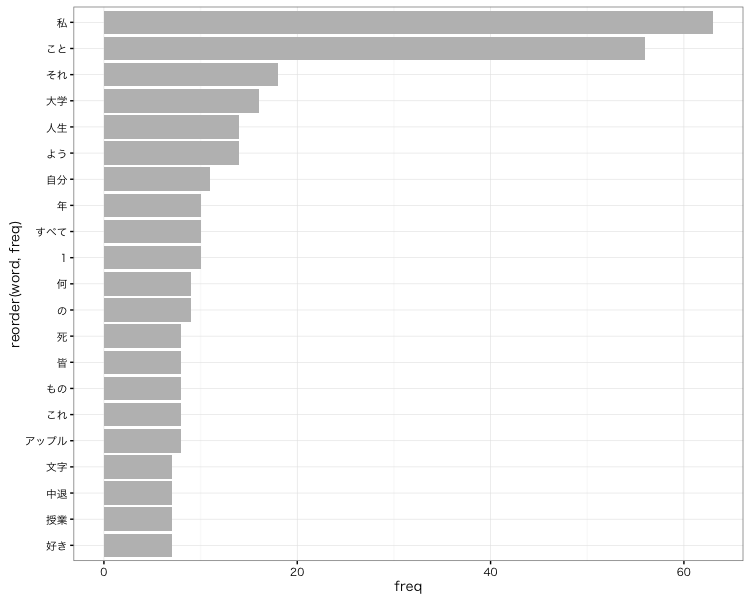
こうしてみると”私”や”人生”、”Apple”といった単語が多く、
この演説がいかに自分の体験や経験に基づいて構成されているのかがよく分かります。