【目次】
1. はじめに
2. 実行環境
3. pythonの実行環境の準備
4. データセットの作成
5. モデルの構築と評価
6. 予測結果についての考察
7. アプリの実装
8. おわりに
1. はじめに
AidemyさんのAIアプリ開発コースのカリキュラムの一環で、機械学習でオリジナルの画像認識モデルを構築し、アプリに実装するという成果物を作成することになりました。(このブログは受講修了条件を満たすために公開しています)
私はSEVENTEENという13人構成のKPOPグループが大好きなのですが、最初のほうは顔の見分けがつかなかったので、画像からどのメンバーかを判別するモデルを作ってみたいと思います。
ただ、私の力量では13人全員の判別をするモデルは精度面でのハードルが高いので、特に顔の特徴がわかりやすい3人に絞りました。
左から、
- WONWOO(ウォヌ):切れ長な目とシュッとした鼻筋が特徴の塩顔イケメン
- SEUNGKWAN(スングァン):全体的にパーツが丸みがあり、童顔のかわいい系イケメン
- VERNON(バーノン):韓米ハーフで、華やかな顔立ちの彫刻系イケメン
です!
といっても、初見の方からすればあまり差はないのでしょうね・・・
機械学習ではちゃんと特徴を抽出できるのか、楽しみです。
※捕捉:このブログでは、pythonによるデータセットの作成からモデル評価にフォーカスを置いています。アプリ開発の説明はかなり割愛しているので、ご了承ください。

2. 実行環境
- モデル構築、アプリ起動:
- 言語:python3.12.1
- 使用サービス:Google Colaboratory
- webページデザイン:
- 言語:html, css
- 使用サービス:Visual Studio Code
- アプリのデプロイ:
- 使用サービス:GitHub, Render
3. pythonの実行環境の準備
実行環境はGoogle Colaboratoryを使います。
Google Colabotoryは、GoogleアカウントさえあればWebブラウザで利用できる無料のPython実行環境で、特に何かをインストール必要がないのでとても手軽ですが、「セッション切断後、90分経過するとリセットされる」等のデメリットもあるので、下記の記事などを参考の上ご利用ください。
▼参考記事:
GoogleColaboratoryとは?4つのメリット・デメリット
Google Colab入門(Google Colaboratory)
では、早速コードを書いていきます。
Google Colaboraoryはローカルにアクセスできないので、Google Driveにデータを置く必要があります。
以下のコードを実行することで、Google Driveにアクセスできるようになります。
from google.colab import drive
drive.mount('/content/drive')
次に、データセットの作成からモデルの評価までの作業に必要なライブラリをインポートします。
大体のライブラリは何もしなくても使えますが、一部のライブラリ(iclawler、kerasなど)については、別途インストールが必要です。
!pip install [ライブラリ名]でインストールできます。
▼参考記事:
Pythonのモジュール、パッケージ、ライブラリ徹底解説!
# 画像収集
!pip install icrawler
from icrawler.builtin import BingImageCrawler #Bing(Microsoft提供の検索エンジン)用
# 画像の読み込み、加工
import cv2
# モデル構築
from tensorflow.keras.utils import to_categorical #正解ラベルをone-hot化
from tensorflow.keras.models import Model, Sequential #線形モデル
from keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D, Dropout, Input #ディープラーニング
from tensorflow.keras.applications.vgg16 import VGG16 #転移学習
from tensorflow.keras import optimizers #最適化関数
# その他(ディレクトリ、データ操作など)
import os
import shutil
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import random
4. データセットの作成
モデル構築の一番の肝である、データセットを作成します。
プロセスが長いので、5つに分けて説明します。
- step1.画像収集
- step2.顔領域の切り取り
- step3.失敗画像の除外
- step4.画像の水増し
- step5.モデル投入用に成形
step1. 画像収集
SEVENTEENのメンバーの画像をインターネットから収集します。
▼参考動画:
【だれでもできる】プログラミングが未経験でも大丈夫。Webから大量画像を収集する方法をわかりやすく解説します。
まず、対象となる3人のメンバーの画像の検索名と、画像を保存するディレクトリのパスのリストを作成します。
尚、検索名として使うメンバーの正式なアルファベット表記はオフィシャルサイトから引用しました。
# グループ名
group_name = "SEVENTEEN"
# メンバー名のリスト
member_name_list = ["WONWOO", "SEUNGKWAN", "VERNON"]
# 検索名のリスト
member_swd_list = [group_name + " " + m for m in member_name_list]
# グループ名のディレクトリパス
main_dir = os.path.join("/content/drive/MyDrive/Aidemy_DataSet/", group_name)
# メンバーごとの保存先のディレクトリパスのリスト
member_dir_list = [os.path.join(main_dir, m) for m in member_name_list]
# print(member_dir_list[0])
# >>>content/drive/MyDrive/Aidemy_DataSet/SEVENTEEN/WONWOO
ディレクトリパスのリストをもとに、SEVENTEENというディレクトリの下にメンバー名のディレクトリを作成します。
for dir in member_dir_list:
# ディレクトリが存在しない場合:ディレクトリを作成する
if not os.path.exists(dir):
os.makedirs(dir)
# ディレクトリが存在しており、かつファイルが含まれている場合:中身を削除してから再作成する(初期化のため)
else:
file_cnt = sum(os.path.isfile(os.path.join(dir, name)) for name in os.listdir(dir))
if file_cnt > 0:
shutil.rmtree(dir)
os.mkdir(dir)
実際に画像を収集してみます。
検索条件を指定して、先ほど作成したメンバーのディレクトリに収集した画像を保存します。
動作は思っていたより早く、一人当たり10秒もかかりませんでした。
# 検索条件を指定
filters = dict(
type='photo',
color='color',
#size='small',
license='commercial',
people='face',
date=((2018, 1, 1), (2023, 12, 31)) #収集できた枚数が少ない場合は期間を広げる
)
# 画像の収集と保存を実行
for swd, dir in zip(member_swd_list, member_dir_list):
bing_crawler = BingImageCrawler(downloader_threads=4,
storage={'root_dir': dir})
bing_crawler.crawl(keyword=swd, filters=None, offset=0, max_num=200)
メンバーごとに、収集した画像のファイルパスのリストを作成しておきます。
member_files_list = []
for dir in member_dir_list:
files = [os.path.join(dir, f) for f in os.listdir(dir) if os.path.isfile(os.path.join(dir, f))]
member_files_list.append(files)
# print(member_files_list[0][0])
# >>>/content/drive/MyDrive/Aidemy_DataSet/SEVENTEEN/WONWOO/000001.jpg
どんな画像が収集できたのか確認してみます。
MyDrive上でも確認できますが、ローカルのほうが一覧で見やすいので、ZIPファイルにしてダウンロードします。
# contentディレクトリの下にZIPファイルを作成し、ダウンロードする
!zip -r /content/wonwoo.zip /content/drive/MyDrive/Aidemy_DataSet/SEVENTEEN/WONWOO
WONWOOは、147枚収集できていました。
おかしな画像は混じっていませんでしたが、必ずしも正方形ではなく、縦長か横長の写真が多いです。
モデルに学習させるときはresizeして縦横の長さを揃えたいのですが、そのままresizeすると歪曲してしまいそうです。

step2. 顔領域の切り取り
他の人はどうしているのか調べた結果、下記の記事で「顔領域」を切り取る方法を見つけました。
人物写真から顔領域だけ正方形で切り出すことができるようです。
▼参考記事:
KerasのCNNで、顔認識AIを作って見た〜スクレイピングからモデルまで〜
早速やってみましょう。
まず、顔領域だけを切り出した画像を保存するためのディレクトリを作成します。
member_faceDir_list = [dir + "_face" for dir in member_dir_list]
for dir in member_faceDir_list:
# ディレクトリが存在しない場合:ディレクトリを作成する
if not os.path.exists(dir):
os.makedirs(dir)
# ディレクトリが存在しており、かつファイルが含まれている場合:中身を削除してから再作成する(初期化のため)
else:
file_cnt = sum(os.path.isfile(os.path.join(dir, name)) for name in os.listdir(dir))
if file_cnt > 0:
shutil.rmtree(dir)
os.mkdir(dir)
# print(member_faceDir_list[0])
# >>>/content/drive/MyDrive/Aidemy_DataSet/SEVENTEEN/WONWOO_face
元の画像から顔領域を切り出して、先ほど作成したディレクトリに保存します。
# カスケード型識別器のpathを設定
# OpenCVのGit(https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml)からDLし、MyDriveにアップロードしたもの
main_path = r"/content/drive/MyDrive/git_dl/"
cascade_path = os.path.join(main_path, "haarcascade_frontalface_default.xml")
# カスケード型識別器の読み込み
faceCascade = cv2.CascadeClassifier(cascade_path)
for files, dir in zip(member_files_list, member_faceDir_list):
#files: オリジナル画像のファイルパスのリスト
#dir:オリジナル画像から切り出した顔領域画像を保存するディレクトリパス
for f in files:
# 入力画像の配列データを読み込み
img = cv2.imread(f)
# グレースケール変換(カラースケールでも十分顔検出が可能だが、グレースケールを使用することで高速に顔検出できる)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 顔領域の探索
face = faceCascade.detectMultiScale(img_gray, scaleFactor=1.1, minNeighbors=3)
if len(face) > 0:
# 顔領域の位置情報(1画像に1つの顔しかない前提。複数の顔があるときはfor文にする)
rect = face[0]
x, y = rect[0], rect[1] #顔領域の開始座標
w, h = rect[2], rect[3] #顔領域の幅
# 顔領域のみ切り取って保存
face_area = img[y:y+h, x:x+w]
file_name = f.split("/")[-1].replace(".jpg", "") + "_face.jpg" #元のファイル名に_faceをつける
file_path = os.path.join(dir,file_name)
cv2.imwrite(file_path,face_area)
先ほどと同じ要領で、ローカルで画像を確認します。
大多数がうまく切り取れているのですが、失敗しているものもちらほら・・・

step3. 失敗画像の除外
失敗画像はデータセットから除外する必要があります。
パッと見た感じ、失敗画像はサイズがやたら小さいので、サイズ昇順でソートして、失敗している画像のファイル番号をメモします。
メモした画像番号をもとに、失敗画像のファイルパスのリストを作成します。
wonwoo_out_list = [13,59,60,36,5,54,116,147,80,20,122,109,37,28,68,6,133,51,120,26,14,65,
48,49,33,133,51,120,26,14,65,48,49,33,42,140,63,95,142,130,134,47,35,144,1]
seungkwan_out_list = [10,47,53,85,42,55,63,87,110,79,113,103,112,128,59,131,24,124,66,56,28,
141,19,8,49,30,72,54,3,41]
vernon_out_list = [118,39,7,104,14,94,95,51,32,36,60,21,110,12,120,127,34,119,109,131,6,
62,5,31,27,65,21,134,125,135,117,89,52,81,122]
# ファイル番号とディレクトリパスを渡すと、正しいファイルパスを返す関数を作成
def fpath_make(file_num, dir_path):
file_name = "{}_face.jpg".format(str(file_num).zfill(6))
file_path = os.path.join(dir_path, file_name)
return file_path
# メンバーごとに除外したい画像のファイルパスのリストを作成
wonwoo_out_list = [fpath_make(num, member_faceDir_list[0]) for num in wonwoo_out_list]
seungkwan_out_list = [fpath_make(num, member_faceDir_list[1]) for num in seungkwan_out_list]
vernon_out_list = [fpath_make(num, member_faceDir_list[2]) for num in vernon_out_list]
# print(wonwoo_out_list[0])
# >>> /content/drive/MyDrive/Aidemy_DataSet/SEVENTEEN/WONWOO_face/000013_face.jpg
# メンバーごとに除外したい顔領域の画像のファイルパスのリストをつなげて、一元化する
all_out_list = wonwoo_out_list + seungkwan_out_list + vernon_out_list
# print(len(all_out_list))
# >>> 110
実際にデータセットから失敗画像を除外していきます。
が、わりと数が多い(一人あたり30画像以上なので、元画像の2割程度が失敗)ので、データセットがだいぶ減ってしまいます。
迷いましたが、失敗している場合は元画像を使うことにしました。(モデル構築後に、元画像と顔領域画像の正解率を比較して、元画像の正解率が悪ければ抜こうと思います。)
新しくALLというディレクトリを作成し、顔領域の切取りに成功している画像、失敗している場合は元画像を保存します。
# SEVENTEENディレクトリの下にALLという名前のディレクトリを作成
all_dir = os.path.join(main_dir, "ALL")
if not os.path.exists(all_dir):
os.mkdir(all_dir)
# 顔領域がうまく切り取れていれば顔領域画像を、そうでなければオリジナル画像をALLディレクトリに格納
# その際、画像データと新しいファイルパスをリストに格納する
faceFile_list = []
faceImg_list = []
for dir in member_faceDir_list:
# メンバー名
member_name = dir.split("/")[-1].replace("_face","") #WONWOO
# 顔領域のファイルパスのリスト
files = [os.path.join(dir, f) for f in os.listdir(dir) if os.path.isfile(os.path.join(dir, f))]
for f in files:
# 顔領域がall_out_listにない場合は、顔領域の画像のファイルパスをtarget_fに格納
if f not in all_out_list:
target_f = f #/content/drive/MyDrive/Aidemy_DataSet/SEVENTEEN/WONWOO_face/000002_face.jpg
# 顔領域がall_out_listに含まれる場合は、オリジナル画像のファイルパスをtarget_fに格納
else:
target_f = f.replace("_face","") #/content/drive/MyDrive/Aidemy_DataSet/SEVENTEEN/WONWOO/000001.jpg
# 画像を配列データで読み込む
img = cv2.imread(target_f)
# チャネルの順番がBGRになっているので、RGBで取り込みなおす
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
# 新しいファイル名(ファイル名の頭にメンバー名を付ける)
new_file_name = member_name + "_" + target_f.split("/")[-1] #WONWOO_000002_face.jpg
# 新しいファイルパス
new_file_path = os.path.join(all_dir, new_file_name)#/content/drive/MyDrive/Aidemy_DataSet/SEVENTEEN/ALL/WONWOO_000002_face.jpg
# ALLディレクトリに画像を保存する
cv2.imwrite(new_file_path,img)
# ファイルパスと画像データを配列に格納する
faceFile_list.append(new_file_path)
faceImg_list.append(img)
spte4. 画像の水増し
収集した画像は一人あたり約150枚でした。
精度を上げるために、画像の水増しをしてみます。
まず、オリジナル画像に対して4パターンで加工し、加工名と配列データの辞書を返す関数を作成します。
def img_generate(origin_img):
# 右に90度回転
flip1_img = cv2.rotate(origin_img, cv2.ROTATE_90_CLOCKWISE)
# 左に90度回転
flip2_img = cv2.rotate(origin_img, cv2.ROTATE_90_COUNTERCLOCKWISE)
# ぼかしを入れる
#blur_img = cv2.GaussianBlur(origin_img, (5,5), 0)
blur_img = cv2.blur(origin_img, (10, 10))
# 閾値処理を入れる
thr_img = cv2.threshold(origin_img, 100, 255, cv2.THRESH_TOZERO)[1]
# 処理名のラベルのリストを作成
img_list = [flip1_img, flip2_img, blur_img, thr_img]
label_list = ["flip1", "flip2", "blur", "thr"]
# 加工した画像とラベルの辞書を作成
img_dict = dict(zip(label_list,img_list))
return img_dict
動作確認をしてみます。こんな感じです。
img_dict = {"original":faceImg_list[1]}
add_dict = img_generate(faceImg_list[1])
img_dict.update(add_dict)
fig = plt.figure()
for i, s in enumerate(img_dict.items()):
label,img = s[0], s[1]
fig.add_subplot(2,3,i+1).set_title(label)
plt.imshow(img)

ALLディレクトリに水増しした画像を保存していきます。
これで画像の用意は完了です。
faceFile_list_final = []
faceImg_list_final = []
label_list_final = []
for f,img in zip(faceFile_list, faceImg_list):
# 加工前の画像のファイルパスと画像データをリストに格納。
faceFile_list_final.append(f)
faceImg_list_final.append(img)
# 加工前の画像のファイル名を取得
file_name = f.split("/")[-1].replace(".jpg","") #WONWOO_000002_face
# 加工ラベルをリストに格納。
if "face" in file_name:
label = "face_original"
else:
label = "portrait_original"
label_list_final.append(label)
# 画像を水増しする
img_dict = img_generate(f)
for gen_label,gen_img in img_dict.items():
# 保存するときのファイル名とパスを設定
gen_file_name = file_name + "_" + gen_label + ".jpg" #WONWOO_000002_face_flip1.jpg
gen_file_path = os.path.join(all_dir, gen_file_name)
# ALLディレクトリに生成した画像を保存する
cv2.imwrite(gen_file_path, gen_img)
# 生成した画像のファイルパスと画像データとラベルをリストに格納。
faceFile_list_final.append(gen_file_path)
faceImg_list_final.append(gen_img)
label_list_final.append(label + "_" + gen_label)
step5. モデル投入用に成形
モデルに投入するデータは、下記の手順で成形します。
- 目的変数(画像がどのメンバーかを示すデータ)の作成
- 説明変数(画像の配列データ)の作成
- ランダムに並べなおしてから、8:2で学習用と検証用に分割
# [1] モデルの目的変数データを作成
# メンバー名と分類番号を対応させる辞書を作成
class_dict = dict(zip(member_name_list, range(len(member_name_list))))
# print(class_dict)
# >>>{'WONWOO': 0, 'SEUNGKWAN': 1, 'VERNON': 2}
# ファイル名からメンバー名を取得し、分類番号を返す関数を作成
def classnum_make(file_path):
file_name = file_path.split("/")[-1] #WONWOO_000002_face_add_1.jpg
member_name = file_name.split("_")[0] #WONWOO
class_num = class_dict[member_name] #0
return class_num
# ALLディレクトリに保存されているファイル名からメンバー名を取得し、分類番号を格納
y = [classnum_make(f) for f in faceFile_list_final]
# print(np.unique(y, return_counts=True))
# (array([0, 1, 2]), array([524, 488, 556]))
# [2] モデルの説明変数データを作成
X = []
img_size = 100 #リサイズ後の一辺の長さ
# ALLディレクトリに保存されている画像データをリサイズをしてから配列に格納
for img in faceImg_list_final:
# 解像度を落とすためにリサイズする
img = cv2.resize(img,(img_size,img_size))
# 配列に格納する
X.append(img)
# [3] ランダムに並べなおしてから、学習用と検証用に分割
# 配列をリストからnumpy配列に変換。
X = np.array(X) #説明変数
y = np.array(y) #目的変数
# 配列のインデックスをランダムに並べなおす
np.random.seed(42)
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# 学習データと検証データに分割
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
#print(X_train.shape)
#print(y_train.shape)
#print(X_test.shape)
#print(y_test.shape)
# >>>
# (1254, 50, 50, 3)
# (1254,)
# (314, 50, 50, 3)
# (314,)
# 正解ラベルをone-hotベクトル化
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# print(y_test[:5])
# >>>
# [[0. 1. 0.]
# [1. 0. 0.]
# [0. 0. 1.]
# [1. 0. 0.]
# [0. 0. 1.]]
# 顔領域の切取り失敗のために入れた元画像の正解率の検証用
labels_random = []
for idx in rand_index:
label = label_list_final[idx]
labels_random.append(label)
labels_train = labels_random[:int(len(labels_random)*0.8)]
labels_test = labels_random[int(len(labels_random)*0.8):]
5. モデルの構築と評価
いよいよモデルを構築していきます。
精度の向上と時間短縮のため、一からモデルを構築するのではなく、転移学習のモデルとして有名なVGG16を使用しました。
▼参考記事:
VGG16とは?構造と共に分かりやすく解説
VGG16に、自作モデルを連結することでモデルを構築します。
自作モデルにおいては、様々なハイパーパラメーターを調整して精度をあげていきます。
初回は、下記で実行してみました。
- 中間層:1つ(ユニット数は256)
- 活性化関数:中間層sigmoid、出力層softmax
- Dropout率:0.5
- エポック数(学習回数):10
- バッチサイズ(一度に読み込むデータ数): 32
エポック数とバッチサイズはもう少し多くしてもいいと思うのですが、実行完了にどれくらい時間がかかるかわからないので、様子見で少なめに設定した次第です。(約45分かかりました。)
▼参考記事:
畳み込みネットワークCNN(Convolutional neural network)
ディープラーニングにおける中間層の役割とは?基本的な仕組みや考え方を解説
活性化関数のまとめ
ディープラーニング初心者が知りたいKerasにおけるdropoutの使い方
機械学習/ディープラーニングにおけるバッチサイズ、イテレーション数、エポック数の決め方
# モデルの入力画像として用いるためのテンソールのオプション
input_tensor = Input(shape=(img_size,img_size, 3))
# 転移学習のモデルとしてVGG16を使用
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# 転移学習の自作モデルを作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256,activation='sigmoid'))
top_model.add(Dropout(0.5))
# 分類したい人数を入れる
top_model.add(Dense(len(member_name_list),activation='softmax'))
# VGG16と自作のtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# VGG16による特徴抽出部分の重みを19層までに固定(以降に新しい層(top_model)が追加)
for layer in model.layers[:19]:
layer.trainable = False
# 訓練課程の記録
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
# コンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9),
metrics=['accuracy'])
# 構築したモデルを確認
model.summary()
# 学習の実行
history = model.fit(X_train, y_train, batch_size=32,
epochs=10, verbose=1, validation_data=(X_test, y_test))
# acc, val_accのプロット
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
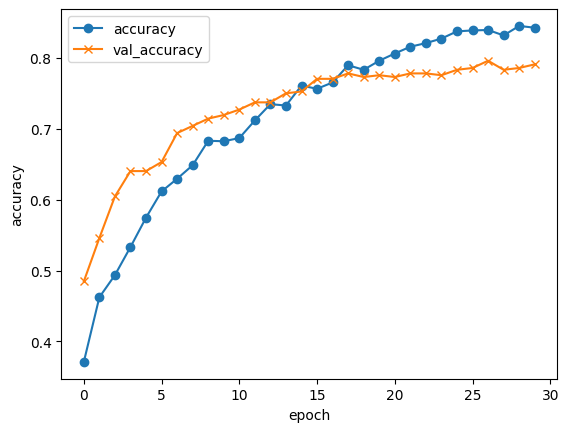
精度を確認します。
エポック数の分、accuracy(訓練データの精度)とval_accuracy(検証データでの精度)をプロットしたグラフがこちらです。
accuracyのみ精度が伸びて、val_accuracyが伸び悩んだ場合は、過学習を起こしているということになります。
今回は両方とも同じように伸びているので、過学習は起こしていないようです。
が、Test accuracyが0.7を切っているので、精度はまだまだです。目標は0.8はです。
Test loss: 0.8047754764556885
Test accuracy: 0.6760203838348389

もしかしたら、顔領域の切取りに失敗した場合は元画像を使ったことで、精度が下がっているかもしれません。
元画像(ラベル名:portrait)と顔領域画像(ラベル名:face)ごとに、検証用データの正解率を比較してみました。
結果、元画像は65%、顔領域画像は68%と、僅差だったので元画像はそのまま使うことにしました。
# 検証用データの推測結果と正解をリストに格納。
pred_y = model.predict(X_test)
pred_y_classes = np.argmax(pred_y,axis = 1)
true_y= np.argmax(y_test,axis = 1)
# 画像データがpotraitかfaceかに分類したリストを作成
type_labels = [label.split("_")[0] for label in labels_test]
# データフレーム化し、portrait/faceごとに正解率を集計
result_df = pd.DataFrame({"true":true_y, "pred":pred_y_classes, "type_label":type_labels})
result_df['flg'] = (result_df['true'] == result_df['pred']).astype(int)
result_df_gp = result_df.groupby("type_label")["flg"].agg(['count','sum'])
result_df_gp['true_ratio'] = result_df_gp['sum']/result_df_gp['count']
# print(result_df)
# >>>
# true pred type_label flg
# 0 1 1 face 1
# 1 2 2 portrait 1
# 2 0 0 face 1
# 3 1 0 face 0
# 4 2 2 face 1
# print(result_df_gp)
# >>>
# count sum true_ratio
# type_label
# face 288 197 0.684028
# portrait 104 68 0.653846
精度をあげるために、パラメーターを調整してみます。
エポック数を10から30にしました。
結果、Test Accuracyがほぼ0.8になりました!
他のハイパーパラメーターを調整すればもっと上がるかもしれないのですが、実行完了に2時間以上かかるので、一旦これでOKとします。
Test loss: 0.5714932084083557
Test accuracy: 0.7908163070678711
構築したモデルはアプリに組み込むので、h5ファイルで保存してダウンロードします。
# resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# h5ファイルでをモデルを保存
model_name = 'seventeen_classification_model_v6.h5'
model_path = os.path.join(result_dir, model_name)
model.save(model_path)
# 保存したモデルをダウンロード
from google.colab import files
files.download(model_path)
6. 予測結果についての考察
検証データ予測結果について、少し掘り下げてみたいと思います。
まず、正解率がメンバーごとに偏っていないか確認してみました。
ほぼ同じです。
true_member
SEUNGKWAN 118 94 0.796610
VERNON 154 121 0.785714
WONWOO 120 95 0.791667
次に、予測が間違っていた場合、どのメンバーに間違われやすいのかを確認しました。
VERNONとWONWOOはほぼ偏りなしですが、SEUNGKWANは誤判定の24画像中15画像がVERNONと判定されているようです。
二人とも目がパッチリしているという共通点があるからでしょうか。
でもVERNONは、SEUNGKWANよりもWONWOOに誤判定されることのほうが多いので、謎です。
true_member pred_member
SEUNGKWAN VERNON 15
WONWOO 9
VERNON SEUNGKWAN 15
WONWOO 18
WONWOO SEUNGKWAN 13
VERNON 12
最後に、誤判定された画像に何か特徴がないか、目視で確認しました。
正直、そこまでおかしな点はなかったです。
強いて言えば、下記の画像のようにやや表情が特殊な画像が含まれている、ということでしょうか。
もっと定量的な特徴を見つけることができればいいのですが、今後の課題としたいと思います。

7. アプリの実装
ここのくだりは、詳しく説明するとかなり長くなるので、webページデザイン用のコードと、アプリを動かすコードのみ記載します。
詳細が気になる方は、ぜひAidemyさんのAIアプリ開発コースを受講してみてください!
webページの文書構造を定義するコード(html)
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>SEVENTEEN Member Classifier</title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<img class="header_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<a class="header-logo" href="#">SEVENTEEN Member Classifier</a>
</header>
<div class="main">
<h2>SEVENTEENは13人で構成されるKPOPグループです。<br>AIが送信された画像がどのメンバーか識別します。</h2>
<p>WONWOO(ウォヌ)、SEUNGKWAN(スングァン)、VERNON(バーノン)から一人選んで画像を送信してください。<br>※正面の顔が大きく映っている正方形の写真がベストです!</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="submit!" type="submit">
</form>
<div class="answer">{{answer}}</div>
<ul>
<li><div class="member">
<img class="member_img" src="https://s3-ap-northeast-1.amazonaws.com/pf-web/fanclubs/15/assets/17/images/profile/wonwoo_s.jpg" alt="WONWOO" width="200px" height="200px">
<p>WONWOO</p></div></li>
<li><div class="member">
<img class="member_img" src="https://s3-ap-northeast-1.amazonaws.com/pf-web/fanclubs/15/assets/17/images/profile/seungkwan_s.jpg" alt="SEUNGKWAN" width="200px" height="200px">
<p>SEUNGKWAN</p></div></li>
<li><div class="member">
<img class="member_img" src="https://s3-ap-northeast-1.amazonaws.com/pf-web/fanclubs/15/assets/17/images/profile/vernon_s.jpg" alt="VERNON" width="200px" height="200px">
<p>VERNON</p></div></li>
</ul>
</div>
<footer>
<img class="footer_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<small>© 2019 Aidemy, inc.</small>
</footer>
</body>
</html>
webページの見た目を定義するコード(css)
header {
background-color: #b2cbe4;
height: 60px;
margin: -8px;
display: flex;
flex-direction: row-reverse;
justify-content: space-between;
}
.header-logo {
color: #fff;
font-size: 25px;
margin: 15px 25px;
}
.header_img {
height: 25px;
margin: 15px 25px;
}
.main {
height: 600px;
}
h2 {
color: #444444;
margin: 50px 0px;
text-align: center;
}
p {
color: #444444;
margin: 30px 0px 30px 0px;
text-align: center;
}
.answer {
color: #444444;
margin: 30px 0px 30px 0px;
text-align: center;
}
form {
text-align: center;
}
ul {
display: flex; /*横並び*/
justify-content: center; /*中央ぞろえ*/
list-style: none; /*li要素の点を消す*/
}
li {
margin:10px;/*余白を指定*/
padding:10px;/*余白を指定*/
}
.member {/*親div*/
position: relative;/*相対配置*/
}
.member p {
position: absolute;
bottom: 0px;
right: 5px;
font-size: 15px;
color: white;
}
.member img {
width: 100%;
display: block;
}
footer {
background-color: #b2cbe4;
height: 60px;
margin: -8px;
position: relative;
}
.footer_img {
height: 25px;
margin: 15px 25px;
}
small {
margin: 15px 25px;
position: absolute;
left: 0;
bottom: 0;
}
アプリを動かすコード(python)
webページからアップロードした画像を受け取り、学習したモデルで識別し、その結果を表示するコードです。
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["WONWOO","SEUNGKWAN","VERNON"]
image_size = 100
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./seventeen_classification_model.h5',compile=False)#学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, target_size=(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
完成したアプリ
こちらが完成したアプリです!
https://flask-seventeen-app.onrender.com
ファイルを選択ボタンから画像をアップロードし、送信すると、メンバー名を返してくれます。

8. おわりに
長い道のりでしたが、とても勉強になりました。
ブログでは比較的さらっと目標の精度に達したかのように書いていますが、実は前半にかなりの試行錯誤を繰り返しています。
最初は顔領域の切取りも水増ししていなかったですし、VGG16を使った転移学習を使わずにやったらどうなるか、Dropoutを設定しなかったらどうなるか、色々やってみた上で、最終的にたどり着いたのがブログに書いたやり方です。
パラメーターの調整ももっと試してみたかったのですが、永遠に終わらなさそうだったので、一旦目標に達した時点で完了としました。
学習を始めた当初は、CNNの仕組みや、モデルのハイパーパラメーターについての説明を読んでもピンときていなかったですし、正直なところ今でも理解はまだまだ浅いのですが、実装のために色々調べたり試行錯誤する過程で、少しずつ知識が馴染んできた気がします。
せっかくなので、また別のアプリも作ってみたいと思います。
ここまで読んでいただき、ありがとうございました!