Keras、TensorFlow、Pytorchなどの機械学習/ディープラーニングのフレームワークを利用する際、
- バッチサイズ
- イテレーション数
- エポック数
などのハイパーパラメータを決める必要があります。
しかし、どうやって決めれば良いのかよく分からず、サンプルプログラムで設定している数値をそのまま使う場合が多いと思います。
そこで、これらのハイパーパラメータの決め方について説明します。
結論を先に言ってしまうと、この場合はこうですという定番の方法があるわけではなく、問題毎にそれぞれのハイパーパラメータをうまく調整していくしかありません。
じゃあ、どうやってうまく調整してくのかということを述べる前に、これらのハイパーパラメータの意味について説明します。
ハイパーパラメータの意味が分かれば、どのように調整していけば良いのかなんとなく分かってくるかと思います。
バッチサイズとは?
ディープラーニングでは、損失関数を最小化して最適なパラメータ(重み、バイアス)を見つけるために勾配降下法と呼ばれる手法が使われます。
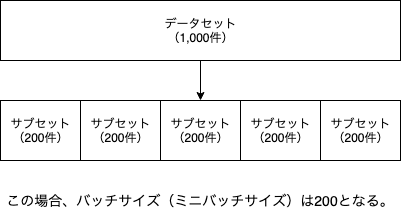
多くの場合、ミニバッチ勾配降下法というバッチ勾配降下法と確率的勾配降下法の間を取った手法が使われ、データセットを幾つかのサブセットに分ける必要があります(学習データとテストデータに分けるのとは別の話しです)。
そして、この幾つかに分けたぞれぞれのサブセットに含まれるデータの数をバッチサイズと呼びます。
例えば、1,000件のデータセットを200件ずつのサブセットに分ける場合、バッチサイズは200となります。
また、バッチサイズのことをミニバッチサイズと呼ぶこともあります。
バッチサイズは機械学習の分野の慣習1として2のn乗の値が使われることが多く、32, 64, 128, 256, 512, 1024, 2048辺りがよく使われる数値だと思います。
データセットの件数が数百件程度であれば32, 64をまずは試してみて、数万件程度であれば1024, 2048をまずは試して見るのが良いのではないでしょうか。
そして、学習がうまくいっておらず、他に調整するパラメータがなくなった時にバッチサイズを大きくしたり小さくしたりするのが良いと思います。
イテレーション数とは?
イテレーション数はデータセットに含まれるデータが少なくとも1回は学習に用いられるのに必要な学習回数であり、バッチサイズが決まれば自動的に決まる数値です。
先程の1,000件のデータセットを200件ずつのサブセットに分ける場合では、イテレーション数は5 (=1,000/200)となります。
つまり、学習を5回繰り返す(イテレートする)ということです。
エポック数とは?
- データセットをバッチサイズに従ってN個のサブセットに分ける。
- 各サブセットを学習に回す。つまり、N回学習を繰り返す。
1と2の手順により、データセットに含まれるデータは少なくとも1回は学習に用いられることになります。
そして、この1と2の手順を1回実行することを1エポックと呼びます。
つまり、エポック数とは1と2の手順を何回実行するのかということです。
普通、1エポックで十分に学習されることはなく、数エポックから数十エポック回すことが多いです。
では、何回エポックを回せば十分なのでしょうか?
答えとしては、損失関数(コスト関数)の値がほぼ収束するまでです。
そして、データの性質や件数によって収束するまでに掛かる回数は異なるので、実際に幾つかの数値で試してみて損失関数の推移を見るしかありません。
また、ほぼ収束と書いたのは、完全に収束まで実行すると過学習になる恐れがあるためです。
バッチサイズ、イテレーション数、エポック数の決め方
ここまで読んで頂ければ、これらのハイパーパラメータの決め方がなんとなく分かってきたと思います。
バッチサイズについては、データセットのサイズが小さければ32, 64などの小さめの値、大きければ1024, 2048などの大きめの値をまずは使ってみるのがよいでしょう。
そして、バッチサイズが決まればイテレーション数は自動的に決まります。
最後に、エポック数は幾つかの数値で試してみて、損失関数の値の推移を見ながら最適そうな値を探すということになります。
参考資料
Epoch vs Batch Size vs Iterations (Medium)
-
SVMの代表的なライブラリであるLIBSVMのグリッドサーチでは2のn乗刻みで最適なパラメータを探索する。 ↩