この記事について
この記事は某企業アドベントカレンダー2024の9日目の記事で,2日目の記事の続きとなります.
前回のあらすじ
ぷよぷよの色を分類するために,機械学習モデルを作成することにしました.その過程でなんとぷよぷよたちは色情報を抜かれてしまいました!
色情報のない色分類は果たして成功するのでしょうか...

↓

モデルの概要
いきなり機械学習と言われても,イメージが湧きませんよね.なのでまずは私たち人間がどのように分類しているかを考えてみましょう.
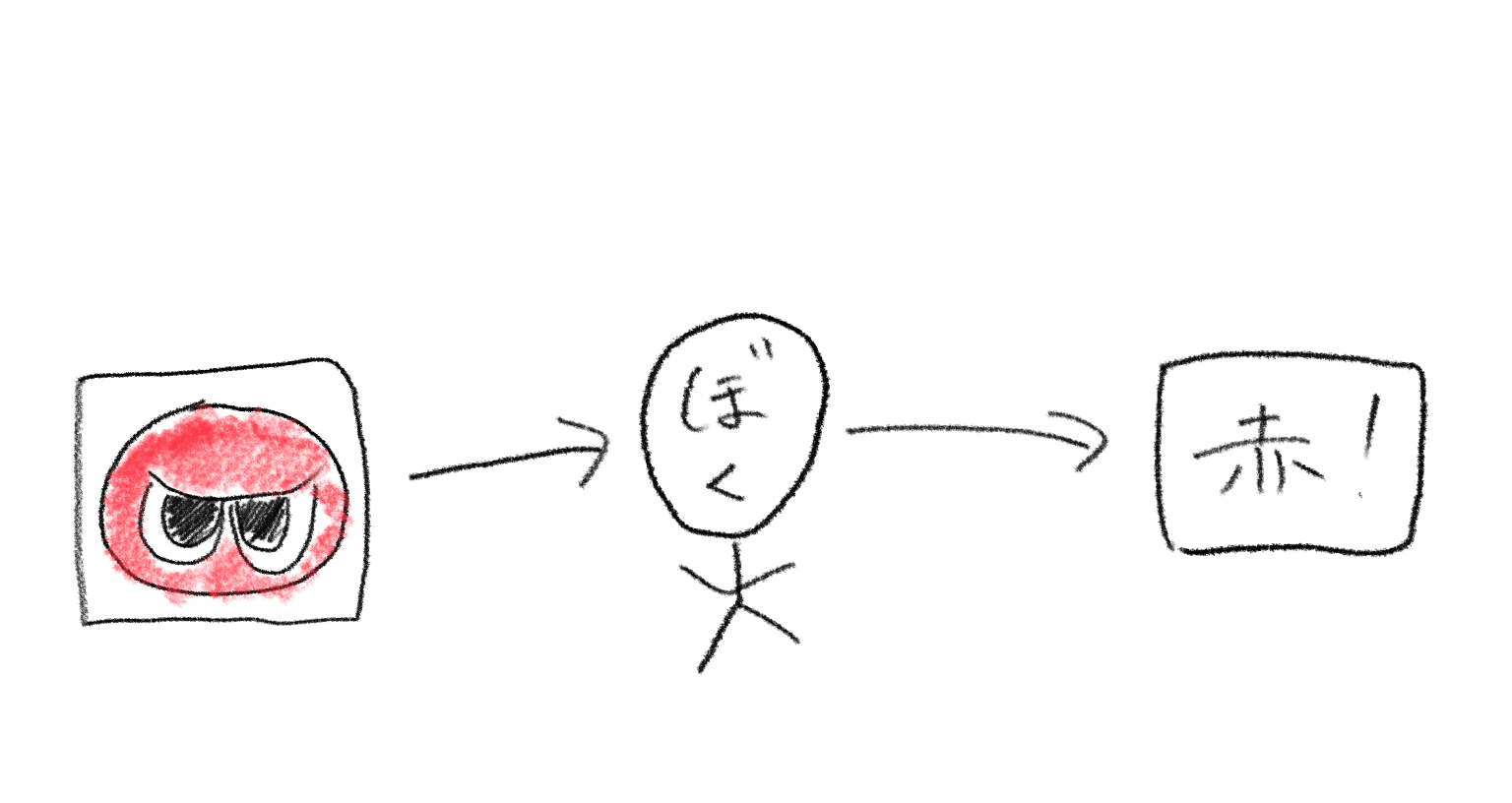
これは「ぼく」が赤いぷよを見たときに,赤だ!と叫んでいる図です.「ぼく」が赤色や,赤ぷよの形を認識しているわけですが,それ以上の細かいことは説明できないですよね.もっと分かりやすい例を出すと,犬を見たときに,なぜ犬だと判断したのか説明することは非常に難しくないですか?機械学習のすばらしいところは,この「なぜ」の部分を丸投げできてしまうところです.
モデルの作成
モデルの定義
ここでは学習するデータが分類されるまでのデータの流れを決めます.今回は28*28の画像を1次元化したデータセットを作成しているので,入力はが784(28 * 28)個で.出力は{RGBYPE}なので6個になります.
# モデルの定義
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(784, ))) # 中間層2
model.add(Dense(6, activation='softmax')) # 出力層 (6クラスの分類)
式中の64という値は今回気にしなくて構いません.また,activationで指定されているreluやsoftmaxについてはこちらを参考にしてください.https://qiita.com/namitop/items/d3d5091c7d0ab669195f
モデルのコンパイル
ここではモデルが学習する方法を設定します.
# モデルのコンパイル
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
データセットの読み込み
データセットは以下の3種類があります:
-
訓練用データ
モデルを学習させるために使用します -
検証用データ
学習中のモデルの性能を評価し、過学習を防ぐために使用します -
テスト用データ
学習が完了したモデルの最終的な性能を確認するために使用します
訓練用データと検証用データを合わせて学習データといいます。
以下はそれぞれの役割を簡単に示した図です:
| データセット種類 | 役割 |
|---|---|
| 訓練用データ | モデルの学習 |
| 検証用データ | 学習過程での性能評価 |
| テスト用データ | モデルの最終性能評価 |
ここで注意点があります.
絶対にテストデータを学習データに含めないでください
テスト用データはモデルの性能評価を行うための本番データであり、モデルから見て初見である必要があります。そのため、テストデータを学習データに含めてはならないというルールがあります。このルールを破ると、モデルが事前に解答を知っている状態で評価することになり、不正確な結果を招きます。
読み込み
学習データを読み込みます.データセットは1列目から785列目までに特徴量,786列目にラベルが格納されています.0列目にはデータのインデックス(何個目のデータかが分かる番号)が格納されていますが,学習には不要のため捨てます.
# データの読み込み
train_data = pd.read_csv('./_Merged/merged.csv')
train_images = train_data.iloc[:, 1:785].values
train_labels = train_data.iloc[:, 785].values
次に学習データを訓練用と検証用で分けます.
train_images, val_images, train_labels, val_labels = train_test_split(
train_images, train_labels, test_size=0.2, random_state=42
)
テストデータも読み込みます.
test_data = pd.read_csv('./_TestData/test_merged.csv')
test_images = train_data.iloc[:, 1:785].values
test_labels = train_data.iloc[:, 785].values
訓練
モデルの訓練は1行で行えます.指定しているパラメータは以下の通りです.
-
epochs
データセット全体を何回モデルに繰り返し学習させるかを指定します。参考書を何周するか,みたいなものです.1周では少ないですが,多すぎてもその参考書しか解けなくなるジレンマがあります. -
batch_size
一度にモデルへ入力するデータのサンプル数を指定します。まとめてデータを扱うので,学習が高速になりますが学習回数が減るデメリットもあります.
# モデルの訓練
model.fit(train_images, train_labels, epochs=10, batch_size=32,
validation_data=(val_images, val_labels))
実行結果
それでは訓練してみましょう!
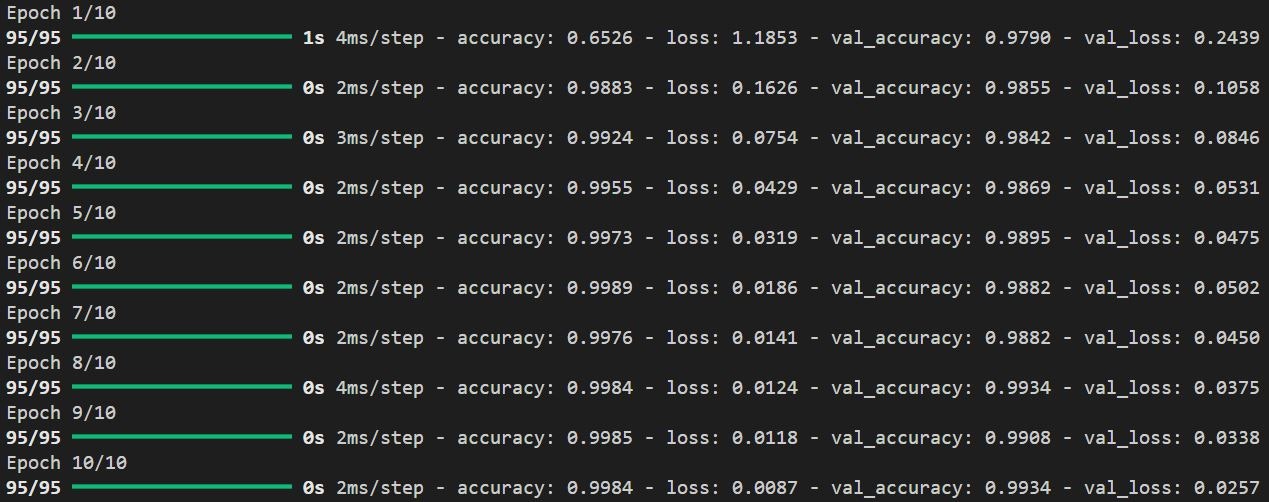
訓練結果の評価
注目すべき指標は、accuracy(正解率)です。
これは、モデルが検証データに対してどれだけ正確に分類できているかを示しています。
-
Epoch 1 終了時点:
- 正解率: 65.26%
→ 検証データ1000枚中約348枚が間違い.
- 正解率: 65.26%
-
Epoch 10 終了時点:
- 正解率: 99.84%
→ 検証データ1000枚中、わずか2枚しか間違えない!
モデルが非常に賢くなったことがわかります.
- 正解率: 99.84%
しかし、ここで重要なのはテストデータでのスコアです。
モデルが真に汎用的に学習できているかどうかは、テストデータでの性能で判断されます。
最後にモデルの評価を行います.
# モデルの評価
predictions = model.predict(test_images)
accuracy = model.evaluate(test_images, test_labels)
print('Test accuracy', accuracy[1])
気になる出力は...
テスト結果

99.84%!
テスト用データでも高いスコアを達成しました 🎉
モデルはしっかりと学習し、未知のデータに対しても優れた性能を発揮しています。
これは、モデルが過学習せず、汎化能力を持っていることを示しています。
上手くモデルの学習ができましたね!👏
実際の活用
実際にぷよぷよの画面をキャプチャして分類させてみましょう!
Youtubeから適当な試合を拝借して試してみます。
手順
-
ぷよぷよの試合画面をキャプチャ
↓ この画像をモデルに渡します

-
モデルに入力して...
そりゃ!
↓
↓
↓ -
分類結果
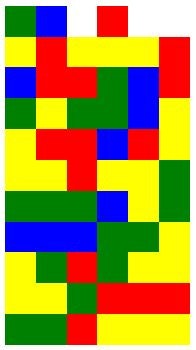
✨ 成功!しっかり分類できています!🎉
モデルの精度の高さが証明されましたね!
さいごに
本記事では,ぷよぷよの色認識を行うための機械学習モデルを作成しました.ここで紹介したアプローチは他の分類タスクにも応用ができますので,ぜひ試してみてください!
p.s.
色認識なのに,色情報なしで解けてしまいました.