この記事について
この記事は某企業アドベントカレンダー2024の2日目の記事になります.趣味techなノリで執筆させていただきます.
導入
ぷよぷよのプレイを棋譜化したくないですか?囲碁や将棋では当たり前の棋譜ですが,プレイが文字となって記録されるって多分ロマンチックだと思うんです.そこでまず必要になるのが,色の認識です.本記事ではぷよの分類に機械学習を応用する方法について述べます.
背景
たかが色認識に機械学習なんておおげさな気もします.色があるんだからもっと簡単に解けそうですよね.しかしそこにはぷよぷよ独自の制約があります.その制約の前に,最も簡単な色認識の方法について説明します.
簡単な色認識
デジタル画像はピクセル(点)の集合体で構成されています.昨今で最も馴染み深いフルHDでは,1920 * 1080個のピクセルがRGB(光の三原色)を混ぜ点灯し,画像を構成しています.
ぷよぷよももちろんデジタル画像なので,黄色のぷよはだいたい黄色に光っているはずです.しかし黄色といっても1種類ではないですね.オレンジは黄色か赤色か,というのは個人差があります.色ごとに境界を決めることで,色を認識することができます.ぷよぷよは6色(赤・緑・青・黄・紫・空き)なので,5つの境界を決めれば色を認識することができます.
RGBは扱いにくいので,HSVという似たような色空間を使います.話が逸れるので説明は省きます.HSVは図のようになっていて,直感的に境界を引けそうです.

[出典:https://emotionexplorer.blog.fc2.com/blog-entry-331.html]
次に認識に用いるピクセルの場所を決めます.とりあえず真ん中あたりでスポイトしてきます.

紫どうした...?これは白目のところから色を抽出してしまっていますね.このように1点から色を抽出すると案外うまくいきません.ぷよには目があり,形があり,顔の影もあり意外と豊富なグラデーションになっています.赤と黄,緑と青と紫は色味も近いため,グラデーションの場所によっては人間でも判断しづらいほど色が近くなります.今回は紫がダメそうですが,他の点で試してもぴったりココ!という点は見つかりませんでした.
それでは点ではなく,面で攻めましょう.ぷよ画像の色の平均値を取る方法が考えられます.しかし,さらなる悪条件が重なります.
ぷよには背景がある
1P側と2P側の盤面に注目してください.キャラクター画像に加えて1P側は赤く,2P側は緑色の透過がかかっています.

マスにおける背景の割合が2,30%ほどあるため,矩形全体で色認識を行うと大きなノイズになります.同じ緑色のぷよでも,背景が赤の時,緑の時ではかなり差が出ます.


う〜ん
背景を取り除いたり,確実に色認識をできるピクセル,もしくは矩形領域を見つけるなど,職人技的なアプローチは取れますが,泥臭くて面倒になりました.そんなときには機械学習による分類です.機械学習の有名なチュートリアルで,手書きの数字画像(MNIST)をAIに分類させるものがあります.ぷよにはこれほどまでに特徴的な顔があるので,AIに分類を任せてしまおうと思い立ったのです.
↓MNISTはこんな感じです.白黒の手書き数字のデータセットです.
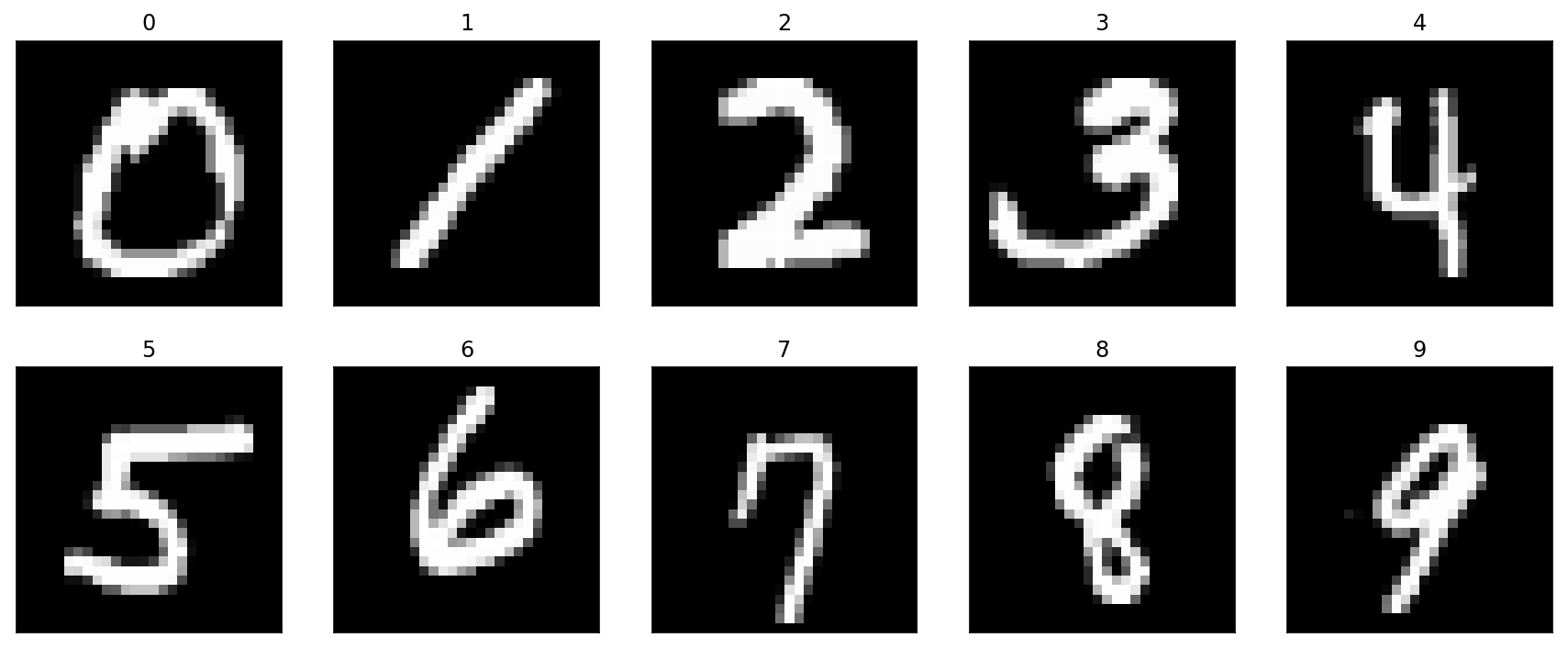
機械学習準備編
機械学習のアプローチはざっくり以下の通りです.
- データセットの作成
- モデルの学習
- モデルの評価
ということでまずはデータセットの作成に取り掛かりましょう.MNISTデータセットは28*28のグレースケール画像です.グレースケールというのは白黒のことです.色認識なのに,白黒...大丈夫です,ぷよぷよは顔と形で勝負しますから.色なんて要らないんです.
ここでMNISTとぷよ画像の違いをまとめます.
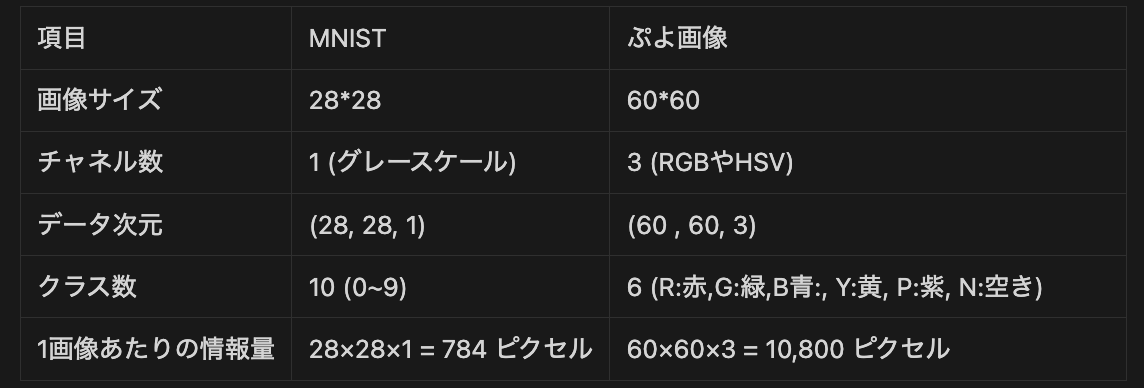
MNISTに比べて,ぷよ画像はかなり情報量が大きいです.画像サイズは特に困らないのですが,チャネル数が違う点が非常に面倒です.なぜなら,学習のアーキテクチャを変える必要があるからです.そのため,ぷよ画像も色を抜いてグレースケールにしてしまいましょう.グレースケール化したぷよ画像がこちら!

国民的パズルゲームですから,皆さんもちろん判別できますよね.左から赤緑青黄紫ですよ.
こんな感じのぷよ画像を大量に作っていきます.MNISTは全部で6万枚の画像が用意されていますが,流石にしんどいので各色500枚程度用意しました.まあ足りるでしょう,知らんけど.
プレイ動画をキャプチャして1マスずつトリミングしてグレースケール化します.私の場合はキャプチャは手動で行い,後の作業はpythonに任せました.生成AIに上手く伝えるとよしなに仕事してくれると思います.
最後にcsv化します.
MNISTデータセットはcsvになっていて,画像という2次元状態から1次元状態へ平坦化されています.人間が見るには画像は2次元の方が圧倒的に見やすいのですが,コンピュータが計算しやすいという理由で1次元にされています.一行にはラベルと特徴量(今回はグレースケール値)が格納されており,それが6万行あります.
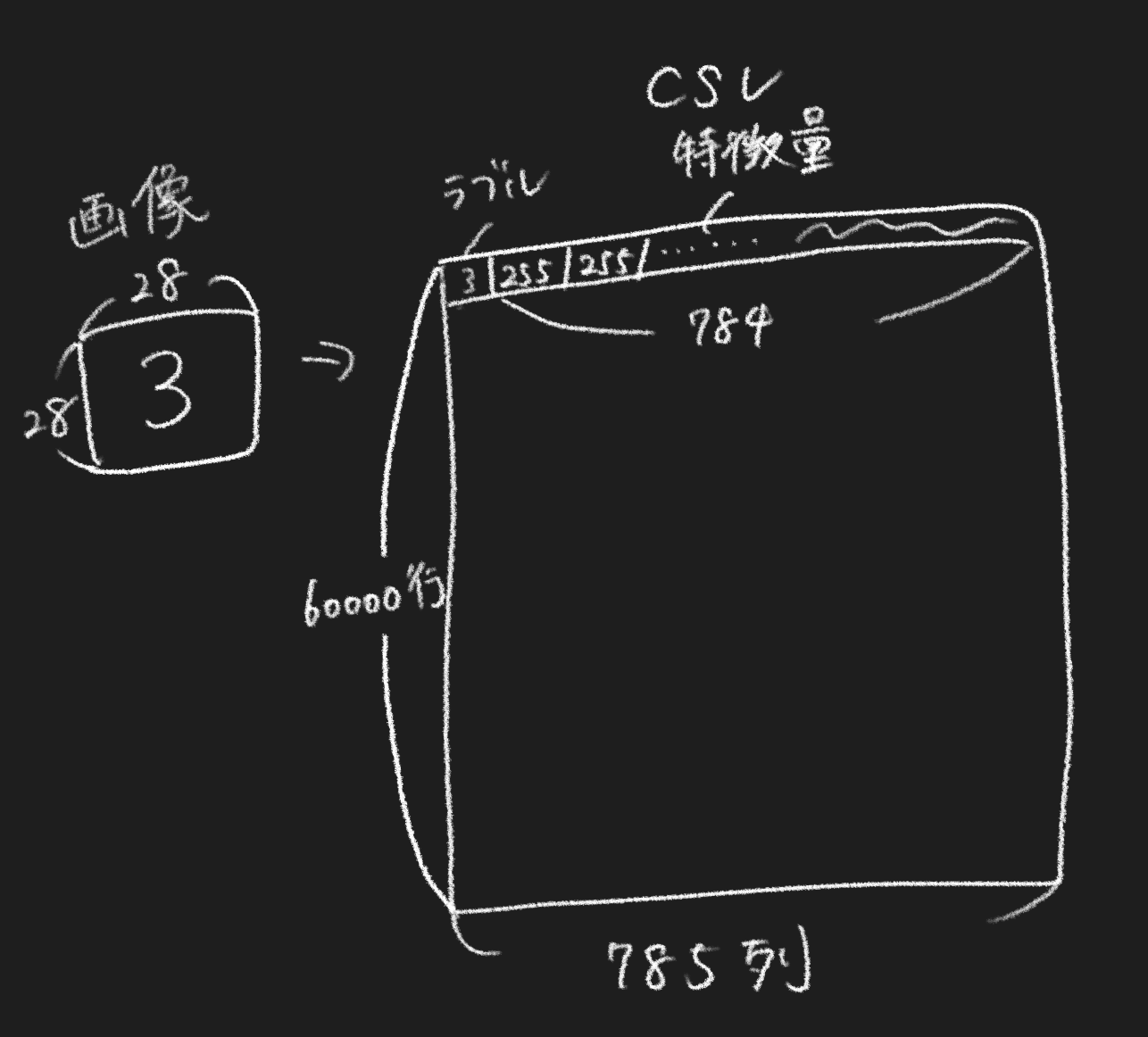
ぷよ画像もcsvにしたいので,R:1,G:2,B:3,Y:4,P:5,E:6と変換して,1次元に変換しましょう.この作業はFlattenや平坦化と調べれば簡単にできます.
私はこんな感じでデータが作成されました.
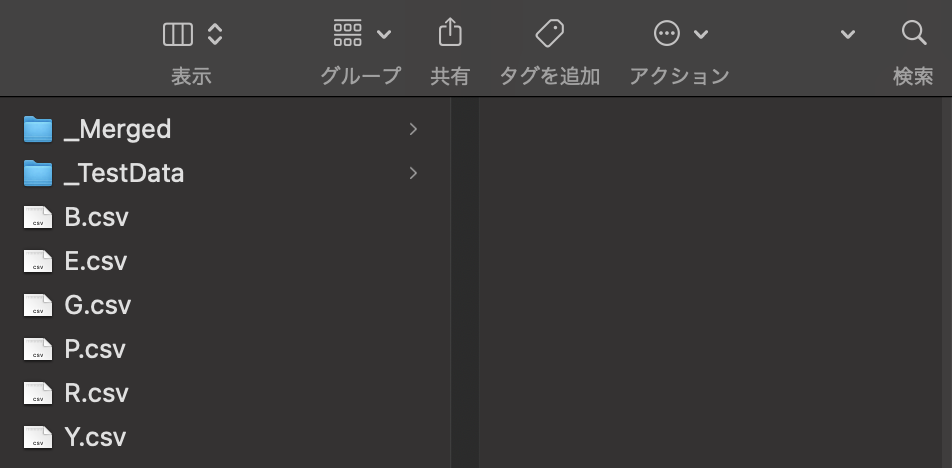
さいごに
これで下準備は完了しました!MNISTの1/20のデータ量で上手く分類モデルを作れるのでしょうか...
続きが気になる次回は 機械学習実践編 です.それではまた来週!