Databricksの弥生です。Databricks Japanにjoinして4年が経ちました。
ちょうど一年前にこちらの記事を書きました。
アドベントカレンダーの季節(皆様ご参加いただきありがとうございます!)ということもあり、改めて今時点のDatabricksをまとめてみたいと思います。
Databricksとは何か?
まず、会社としてのDatabricksの説明をさせてください。同名のプラットフォームを提供している企業で、2013年に創業されました。今年で11年目です。由来はユニークで、カルフォルニア大学バークレー校に在学していた大学院生と教授たちとで創業された会社です。そして、彼らはApache Spark、Delta Lake、MLflowのオリジナルクリエーターです。このような背景から、企業全体としてオープンソースにコミットしています。

おかげさまで、グローバル全体でのお客様が1万社を突破しております!
データインテリジェンスプラットフォームとは何か?
今ではDatabricksのプラットフォームの名称はデータインテリジェンスプラットフォームとなっています。2023年11月にレイクハウスプラットフォームから名称変更しました。レイクハウスの説明はこちらをご覧ください。レイクハウスという概念はDatabricksが2020年に発明したものです。4年経ってみると、Databricks以外の場所でも一般的に用いられる概念となっています。しかし、Databricksが別物に変わったのではなく、レイクハウスというアーキテクチャはそのままに、プラットフォーム自体に生成AIを取り込んで進化したのだと私は理解しています。

では、ここで用いられている用語データインテリジェンスとは何なのでしょうか。ここで対比としてあげるのが、汎用インテリジェンスです。これは、インターネット上の広範なデータを学習した生成AIです。非常に膨大な知識に基づいて解答を行うので、昨年の(実際には一昨年だそうですが)ChatGPTの出現は私を含め多くの人が驚いたことでしょう。一般常識や一般的なタスクであれば、非常に高い精度でタスクをこなす汎用インテリジェンスですが、企業でのユースケースを考えた場合にはどうでしょうか。
企業にはそれぞれのデータ、専門用語、分析手法が存在します。汎用インテリジェンスはそれらを完全に理解することができないため、企業が求める複雑なタスクを解決するには不十分です。仮に汎用インテリジェンスが企業固有のデータを学習していたとしたらそれは大きな問題となります。
そこで、Databricksが提唱するデータインテリジェンスの出番です。データインテリジェンスはデータに立脚して推論を行うインテリジェンス(生成AI) だと私は理解しています。これによって、企業固有のデータを直接活用し、企業のステークホルダーが求める解答を導き出すのがデータインテリジェンスです。
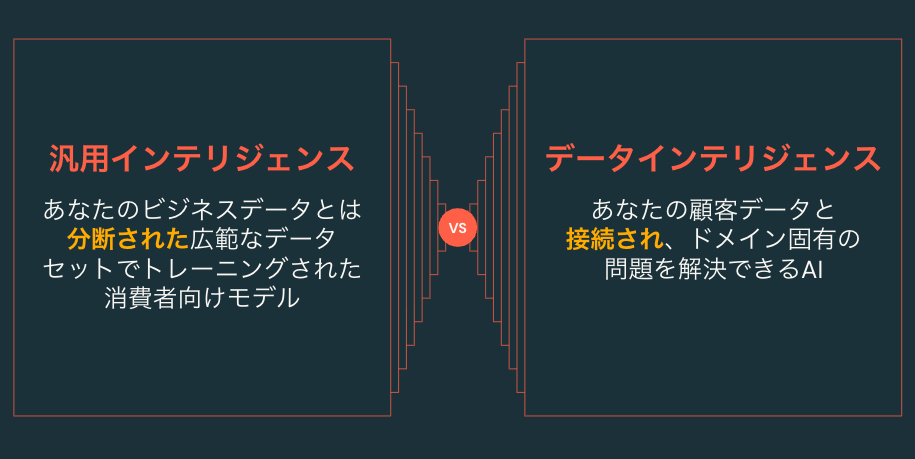
このようなデータインテリジェンスを企業で構築、活用するためのプラットフォームがデータインテリジェンスプラットフォームなのです。

Databricksの提供機能
Databricksの提供機能は多岐に渡ります。ここで、すべての機能を説明するのは大変なので上の図にある機能群にフォーカスします。ただ、言っておきたいのは、こちらで言及いただいているようにかゆいところに手が届くソリューションとなっています。データやAIに関係することで、「こういう取り組みしたいんだよな」や「こういう構成組めないかな」と思った場合には、十中八九Databricksでカバーできます。どのような機能があるのかを一覧したいのであれば、公式マニュアルや私のQiita記事のまとめページ(その1、その2)をご覧ください。
Mosaic AI
生成AIアプリケーションの開発、運用に関連する機能を提供しているのがMosaic AIです。これは昨年買収したMosaicMLから名前を取っています。データインテリジェンスの文脈で生成AIを活用するには、企業固有のデータの取り込み、エージェントシステムの構築、運用、評価というサイクルを回していくことが重要だとDatabricksでは考えています。
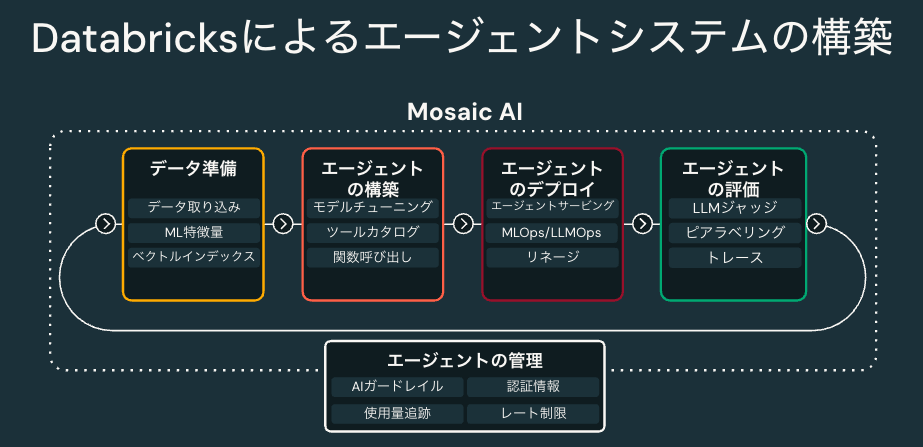
Mosaic AIではそれに必要な機能を提供しています。
- ベクトル検索: RAGで欠かせないベクトルデータベース。企業データと自動で同期することも可能です。
- エージェントフレームワーク: エージェントシステムのプロトタイピングから、評価、本番環境へのデプロイ、監視までエンドツーエンドで支援してくれるフレームワークです。
- モデルサービング: 生成AI(LLM)をアプリケーションから活用するためのREST APIエンドポイントを容易に構築できます。
- モデルトレーニング: 事前学習からファインチューニングまでをカバーしており、GUIやAPIから簡単にLLMをトレーニングすることができます。
- 特徴量ストア: テキストデータのみならず構造化データも活用するような生成AIアプリケーションを支援します。
- AutoML: 従来のMLモデルのAuto MLだけではなく、LLMのファインチューニングもAutoMLの枠組みで実施することが可能です。
- レイクハウスモニタリング: 従来のMLモデルや生成AIアプリケーションの精度、性能を継続的に監視することができます。
Databricks SQL
上でさらりと流してしまいましたが、レイクハウスの由来はデータレイク + データウェアハウスです。データレイク上のデータに対して、データウェアハウスのワークロードも実現可能にしましょうということです。なので、Databricksでは普通にデータウェアハウスとしての活用も可能です。Databricksでデータウェアハウスの機能を一手に引き受けてくれるのが、Databricks SQLです。

SQLクエリーによるデータベースへの問い合わせ、問い合わせ結果の可視化を行うことができます。SQLクエリーを作成する際には生成AIのアシスタント(Databricksアシスタント)が支援してくれるので、日本語で指示を出すことも可能です。日本語を駆使してどのようにクエリーを作成するのかに関しては、こちらのワークショップの流れをご覧ください。
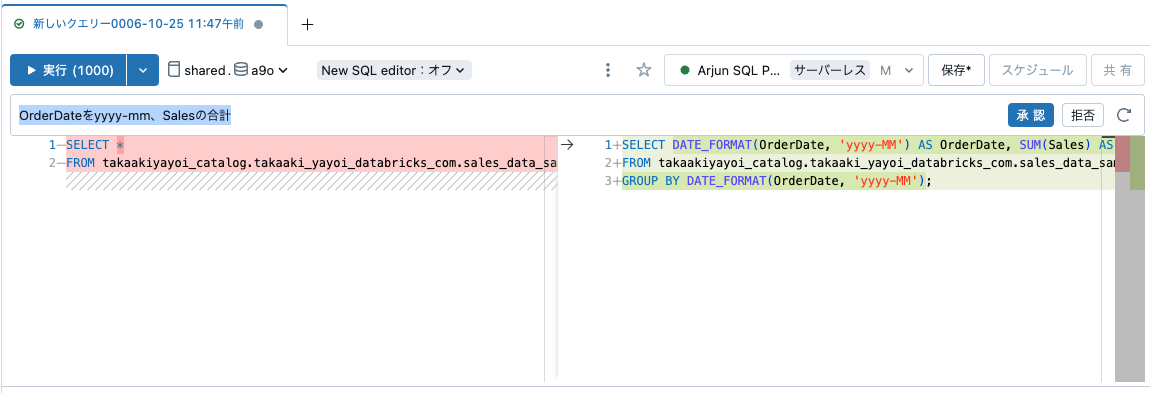
問い合わせ結果からシームレスに可視化、ダッシュボードを作成することができます。
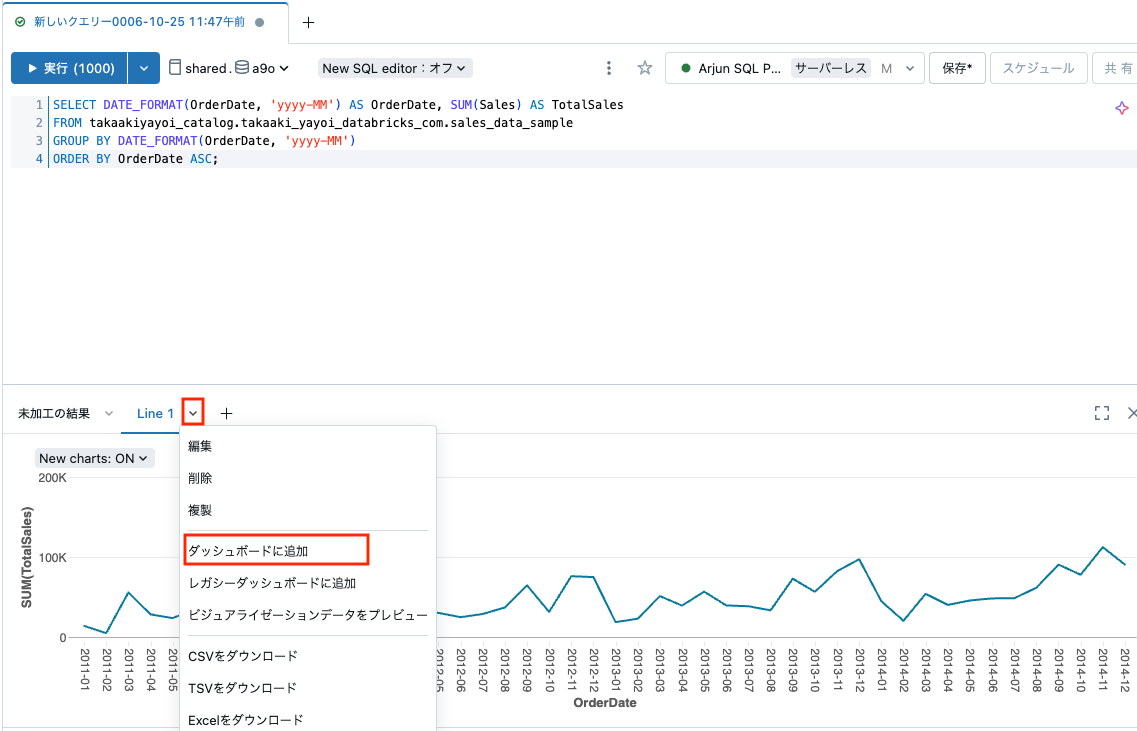
これ以外にも、基本的なデータウェアハウスの機能やガバナンスの機能を数多く提供しているので、既存のデータウェアハウスからの移行も容易です!

Workflows/DLT
Databricksのジョブ管理には、オーケストレーションソリューションであるワークフローを使用します。そして、データパイプラインの構築、運用にはDLT(Delta Live Tables)を活用いただくことで、パイプラインのロジックの開発にフォーカスいただけるようになります。

なお、今後は以下のようにDLTはLakeFlow Pipelines、ワークフローはLakeFlow Jobsとなり、LakeFlowの名の下に、データの取り込みから変換までをサポートする形になります。

LakeFlowは今年の6月のDatabricks最大の年次イベントData + AIサミットで発表されました。発表内容については、こちらのブログ記事をご覧ください。
AI/BI
昨年と比べて特筆すべき変化の一つとも言えるのが、こちらのAI/BIです。

名称が独特ですが、私はAIの支援を受けて行うBIだと理解しています。AI/BIは以下の二つのコンポーネントから構成されています。
-
AI/BIダッシュボード: 上述のDatabricks SQLとインテグレーションされているダッシュボード機能です。AIが含まれているダッシュボードとは?となるかもしれませんが、こちらのダッシュボード、日本語でダッシュボード作成を指示することができます。

-
AI/BI Genie: 上述のエージェントシステムを企業データに対して動作するようにしたのが、こちらのGenieです。テーブルを追加するだけで、日本語によるデータ分析、可視化が可能になります。IT部門以外の方がご自身のドメイン知識を活用してさまざまな切り口でデータ分析を行えるようになる、(私が言うのもあれですが)画期的なソリューションです!

これらの機能のウォークスルーはこちらをご覧ください。国内のお客様にも多数活用いただいていますが、非常にご好評いただいております!
まとめ
これ以外にも、Databricksでは以下のような機能を提供しており、データやAIに関する様々な問題を解決する手助けをしています!無料トライアルを簡単にスタートできるので、ご興味のある方は是非試してみてください!
- Unity Catalog: Databricksにおけるカタログソリューションです。テーブルだけではなく、ファイル、機械学習モデル、LLM、関数、ツール、ダッシュボードなどなど、Databricksで管理されるすべての資産に対するガバナンスを実現します。最近ではオープンソース化されました。
- サーバレスコンピュート: Databricksの計算資源は、かつてはお客様ネットワーク上のクラウドコンピュートを使っていましたが、ここ1年でサーバレス化が急激に進行しました。SQLのためのサーバレスSQLウェアハウス、Pythonなどを実行するためのノートブック向けサーバレスコンピュート、DLT向け、ワークフロー向けのサーバレスコンピュート、サーバレスモデルサービングなど、ほぼすべてのワークロードでサーバレスを活用できるようになっています!
- Apache Spark: DatabricksでPythonやSQLを実行する際に、背後で動作している並列処理エンジンです。データの加工や検索、機械学習モデルのトレーニングや推論などさまざまなシーンで、Sparkが活用されるので大量データも高速に処理することが可能です。最適化技術もどんどん進んでおり、手動でのパフォーマンスチューニングの手間も減ってきていますので、気軽にご活用いただけます。
- コラボレーティブノートブック: 同時参照、同時編集が可能で、SQL、Python、Scala、Rを実行可能なノートブックです。下のアシスタントとともに活用することで、効率的に開発を進めることができます。
- Databricksアシスタント: データエンジニアリング、データサイエンス、データウェアハウスの文脈で生成AIアシスタントの力を借りることができます。コード生成、エラーの修正、技術的問い合わせなどなど日本語でやり取りすることができます。これが出てから、私も困った時にネット検索する頻度が減りました。
- Delta Sharing: 社外のパートナーとテーブルやモデルなどをセキュアに共有できます。データのコピーをするのではなく、ライブのデータを共有できます。