はじめに
本記事はDatabricks アドベントカレンダー2024 5日目の記事です。
Databricks 使っていますか?
みなさん、Databricks 使っていますでしょうか。Databricksを日々さわり、情報を集め、Databricksのロゴを毎日見ていたら、

先日、日本Microsoft社に訪問した時の総合受付への案内表示までもDatabricksに見えてしまいました🤣

なぜDatabricksは人々を魅了するのか
さて本題です。Googleトレンドで某DWH製品と比較すると、Databricksは年々支持を拡大していることがわかります。
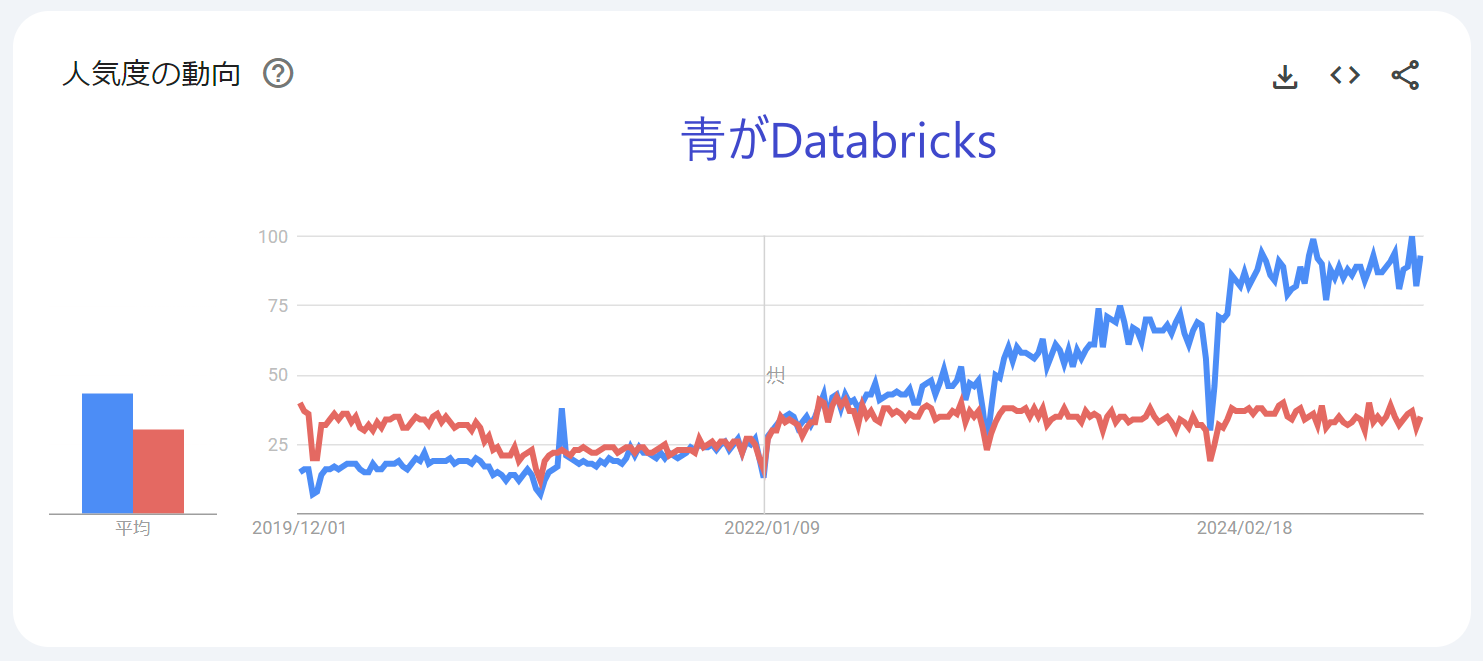
体感でも、自社内はもちろん、他社でも活用している方が増えてきた印象がありますし、Data & AIや日本での各種イベントも年々熱気が高まっているように感じています。
では、なぜ、あまたあるデータ製品のなかで、Databricksに人々は魅了されているのか。考察していこうと思います。Databricksをまだ導入していない人にも届くといいな😊
各種OSSへの貢献
Databricksはその創業当初から、オープンソースを中心に据えた戦略でデータとAIの未来を築くことに注力してきました。彼らの目標は、最新技術をオープンな形で共有し、開発者や企業がその恩恵を享受できるようにすることです。Databricksが主導または大きく貢献してきたオープンソースプロジェクトは、データ処理やAIの進化において重要な役割を果たしています。以下、その代表的なプロジェクトをご紹介します。
このあと書くこと、すべてに通じますが、推しのプロダクトが他社製品で使われ始めることは、ユーザーとしてはかなり嬉しいことだと感じています。SparkもDeltaもML flowも、いまやどのデータ製品をさわってもみかけますよね。
Apache Spark
Databricksの創業者たちが開発したApache Sparkは、分散データ処理の標準を築いた画期的なフレームワークです。このプロジェクトは今でもデータエンジニアリング、データサイエンス、AIの基盤技術として世界中で利用されています。Databricksは現在もSparkの開発に積極的に関与し、その進化を支え続けています。
Delta Lake
データウェアハウスのようなトランザクション保証と、データレイクのスケーラビリティを両立するオープンフォーマット「Delta Lake」。DatabricksはこれをApache Sparkに統合することで、「Lakehouse」という新しいアーキテクチャの実現を可能にしました。Delta Lakeはすでにオープンソースとして公開されており、多くの企業が採用しています。

MLflow
機械学習プロジェクトのライフサイクル全体を管理するためのプラットフォームであるMLflowもDatabricksが発案したものです。モデルの実験、トラッキング、デプロイまでを一貫して管理できるこのツールは、エンドツーエンドで機械学習を実用化する企業にとっての標準となりつつあります。
Unity Catalog
2024年6月、DatabricksはデータとAIのガバナンスを統合的に管理するソリューションである Unity Catalog をオープンソース化しました。
これにより、クラウド、データ形式、データプラットフォームを横断して、データとAI資産のガバナンスを行う業界初のオープンソースカタログが誕生しました。
↓の動画はMateiさんが、2024年Data&AIのKeynote登壇中に、Unity Catalogのリポジトリをパブリックに公開する瞬間の動画です。イベントの中でもっとも盛り上がった瞬間でした。
Koalas
Pythonのデータ分析ライブラリPandasの利便性をそのままに、大規模データセットをSparkで処理可能にするためのプロジェクトです。Koalasは多くのPython開発者にとってSparkを身近な存在にしました。現在は、Spark自体に統合され、Pandas APIとして進化を続けています。

良いワード(概念)を生み出している
いまやデータ業界ではどこの製品でも言われているような言葉を最初に生み出しているのも、Databricksの魅力です。自分たちがつかっている製品が言っているワード(概念)が、世の中に広まっていくのを感じるのはユーザーとしても良い気分になります。
例えば以下のようなワード(概念)です。
1. メダリオンアーキテクチャ (Medallion Architecture)
メダリオンアーキテクチャは、データを Bronze(生データ)→Silver(整形データ)→Gold(集計・分析用データ) という階層に分けて管理する手法を指します。この構造により、データの品質管理とトレーサビリティを容易にし、複雑なデータパイプラインを簡素化することができます。特にDelta Lakeとの組み合わせで活用され、データエンジニアリングの基本的な設計パターンとして広く認知されています。
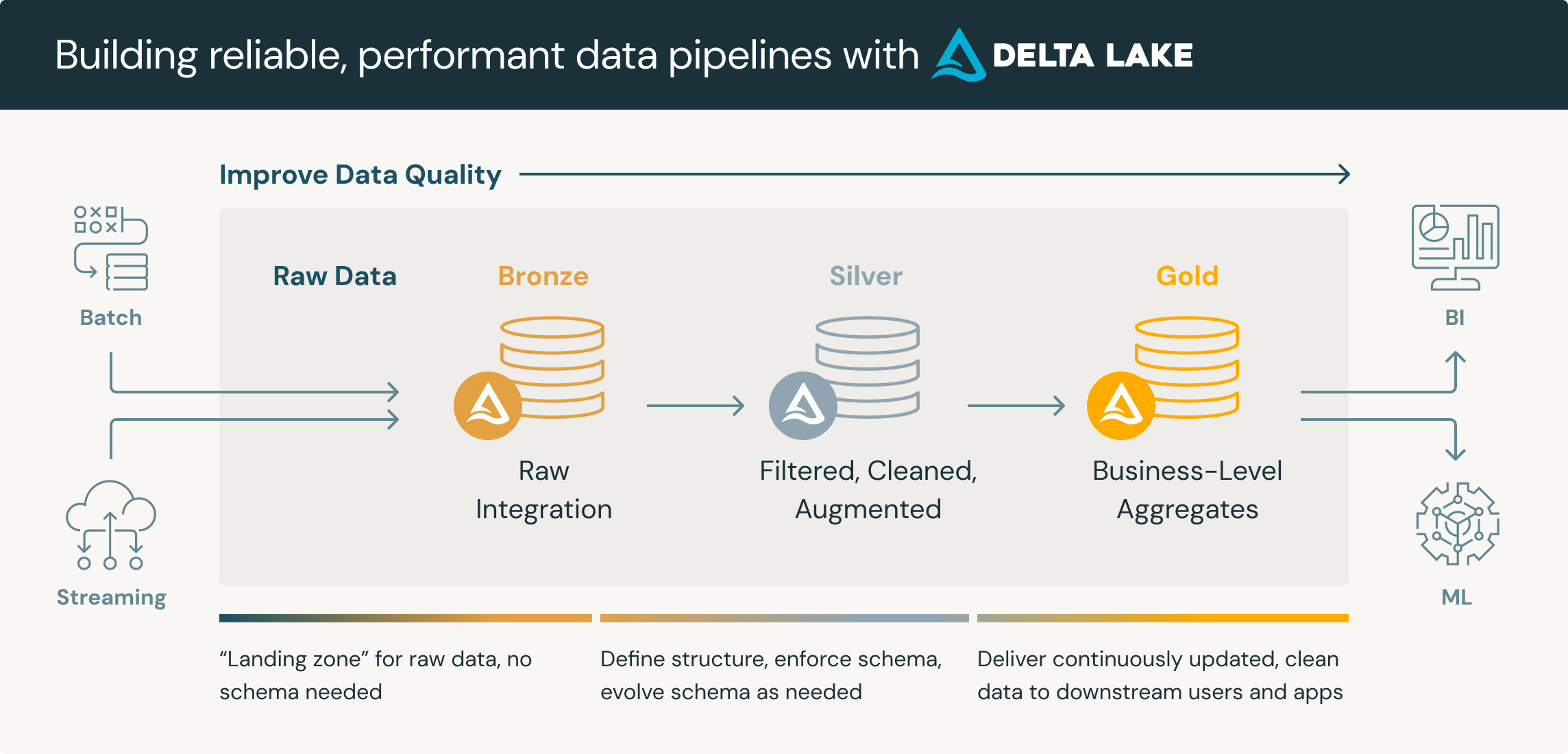
2. レイクハウス (Lakehouse)
Lakehouseは、従来のデータウェアハウスとデータレイクの利点を統合した新しいデータ管理アーキテクチャを指します。Databricksがこの言葉を広めたことで、データ管理のパラダイムシフトが起き、多くの企業がデータレイクのスケーラビリティとウェアハウスのトランザクション性を併せ持つ設計を採用するようになりました。いまではMicrosoft Fabric、Snowflake、AWS SagemakerもLakehouseを標榜した製品を扱っています。

かゆいところに手が届く
エンジニアや管理者が「こうだったらいいのにな~」という機能がいち早く導入されていくのもDatabricksの特徴です。
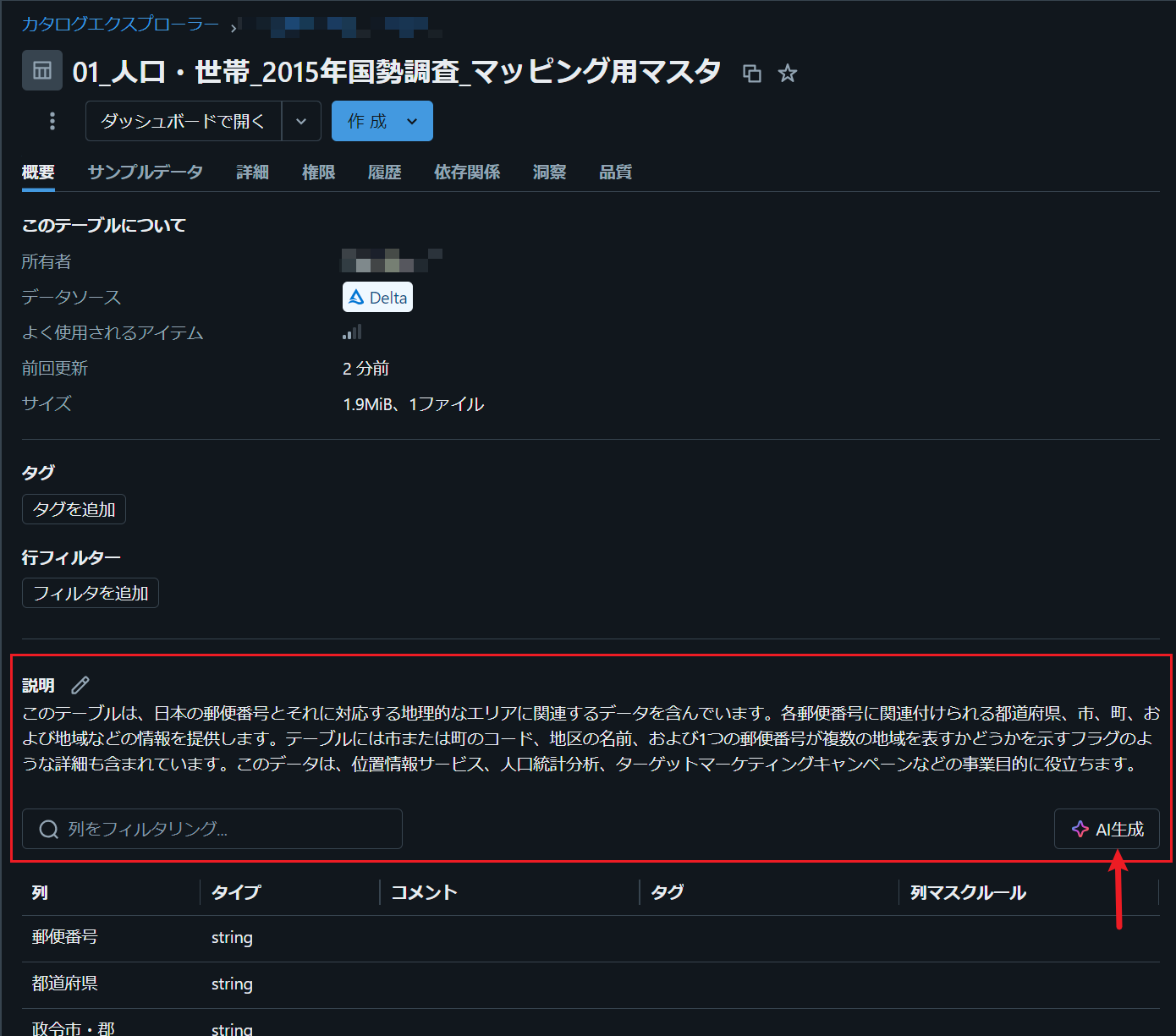
AI コメント
例えば、テーブルの説明をAIが記入してくれる機能。かなり的確にテーブルや列のコメントを入れてくれます。
データリネージ
データリネージはエンジニアも管理者としてももはやないと困る機能になっています。
課金してもよさそうなところが無料で使える
Databricksは、ユーザーの生産性向上を目指し、DatabricksアシスタントというAIベースのペアプログラマーを提供しています。このアシスタントは、コードやクエリの生成、最適化、補完、説明、修正などの機能を備えており、ユーザーがノートブック、クエリ、ファイルを作成する際の効率を高めます。
このDatabricksアシスタント、なぜか無料で使えちゃいます。クラスターをアタッチする必要もなく、冷蔵庫に余っている食材から晩御飯のメニューを聞くことができちゃいます。

同様にDatabricks SQLで利用できるAI関数も、特にAI利用に関しては費用がかからない状態になっています。いつか課金がされる日がくるかもしれないけれど、この寛容な体制には好感をもたざるをえません。
小額から始められる
Databricksをつかいはじめるときに、最初から大きな予算を取る必要はありません。ワークスペースを作成するのは無料でできます。ストレージアカウントに必要なデータを入れて、小さなクラスターを動かして検証をするくらいなら、何百円、何千円で十分な検証を行うことができます。
また、ほぼすべてのリソースが従量課金となっているため、10万円→50万円→100万円のようなラダーはありません。使った分だけお支払いすればよいですし、逆に使わなくなったらその日から0円になります。
変化の激しいビジネス環境において、このような料金体系なのはとても助かりますよね。

中の人たちが楽しそう
技術書展
中の人たちが本当にデータを愛し、Databricksで楽しんで働いていることが伝わってきます。技術書の同人誌即売会、技術書展では毎回Databricks有志が技術書を書いて販売しています。こちらの本、中身もとても読みごたえがあるので、未読の方はぜひ以下リンクから購入してみてください。
毎日DatabricksについてBlogを書いている人がいる
中の人で、毎日のようにDatabricksについてのブログを書いている人がいます。今日(2024年12月)時点で1700本以上の記事を書いています。自社の製品にこれだけコミットしている人がいると、こちらも引き込まれますよね。
@taka_yayoi さん、毎日読んでますので引き続き更新頑張ってください~
まとめ
Databricksは単なるツールの提供者にとどまらず、オープンソースコミュニティとの密接な協力関係を築いています。ユーザーコミュニティもどんどん活発になっていますよね。私も2025年はDatabricksの発信を増やしていこうと考えています。
いつかのユーザーコミュニティでお会いしましょう。それではまた🧔