Databricksの Lakeflowジョブ を使えば、データパイプラインの自動化がとても簡単です!本記事では、初めての方でも15分で最初のワークフローを作成できるように、基本から丁寧に解説します。
Databricksが初めての方へ
この記事を読む前に、Databricksの基本的な使い方を知りたい方は、まず以下の記事をご覧ください。
なぜLakeflowジョブなのか?
Databricksワークフロー機能の変遷
Databricksのワークフロー機能は、時代とともに進化してきました:
2021年7月: Databricksジョブ
↓ (タスクの依存関係グラフをサポート)
2022年: Databricks Workflows
↓ (ワークフロー機能として拡張)
2023年: 主要機能の追加
├─ 条件分岐(if/else)10月GA
└─ ファイル到着トリガー 2月初期リリース
↓
2024年: エンタープライズ機能の強化
├─ サーバレスコンピュート(ジョブ用)GA
├─ ファイル到着トリガー GA(2月)
└─ テーブル更新トリガー GA(11月20日)
↓
2025年9月: Lakeflowジョブ ← いまここ!
用語の整理
過去の記事で「Databricksジョブ」「Databricks Workflows」と呼ばれていた機能は、現在すべて Lakeflowジョブ として統合されています。
ジョブとは?
公式ドキュメントによると、Lakeflowジョブは以下のように定義されています:
Lakeflow Jobsは、Databricks向けのワークフロー自動化であり、データ処理ワークロードのオーケストレーションを提供します。
ジョブの特徴:
- 1つ以上のタスクで構成され、複雑なワークフロー管理が可能
- タスクオーケストレーション、クラスター管理、モニタリング、エラーレポートはすべてDatabricksが管理
- 即時実行、スケジュール実行、連続実行が可能
Lakeflowジョブの「すごい」ところ
1. 複数タスクのオーケストレーション
Databricksジョブによる複数タスクのオーケストレーションで紹介されているように、2021年7月から以下の機能が利用可能になっています:
シンプルなタスクオーケストレーション:
- 誰でもDatabricksのUI、APIを用いてDAG(有向非巡環グラフ)で容易にタスクをオーケストレート
- データサイエンティストやアナリストが自身でジョブを構築、モニタリング可能
推薦を行う機械学習モデルのトレーニングを行う7つのノートブックを実行するジョブ
どこでも何でもオーケストレーション:
- ジョブオーケストレーションはDatabricksに完全に統合
- 追加のインフラストラクチャやDevOpsのリソースは不要
- APIさえ公開しているものであれば何でもオーケストレート可能(例:CRMからデータを取得)
2. 99.95%の稼働時間保証
- 本番環境で実証済みの信頼性
- 数千の企業が数百万のワークロードを実行中
- エンタープライズグレードのSLA
3. サーバレスコンピュート
従来の方法:
❌ サーバーの起動 → 設定 → データ処理 → サーバーの停止
❌ 面倒なインフラ管理...
Lakeflowジョブ(サーバレス):
✅ データ処理だけ書けばOK!
✅ あとは全部自動!
サーバレスの最適化モード:
| モード | 特徴 | おすすめの用途 |
|---|---|---|
| Performance | クラシッククラスターの2倍高速 | レイテンシーが重要なワークロード |
| Standard | Performance比で最大70%安い | バッチ処理、深夜実行のETL |
はじめてのLakeflowジョブ:赤ちゃんの名前データで学ぶ
このチュートリアルは、Lakeflowジョブを使用して最初のワークフローを作成する公式クイックスタートガイドに基づいています。
前提条件
以下の環境が必要です:
- Unity Catalogに対応したワークスペース
- サーバレスジョブ機能が有効化されている(または新規クラスター作成権限)
- Unity Catalogボリュームへのアクセス権限
-
READ VOLUME、WRITE VOLUME、USE SCHEMA、USE CATALOGの権限
Unity Catalogやサーバレス機能について詳しく知りたい方は、Unity Catalogのドキュメントをご参照ください。
ステップ0: ノートブックを準備する
ノートブック1: データ取得(retrieve-baby-names)
外部APIから赤ちゃんの名前データを取得し、Unity Catalogボリュームに保存します。
# NY州の赤ちゃんの名前データCSVをWebから取得し、Unity Catalogのボリュームに保存
import requests
# データをWebから取得
response = requests.get('https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv')
# 取得したCSVデータをデコード
csvfile = response.content.decode('utf-8')
# Unity CatalogのボリュームにCSVファイルとして保存
# (パスは適宜変更してください)
dbutils.fs.put("/Volumes/takaakiyayoi_catalog/default/data/babynames.csv", csvfile, True)
ノートブック2: データ処理(process-baby-names)
保存されたCSVファイルを読み込み、年度別にフィルタリングして表示します。
babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/Volumes/main/default/my-volume/babynames.csv")
babynames.createOrReplaceTempView("babynames_table")
years = spark.sql("select distinct(Year) from babynames_table").toPandas()['Year'].tolist()
years.sort()
dbutils.widgets.dropdown("year", "2014", [str(x) for x in years])
display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
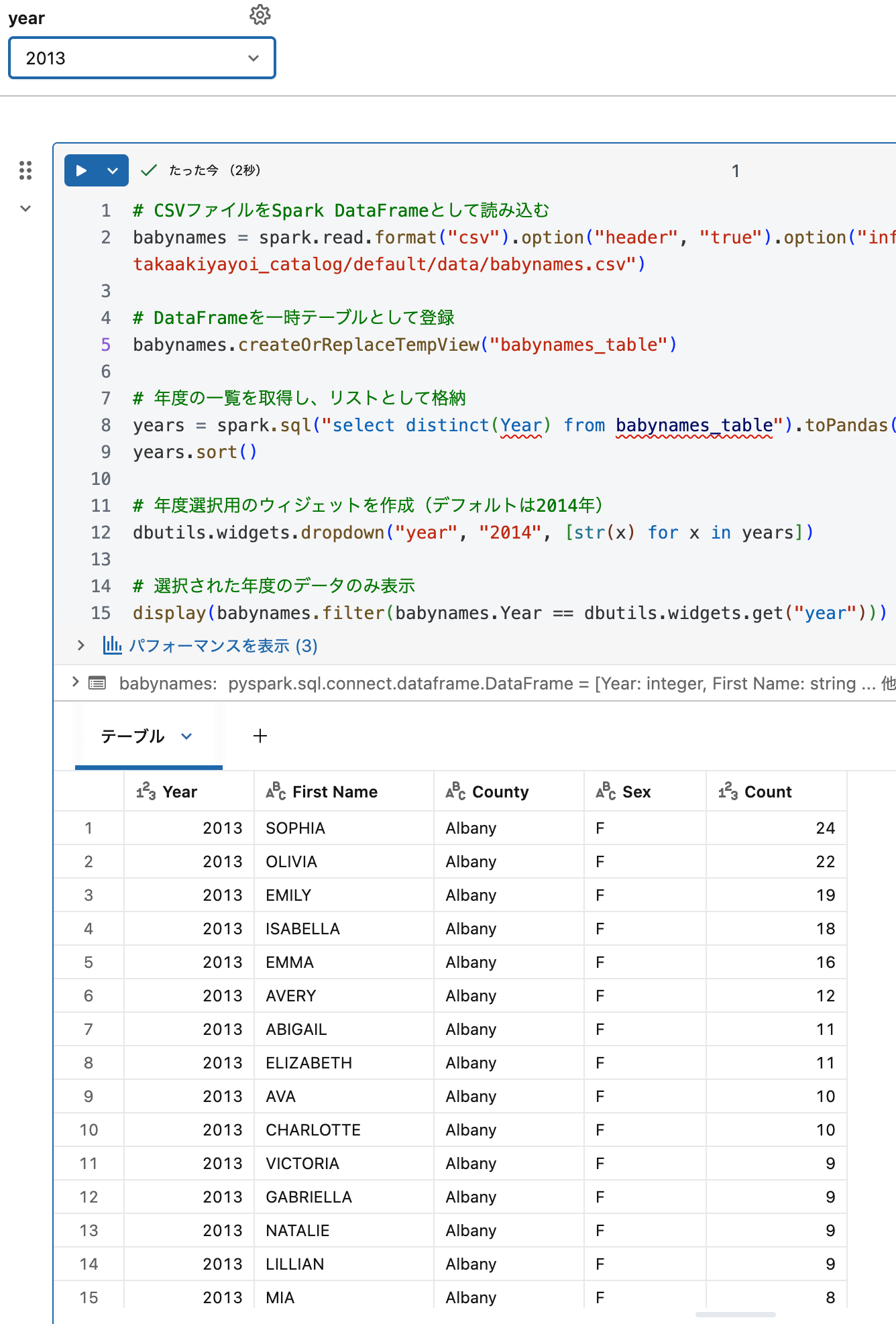
指定した年度の赤ちゃんの名前データが表示されます
ノートブックウィジェットについて
パラメーターの詳しい使い方はノートブックウィジェットをご参照ください。
ステップ1: ワークスペースにアクセス
Databricksワークスペースにログインしたら、左側のサイドバーから ジョブとパイプライン を選択します。
サイドバー
├── ワークスペース
├── カタログ
├── ジョブとパイプライン ← これをクリック!
└── ...
ジョブ一覧画面。「ジョブを作成」ボタンと既存ジョブの一覧が表示されます
Databricks Workflowsについてもっと知りたい方へ
ワークフロー機能の詳しい機能や高度な使い方については、こちらの記事で詳しく解説しています。
ステップ2: 新しいジョブを作成
公式クイックスタートガイドに従って、新しいジョブを作成します:
-
サイドバーの 作成 をクリックし、メニューから ジョブ を選択します
-
新規ジョブ… にジョブ名を入力します(例:
baby-names-workflow)
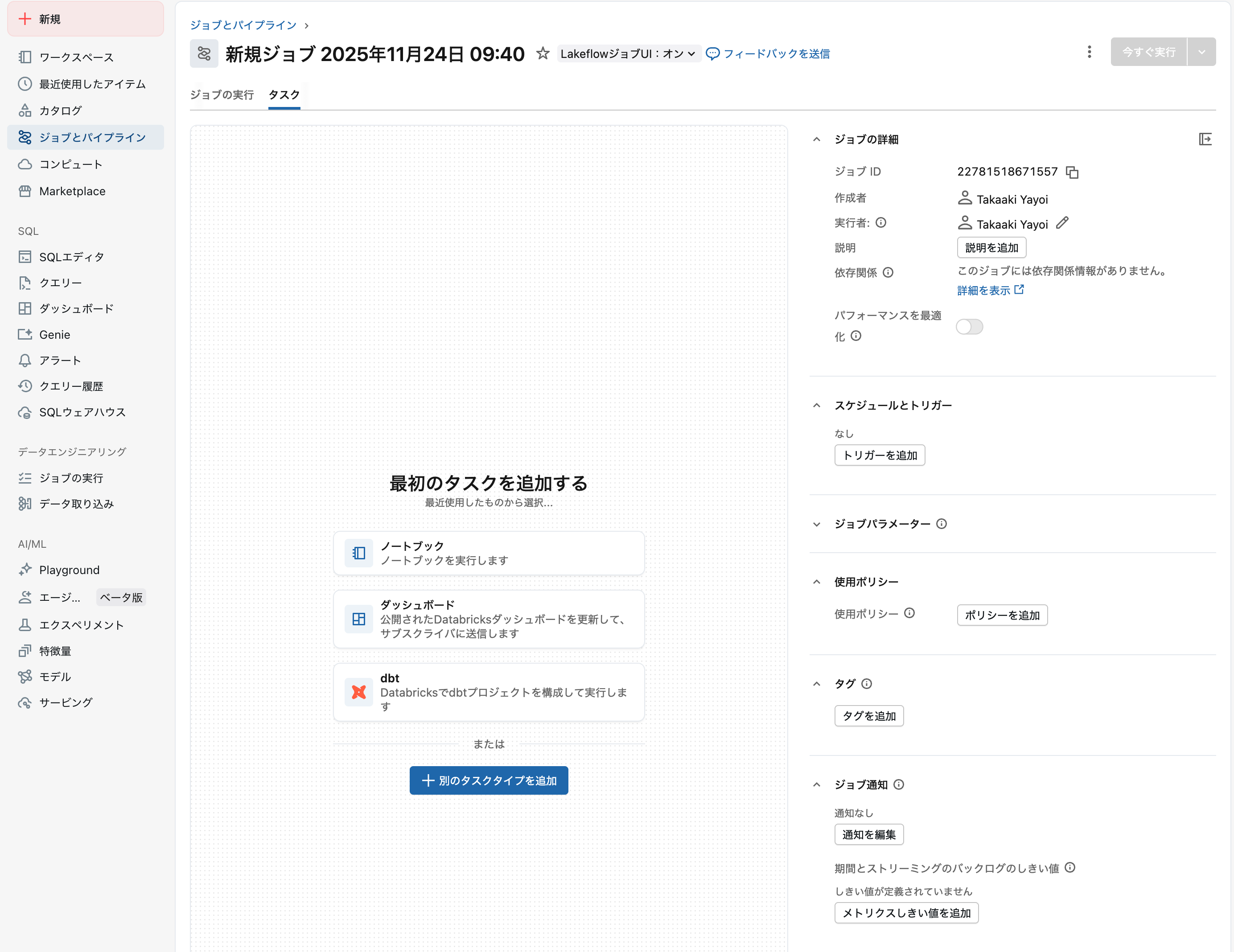
新規ジョブ作成画面。ジョブ名の入力とタスク追加が可能です -
ノートブックをクリックします。
ステップ3: 最初のタスクを追加(データ取得)
タスクタブでタスク作成ダイアログが表示されます:
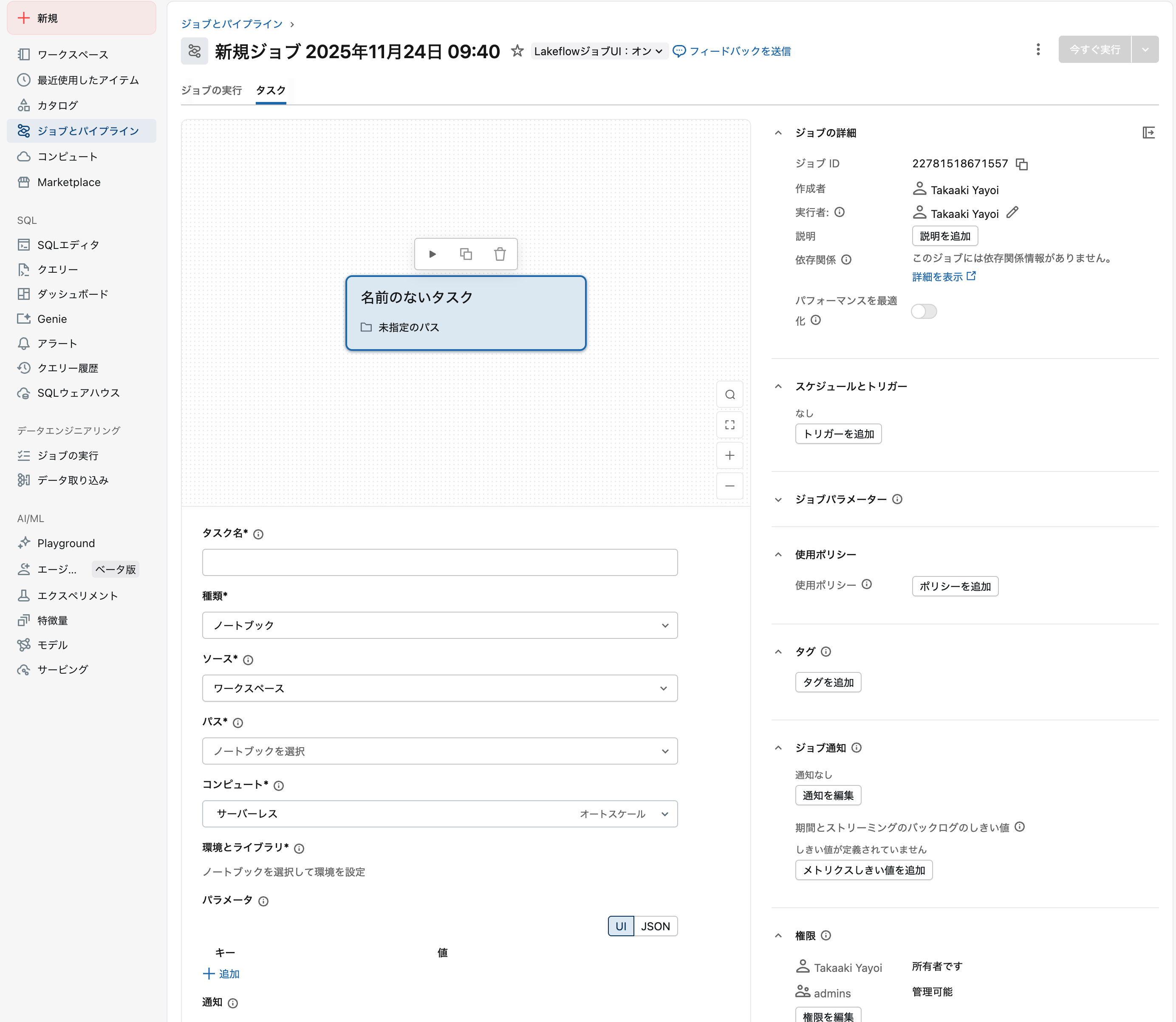
タスク作成ダイアログ。タスク名、ソース、ノートブックを設定します
タスク設定の手順
-
タスク名:
retrieve-baby-namesと入力します -
ソース:ワークスペース を選択します
-
種類はノートブックになっているのでパスで先ほど作成した
retrieve-baby-namesを選択します:- ファイルブラウザから先ほど作成した
retrieve-baby-namesノートブックを検索 - ノートブックを選択して 確認 をクリック
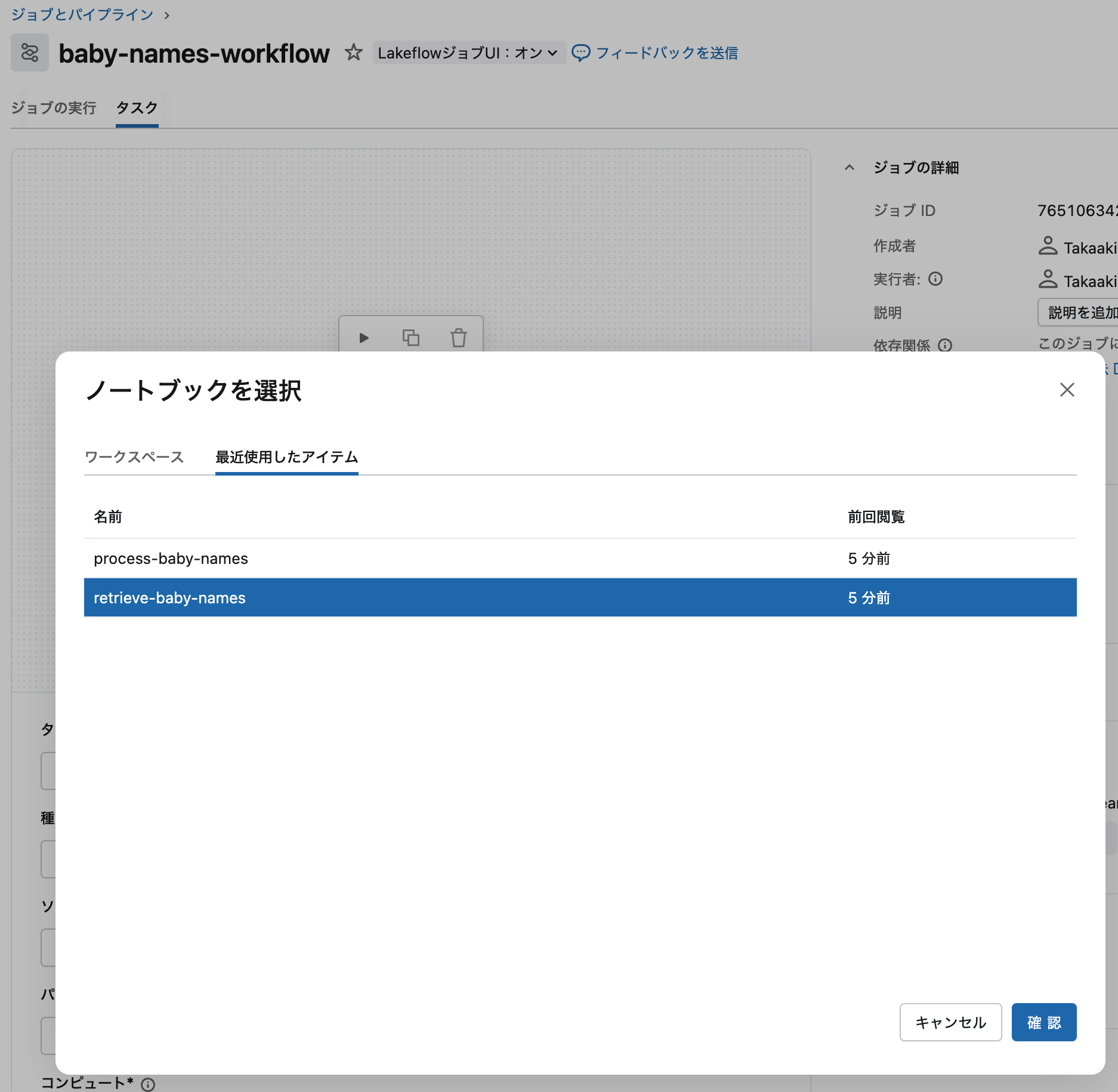
- ファイルブラウザから先ほど作成した
-
コンピュート:
- サーバレス を選択(推奨)
- または既存のクラスター、新規ジョブクラスターを選択
-
タスクを作成 をクリックしてタスクを追加
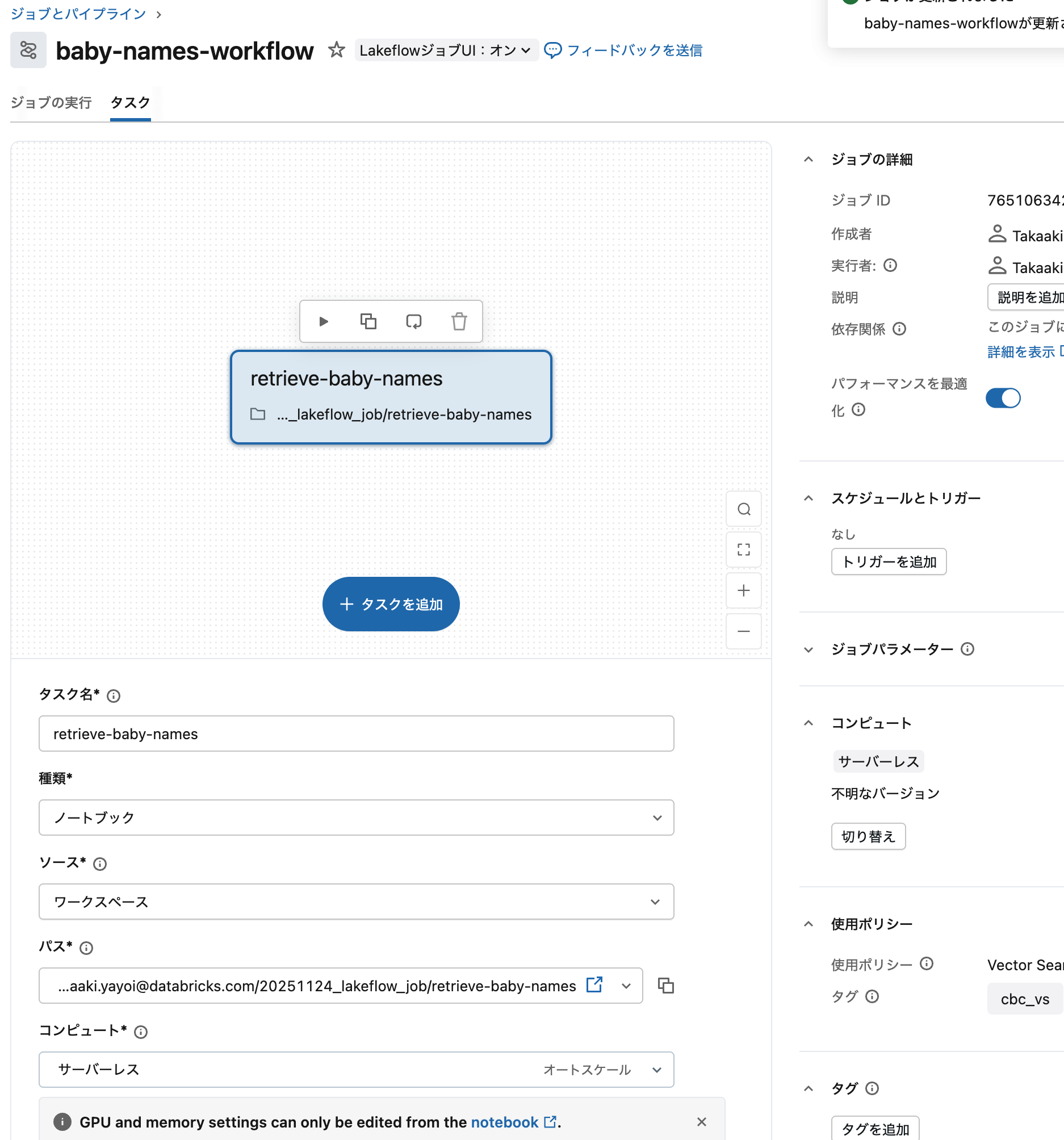
ステップ4: 2番目のタスクを追加(データ処理)
次に、データ処理用の2番目のタスクを追加します:
-
タスクを追加をクリックして、ノートブックを選択します
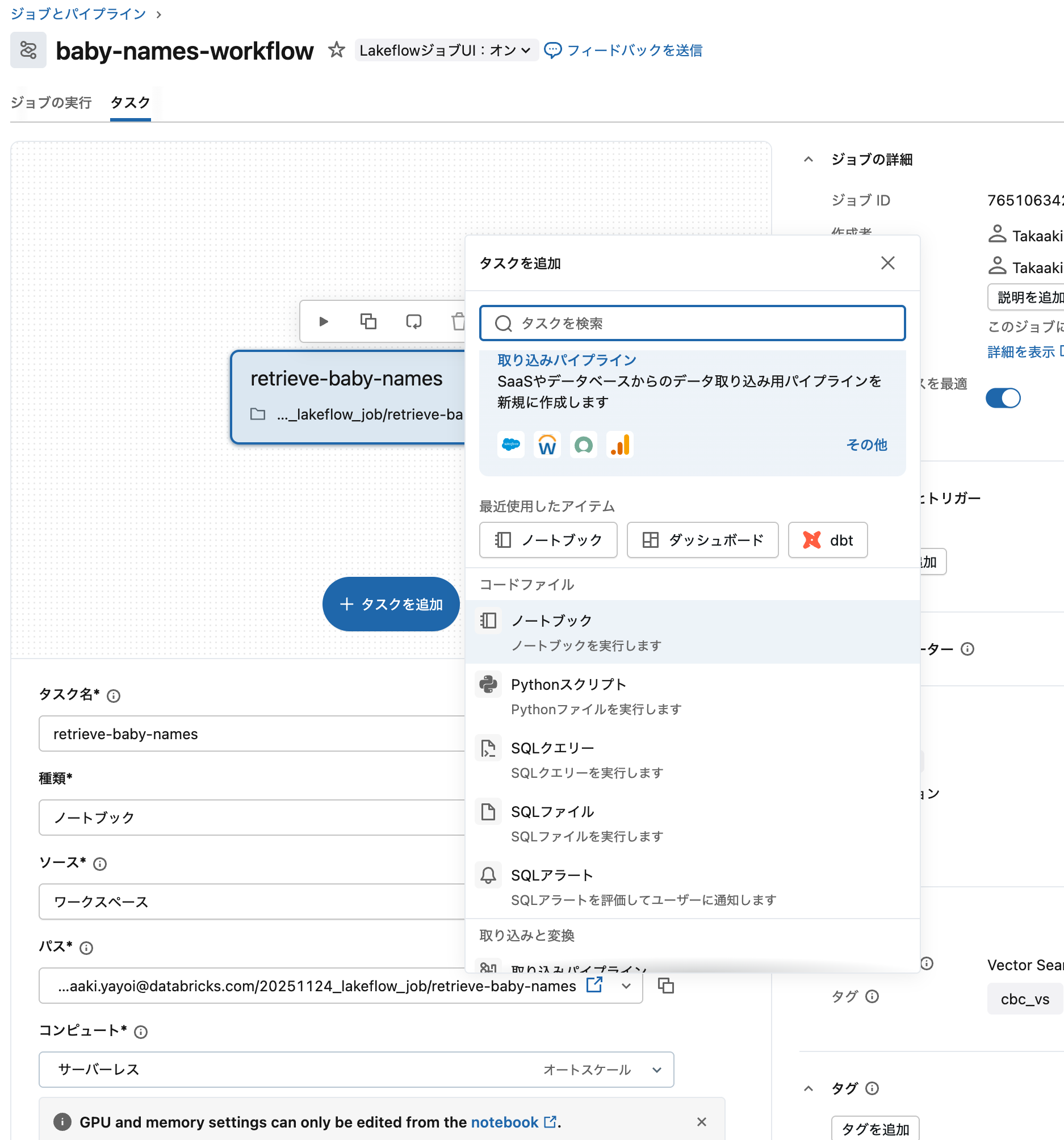
-
タスク名:
process-baby-namesと入力 -
ソース:ワークスペース を選択
-
ノートブック:
process-baby-namesノートブックを選択
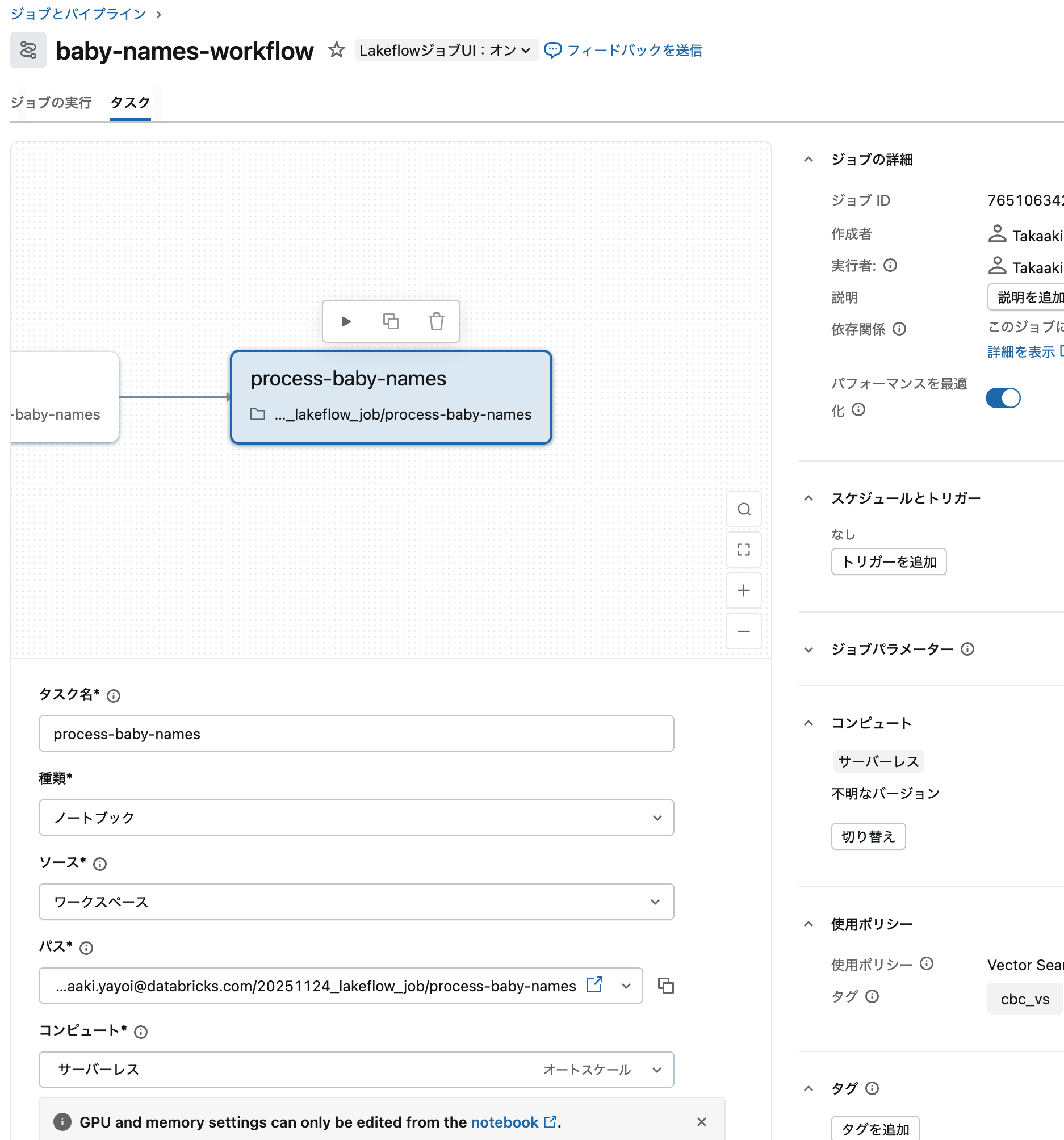
-
依存関係:
-
依存先 で
retrieve-baby-namesがデフォルトで選択されています - これにより、データ取得タスクが完了してからデータ処理タスクが実行されます
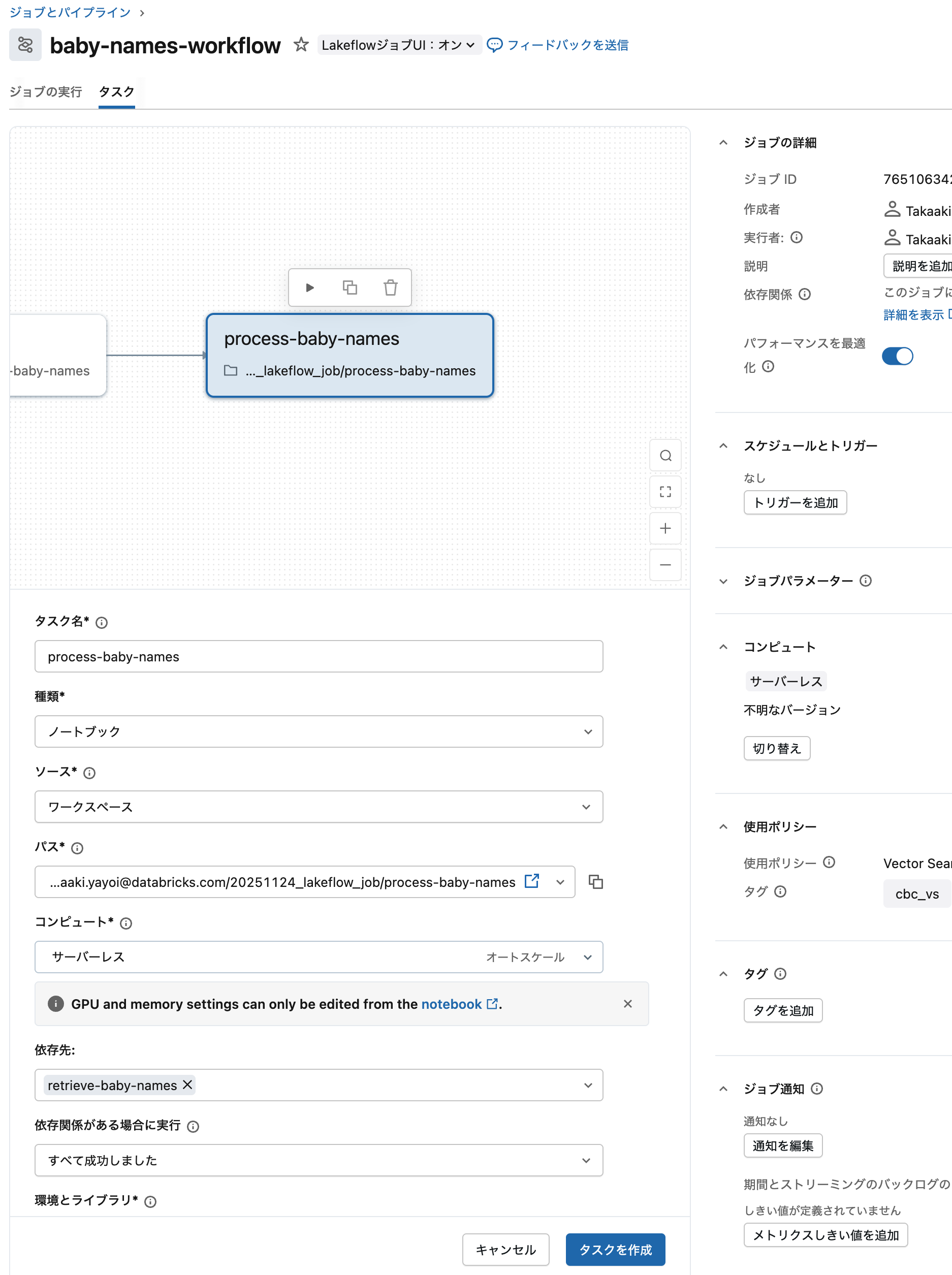
-
依存先 で
-
パラメーター:
- 追加 をクリック
-
キー:
year -
値:
2014
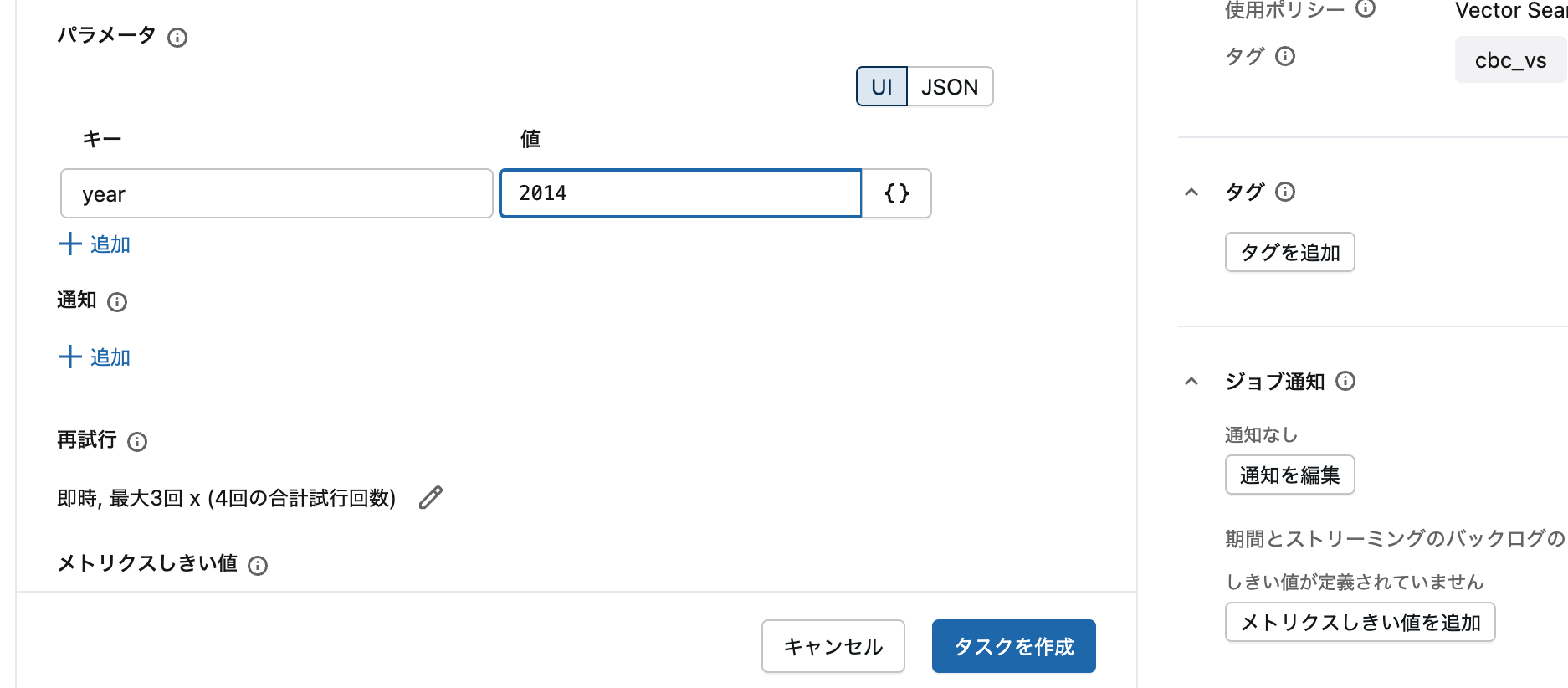
パラメーター設定画面。キーバリュー形式でパラメーターを指定します
6. タスクを作成 をクリックしてタスクを追加します
これで2つのタスクが連携したワークフローが完成しました!

ステップ5: ジョブを実行してみる
右上の 今すぐ実行 ボタンをクリックします。
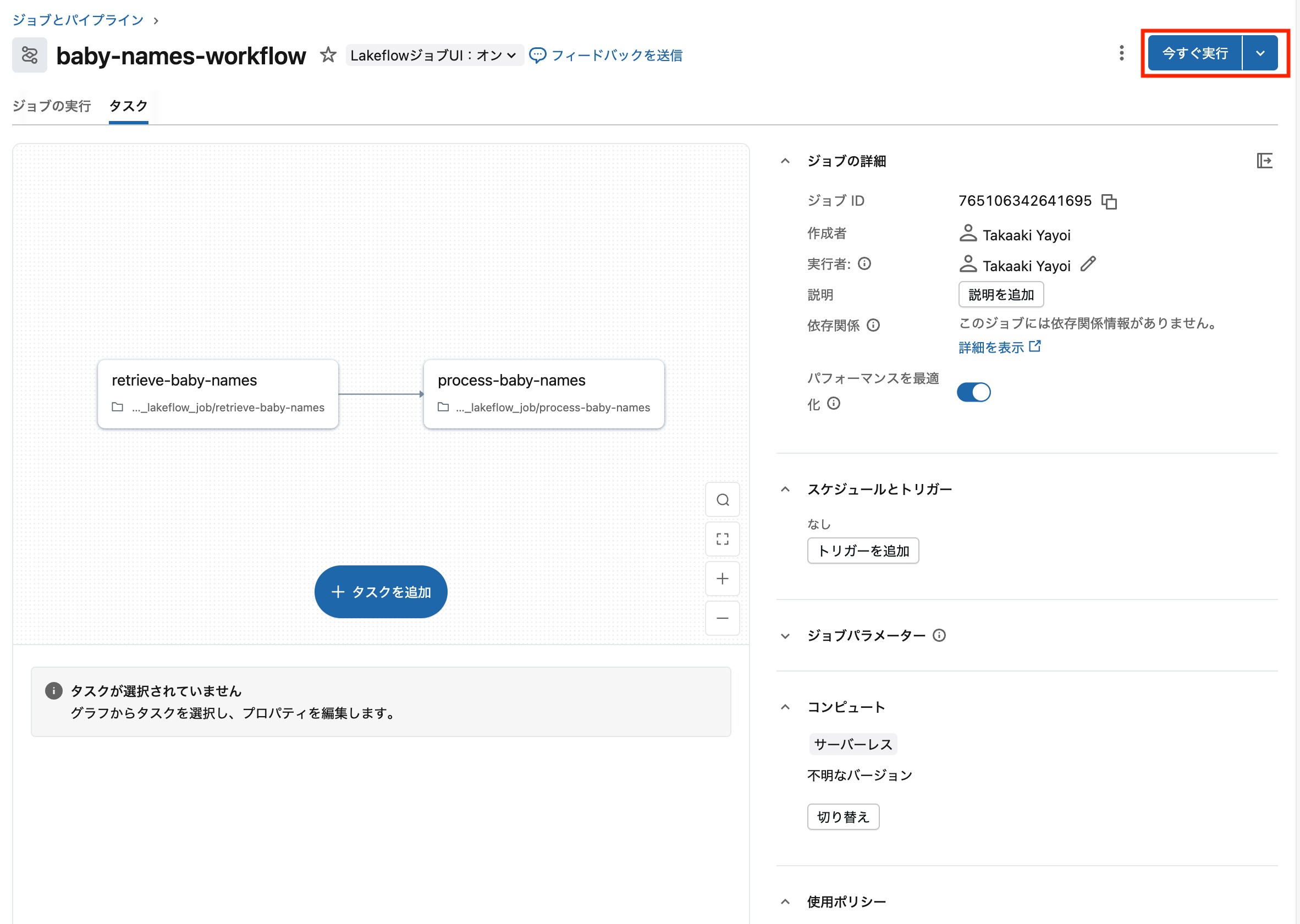
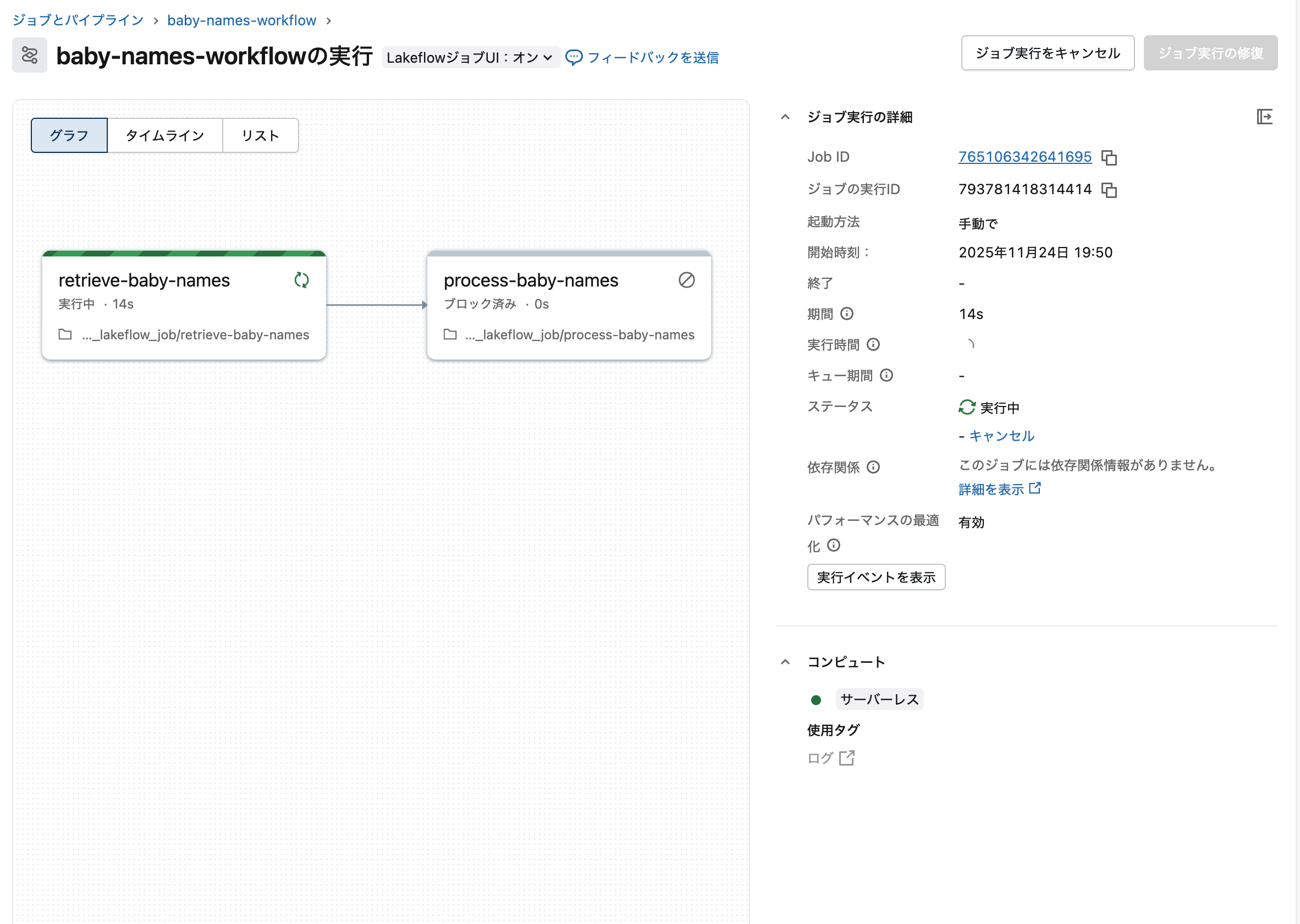
ジョブ実行中の画面。タスクの実行状況がリアルタイムで表示されます
数秒〜数分で実行が完了します。
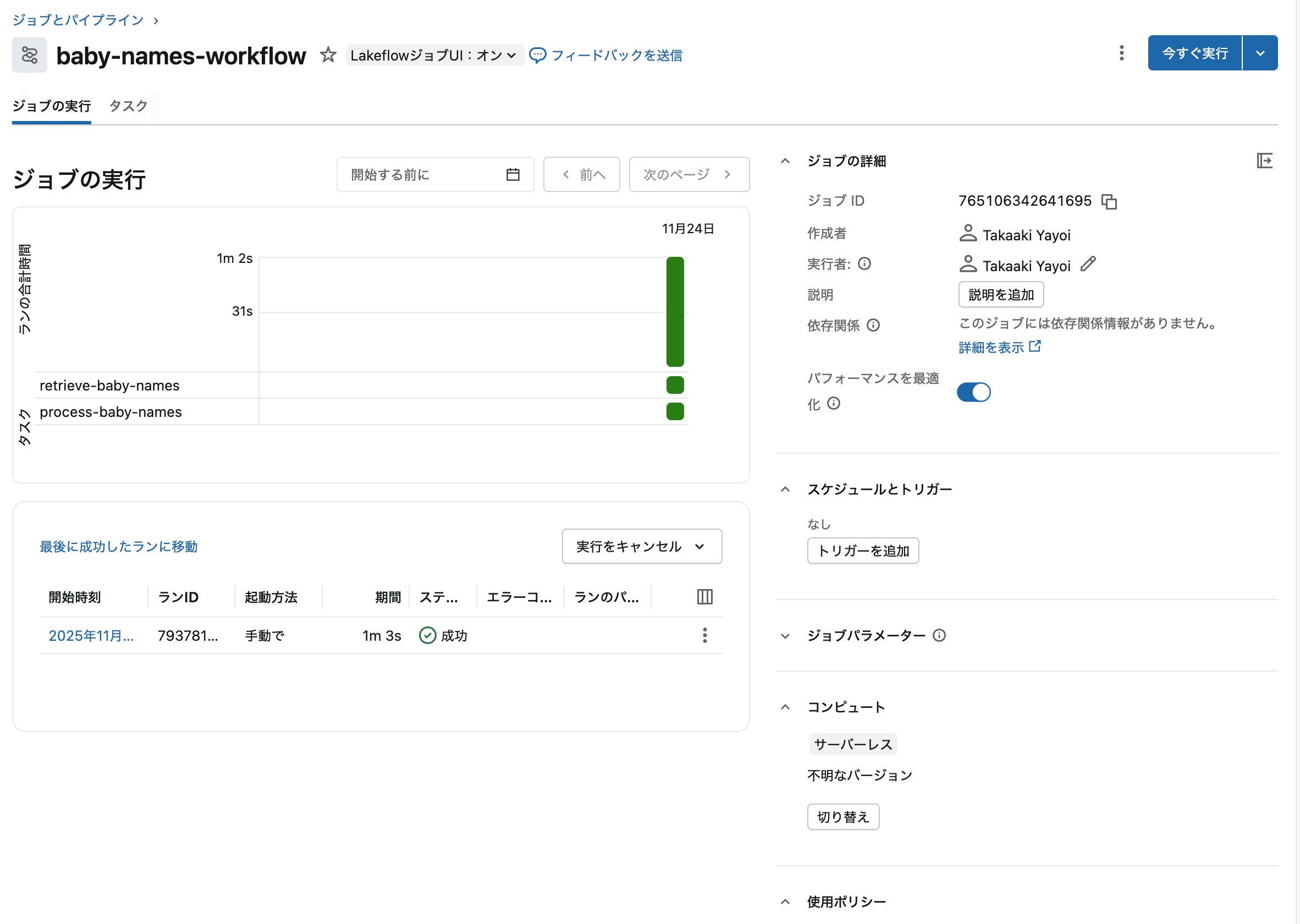
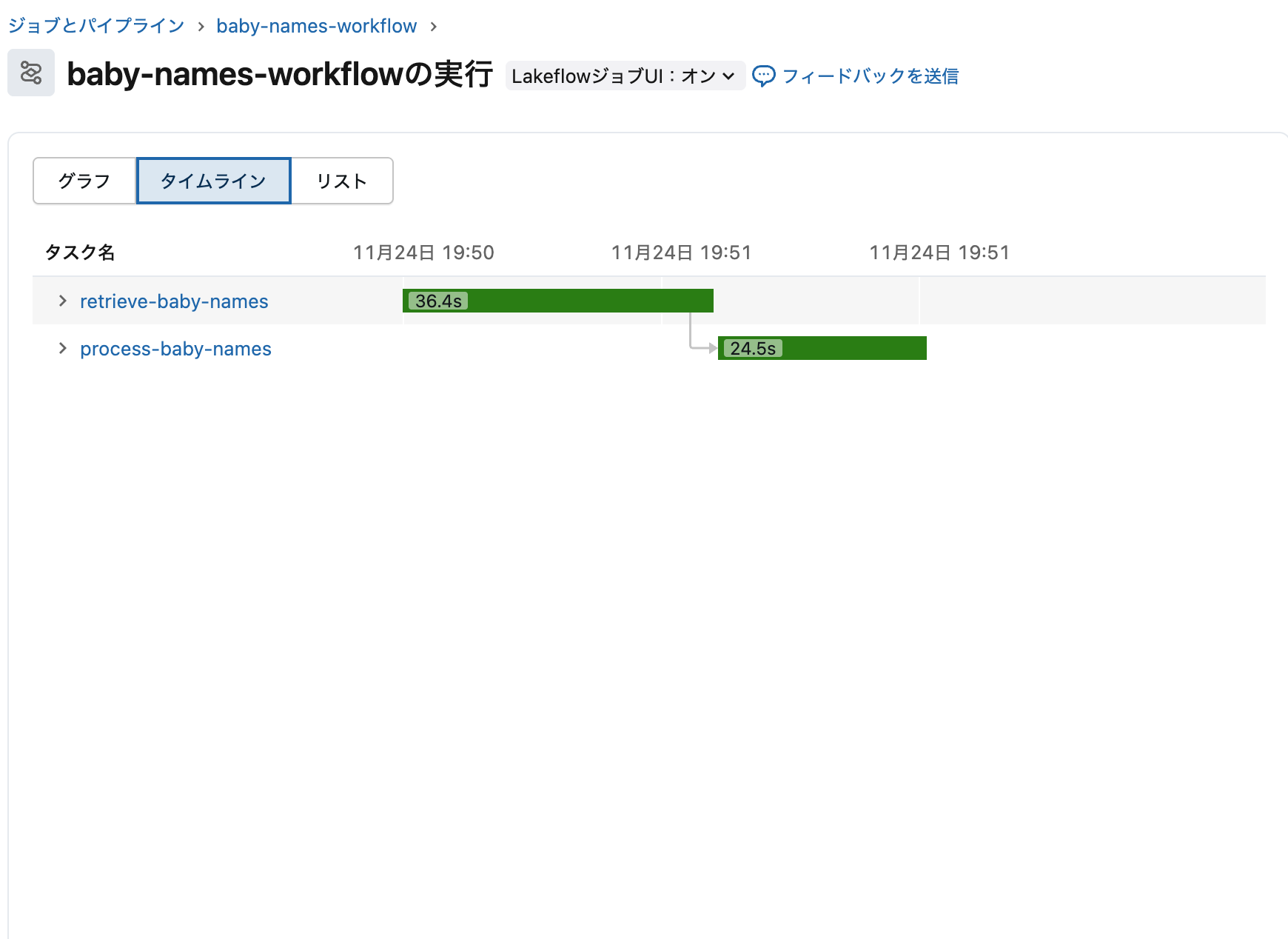
ジョブの実行タブで実行結果を確認できます。2つのタスクが順番に実行されています
パラメーターを変更して再実行
今すぐ実行 の横のドロップダウンメニューから 別の設定で今すぐ実行 を選択すると、異なるパラメーターで実行できます:
- 別の設定で今すぐ実行 を選択
-
year パラメーターを
2014から2015に変更 - 今すぐ実行 をクリック
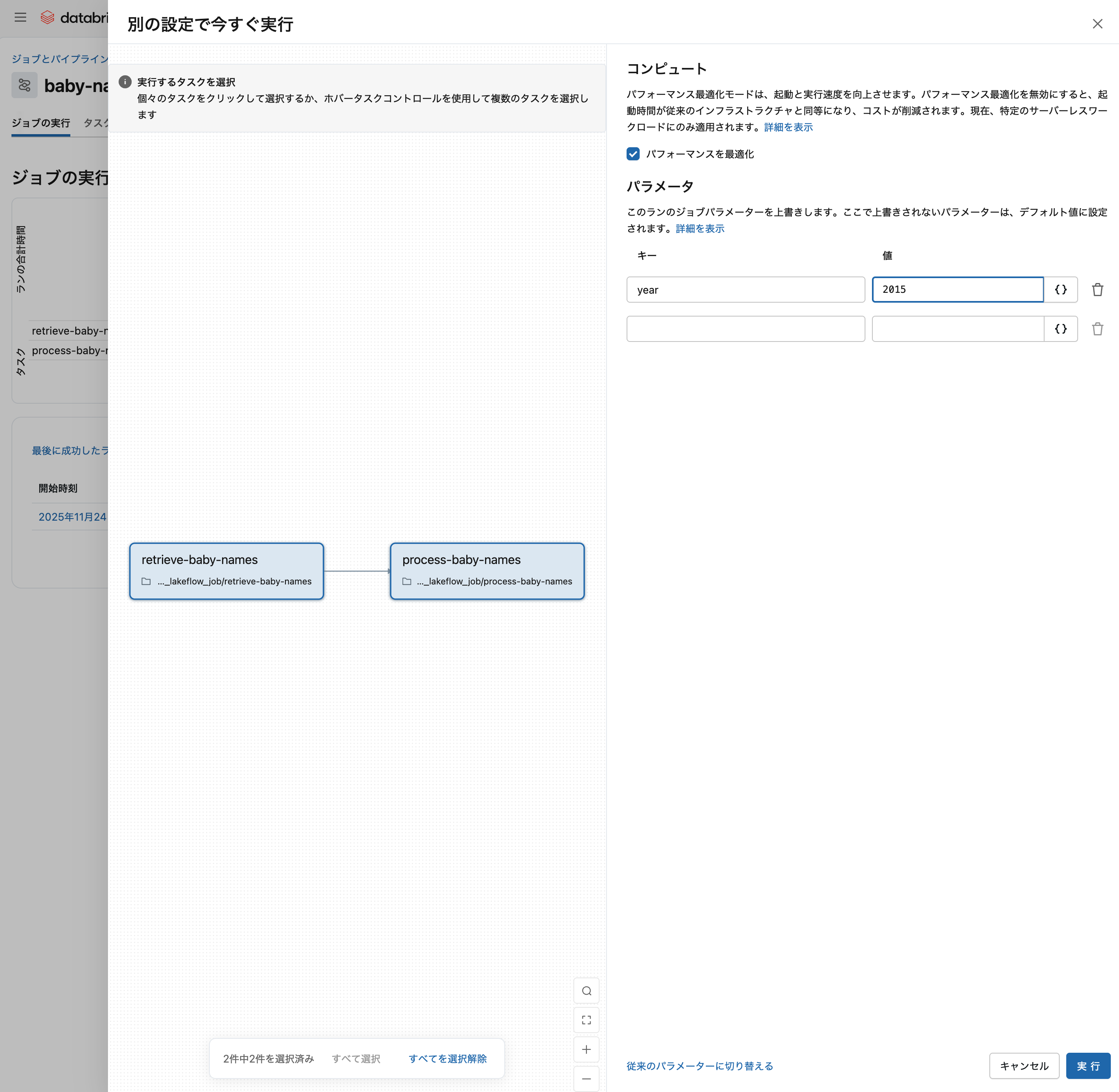
これにより、異なる年度のデータを処理できます!
🎉 おめでとうございます!
最初のLakeflowジョブが動きました!
ステップ6: スケジュールを設定(オプション)
ジョブのスケジュールを設定する場合には、Edit Scheduleをクリックします。
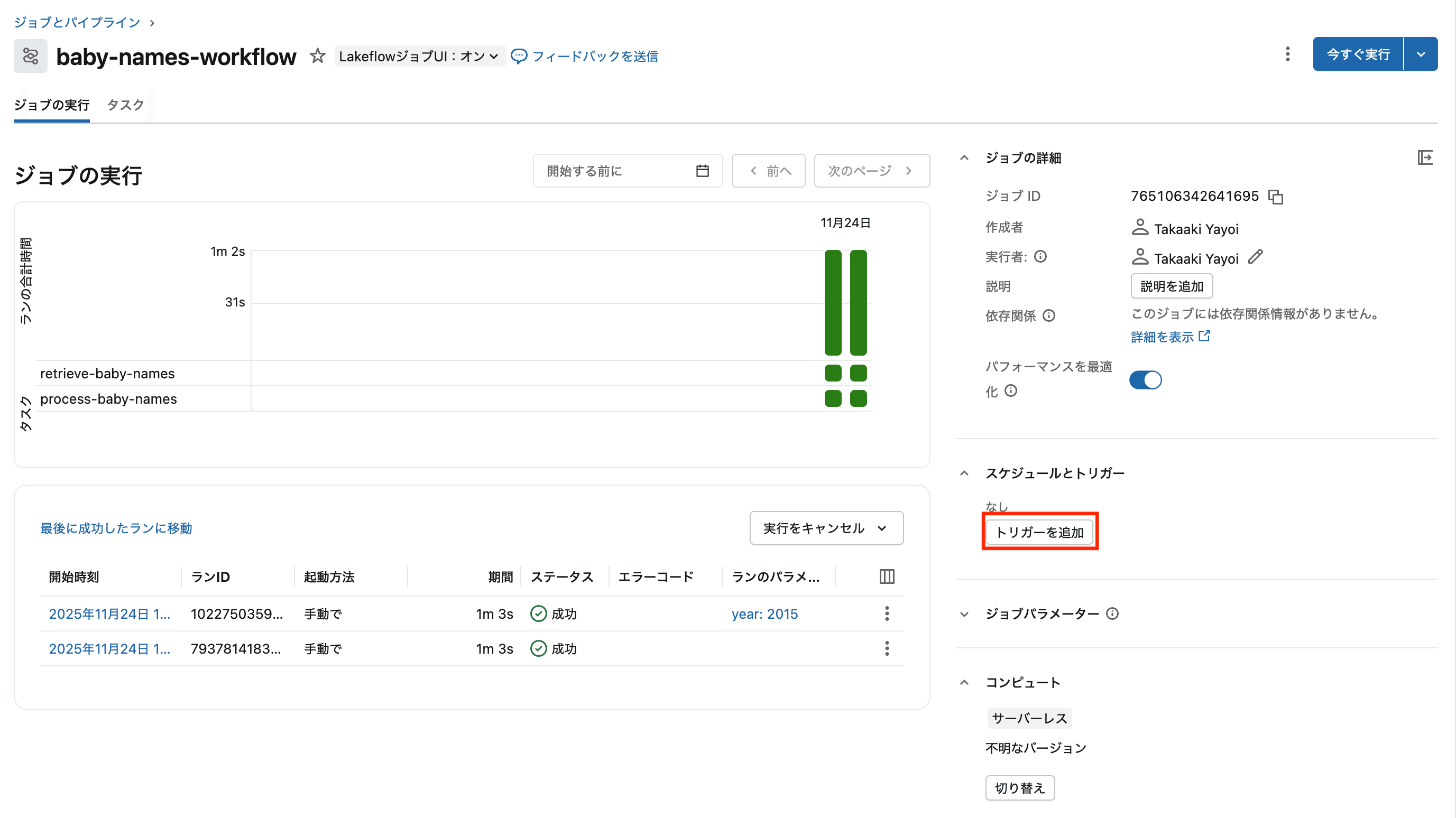
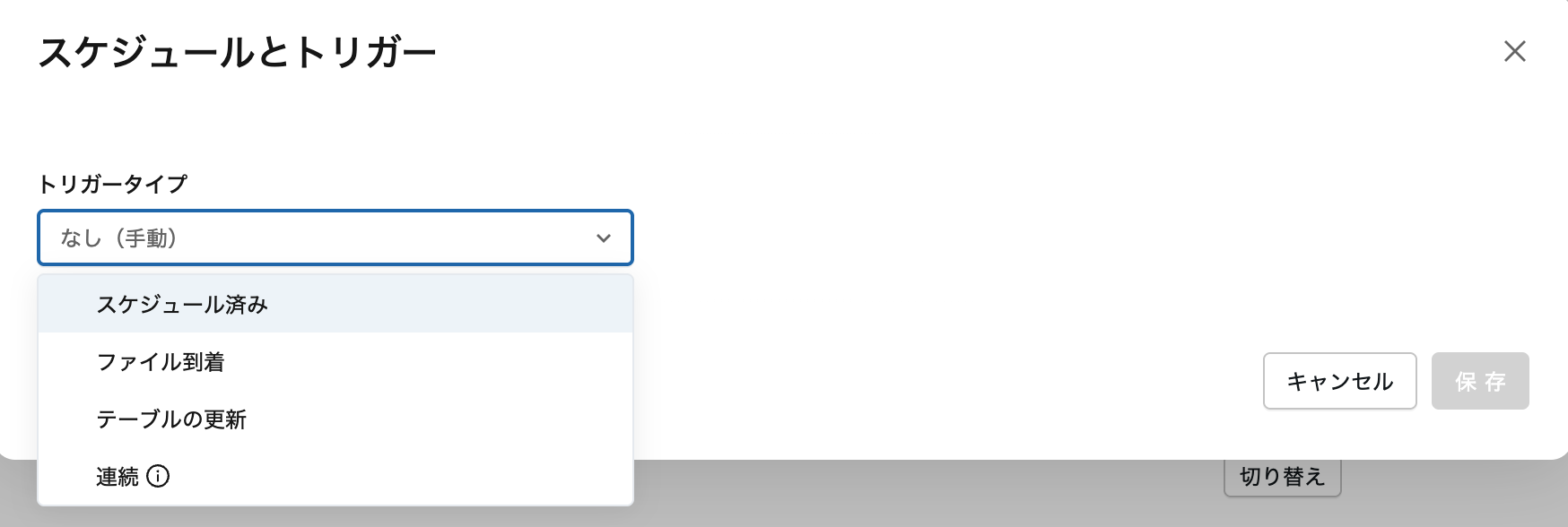
スケジュール設定画面。トリガータイプ(Scheduled/File arrival/Table update)を選択できます
スケジュールトリガーの例:
毎日9時に実行:
スケジュール: 毎日
時刻: 9:00
タイムゾーン: Asia/Tokyo
その他のトリガー:
- File arrival: 新しいファイルが届いたら自動実行(詳細はこちら)
- Table update: テーブルが更新されたら自動実行(2024年11月GA)
- Manual: 手動実行のみ
実行結果画面で確認できること:
- ✅ タスクの実行状況(実行中/完了/失敗)
- ✅ 各タスクの実行時間
- ✅ ログ出力(標準出力/エラー出力)
- ✅ 使用したコンピュートリソース
- ✅ 実行履歴(過去60日間)
Lakeflowジョブの基本概念
DAGとは?タスクの依存関係を見える化
DAG(Directed Acyclic Graph: 有向非巡環グラフ) は、Lakeflowジョブの核となる概念です。
DAGを一言で言うと
「どのタスクがどの順番で実行されるかを、矢印で結んだ図」
例:売上レポート作成のDAG
データ収集 → データクレンジング → レポート生成
(Task 1) (Task 2) (Task 3)
矢印(→)が「順番」を表します
Task 1が完了したら → Task 2を実行
Task 2が完了したら → Task 3を実行
なぜDAGが重要なのか?
1. 依存関係が一目で分かる
❌ 従来:スクリプトを開いて、コードを読んで理解...
✅ DAG:図を見るだけで全体の流れが分かる!
2. 自動的に順番通りに実行
Task 1(データ収集)が失敗
↓
Task 2(クレンジング)は実行されない
↓
無駄な処理を防ぎ、データ品質を保証
3. 並列実行で高速化
Task 1(完了)
├→ Task 2(並列実行)
└→ Task 3(並列実行)← Task 2と同時に実行可能!
実際のDAG画面
公式ドキュメントによると、「ジョブ内のタスクは、有向非巡回グラフ(DAG)によって視覚的に表されます」とされています。
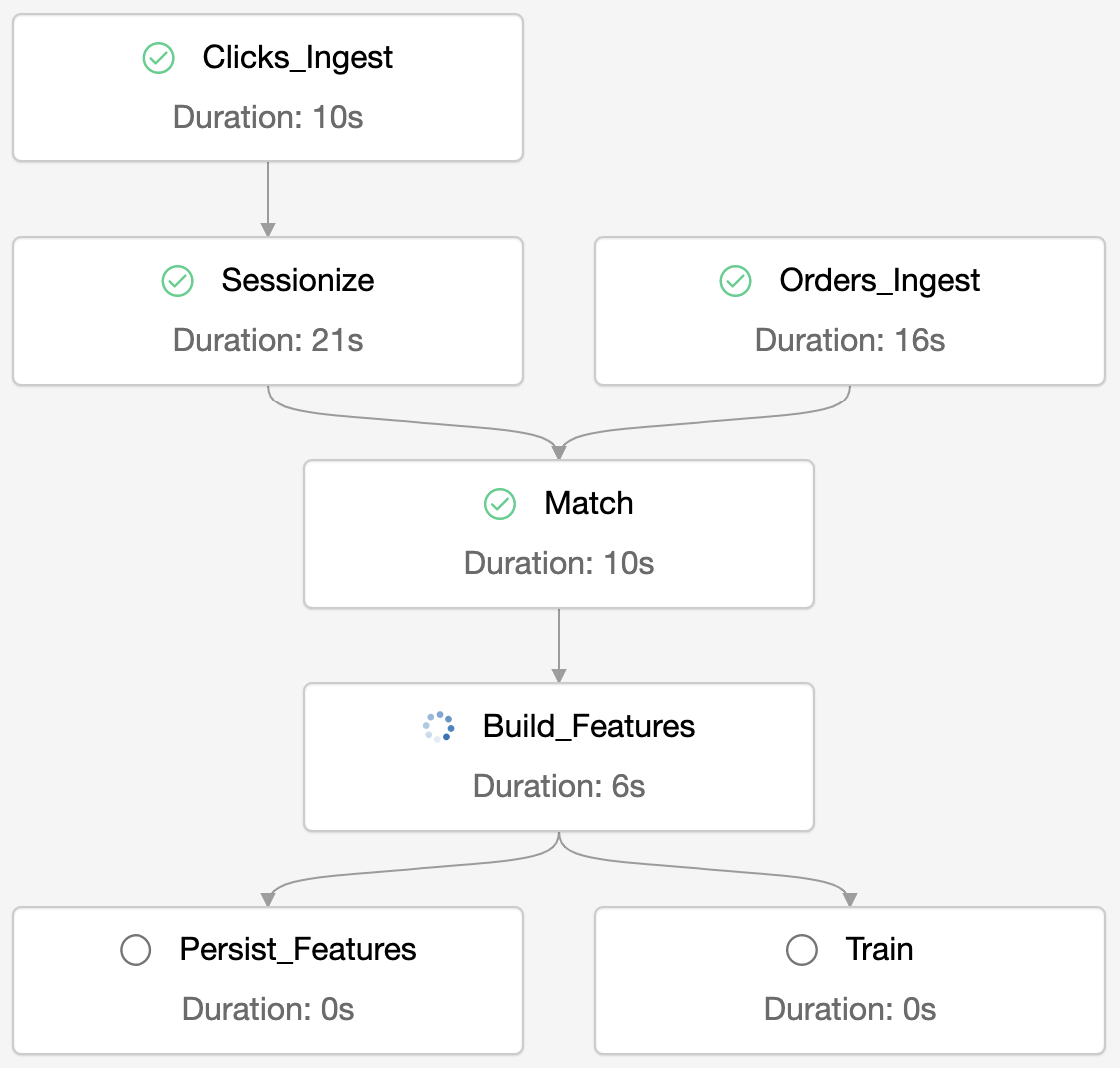
複雑なワークフローの例:
- 生のクリックストリームデータを取り込み、レコードをセッション化するために変換
- 注文データを取り込み、セッション化されたクリックストリームデータと結合し、分析データを準備
- 準備されたデータから特徴量を抽出
- 特徴量を永続化し、機械学習モデルをトレーニングするために並列でタスクを実行
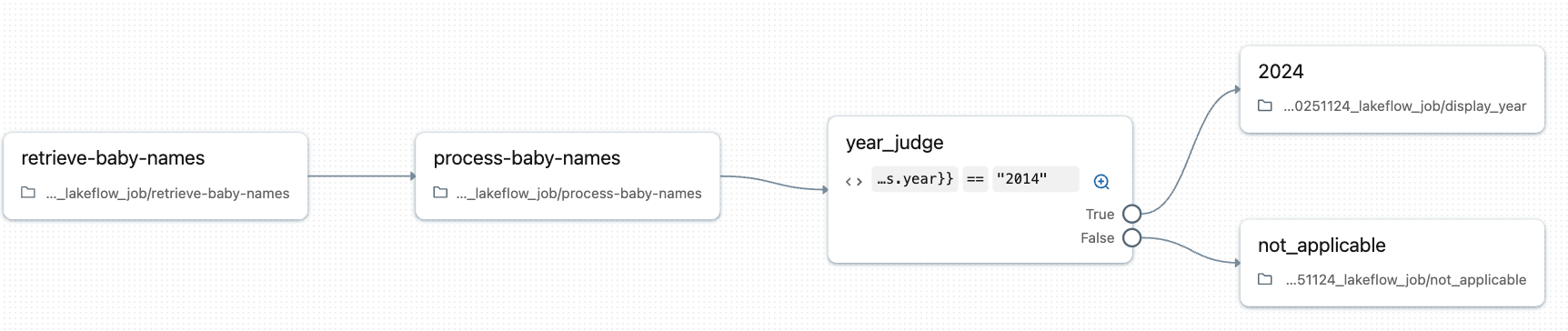
実際のジョブ画面でのDAG表示。タスク間の依存関係が視覚的に表現されます
タスクタイプと制御フローの豊富さ
Lakeflowジョブの大きな特徴は、14種類以上のタスクタイプと強力な制御フロー機能です。
データ処理タスク(7種類)
| タスクタイプ | 説明 | おすすめ度 |
|---|---|---|
| Notebook | Databricksノートブックを実行 | ⭐⭐⭐⭐⭐ 初心者向け |
| Python script | Pythonファイル(.py)を実行 | ⭐⭐⭐⭐ |
| SQL | SQLクエリーを実行 | ⭐⭐⭐⭐⭐ アナリスト向け |
| Pipeline | Lakeflow Spark宣言型パイプラインを実行 | ⭐⭐⭐⭐⭐ ETL向け |
| Python wheel | Pythonパッケージを実行 | ⭐⭐⭐ 上級者向け |
| JAR | Java/Scalaアプリケーションを実行 | ⭐⭐⭐ 上級者向け |
| Spark Submit | spark-submitコマンドを実行 | ⭐⭐⭐ レガシー移行 |
統合・外部システムタスク(4種類)
| タスクタイプ | 説明 |
|---|---|
| dbt | dbtプロジェクトを実行 |
| dbt platform | dbt Cloudプロジェクトを実行(Beta) |
| Dashboards | Databricksダッシュボードを更新 |
| Power BI | Power BIダッシュボードを更新 |
制御フロータスク(3種類)
これがLakeflowジョブの最大の強みです!
| 制御フロー | 説明 | 用途 |
|---|---|---|
| If/else | 条件分岐ロジック | ✅ 成功時は処理A、失敗時は処理B |
| For each | ループ処理 | ✅ 複数テーブルに同じ処理を適用 |
| Run Job | 別のジョブを呼び出し | ✅ ジョブの再利用と組み合わせ |
制御フローの詳細:
If/else条件分岐:
条件評価:
├─ タスク値(前のタスクの結果)
├─ ジョブパラメーター
└─ 動的値
比較演算子:
==(等しい)、!=(等しくない)
>、>=、<、<=
For eachループ:
例:10個のテーブルに同じ変換処理
├─ テーブル名リスト: [table1, table2, ..., table10]
├─ 各テーブルに対してノートブックを実行
└─ 並列実行で高速処理!
Run if条件付き実行:
依存タスクの結果に応じて実行:
├─ すべて成功した場合のみ実行
├─ 少なくとも1つ成功した場合に実行
└─ 1つ以上失敗した場合に実行(クリーンアップなど)
初心者におすすめ:Notebook + If/else
✅ UIで結果を確認しながら開発
✅ デバッグが簡単
✅ 条件分岐で柔軟な処理が可能
✅ ドキュメントとコードを一緒に管理
トリガーの種類
1. スケジュールトリガー
毎日9時に実行:
スケジュール: 毎日
時刻: 9:00
タイムゾーン: Asia/Tokyo
2. ファイル到着トリガー
新規ファイルが到着した際にDatabricksジョブを起動するで詳しく解説されています。
設定項目:
-
Storage location: 外部ロケーションのURL(例:
s3://my-bucket/incoming/) - Minimum time between triggers: 前回実行完了後の最小待機時間
- Wait after last change: ファイル到着後の待機時間(バッチ処理用)
注意点:
- 最大10,000ファイルまでのロケーションのみサポート
- 毎分新規ファイルをチェック
- Unity Catalog有効化が必要
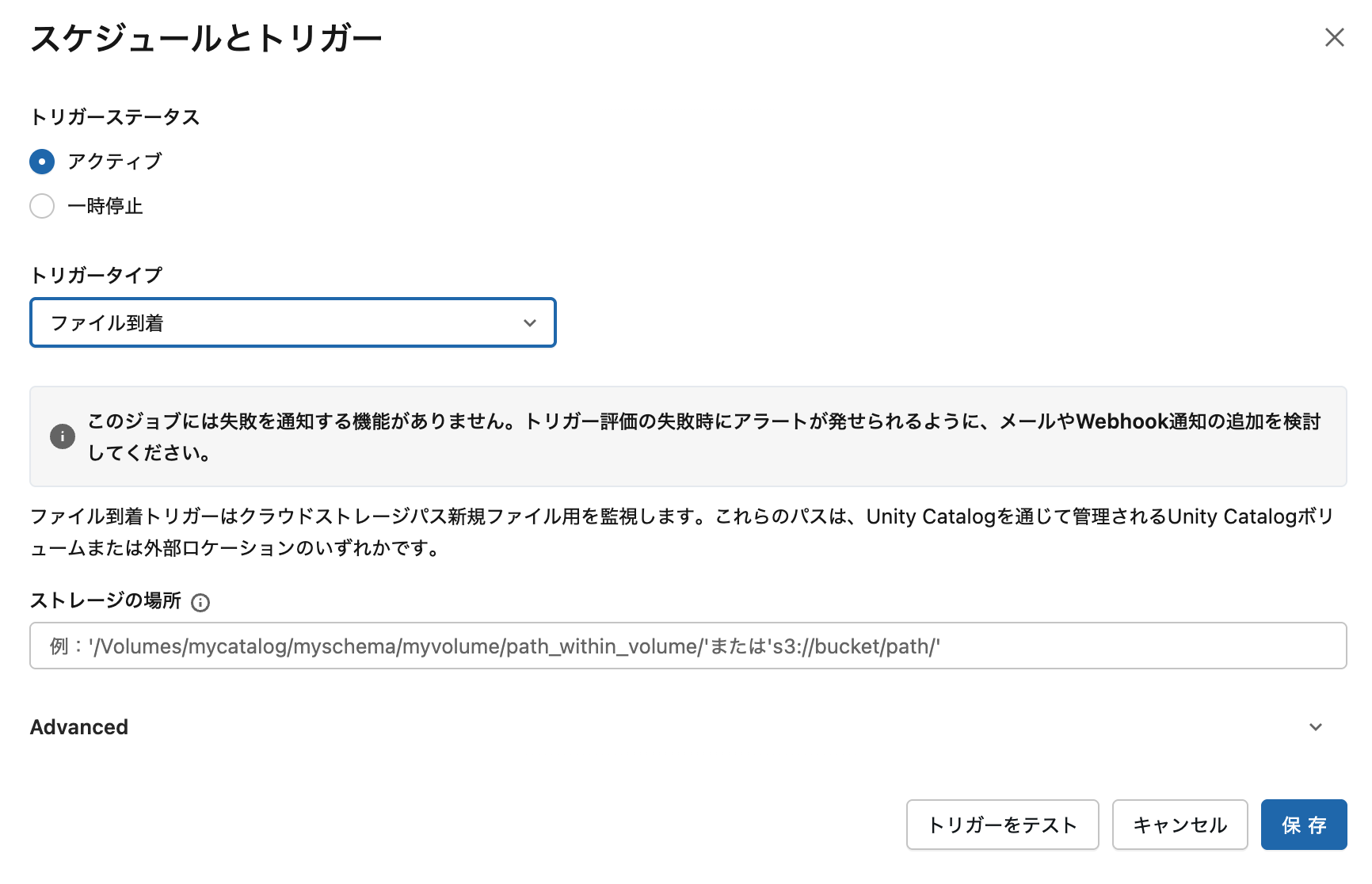
ファイル到着トリガー設定画面。外部ロケーションのパスと待機時間を設定します
3. テーブル更新トリガー
2024年11月20日にGA(一般提供)となった最新機能です。
設定:
テーブル: sales.transactions
待機時間: 30秒
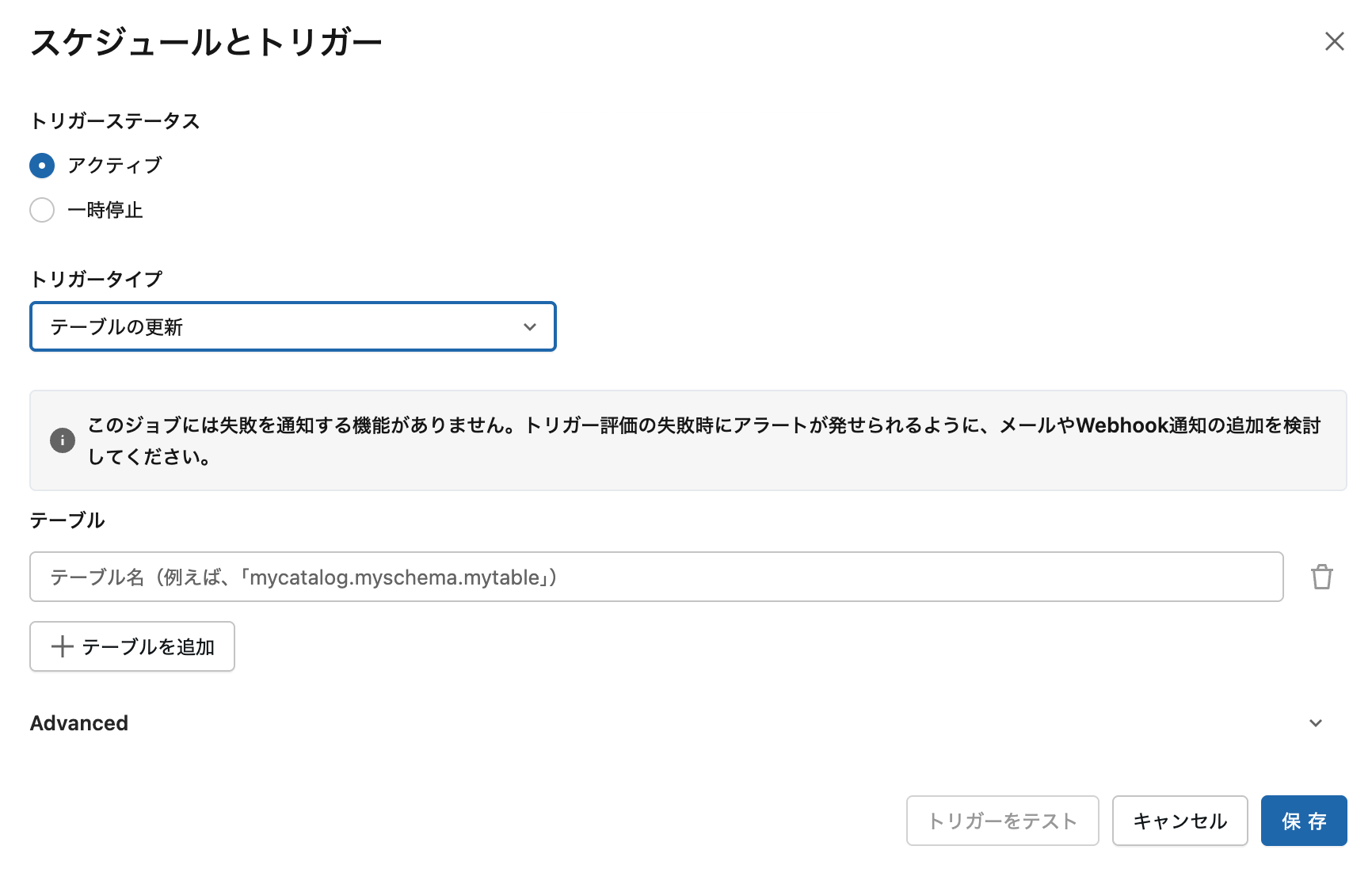
テーブル更新トリガー設定画面。監視するテーブルと待機時間を設定します
よくある質問(FAQ)
Q1: サーバレスとクラシッククラスター、どちらを使うべき?
A: 初心者はサーバレス一択!
| サーバレス | クラシッククラスター | |
|---|---|---|
| 設定の簡単さ | ⭐⭐⭐⭐⭐ | ⭐⭐ |
| 起動速度 | 高速 | 遅い |
| コスト効率 | 自動最適化 | 手動調整が必要 |
| おすすめ度 | ✅ 初心者向け | 上級者向け |
Q2: ジョブが失敗したらどうなる?
A: 自動的にリトライできます
公式ドキュメントによると、Lakeflowジョブは指数バックオフを使用してジョブを再試行します:
指数バックオフ:
- 連続した失敗がしきい値を超えると、待機時間を指数関数的に増やして再試行
- 連続失敗回数が表示される
- 次の再試行までの待機時間が表示される
- 成功と見なされるまでの無エラー実行期間が設定される
失敗時の動作:
- 1回目失敗 → 短い待機時間で再実行
- 2回目失敗 → より長い待機時間で再実行
- 3回目失敗 → さらに長い待機時間で再実行
- しきい値超過 → ジョブ失敗として記録(メール通知可能)
Q3: 実行履歴はどこで見る?
A: ジョブ画面から簡単に確認できます
ジョブとパイプライン → ジョブを選択 → 実行 タブ
確認できる情報:
- ✅ 実行開始時刻・終了時刻
- ✅ 実行時間(何分かかったか)
- ✅ 成功/失敗
- ✅ ログ(詳細なエラーメッセージ)
- ✅ 実行したユーザー
Q4: 失敗したジョブを修復できる?
A: はい、リペア機能があります
公式ドキュメントによると、失敗またはキャンセルされたマルチタスクジョブを部分的に修復できます:
リペア機能の特徴:
- 失敗したタスクのサブセットと依存タスクのみを実行
- 成功したタスクは再実行されない
- 必要な時間とリソースが削減される
- 修復前にジョブ設定を変更可能
修復手順:
- 実行タブで失敗したランを選択
- 実行の修復ボタンをクリック
- 再実行するタスクを確認
- パラメーターを修正(必要に応じて)
- 修復を実行
注意点:
- 2つ以上のタスクを持つジョブのみサポート
- ジョブクラスター使用時は新しいクラスターが生成される
Q5: 本番環境で使って大丈夫?
A: はい!99.95%の稼働時間SLA
- 数千の企業が本番環境で利用中
- 数百万のワークロードが毎日実行されている
- エンタープライズグレードの信頼性
次のステップ:さらに学ぶために
公式ドキュメント
おすすめのトピック:
関連記事
- Databricks Jobsを使ってみる - 実践的なチュートリアル
- Databricksジョブによる複数タスクのオーケストレーション - マルチタスクジョブの概要
- 新規ファイルが到着した際にDatabricksジョブを起動する - ファイル到着トリガーの詳細
- Lakeflow Spark宣言型パイプライン(Delta Live Tables)クイックスタート - パイプラインの作成
- Databricks Workflowsのご紹介 - ワークフロー機能の全体像
実際に試してみよう
ステップ1: 無料トライアルを開始
Databricks無料トライアル - 14日間無料で試せます
ステップ2: チュートリアルを実践
- ワークスペースにログイン
- サンプルNotebookをインポート
- 最初のジョブを作成
- 実行して結果を確認
ステップ3: コミュニティに参加
Databricks Japan - 最新情報と活用事例をチェック
まとめ
Lakeflowジョブで実現できること
✅ データパイプラインの自動化
- 毎日の集計レポート
- データウェアハウスのETL
- 機械学習モデルの再トレーニング
✅ イベント駆動の処理
- ファイルが届いたら自動処理
- テーブルが更新されたら下流ジョブを実行
- リアルタイムデータパイプライン
✅ 複雑なワークフローの管理
- タスクの依存関係
- 並列実行
- エラーハンドリング
「簡単ですごい」ポイントまとめ
1. サーバレスで管理不要
- インフラ管理? → 不要!
- スケーリング? → 自動!
- アップデート? → 自動!
2. UIでポチポチ作れる
- プログラミング経験なし → OK!
- ドラッグ&ドロップ → できる!
- すぐに動く → 確認できる!
3. 本番環境で安心
- 稼働時間SLA → 99.95%
- 実績 → 数百万のワークロード
- 信頼性 → エンタープライズグレード
4. コストも最適化
- 従量課金 → 使った分だけ
- Standard最適化 → 最大70%削減
- 無駄なし → 自動で停止
さあ、最初のワークフローを作ってみましょう! 🚀