How Delta Lake Is Forging a More Efficient Machine Learning Tomorrow - The Databricks Blogの翻訳です。
Delta LakeとMLflowの両方が頻繁に会話に上ってきますが、多くの場合、別個の製品としてです。この記事では、機械学習ユースケースにおけるDelta LakeとMLflowのシナジーにフォーカスを当て、堅牢なデータ基盤に基づき強固なMLの結果をもたらすために、どのようにDelta Lakeを活用するのかを説明します。
もし、データサイエンティストとして働いているのでしたら、MLflowを用いた完全なモデリングプロセス、そして、おそらくは機械学習モデルのプロダクションへのデプロイを経験したことがあるのかもしれません。MLflowトラッキング、MLflowモデルレジストリを使用してモデルのプロモーションを体験されたのかもしれません。コードのバージョン、クラスターの設定、データの場所などを追跡できるので、これらの機能によって提供される再現性に非常に幸せを感じたことがあるのかもしれません。
しかし、データ探索に費やす時間を短縮できるとしたらどうでしょうか?開発に使用したデータのバージョンを確認できるとしたらどうでしょうか?そして、トレーニングジョブのパフォーマンスが期待したほどではなかった時、あるいはアウトオブメモリー(OOM)エラーに遭遇した時にはどうしますか?
MLの開発、デプロイメントプロセスにおいて、これらの全てが起こり得ることです。これらに対するソリューションを考え出すことは非常に難しいことですが、これらのスケーラビリティに関する問題に対処するための方法の一つは、Delta Lakeを活用することです。
Delta Lake(略してDelta)は、お使いのデータレイクに信頼性をもたらすオープンソースのストレージレイヤーです。メリットを享受するために作業の方法を変える必要はありまえんし、新たなAPIを学ぶ必要もありません。この記事では、データサイエンティストとMLエンジニアが直面している一般的な問題にフォーカスし、Deltaがどのようにそれらの問題に取り組んでいるのかをハイライトします。
クエリーが遅いのですが、理由がわかりません
お使いのデータセットのサイズに依存しますが、データの学習が時間のかかるプロセスであることに気づくかもしれません。クエリーを並列化したとしても、別の内部プロセスがクエリーを遅くしている場合があります。Deltaには、ETLや探索的データ分析におけるアドホッククエリーなど、様々なクエリーの性能を改善する最適化Deltaエンジンがあります。それでも性能が期待通りでない場合には、DeltaフォーマットではDESCRIBE DETAIL機能を活用することができます。これによって、クエリーを発行しているテーブルがどの程度のサイズなのか、どれだけのファイルで構成されているのか、スキーマに関する情報などについて、クイックに洞察を得ることができます。このようにして、Deltaはお使いのノートブックから使用できる、性能問題特定のためのビルトインツールを提供し、複雑性を抽象化してくれます。

クエリー実行の待ち時間は一般的な問題であり、データボリュームが増加すればするほど悪化します。幸運なことに、Deltaではデータスキッピングのようないくつかの最適化技術を提供しています。データが増加し、DatabricksのDeltaテーブルに追加される都度、サポートされる全てのカラムにおいて、ファイルレベルでのmin/max統計情報が収集されます。そして、テーブルに対してクエリーを行う際、DatabricksのDeltaは、まず初めにどのファイルは問題なくスキップでき、どのファイルが対象のものであるのかを判断するために、これらの統計情報に問い合わせを行います。設定なしに、高速なクエリーを実現するために、DatabricksのDelta Lakeはクエリー実行時にこの情報を活用します。
データスキッピングを活用するもう一つの方法として、Deltaに対して明示的にカラムを指定してデータの最適化をアドバイスできます。これは、同じファイル内で関連する情報を近い場所に配置するテクニックであるZ-Orderingで実行できます。同じカラムに対してフィルタリング条件を設定して、繰り返しクエリーを行う際に結果を高速に取得したい場合には、テーブルの当該カラムに対してZORDER BYを適用します。カラムが高いカーディナリティを示す場合、すなわち、異なる値が数多く含まれている場合には、非常に効果があるテクニックとなります。
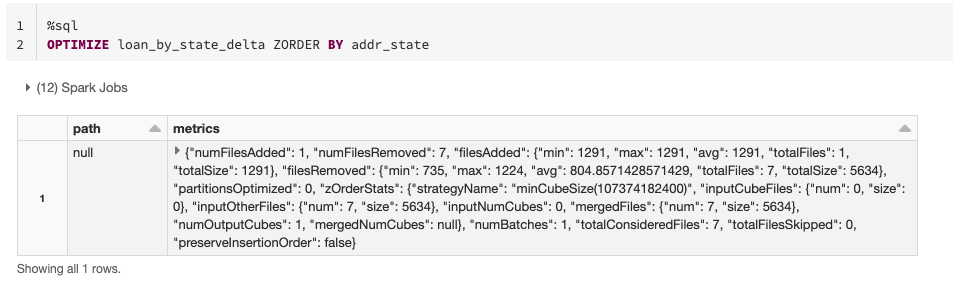
探索段階において、テーブルに対する一般的なフィルタリング条件がわかっていない場合には、小さなファイルを大きなファイルにまとめる最適化を行うことも可能です。これによって、データに対してクエリーを実行する際にスキャンするファイルを削減するので、性能を改善できます。この場合、ZORDERを指定しないでOPTIMIZEコマンドを実行します。

大量のデータを取り扱っていて、サブセットのみを最適化したい場合には、WHEREを用いてパーティションに対する述語を指定して、最適化したいデータのサブセット(例えば、最近追加されたデータ)を指示します。

データがメモリに収まりません
モデルをトレーニングする際、全てのデータセットではなく特定の期間のサブセットや、特定のサブセットを対象にトレーニングを行うケースがあるかもしれません。通常のワークフローは、全データの読み込み、全データのスキャン後メモリーにロード、対象データの保持、という流れになります。この段階でエラーが起きなかったとしても、このプロセスは非常に遅いものになります。しかし、もし最初から必要なファイルを読み込むことで、最終的には削除するデータであなたのマシンがオーバーロードすることを回避できるとしたらどうでしょうか?ここで、パーティションプルーニング(刈り込み)が役に立ちます。
通常パーティションについて話をする際には、パーティションカラムの別個の値に対応するサブディレクトリのことを参照しています。フィルタリングを行いたいカラムでデータがパーティション分けされているのであれば、正しいサブディレクトリのみをスキャンし、他は無視するプルーニング技術を利用することができます。これは大したことではないように見えますが、モデルを最終化するために必要となるデータ読み込み、繰り返しの数を考慮した際に非常に重要なものになってきます。このため、データに対して頻繁に行うクエリーのパターンを理解することは、優れたパーティションを選択し、全体的なオペレーションコストを引き下げることができます。
あるいは、データがパーティション分けされておらず、単体のエグゼキュータにデータが乗り切らずに、OOMエラーに遭遇することがあるかもしれません。DESCRIBE DETAIL、パーティショニング、ZORDERを組み合わせることで、エラーの原因を特定し、解決する助けになります。
データ品質の改善に1日の半分を費やしています
データセットに取り組んでいるデータチームが、変数に不正な値、例えば1485年のタイムスタンプが含まれていることを発見するということはよくあることです。このようなデータ問題を特定し取り除くことは、大変手間のかかる作業となります。これらの行を削除することは、.filter()を用いたクエリーが処理に大量のリソースを必要とすることから、計算リソースの観点からも高コストです。理想的なシナリオにおいては、テーブルに不正な値が追加されることを完全に防ぐことができるかもしれません。ここでは、Deltaの制約と、Delta Live Tablesのエクスペクテーションが役立ちます。特に、Delta Live Tablesを活用することで、期待するデータ品質、および目標のデータ品質を満たさない場合にはどうすべきかを指定することができます。過去に遡ってデータを削除するのではなく、プロアクティブにデータを綺麗な状態に保ち、すぐに利用することができます。
同じように、モデリングに使用しているデータに対して、誰かが誤ってカラムを追加することを防ぎたいケースがあるかもしれません。ここでもDeltaはシンプルなソリューションを提供します:自動スキーマアップデートです。デフォルトでは、Deltaテーブルに書き込まれるデータは明示的な指定がない限り、既知のスキーマに準拠する必要があります。
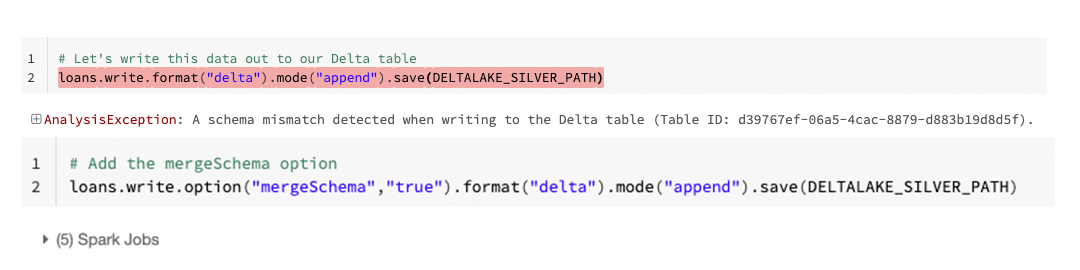
何かしらの理由で誰かがスキーマを変更してしまった場合には、describe detailコマンド、およびDESCRIBE HISTORYを用いて、現状のスキーマがどのようなものか、誰がスキーマを変更したのかを容易にチェックすることができます。これによって、同僚のデータサイエンティスト、データエンジニア、データアナリストとコミュニケーションをとり、なぜ彼らがスキーマを変更したのか、その変更は適切か否かを理解することができます。
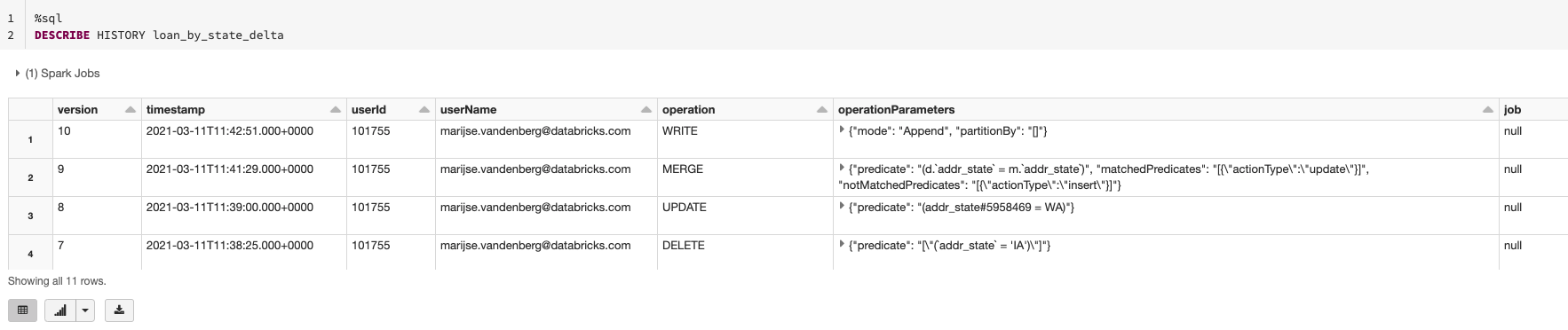
変更が不適切な場合、あるいは過失によるものである場合、タイムトラベルの機能を用いて、以前のバージョンに復旧する選択肢があります。
トレーニングの際に使用したデータがわからず、結果を再現できません
特定のモデルに対して特徴量を作成した際、途中で別のバージョンの特徴量を試すケースがあります。同じ特徴量に対して複数のバージョンを用いることは、以下のような課題を引き起こします。
- トレーニングに用いた特徴量のバージョンを追跡できなくなってしまい、トレーニング結果を再現できなくなる。
- 実運用で用いる特徴量とトレーニングで用いた特徴量が異なるため、実運用中のモデルの結果が目標水準を満たさない。
これを避けるためのソリューションの一つは、複数バージョンの特徴量テーブルを作成し、(例えばApache Parquetを用いて)blobストレージに格納することです。使用したデータへのパスは、MLflowランの過程でパラメーターとして記録されます。しかし、これは依然として手動のプロセスであり、膨大なデータストレージ容量を必要とします。ここで、Deltaは代替案を提示します。手動で異なるバージョンのデータを保存するのではなく、データに対してなされた変更を自動で追跡するDeltaのデータバージョン管理機能を活用します。さらに、Deltaは、モデルトレーニングに使用されたデータの場所、Deltaとしてデータを書くのしている場合にはデータのバージョンを追跡するmlflow.spark.autolog()のような自動ロギングをサポートしている様々なMLflowのフレーバーと統合されています。このようにして、複数のバージョンのデータを格納することなしに、ストレージコストを削減することに加え、どのデータをトレーニングに使ったのかで混乱することがなくなります。

しかし、データのバージョンを際限なく保存していくことで、やはりストレージコストが問題になってきます。Deltaでは、保持したいデータバージョンの数を指定することで、保持期間の閾値(VACUUM)を設けることができます。例えば、時間が経ってから新たなモデルに対してA/Bテストを実施するために、長期間にわたってデータをアーカイブしたい場合には、Deltaのクローン機能を用いることができます。ディープクローンは、指定されたバージョンのメタデータ、データファイルの完全なコピーを作成し、これにはパーティション、制約など他の情報も含まれます。ディープクローンの文法はシンプルであり、時間が経ってからのモデルテストのためのテーブルのアーカイブも非常にシンプルなものとなります。

実運用で使用している特徴量と開発時に使用した特徴量が一致しません
データのバージョン管理に関する課題が解決されたとしても、特定の特徴量に対するコードの再現性について心配されるかもしれません。ここでのソリューションは、Deltaの基盤を完全に活用し、この記事で述べられたアプローチをサポートするDatabricksのFeature Storeとなります。あらゆる特徴量の開発はDeltaテーブル上で行われ、どのように特徴量が作成されたのかがわかるようにコードとバージョンは追跡され、これらは容易にFeature Storeに記録されます。さらに、容易に特徴量を検索し、簡単に特徴量を利用できるようにするための特徴量検索ロジックを提供するなど、特徴量に対してさらなるガバナンスを提供します。
詳しく知りたい場合には
この記事で議論された様々なコンセプトをより学びたい方は、以下のリソースを参照ください。
- How to Easily Clone Your Delta Lake Data Tables with Databricks - The Databricks Blog
- Databricks Feature Store : データ、MLOpsと協調設計された史上初のフィーチャーストア - Qiita
- ACID Transactions on Data Lakes, From A-Z: 5 Lakehouse Tech Talks - The Databricks Blog
- Delta Live Tablesのローンチ : 信頼性のあるデータエンジニアリングを簡単に実現 - Qiita
- Data Time Travel by Delta Time Machine - Databricks
- Delta Lake: The definitive guide (Chapter 3: Time Travel)
まとめ
この記事では、データサイエンティストが直面する一般的な課題をレビューしました。そして、どのようにDelta Lakeがこれらの課題を解決あるいは軽減し、データサイエンスと機械学習プロジェクトが成功する確率を引き上げるのかを学びました。
詳細は、Delta Lakeをご覧ください。