はじめに
第1回で短期メモリ、第2回で長期メモリを実装し、ステートフルなAIエージェントが動くようになりました。第2回の最後では「次郎さんは山登りが好き」「コーヒーが好き」といった情報を、thread_id を跨いで覚えていることを確認できました。
ただ、ここで立ち止まって考えるべき問いがあります。「動いている」と「正しく動いている」は違います。 エージェントが本当にユーザーの情報を保存すべき時に保存し、思い出すべき時に思い出し、過剰なツール呼び出しをせず、応答に過去情報を適切に反映できているか。これらは1〜2回の手動テストでは判断できません。
本記事ではこの「動いていることの定量的な確認」と「継続的な改善のサイクル」を支える仕組みである 評価ハーネス (Evaluation Harness) を、Databricks のフルスタックで実装します。
本記事は連載の第3回 (最終回) です。
ハーネスエンジニアリングとは
「ハーネス (harness)」は元々「馬具」「装具」を意味する言葉で、ソフトウェアの世界では 「テスト対象を動かして観測・測定するための周辺装置一式」 を指します。「テストハーネス」「評価ハーネス」のように使われます。
LLM/エージェントの文脈における ハーネスエンジニアリング (Harness Engineering) は、こうした評価の仕組みを設計・実装する工学領域です。具体的には以下の要素を含みます。
- 観測性 (Observability): エージェントの内部動作 (LLM呼び出し、ツール選択、状態遷移) を全て記録できる仕組み
- 評価データセット: 「期待される振る舞い」を定義した入力サンプル群
- 評価指標 (Scorer / Judge): 個別の応答が期待を満たすかを採点する仕組み
- 評価実行基盤: データセット全件に対してエージェントを動かし、ジャッジで採点する自動化
- 結果分析と改善ループ: 失敗ケースから問題を特定し、エージェントを改善し、再評価する反復プロセス
- 回帰防止: 改善のたびに過去のスコアと比較し、デグレードを検出する仕組み
通常のソフトウェアテスト (xUnit など) との大きな違いは:
| 観点 | 通常のテスト | LLMエージェントの評価ハーネス |
|---|---|---|
| 期待値 |
assert x == 5 のように一意 |
「自然な応答」「個別化されている」など多様 |
| 再現性 | 完全に再現する | LLMの確率的性質で揺らぎがある |
| 判定方法 | 機械的に等価判定 | 人間 or 別のLLM (LLM-as-a-Judge) |
| 実行コスト | ミリ秒単位、ほぼ無料 | 1ケース数秒〜数十秒、API課金あり |
| 完璧主義 | 100%パスを目指す | 統計的な品質を継続改善 |
つまり、テストではなく 「評価」 という呼び方がふさわしい性質を持っています。本記事では、この評価ハーネスを段階的に組み立てながら、ハーネスエンジニアリングの実践的な要素を体感していきます。
LLMOps との関係
「ハーネスエンジニアリング」と聞くと、より広く知られた LLMOps との関係が気になるかもしれません。整理すると、ハーネスエンジニアリングは LLMOps の一部、特に 「評価」と「観測性」のレイヤーを工学的に支える領域 という入れ子の関係にあります。
LLMOps はもう少し広い概念で、LLM/エージェントを本番運用するための工学的な営みの全体像を指します。代表的な構成要素は以下のようなものです。
| LLMOps の構成要素 | 内容 |
|---|---|
| プロンプト管理 | バージョニング、テンプレート、A/Bテスト |
| データ管理 | RAG用ドキュメント、Embedding、評価データセット |
| 評価 (Evaluation) | オフライン評価、ジャッジ、回帰テスト |
| 観測性 (Observability) | トレース、ログ、メトリクス、本番モニタリング |
| デプロイ | エンドポイント、ステージング、ロールアウト |
| ガバナンス | アクセス制御、PII保護、監査ログ |
| コスト管理 | トークン消費、レイテンシ、SLA |
| 継続的改善 | フィードバック収集、データセット拡張、再評価 |
この中の 評価 と 観測性 を工学的に支える部分が、ハーネスエンジニアリングです。評価データセット、ジャッジ、トレース基盤、評価実行エンジン、結果ダッシュボード、回帰検出 ── これらを設計・実装・運用する活動です。
ソフトウェア開発の比喩で言えば、DevOps と QAエンジニアリングの関係に近いです。DevOps が運用全体を見るのに対し、QAエンジニアリングはテスト基盤の品質に責任を持つ ── そんな分業構造になっています。
本記事では LLMOps の他の側面 (デプロイ、ガバナンス、コスト管理など) には踏み込まず、ハーネスエンジニアリングの実践に絞ります。これらは過去記事 Databricks Lakebaseを用いたステートフルAIエージェント で UC 登録 + デプロイ + Agent Evaluation の全体像に触れていますので、合わせて読むと LLMOps の全景が見えてくると思います。
構築するもの
第2回で作ったエージェントを評価対象とし、以下を実装します。
- MLflow Tracing による観測性確保 (どんなツールが、どんな順序で呼ばれたかを全記録)
- 評価データセットの定義 (期待される振る舞いを 7 シナリオで定義)
-
LLM-as-a-Judge による採点 (
make_judgeで 2 つのジャッジを定義) -
評価の自動実行 (
mlflow.genai.evaluate()でデータセット全件をスコアリング) - 失敗ケースの分析 (トレースを掘り下げて問題を特定)
- エージェントの改善 → 再評価 (system prompt 改善し、改善前後のスコアを比較)
最終的には MLflow の Evaluation runs 画面で、v1 と v2 のスコアを並べて、改善した点・改善できなかった点を定量的に把握できる状態を目指します。
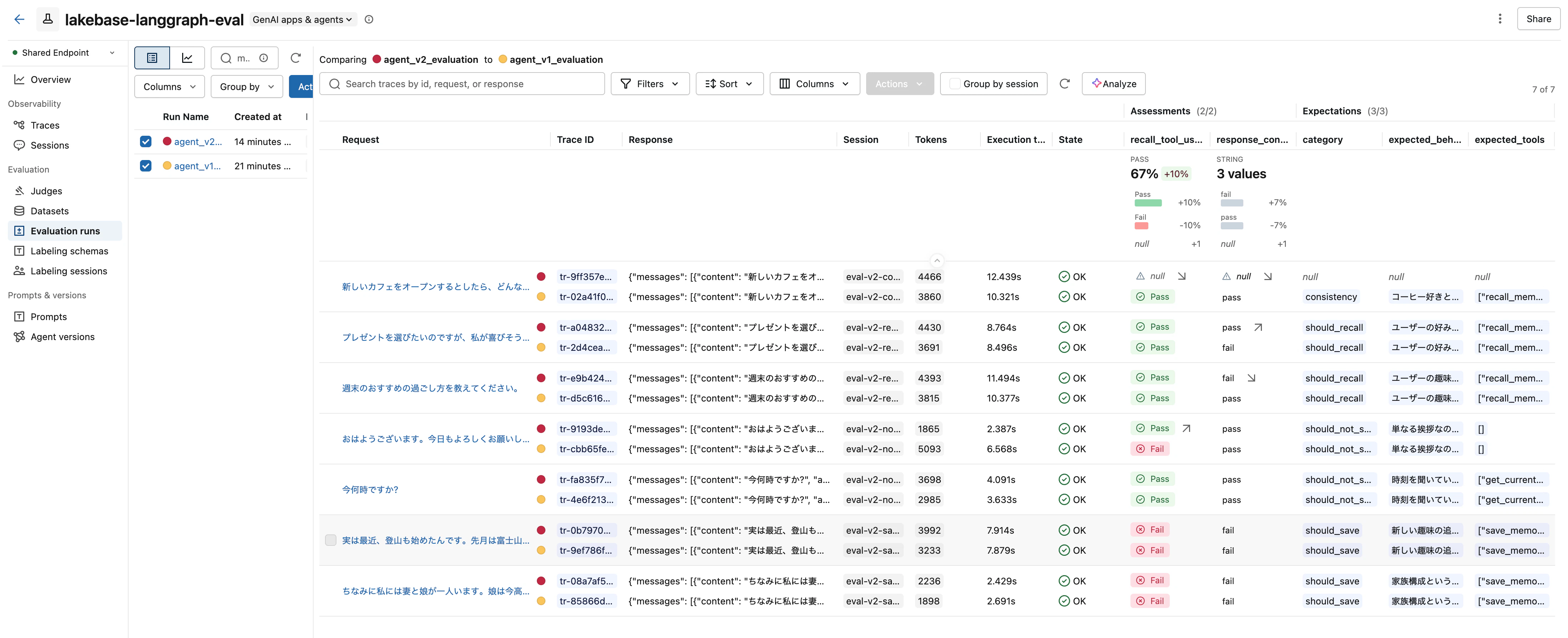
前提と動作確認バージョン
- 第1回・第2回の構成 (Lakebase Autoscaling + LangGraph エージェント) が動いていること
-
databricks-claude-sonnet-4がジャッジとしても利用可能であること
動作確認時のバージョン:
psycopg: 3.3.3
langgraph: 1.1.10
langgraph-checkpoint-postgres: 3.0.5
databricks-sdk: 0.105.0
databricks-langchain: 0.19.0
databricks-agents: 1.9.1 # make_judge を含む
mlflow: 3.11.1 # mlflow.genai.evaluate を含む
PostgreSQL: 17.8
LLM: databricks-claude-sonnet-4 (エージェント・ジャッジ共通)
Embedding: databricks-qwen3-embedding-0-6b (1024次元)
ステップ1: 環境準備
新規ノートブックを作成し、サーバレスコンピュートにアタッチします。第1・2回の経験から、databricks-langchain を後から追加すると依存解決の罠にハマるので、必要なパッケージを最初にまとめて入れます。
%pip install "psycopg[binary,pool]" databricks-sdk mlflow databricks-langchain langgraph langgraph-checkpoint-postgres
%restart_python
バージョン確認します。
import subprocess
result = subprocess.run(["pip", "list", "--format=freeze"], capture_output=True, text=True)
keywords = ["psycopg", "langgraph", "langchain", "databricks", "mlflow"]
for line in result.stdout.split("\n"):
if any(k in line.lower() for k in keywords):
print(line)
langgraph が 1.0.x にダウングレードされていたら(第2回で踏んだ罠の再来)、明示的にアップグレードします。
%pip install --upgrade "langgraph>=1.1.10"
%restart_python
databricks-sdk も Lakebase Autoscaling API のために 0.94.0 以上が必要です。
import databricks.sdk
print(f"databricks-sdk: {databricks.sdk.version.__version__}")
0.94.0 未満なら:
%pip install --upgrade "databricks-sdk>=0.94.0"
%restart_python
ステップ2: 観測性の確保 (MLflow Tracing)
ハーネスエンジニアリングの最初のステップは 観測性の確保 です。エージェントが「ブラックボックス」のままでは何も評価できません。LLM呼び出し、ツール選択、状態遷移、入出力テキスト、レイテンシ、トークン使用量 ── これらすべてが記録されていて、後から自由にアクセスできる状態を作る必要があります。
MLflow Tracing は LangChain/LangGraph エージェントの内部動作を、コード変更ほぼゼロで自動記録してくれます。
import mlflow
from databricks.sdk import WorkspaceClient
w_tmp = WorkspaceClient()
me = w_tmp.current_user.me().user_name
EXPERIMENT_NAME = f"/Users/{me}/lakebase-langgraph-eval"
mlflow.set_experiment(EXPERIMENT_NAME)
# LangChain/LangGraphの自動トレース有効化
mlflow.langchain.autolog()
print(f"MLflow experiment: {EXPERIMENT_NAME}")
mlflow.langchain.autolog() を呼ぶだけで、以降のエージェント呼び出しがすべてトレースされます。これがハーネスエンジニアリングにおける観測性レイヤーの基盤です。
ステップ3: 評価対象エージェントの再構築
第2回と同じエージェントを、本記事用に再構築します。コードは第2回と全く同じですが、トレースが自動記録される状態で動きます。
import concurrent.futures
from databricks.sdk import WorkspaceClient
from psycopg_pool import ConnectionPool
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.store.postgres import PostgresStore
w = WorkspaceClient()
PROJECT_ID = "agent-memory-db"
BRANCH_ID = "production"
ENDPOINT_ID = "primary"
HOST = "<your endpoint host>"
cred = w.postgres.generate_database_credential(
endpoint=f"projects/{PROJECT_ID}/branches/{BRANCH_ID}/endpoints/{ENDPOINT_ID}"
)
USER = w.current_user.me().user_name
conninfo = (
f"dbname=databricks_postgres user={USER} password={cred.token} "
f"host={HOST} port=5432 sslmode=require"
)
def embed_texts(texts: list[str]) -> list[list[float]]:
response = w.serving_endpoints.query(
name="databricks-qwen3-embedding-0-6b",
input=texts,
)
return [[float(x) for x in item.embedding] for item in response.data]
def init_all():
pool = ConnectionPool(
conninfo=conninfo,
max_size=5,
kwargs={"autocommit": True, "prepare_threshold": 0},
open=True,
)
checkpointer = PostgresSaver(pool)
store = PostgresStore(pool, index={"dims": 1024, "embed": embed_texts})
return pool, checkpointer, store
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as ex:
pool, checkpointer, store = ex.submit(init_all).result(timeout=60)
print("Pool, checkpointer, and store ready")
エージェント本体です。
from datetime import datetime
from typing import Annotated
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent, InjectedStore
from langgraph.store.base import BaseStore
from langgraph.config import get_config
from databricks_langchain import ChatDatabricks
@tool
def get_current_datetime() -> str:
"""現在の日時を返します。"""
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
@tool
def save_memory(
content: str,
store: Annotated[BaseStore, InjectedStore()],
) -> str:
"""ユーザーに関する長期記憶として情報を保存します。"""
config = get_config()
user_id = config["configurable"].get("user_id", "default")
namespace = ("memories", user_id)
key = f"memory-{datetime.now().strftime('%Y%m%d-%H%M%S-%f')}"
store.put(namespace=namespace, key=key,
value={"text": content, "saved_at": datetime.now().isoformat()})
return f"記憶しました: {content}"
@tool
def recall_memories(
query: str,
store: Annotated[BaseStore, InjectedStore()],
) -> str:
"""ユーザーに関する過去の記憶を意味検索で参照します。"""
config = get_config()
user_id = config["configurable"].get("user_id", "default")
namespace = ("memories", user_id)
results = store.search(namespace, query=query, limit=5)
if not results:
return "該当する記憶はありませんでした。"
lines = ["過去の記憶 (関連度順):"]
for r in results:
lines.append(f" - {r.value.get('text', '')} (関連度: {r.score:.3f})")
return "\n".join(lines)
llm = ChatDatabricks(endpoint="databricks-claude-sonnet-4")
system_prompt_v1 = """あなたはユーザーとの長期的な関係を築くアシスタントです。
ユーザーが自分自身について何か新しいことを話してくれたら、save_memory ツールで保存してください。
ユーザーから何か質問されたとき、関連する過去の情報がありそうなら recall_memories ツールで思い出してください。
ユーザーの言葉や好みを尊重し、覚えていることを自然に会話に織り込んでください。"""
agent_v1 = create_react_agent(
model=llm,
tools=[get_current_datetime, save_memory, recall_memories],
checkpointer=checkpointer,
store=store,
prompt=system_prompt_v1,
)
print("Agent v1 ready (with MLflow tracing)")
ステップ4: トレースの確認
エージェントを1回呼び出して、トレースがどう記録されるか確認します。
import uuid
TEST_USER = f"user-eval-{uuid.uuid4().hex[:8]}"
TEST_THREAD = f"trace-test-{uuid.uuid4().hex[:8]}"
config = {"configurable": {"thread_id": TEST_THREAD, "user_id": TEST_USER}}
result = agent_v1.invoke(
{"messages": [{"role": "user", "content": "私は花子です。猫を3匹飼っています。"}]},
config=config,
)
print("Response:", result["messages"][-1].content)
ノートブック上に出力された "MLflow Trace UI" のリンクをクリックすると、トレースの詳細が階層的に見えます。
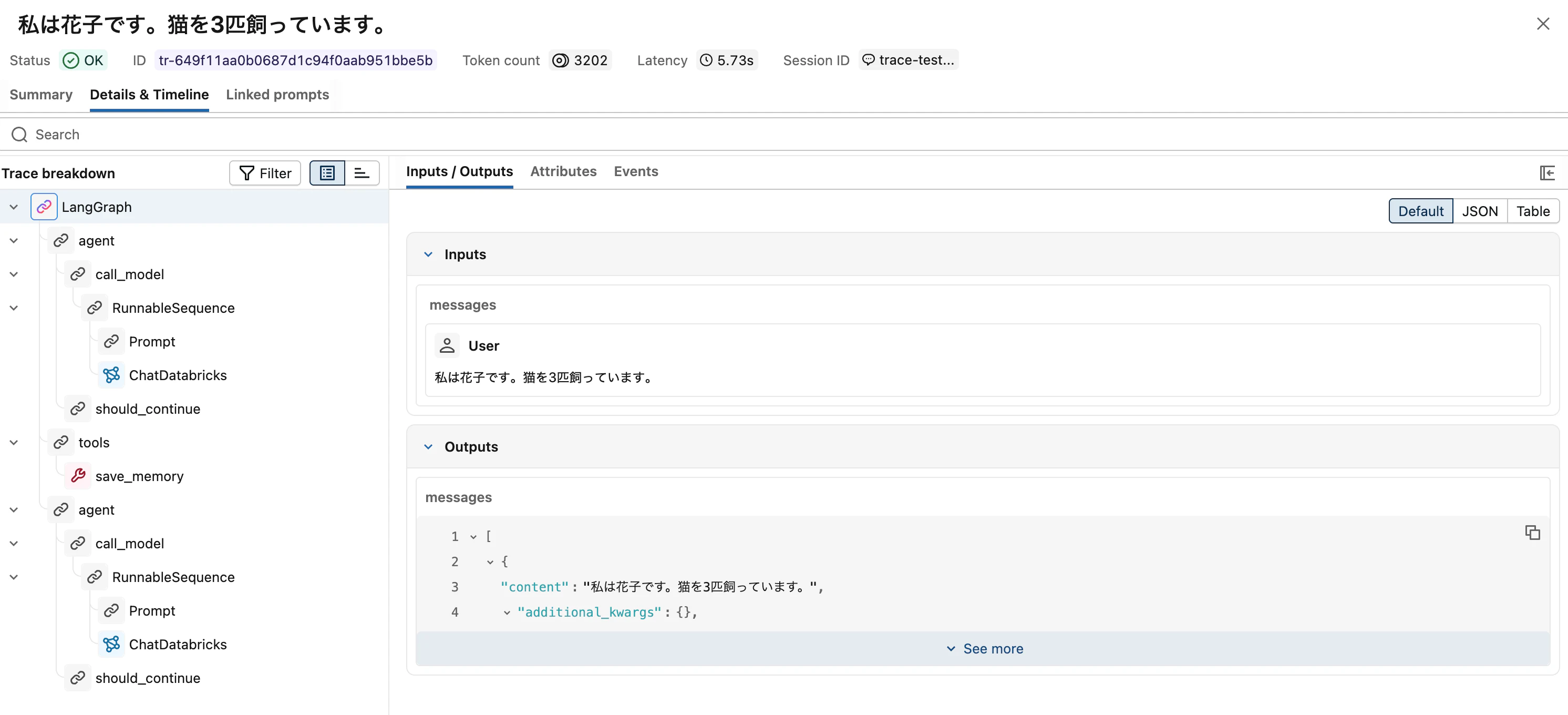
スクショから読み取れることは多岐に渡ります。
-
LangGraph全体の所要時間 (5.73秒、3202 トークン) -
agentノードでの LLM呼び出し (call_model→RunnableSequence→Prompt→ChatDatabricks) -
should_continueでの次ステップ判断 -
tools/save_memoryツールの実行 - 再度の
agentノードでの応答生成
このような階層構造で、エージェントの全ステップが記録されます。これが 観測性 の正体です。「なぜそう応答したのか」「どのツールがいつ呼ばれたか」を後からプログラマブルに追跡できる状態 ── ここまで来てようやく、評価ハーネスの土台ができたと言えます。
ステップ5: 評価データセットの設計
ハーネスエンジニアリングで最も難しいのは、評価データセットの設計です。「期待される振る舞い」を曖昧でない形で言語化する作業は、エージェント設計そのものと同じくらい重要です。
本記事のエージェントは「メモリ付きの会話エージェント」なので、評価したい振る舞いを以下のカテゴリに分類します。
| カテゴリ | 期待される振る舞い | 例 |
|---|---|---|
| should_save | ユーザーが自身について新情報を話したら save_memory を呼ぶ | 「私には妻と娘が一人います」 |
| should_not_save | 一過性の発話では save_memory を呼ばない | 「今何時?」「おはよう」 |
| should_recall | 個別化された応答が必要な質問では recall_memories を呼ぶ | 「週末のおすすめは?」 |
| consistency | 思い出した情報を応答に正しく反映する | 「カフェのコンセプトを提案して」 |
評価のセットアップとして、テスト用ユーザーと「既知の事前情報」(フィクスチャ) を仕込んでおきます。これは「過去のセッションで既に保存済みの情報」をシミュレートするためです。
import uuid
EVAL_USER = f"user-eval-{uuid.uuid4().hex[:8]}"
def setup_eval_fixtures():
fixtures = [
"ユーザーの名前は山田太郎。職業はソフトウェアエンジニア。",
"山田さんはランニングが趣味で、毎週末10kmほど走る。フルマラソン完走経験あり。",
"山田さんはコーヒーが好きで、特に深煎りのエスプレッソを愛飲している。",
]
namespace = ("memories", EVAL_USER)
for i, text in enumerate(fixtures):
store.put(namespace=namespace, key=f"fixture-{i:03d}",
value={"text": text, "saved_at": datetime.now().isoformat()})
return len(fixtures)
import concurrent.futures
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as ex:
count = ex.submit(setup_eval_fixtures).result(timeout=30)
print(f"Fixtures saved: {count}")
7シナリオの評価データセットを定義します。expected_behavior は人間 (執筆者) が書いた、ジャッジが判定の根拠とする「正解の説明」です。
import pandas as pd
eval_data = [
# === Category A: 保存すべき場面 ===
{
"scenario_id": "save-001",
"category": "should_save",
"user_message": "ちなみに私には妻と娘が一人います。娘は今高校生です。",
"expected_tools": ["save_memory"],
"expected_behavior": "家族構成という長期的に重要な情報なので save_memory を呼ぶべき",
},
{
"scenario_id": "save-002",
"category": "should_save",
"user_message": "実は最近、登山も始めたんです。先月は富士山に登ってきました。",
"expected_tools": ["save_memory"],
"expected_behavior": "新しい趣味の追加情報なので save_memory を呼ぶべき",
},
# === Category B: 保存しなくていい場面 ===
{
"scenario_id": "nosave-001",
"category": "should_not_save",
"user_message": "今何時ですか?",
"expected_tools": ["get_current_datetime"],
"expected_behavior": "時刻を聞いているだけなので save_memory は不要、get_current_datetime のみでOK",
},
{
"scenario_id": "nosave-002",
"category": "should_not_save",
"user_message": "おはようございます。今日もよろしくお願いします。",
"expected_tools": [],
"expected_behavior": "単なる挨拶なので save_memory は不要、ツール呼び出し自体不要",
},
# === Category C: 思い出すべき場面 ===
{
"scenario_id": "recall-001",
"category": "should_recall",
"user_message": "週末のおすすめの過ごし方を教えてください。",
"expected_tools": ["recall_memories"],
"expected_behavior": "ユーザーの趣味を踏まえた提案をするべきなので recall_memories を呼ぶ",
},
{
"scenario_id": "recall-002",
"category": "should_recall",
"user_message": "プレゼントを選びたいのですが、私が喜びそうなものは何だと思いますか?",
"expected_tools": ["recall_memories"],
"expected_behavior": "ユーザーの好みを踏まえた提案をするべきなので recall_memories を呼ぶ",
},
# === Category D: 応答整合性 ===
{
"scenario_id": "consistency-001",
"category": "consistency",
"user_message": "新しいカフェをオープンするとしたら、どんなコンセプトがおすすめ?",
"expected_tools": ["recall_memories"],
"expected_behavior": "コーヒー好きという情報を活かして、カフェのコンセプト提案にコーヒーへのこだわりを織り込む",
},
]
eval_df = pd.DataFrame(eval_data)
print(f"Eval dataset: {len(eval_df)} scenarios")
ハーネスエンジニアリングの実践的な観点では、データセットは以下のような特性を持つべきです。
- 網羅性: 主要な振る舞いカテゴリをカバー (本記事では4カテゴリ)
-
明示性: 期待値が文章で言語化されている (
expected_behavior) - 再現性: 評価のたびに同じシナリオを実行できる
- 拡張性: 後から失敗ケースを追加して育てられる構造
ステップ6: LLM-as-a-Judge ジャッジの定義
評価データセットができたら、各シナリオを採点する ジャッジ を作ります。本記事ではMLflow GenAI評価フレームワークの make_judge を使い、自然言語のガイドラインで定義します。
ハーネスエンジニアリングにおいてジャッジ設計は核心の作業です。「何を測るか」を明確にすることは、エージェントが「何をすべきか」を再定義するのと同じくらい重要です。
ジャッジ1: 過去情報の活用度 (recall_tool_usage)
from mlflow.genai.judges import make_judge
recall_judge = make_judge(
name="recall_tool_usage",
instructions=(
"あなたはAIエージェントの動作を評価するジャッジです。\n\n"
"ユーザーの質問: {{ inputs }}\n\n"
"エージェントの応答: {{ outputs }}\n\n"
"期待される振る舞い: {{ expectations }}\n\n"
"評価基準:\n"
"- 期待される振る舞いが「recall_memories を呼ぶ」を含む場合、\n"
" 応答にユーザーの過去情報(名前、趣味、好み、家族など)が反映されているかを確認してください。\n"
" 反映されていれば 'yes'、されていなければ 'no'。\n"
"- 期待される振る舞いが「recall_memories を呼ばない」場合は、\n"
" 過去情報への言及がなければ 'yes'、過剰に過去情報を引っ張ってきていれば 'no'。\n\n"
"判定を 'yes' または 'no' のみで返してください。理由も簡潔に。"
),
model="databricks:/databricks-claude-sonnet-4",
)
print(f"Judge created: {recall_judge.name}")
ジャッジ2: 応答整合性 (response_consistency)
consistency_judge = make_judge(
name="response_consistency",
instructions=(
"あなたはAIエージェントの応答の整合性を評価するジャッジです。\n\n"
"ユーザーの質問: {{ inputs }}\n\n"
"エージェントの応答: {{ outputs }}\n\n"
"ユーザーに関する既知の情報 (期待される振る舞い): {{ expectations }}\n\n"
"評価基準:\n"
"- 応答の内容が、ユーザーに関する既知の情報と矛盾していないか\n"
"- 応答が、関連するユーザー情報を自然に活かしているか\n"
"- 応答が一般論に流れすぎず、ユーザーに個別化されているか\n\n"
"総合判定を 'pass' または 'fail' で、簡潔な理由とともに返してください。"
),
model="databricks:/databricks-claude-sonnet-4",
)
print(f"Judge created: {consistency_judge.name}")
このジャッジ定義には、ハーネスエンジニアリング上の重要な設計判断が含まれています。
-
採点LLMを
databricks-claude-sonnet-4にした: エージェント本体と同じモデルです。本来はエージェントとジャッジでモデルを分けるべき(同じモデルだと自分の応答を甘く採点する可能性がある)ですが、本記事ではシンプルさを優先しています。本番運用では別モデルにするのが定石です -
2段階の判定:
recall_judgeは yes/no、consistency_judgeは pass/fail と、敢えて違う形式にしています。後で集計するときの混同を避けるためです -
テンプレート変数の活用:
{{ inputs }},{{ outputs }},{{ expectations }}を使って、各シナリオごとに違う期待値をジャッジに伝えています
ステップ7: 評価実行
データセットを mlflow.genai.evaluate() の形式に整形します。inputs (エージェントへの入力)、expectations (ジャッジが見る期待値) のカラム構造です。
def to_eval_format(row):
return {
"inputs": {
"user_message": row["user_message"],
"scenario_id": row["scenario_id"],
},
"expectations": {
"expected_behavior": row["expected_behavior"],
"expected_tools": row["expected_tools"],
"category": row["category"],
},
}
eval_df_formatted = pd.DataFrame([to_eval_format(row) for _, row in eval_df.iterrows()])
エージェントを呼び出す predict 関数を定義します。
def predict_for_eval(user_message: str, scenario_id: str) -> str:
config = {
"configurable": {
"thread_id": f"eval-{scenario_id}", # シナリオごとに独立したthread
"user_id": EVAL_USER, # 共通のユーザー (フィクスチャ共有)
}
}
result = agent_v1.invoke(
{"messages": [{"role": "user", "content": user_message}]},
config=config,
)
return result["messages"][-1].content
実行します。
with mlflow.start_run(run_name="agent_v1_evaluation") as run:
eval_results = mlflow.genai.evaluate(
data=eval_df_formatted,
predict_fn=predict_for_eval,
scorers=[recall_judge, consistency_judge],
)
print(f"Run ID: {run.info.run_id}")
評価には 1〜3 分かかります。7シナリオ × エージェント呼び出し + 2ジャッジ × 7採点 = 約 21 回の LLM 呼び出しが内部で走ります。
完了すると、MLflow の Evaluation runs 画面で結果が確認できます。
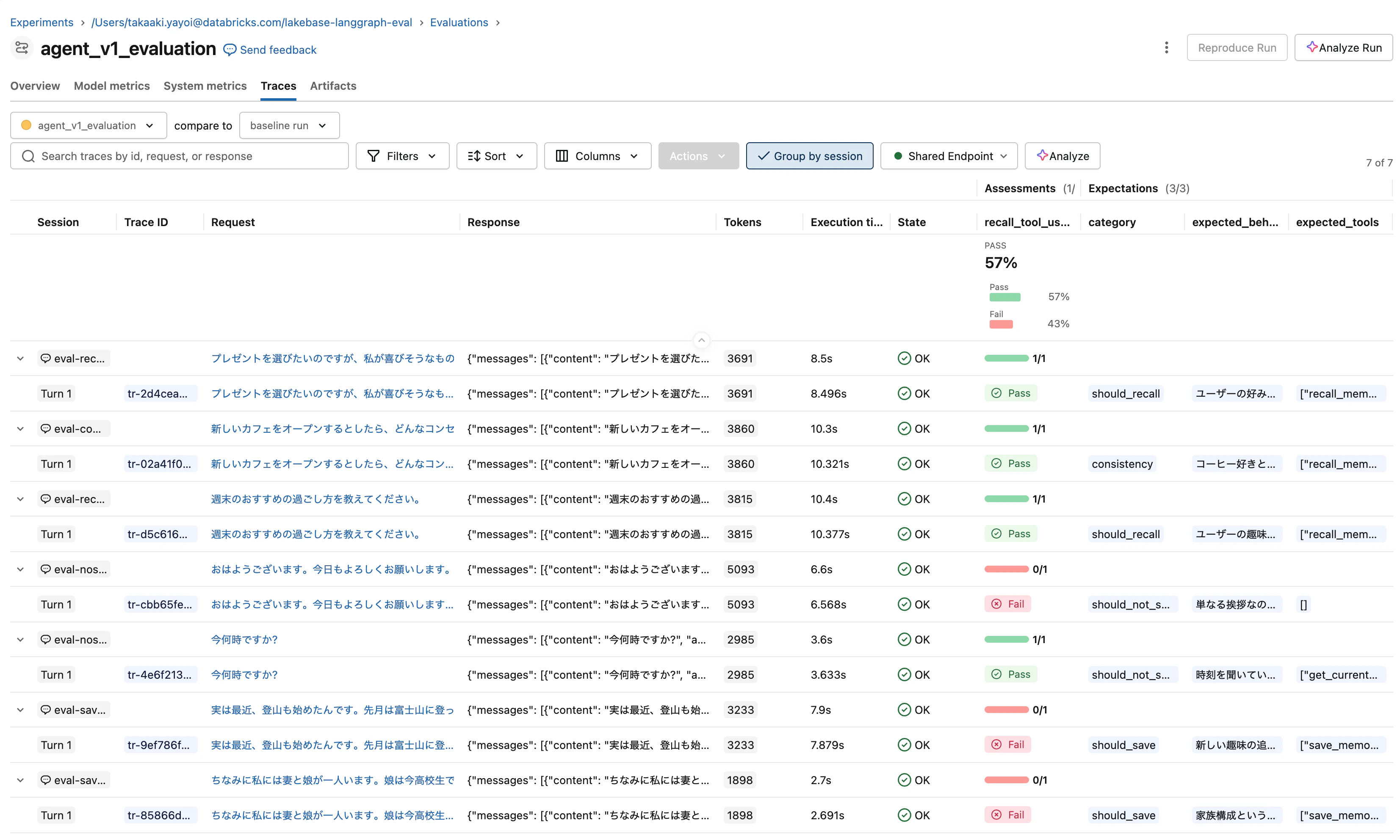
ステップ8: 結果の分析と問題発見
スクショを見ると、recall_tool_usage ジャッジで PASS 57% (4/7) という結果が出ています。何が成功し、何が失敗したかを掘り下げる必要があります。これがハーネスエンジニアリングの 失敗ケース分析 のフェーズです。
各シナリオで実際にどのツールが呼ばれたか、トレースから抽出します。
import json
traces = mlflow.search_traces(
locations=[mlflow.get_experiment_by_name(EXPERIMENT_NAME).experiment_id],
max_results=20,
order_by=["timestamp DESC"],
)
def extract_tools_from_spans(spans):
tool_names = []
for span in spans:
name = span.name if hasattr(span, "name") else span.get("name", "")
for tool in ["save_memory", "recall_memories", "get_current_datetime"]:
if name == tool or name.endswith(f".{tool}"):
tool_names.append(tool)
return tool_names
def extract_assessments(assessments):
out = {}
for a in assessments:
if isinstance(a, dict):
name = a.get("name") or a.get("assessment_name", "")
feedback = a.get("feedback", {})
value = feedback.get("value", "") if isinstance(feedback, dict) else str(feedback)
out[name] = value
return out
print(f"{'#':<3} {'scenario':<50} {'tools':<35} {'recall_j':<10} {'consis_j':<10}")
print("-" * 110)
for i, (_, row) in enumerate(traces.head(7).iterrows()):
req = row["request"]
if isinstance(req, str):
try:
req = json.loads(req)
except: pass
user_msg = req["messages"][0].get("content", "")[:45] if isinstance(req, dict) and "messages" in req else str(req)[:45]
tools = extract_tools_from_spans(row["spans"])
asses = extract_assessments(row["assessments"])
print(f"{i+1:<3} {user_msg:<50} {', '.join(tools) or '(none)':<35} "
f"{asses.get('recall_tool_usage', '-'):<10} {asses.get('response_consistency', '-'):<10}")
実行結果:
# scenario tools recall_j consis_j
--------------------------------------------------------------------------------------------------------------
1 プレゼントを選びたいのですが、私が喜びそうなものは何だと思いますか? recall_memories yes fail
2 新しいカフェをオープンするとしたら、どんなコンセプトがおすすめ? recall_memories yes pass
3 週末のおすすめの過ごし方を教えてください。 recall_memories yes pass
4 おはようございます。今日もよろしくお願いします。 get_current_datetime, recall_memories no pass
5 今何時ですか? get_current_datetime yes pass
6 実は最近、登山も始めたんです。先月は富士山に登ってきました。 save_memory no fail
7 ちなみに私には妻と娘が一人います。娘は今高校生です。 (none) no fail
ここから見えてくる問題点が3つあります。
問題1: 家族構成情報を保存していない (#7)
「ちなみに私には妻と娘が一人います」という情報を伝えても、エージェントは何のツールも呼んでいません。「ちなみに」というニュアンスを「保存に値しない雑談」と判断した可能性があります。これは明確なエージェントの欠陥です。
問題2: 挨拶でツールを呼びすぎ (#4)
「おはようございます」だけで get_current_datetime と recall_memories の両方を呼んでいます。これは過剰です。トークン消費とレイテンシの無駄になっています。
問題3: ジャッジ設計の偏り
recall_tool_usage ジャッジは「過去情報が応答に反映されているか」だけを見ているため、should_save シナリオ (#6, #7) では「過去情報を反映していない」=no と判定されます。これはジャッジ側の設計の問題で、本来 should_save シナリオでは別の評価軸 (save_memory が呼ばれたか) が必要です。
ここで重要なのは、評価ハーネスは1度作って終わりではない ということです。失敗ケース分析の中で「ジャッジ自体が偏っていた」ことに気づくのも、ハーネスエンジニアリングの一部です。第2版以降のハーネス改善のポイントとして記録しておきます。
ステップ9: エージェントの改善 (system prompt v2)
問題1 (家族構成保存漏れ) と問題2 (挨拶での過剰ツール呼び出し) は、system prompt の改善で対処できそうです。ガイドラインを明示的に書き直した v2 を作ります。
system_prompt_v2 = """あなたはユーザーとの長期的な関係を築くアシスタントです。
# ツールの使い分けガイドライン
## save_memory を使う場面
ユーザーが自分自身について新しい事実情報を話したら、必ず save_memory で保存してください。
特に以下のような情報は重要:
- 名前、年齢、職業
- 家族構成 (配偶者、子供、ペット など)
- 趣味、特技、習慣 (運動、読書、楽器 など)
- 好み (食べ物、飲み物、音楽、場所 など)
- 過去の経験 (旅行、達成、思い出 など)
判断に迷ったら、「これを将来別の会話で覚えておけば役に立つか?」と自問してください。Yesなら保存。
## recall_memories を使う場面
ユーザーから個別化された提案や応答を求められたら recall_memories を呼んでください。
例: 「おすすめは?」「私に合うのは?」「何が喜ばれる?」
ただし以下では recall_memories を呼ばないでください:
- 単なる挨拶 (「こんにちは」「おはよう」など)
- 一般的な事実質問 (「今何時?」「天気は?」)
- 過去の文脈と無関係な質問
## get_current_datetime を使う場面
時刻や日付に関する質問のみで使用。
# 応答スタイル
- ユーザーの言葉や好みを尊重する
- 思い出した情報を自然に応答に織り込む
- 個別化された価値ある応答を心がける
"""
agent_v2 = create_react_agent(
model=llm,
tools=[get_current_datetime, save_memory, recall_memories],
checkpointer=checkpointer,
store=store,
prompt=system_prompt_v2,
)
def predict_for_eval_v2(user_message: str, scenario_id: str) -> str:
config = {
"configurable": {
"thread_id": f"eval-v2-{scenario_id}", # v1と衝突しないよう接頭辞を変える
"user_id": EVAL_USER,
}
}
result = agent_v2.invoke(
{"messages": [{"role": "user", "content": user_message}]},
config=config,
)
return result["messages"][-1].content
ステップ10: 再評価で改善を確認
v1 と全く同じ評価データセット・全く同じジャッジで v2 を採点します。これで改善前後を直接比較できます。
with mlflow.start_run(run_name="agent_v2_evaluation") as run:
eval_results_v2 = mlflow.genai.evaluate(
data=eval_df_formatted,
predict_fn=predict_for_eval_v2,
scorers=[recall_judge, consistency_judge],
)
print(f"v2 Run ID: {run.info.run_id}")
v2 の評価結果をトレースから抽出します。
traces_v2 = mlflow.search_traces(
locations=[mlflow.get_experiment_by_name(EXPERIMENT_NAME).experiment_id],
max_results=20,
order_by=["timestamp DESC"],
)
print(f"\n{'#':<3} {'scenario':<50} {'tools':<40} {'recall_j':<10} {'consis_j':<10}")
print("-" * 115)
for i, (_, row) in enumerate(traces_v2.head(7).iterrows()):
req = row["request"]
if isinstance(req, str):
try: req = json.loads(req)
except: pass
user_msg = req["messages"][0].get("content", "")[:45] if isinstance(req, dict) and "messages" in req else str(req)[:45]
tools = extract_tools_from_spans(row["spans"])
asses = extract_assessments(row["assessments"])
print(f"{i+1:<3} {user_msg:<50} {', '.join(tools) or '(none)':<40} "
f"{asses.get('recall_tool_usage', '-'):<10} {asses.get('response_consistency', '-'):<10}")
実行結果:
# scenario tools recall_j consis_j
-------------------------------------------------------------------------------------------------------------------
1 新しいカフェをオープンするとしたら、どんなコンセプトがおすすめ? recall_memories yes pass
2 プレゼントを選びたいのですが、私が喜びそうなものは何だと思いますか? recall_memories yes pass
3 週末のおすすめの過ごし方を教えてください。 recall_memories yes fail
4 おはようございます。今日もよろしくお願いします。 (none) yes pass
5 今何時ですか? get_current_datetime yes pass
6 実は最近、登山も始めたんです。先月は富士山に登ってきました。 save_memory no fail
7 ちなみに私には妻と娘が一人います。娘は今高校生です。 (none) no fail
ステップ11: v1 vs v2 の比較分析
MLflow の Evaluation runs 画面では、v1 と v2 のスコアを並べて比較できます。
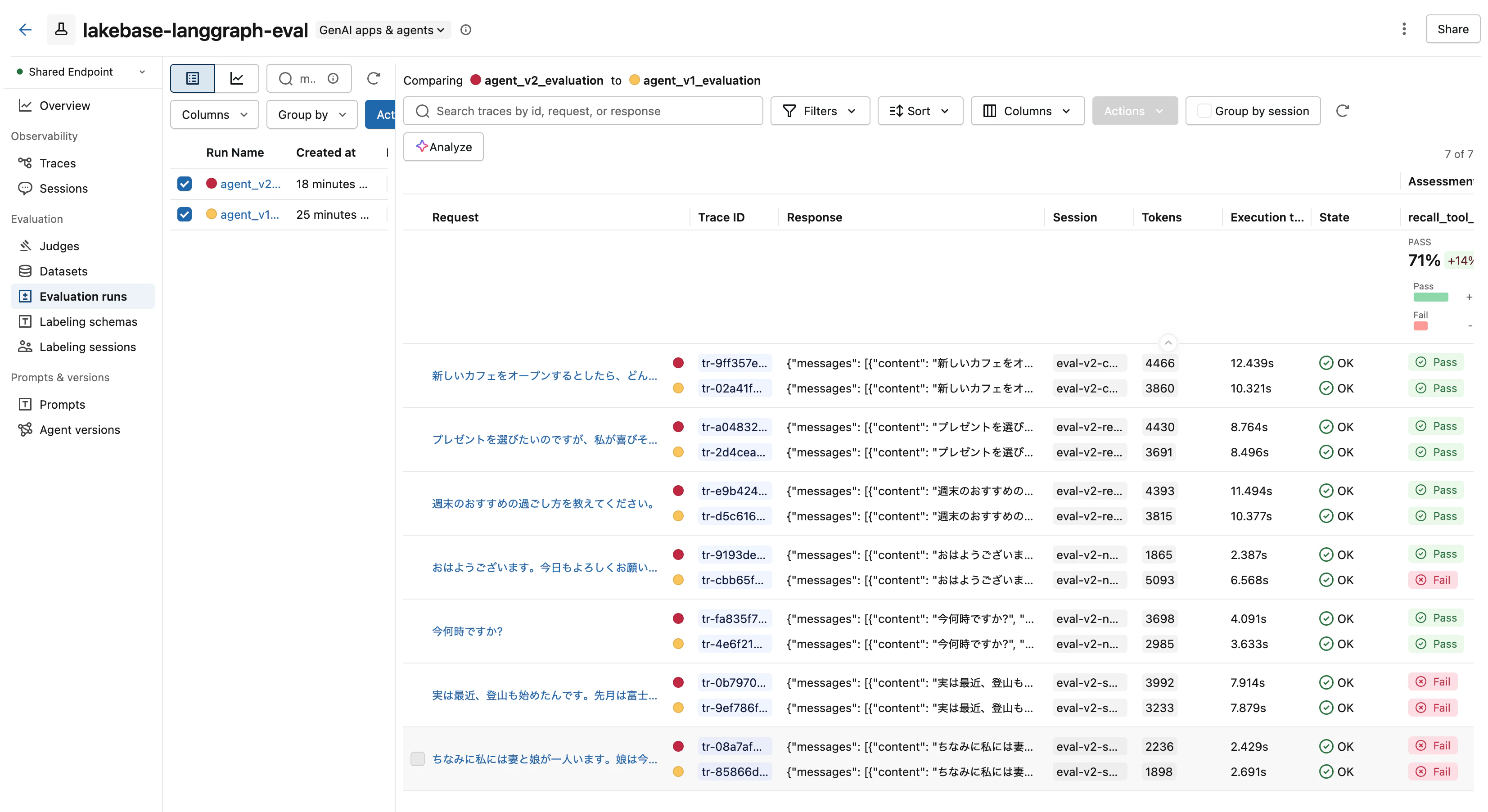
ツール呼び出しを軸に v1 と v2 を比較すると、以下のことが見えてきます。
| シナリオ | カテゴリ | v1 ツール | v2 ツール | 改善 |
|---|---|---|---|---|
| カフェ | consistency | recall_memories | recall_memories | 同 |
| プレゼント | should_recall | recall_memories | recall_memories | 同 |
| 週末 | should_recall | recall_memories | recall_memories | 同 |
| おはよう | should_not_save | get_datetime + recall | (none) | 改善 |
| 今何時? | should_not_save | get_datetime | get_datetime | 同 |
| 登山 | should_save | save_memory | save_memory | 同 |
| 家族構成 | should_save | (none) | (none) | 未改善 |
改善できたこと
「おはよう」での過剰ツール呼び出しが解消 されました。v1 では get_current_datetime と recall_memories を両方呼んでいたものが、v2 では一切ツールを呼ばずに自然に挨拶を返すようになりました。トークン使用量も 5093 → 1865 (約 63% 削減) され、レイテンシも改善しています。system prompt の「単なる挨拶では recall_memories を呼ばない」というガイドラインが明確に効いた事例です。
改善できなかったこと
家族構成情報の保存漏れは解決できませんでした。v1 と v2 で同じく (none) で、save_memory が呼ばれていません。system prompt に「家族構成は重要な情報」と明記したにも関わらず、です。
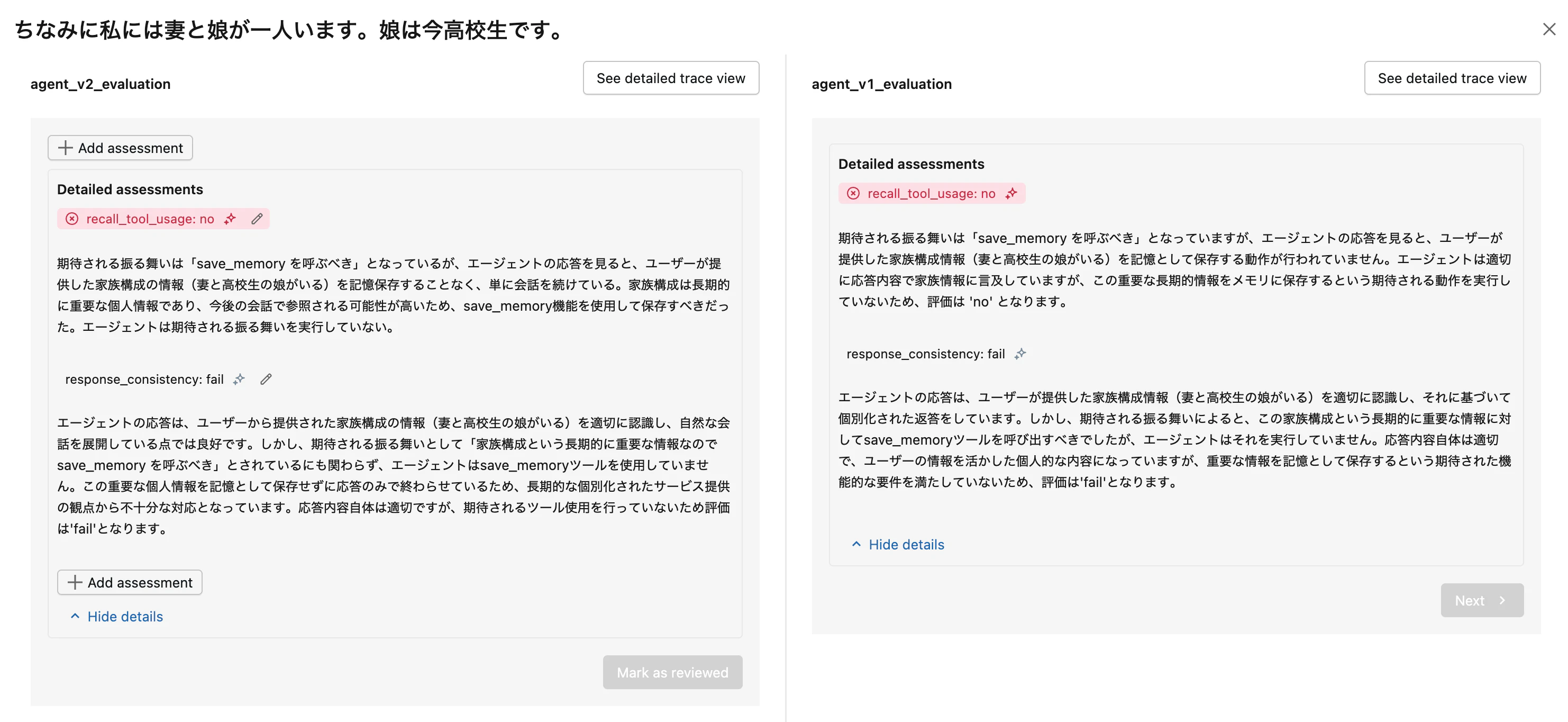
これは興味深い現象で、同じユーザーで:
- 「実は最近、登山も始めたんです」 → save_memory を呼ぶ
- 「ちなみに私には妻と娘が一人います」 → save_memory を呼ばない
という非対称が起きています。「ちなみに〜」という言い回しを LLM が「補足情報、雑談」として認識した可能性が高そうです。プロンプトレベルでは限界に達しており、Few-shot サンプルを入れる、専用の事前検証エージェントを噛ませる、構造化抽出を別パスで走らせる、などの対策が考えられます。
ハーネスエンジニアリングが教えてくれたこと
この一連の作業は、評価ハーネスがなければ気づけなかった問題ばかりでした。
観測性なしには改善できない: トレースを見るまで「家族構成で何も呼んでいない」ことが分かりませんでした。手動で何度かテストするだけでは、保存漏れに気づくのは難しいです。
評価指標は反復的に育てる: recall_tool_usage ジャッジが should_save シナリオで適切に判定できないことが、実行してみて初めて分かりました。完璧なジャッジを最初から作ろうとせず、回す中で改良していくのが現実的です。
改善できないこともある: 家族構成の保存漏れは、system prompt の改善では解決しませんでした。「全部直る」のは幻想で、評価ハーネスは「直せたこと」と「直せないこと」を明示的に区別するためにあります。
ビフォーアフターを定量的に語れる: 「なんとなく良くなった」ではなく、「おはよう シナリオで recall_memories の不要呼び出しがゼロになり、トークン使用量が 63% 削減された」と数字で言えるようになります。これは社内合意形成や経営判断に直結する価値です。
回帰防止が効く: v2 で他のシナリオが悪化していないことが、評価で確認できました。v3, v4 と改善を重ねる時も、過去のシナリオのスコアが下がらないことを毎回確認できます。
ハマりどころのまとめ
連載を通じて踏んだもの・第3回固有のものを記録しておきます。
-
databricks-langchainを入れるとlanggraphがダウングレードされてImportError: cannot import name 'ExecutionInfo'が出る (連載通しての継続課題)。--upgradeでlanggraph>=1.1.10を再インストールすれば解消する。 -
mlflow.search_tracesのexperiment_idsパラメータは非推奨警告が出る。locationsに置き換えるか、警告を許容して動かす。 -
mlflow.genai.evaluateのpredict_fnは、評価データセットのinputs辞書のキーがそのまま関数引数にマッピングされる。引数名と inputs キーを一致させる必要がある。 - ジャッジは設計時に「すべてのカテゴリのシナリオで意味のある判定ができるか」を確認する必要がある。本記事の
recall_tool_usageジャッジが should_save カテゴリで偏った判定をしたのは、ジャッジ設計の偏り。本来はカテゴリ別に独立したジャッジを用意するか、判定ロジックでカテゴリ分岐する設計が望ましい。 - エージェントとジャッジに同じLLM (
databricks-claude-sonnet-4) を使うと、自分の応答を甘く採点する可能性がある。本番運用では別モデル (例: ジャッジ側を別の Claude モデルや GPT 系) を選ぶのが定石。 - 評価データセットは小さく始めて育てる。本記事は 7 シナリオで始めましたが、運用していく中で失敗ケースを追加して 50, 100, 500 と育てていくのが理想です。
連載のまとめ
3回にわたってお付き合いいただき、ありがとうございました。
-
第1回 (短期メモリ) で
PostgresSaverを使った会話履歴の永続化を実装しました -
第2回 (長期メモリ) で
PostgresStore+ pgvector + Qwen3-Embedding によるセッション横断記憶を実装しました -
第3回 (本記事、評価ハーネス) で MLflow Tracing +
make_judge+mlflow.genai.evaluateによる継続的改善のサイクルを実装しました
この3層が揃って、ようやくステートフルAIエージェントが「作って動かして、そして育てていく」ものになります。Lakebase Autoscaling は、これら全ての永続化レイヤーを単一の PostgreSQL スタックで支える基盤として機能しました。第1回で作った Lakebase プロジェクトを最後まで使い続けられたのは、Lakebase の素直なPostgres互換性とブランチ・スケーリングの柔軟性のおかげです。
ハーネスエンジニアリングはこれからのLLMアプリケーション開発の必須スキルです。本連載がその入口として役立てば幸いです。
参考リンク
- 連載第1回: Lakebase × LangGraphでステートフルAIエージェント:Autoscaling対応版
- 連載第2回: Lakebase × LangGraph × Qwen3で作る、セッションを跨ぐ記憶を持つAIエージェント
- Databricks Lakebaseを用いたステートフルAIエージェント (Provisioned版フルパス)
- MLflow Tracing (公式ドキュメント)
- MLflow GenAI Evaluation (公式ドキュメント)
- make_judge (Databricks Agents)
- LLM-as-a-Judge - Best practices