はじめに
Databricks Lakebase は AI エージェントの永続メモリのバックエンドとして非常に相性が良い、サーバレスのマネージドな PostgreSQL です。LLM はステートレスなので、エージェントが「前回の会話を覚えている」「ユーザーの好みを学習する」といった振る舞いをするには、外部に状態を保存する仕組みが必要になります。
以前 Databricks Lakebaseを用いたステートフルAIエージェント で、Lakebase Provisioned + LangGraph で ResponsesAgent ラップ + Unity Catalog 登録 + Agent Evaluation までフルパスで書きました。本記事はその後継として、 Lakebase Autoscaling 対応の最小構成版 を書きます。
2026年3月以降、新規 Lakebase はデフォルトが「Autoscaling」になり、SDK API も w.database.*(Provisioned 系)から w.postgres.*(Autoscaling 系)へと変わりました。プロジェクト構造もインスタンス1階層から プロジェクト → ブランチ → エンドポイント の3階層に変わったため、過去記事と同じコードがそのままでは動きません。
本記事は連載の第1回です。
- 第1回 (本記事): 短期メモリ(セッション内の会話履歴)、最小構成
- 第2回: 長期メモリ(セッションを跨ぐユーザー単位の知識)への拡張
- 第3回: 評価ハーネス層(MLflow Tracing → 評価データセット自動生成 → カスタムジャッジ → 継続的改善ループ)
ResponsesAgent ラップや UC 登録、デプロイまでの一気通貫は過去記事を参照してください。本記事ではノートブックでローカル動作確認するところまでに絞り、Autoscaling 環境の差分にフォーカスします。
Lakebase Autoscaling とは
Lakebase Autoscaling は Lakebase の最新世代で、従来の Provisioned に比べて以下の4つの大きな特徴があります。
Autoscaling Compute: ワークロードに応じてコンピュートが自動でスケールアップ/ダウンします。事前に容量を見積もる必要がなく、CU(Compute Unit)の最小値と最大値を指定するだけで、その範囲内で自動調整されます。Provisioned 時代の「ピーク時に合わせて常時オーバープロビジョニングする」コスト構造が解消されます。
Scale to Zero: 一定時間アイドル状態が続くとコンピュートが完全に停止し、コストがゼロになります。再アクセス時に数秒で復帰します。開発用ブランチや時間帯依存のアプリでは7割以上のコスト削減が見込めるとされています。なお、新規プロジェクトはデフォルトでは無効化されており、明示的に有効化する必要があります。
Branching: Git のブランチに似た仕組みで、データベースをコピーオンライト方式で瞬時に分岐させられます。本番データを使った安全なテスト環境、CI/CD パイプライン用の隔離環境、過去の任意の時点からの復旧など、開発体験が大きく変わります。
Instant Restore: リストアウィンドウ(0〜30日)内であれば、任意の時点に瞬時にリストアできます。
これらの特徴に加えて、リソース構造も Provisioned と異なります。Provisioned は「インスタンス」1階層でしたが、Autoscaling では プロジェクト → ブランチ → エンドポイント の3階層構造になります。1つのプロジェクトに複数のブランチが作れ、各ブランチに1つ以上のエンドポイント(R/W や read replica)が紐付きます。
| 観点 | Provisioned | Autoscaling |
|---|---|---|
| 構造 | インスタンス1階層 | プロジェクト → ブランチ → エンドポイントの3階層 |
| CU あたりの RAM | 約16 GB | 2 GB(細粒度なスケーリング) |
| 上限 CU | (固定) | 32 CU まで(min/max 差 ≤ 16 CU) |
| Scale to Zero | なし | あり |
| ブランチング | なし | あり |
| インスタント復元 | なし(バックアップ復元のみ) | あり(0〜30日) |
| SDK API | w.database.* |
w.postgres.* |
| Apps 連携 | 可 | 不可(現時点) |
新規 Lakebase プロジェクトは2026年3月12日以降、すべて Autoscaling として作成されるようになりました。既存の Provisioned インスタンスはそのまま継続利用でき、API も並行サポートされています。
AI エージェントのメモリストアという用途とは特に相性が良く、リクエストパターンが変動しがち、開発・検証用にブランチで隔離環境を作りたい、開発が一段落したらコストを下げたい、といった要件にきれいにフィットします。
構築するもの
会話の文脈を保持する短期メモリ付きのエージェントを作ります。
- LangGraph の
create_react_agentでエージェントを組み立てる - Foundation Model API の Claude Sonnet 4 を LLM として利用
- 簡単なツール(現在時刻を返す)を1つ持たせる
- LangGraph の
PostgresSaver(Checkpointer)を使って、会話状態を Lakebase に永続化 - 同一スレッドでは会話の文脈を保持し、別スレッドでは引き継がないことを確認
完成形のアーキテクチャはこのような形です。
[ユーザー]
↓
[LangGraph Agent (create_react_agent)]
├─ ChatDatabricks (Foundation Model API)
├─ Tools
└─ PostgresSaver (Checkpointer)
↓
[Lakebase Autoscaling]
thread_id 単位で会話のスナップショットを保存
前提と動作確認バージョン
- 有償版の Databricks ワークスペース (us-west-2 で確認、他リージョンでもOK)
- サーバレスコンピュート上のノートブック
- Foundation Model API へのアクセス
- Lakebase Autoscaling Project が利用可能
なお Free Edition のサーバレスコンピュートでは、本記事執筆時点で psycopg3 binary の動的ロードが不安定な状態を確認しています。Free Edition で進める場合はノートブック側の安定性に要注意です(別記事で改めて扱うかもしれません)。
動作確認時のバージョンは以下です。
psycopg: 3.3.3
psycopg-binary: 3.3.3
psycopg-pool: 3.3.0
langgraph: 1.1.10
langgraph-checkpoint: 4.0.3
langgraph-checkpoint-postgres: 3.0.5
databricks-sdk: 0.105.0
databricks-langchain: 0.19.0
PostgreSQL: 17.8 (Lakebase 側)
ステップ1: Lakebase Autoscalingプロジェクトの作成
ワークスペース左上の App Switcher から Lakebase Postgres を開きます。
サイドバー左の Autoscaling タブを選択した状態で + New project をクリックします。
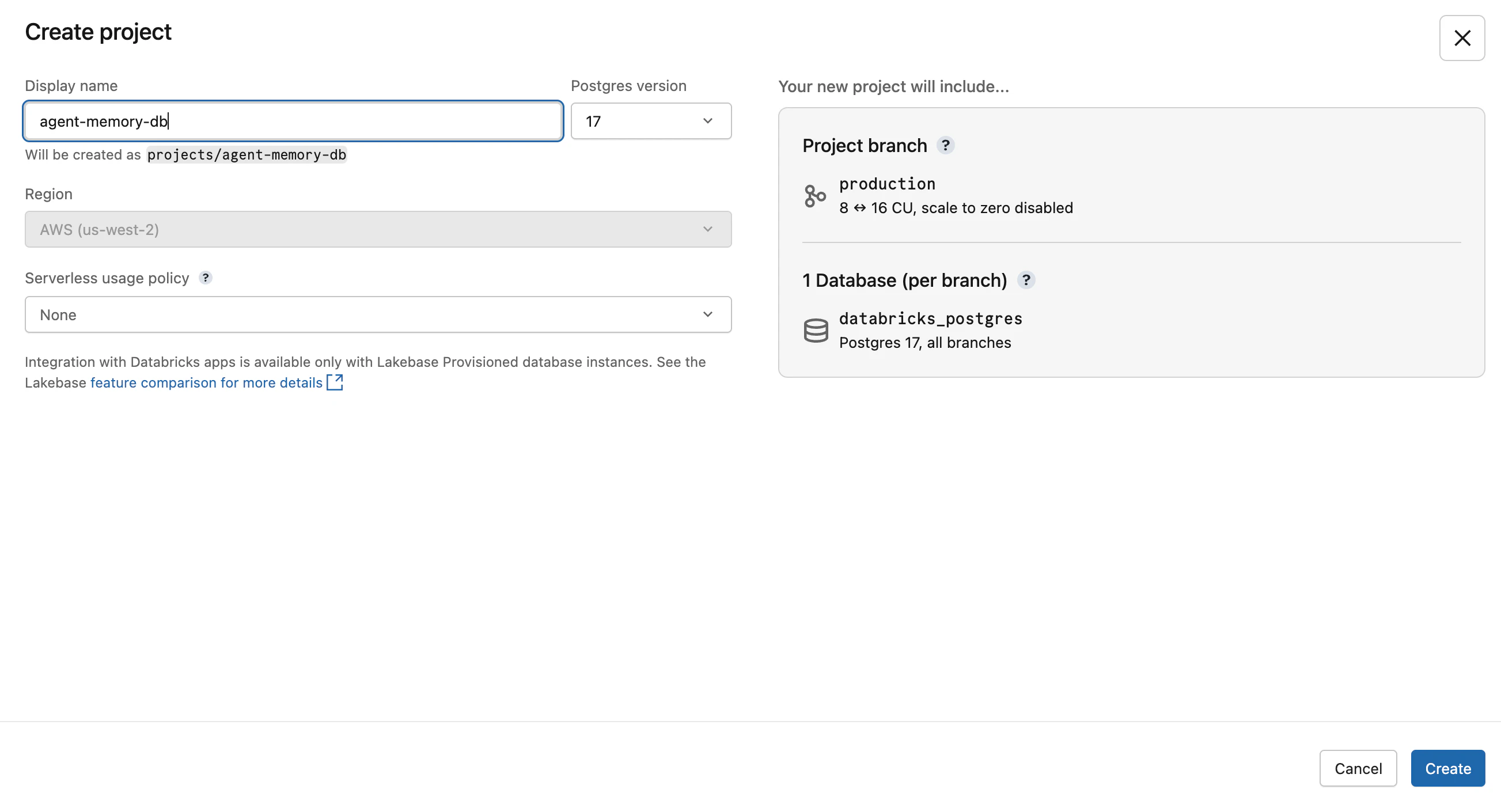
ダイアログで以下を入力します。
- Display name:
agent-memory-db(お好みで) - Postgres version:
17(デフォルト) - Region: ワークスペースのリージョンが固定で表示される
- Serverless usage policy:
None(デフォルト)
Create をクリックすると、数十秒で production ブランチと primary という R/W エンドポイントが自動生成されます。これが Lakebase Autoscaling の3階層構造(プロジェクト → ブランチ → エンドポイント)の最小構成です。
作成が完了すると Project dashboard に遷移します。右上の Connect ボタンをクリックすると接続文字列のサンプルや psql 用のスニペットが取れますが、本記事ではノートブックから SDK 経由でプログラマティックに接続するため、ここでは中身を確認するだけでOKです。
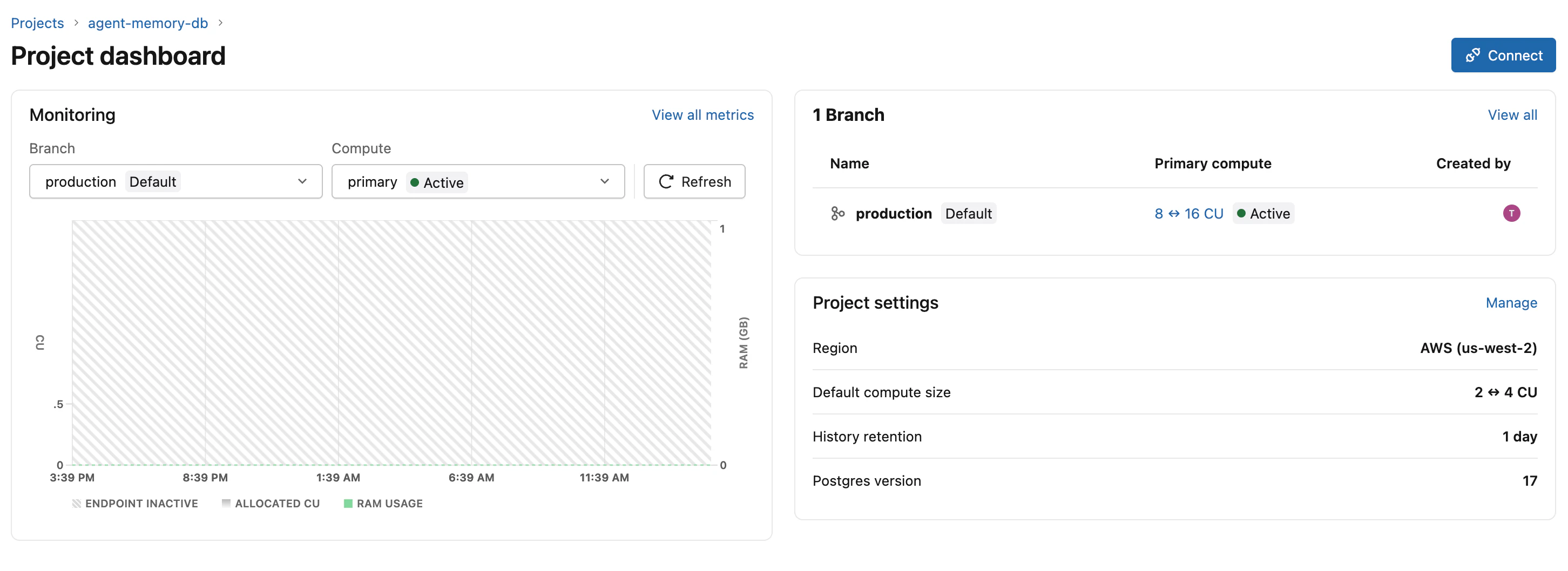
ちなみに、ダイアログ内に「Integration with Databricks apps is available only with Lakebase Provisioned database instances」という注記があります。Autoscaling は現時点で Databricks Apps のリソースとして紐付けることはできません(将来対応予定とのこと)。Apps 連携が必須の場合は Provisioned を選んでください。本記事はノートブック前提なので Autoscaling のままでOKです。
ステップ2: ノートブックでパッケージを準備
新規ノートブックを作成し、サーバレスコンピュートにアタッチします。
%pip install "psycopg[binary,pool]" databricks-sdk
%restart_python
%restart_python で Python カーネルが再起動するので、これ以降のセル実行で確実に新しいパッケージが反映されます。
インストール後の状態を確認します。
import psycopg
import databricks.sdk
print(f"psycopg: {psycopg.__version__}")
print(f"psycopg impl: {psycopg.pq.__impl__}")
print(f"libpq: {psycopg.pq.version()}")
print(f"databricks-sdk: {databricks.sdk.version.__version__}")
期待される出力例:
psycopg: 3.3.3
psycopg impl: binary
libpq: 180000
databricks-sdk: 0.105.0
psycopg impl: binary が出ていれば、libpq がバンドルされたバイナリホイール版が使われており、システムライブラリ依存が解消されています。
ステップ3: Lakebaseに接続
Lakebase Autoscaling では、認証は OAuth ベースで Databricks アイデンティティを使います。SDK の w.postgres.generate_database_credential() で短期トークン(60分有効)を発行し、それを Postgres の password として使います。
まずプロジェクトのリソース情報を SDK で確認します。
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
PROJECT_ID = "agent-memory-db"
print("=== Branches ===")
for br in w.postgres.list_branches(parent=f"projects/{PROJECT_ID}"):
print(br.as_dict())
print("\n=== Endpoints ===")
for br in w.postgres.list_branches(parent=f"projects/{PROJECT_ID}"):
branch_id = br.name.split("/")[-1]
for ep in w.postgres.list_endpoints(
parent=f"projects/{PROJECT_ID}/branches/{branch_id}"
):
print(ep.as_dict())
=== Branches ===
{'create_time': '2026-04-28T06:39:25Z', 'name': 'projects/agent-memory-db/branches/production', 'parent': 'projects/agent-memory-db', 'status': {'branch_id': 'production', 'current_state': 'READY', 'default': True, 'is_protected': False, 'logical_size_bytes': 0, 'state_change_time': '2026-04-28T06:39:27Z'}, 'uid': 'br-broad-bird-d1tyno0e', 'update_time': '2026-04-28T06:39:31Z'}
----------------------------------------
=== Endpoints ===
{'create_time': '2026-04-28T06:39:25Z', 'name': 'projects/agent-memory-db/branches/production/endpoints/primary', 'parent': 'projects/agent-memory-db/branches/production', 'status': {'autoscaling_limit_max_cu': 16.0, 'autoscaling_limit_min_cu': 8.0, 'current_state': 'ACTIVE', 'disabled': False, 'endpoint_id': 'primary', 'endpoint_type': 'ENDPOINT_TYPE_READ_WRITE', 'group': {'enable_readable_secondaries': False, 'max': 1, 'min': 1}, 'hosts': {'host': 'ep-nameless-heart-d1hjayp3.database.us-west-2.cloud.databricks.com'}, 'settings': {}}, 'uid': 'ep-nameless-heart-d1hjayp3', 'update_time': '2026-04-28T06:39:31Z'}
----------------------------------------
出力からは以下のような構造が見えます。
- Branch:
production(デフォルト名) - Endpoint:
primary(R/W エンドポイントのデフォルト名) - Endpoint host:
endpoint.status.hosts.hostの中(例:ep-xxxxx-xxxxxxxx.database.us-west-2.cloud.databricks.com)
これらを変数として保持して、接続テストを実行します。
import concurrent.futures
import psycopg
PROJECT_ID = "agent-memory-db"
BRANCH_ID = "production"
ENDPOINT_ID = "primary"
HOST = "<上で確認したendpoint host>"
cred = w.postgres.generate_database_credential(
endpoint=f"projects/{PROJECT_ID}/branches/{BRANCH_ID}/endpoints/{ENDPOINT_ID}"
)
USER = w.current_user.me().user_name
def try_connect():
conn = psycopg.connect(
host=HOST, port=5432, dbname="databricks_postgres",
user=USER, password=cred.token,
sslmode="require", connect_timeout=10,
)
with conn.cursor() as cur:
cur.execute("SELECT current_user, version();")
result = cur.fetchone()
conn.close()
return result
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as ex:
fut = ex.submit(try_connect)
try:
print("OK:", fut.result(timeout=20))
except Exception as e:
print(f"NG: {type(e).__name__}: {e}")
ThreadPoolExecutor で別スレッドに接続を投げているのは、認証段階のハングでカーネルが固まらないように予防線を張っているためです。20秒で必ず例外として戻ってくるので、ハマっても安全に切り分けできます。
期待される出力:
OK: ('your.email@databricks.com', 'PostgreSQL 17.8 (130b160) on x86_64-pc-linux-gnu, ...')
PostgreSQL 17.8 が見えれば疎通成功です。
なお、自分のメールアドレスに対応する Postgres ロール (OAuth ロール) は、プロジェクト作成時に自動作成されています。明示的に作る必要はありません。
ステップ4: PostgresSaverのセットアップ
LangGraph 関連パッケージをインストールします。
%pip install langgraph langgraph-checkpoint-postgres
%restart_python
ここで重要な注意点として、-U (--upgrade) は付けません。すでに動作確認済みの psycopg==3.3.3 を、依存解決で動かさないようにするためです。
%restart_python で Python 環境がリセットされるので、WorkspaceClient、cred、その他の変数を再定義する必要があります。
import concurrent.futures
from databricks.sdk import WorkspaceClient
from psycopg_pool import ConnectionPool
from langgraph.checkpoint.postgres import PostgresSaver
w = WorkspaceClient()
PROJECT_ID = "agent-memory-db"
BRANCH_ID = "production"
ENDPOINT_ID = "primary"
HOST = "<your endpoint host>"
cred = w.postgres.generate_database_credential(
endpoint=f"projects/{PROJECT_ID}/branches/{BRANCH_ID}/endpoints/{ENDPOINT_ID}"
)
USER = w.current_user.me().user_name
conninfo = (
f"dbname=databricks_postgres user={USER} password={cred.token} "
f"host={HOST} port=5432 sslmode=require"
)
def setup_pool_and_saver():
pool = ConnectionPool(
conninfo=conninfo,
max_size=5,
kwargs={"autocommit": True, "prepare_threshold": 0},
open=True,
)
checkpointer = PostgresSaver(pool)
checkpointer.setup()
return pool, checkpointer
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as ex:
pool, checkpointer = ex.submit(setup_pool_and_saver).result(timeout=60)
print("PostgresSaver setup OK")
checkpointer.setup() は内部で以下のテーブルを Lakebase 側に作成します。
-
checkpoints: 各 thread_id ごとの会話状態のスナップショット -
checkpoint_blobs: 大きなオブジェクト用 -
checkpoint_writes: ライト操作のログ -
checkpoint_migrations: スキーマバージョン管理
初回のみ実行が必要で、2回目以降は冪等にスキップされます。
実際にテーブルが作られたか SQL で確認します。
def list_tables():
with pool.connection() as conn:
with conn.cursor() as cur:
cur.execute("""
SELECT tablename FROM pg_tables
WHERE schemaname = 'public'
ORDER BY tablename;
""")
return cur.fetchall()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as ex:
tables = ex.submit(list_tables).result(timeout=15)
print("Tables in public schema:")
for t in tables:
print(f" - {t[0]}")
出力:
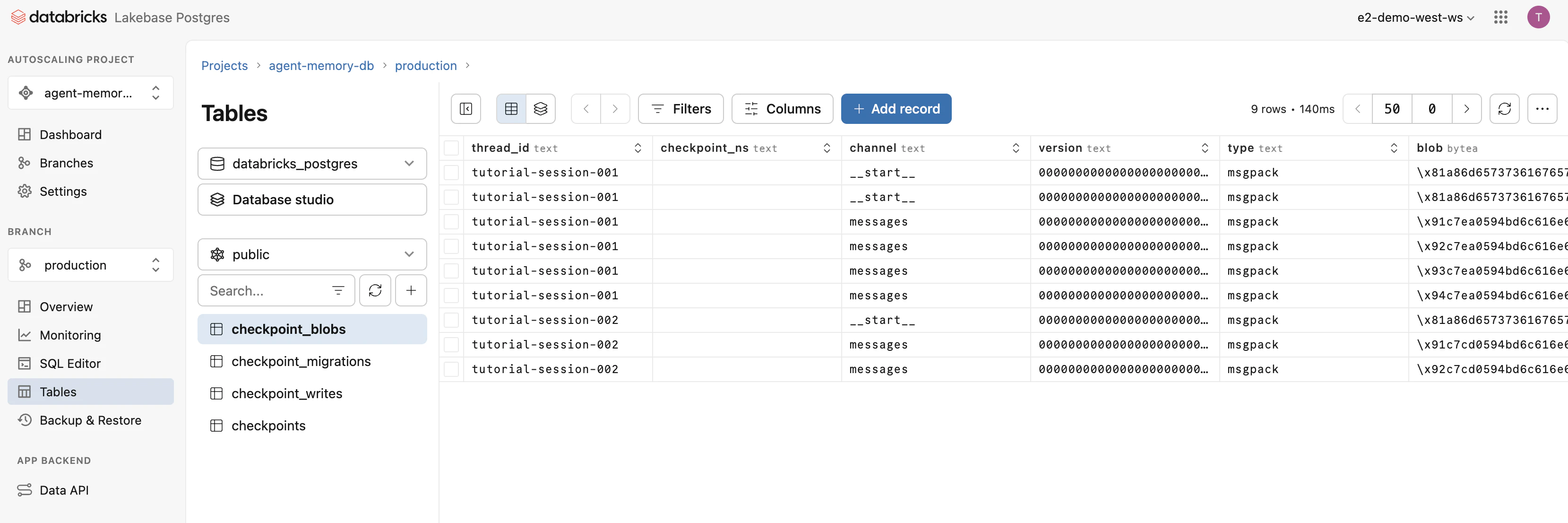
Tables in public schema:
- checkpoint_blobs
- checkpoint_migrations
- checkpoint_writes
- checkpoints
LakebaseのGUIでも確認できます。
ステップ5: 短期メモリ付きエージェントを組み立てる
エージェント側のパッケージを追加します。
%pip install databricks-langchain
%restart_python
ここでハマりどころが1つあります。databricks-langchain を入れると依存解決で langgraph がダウングレードされ、後続の import で ImportError: cannot import name 'ExecutionInfo' from 'langgraph.runtime' というエラーが出ることがあります。これは databricks-langchain==0.19.0 のコードが langgraph 1.1.x の機能を使っているのに、依存解決が langgraph 1.0.x を引き寄せてしまうために起きます。
その場合は langgraph を再アップグレードします。
%pip install --upgrade "langgraph>=1.1.10" "langgraph-checkpoint-postgres"
%restart_python
import が通ることを確認しておきます。
from langgraph.runtime import ExecutionInfo
from databricks_langchain import ChatDatabricks
from langgraph.prebuilt import create_react_agent
print("All imports OK")
%restart_python で再びカーネルがリセットされたので、pool と checkpointer を再構築する必要があります。
import concurrent.futures
from databricks.sdk import WorkspaceClient
from psycopg_pool import ConnectionPool
from langgraph.checkpoint.postgres import PostgresSaver
w = WorkspaceClient()
PROJECT_ID = "agent-memory-db"
BRANCH_ID = "production"
ENDPOINT_ID = "primary"
HOST = "<your endpoint host>"
cred = w.postgres.generate_database_credential(
endpoint=f"projects/{PROJECT_ID}/branches/{BRANCH_ID}/endpoints/{ENDPOINT_ID}"
)
USER = w.current_user.me().user_name
conninfo = (
f"dbname=databricks_postgres user={USER} password={cred.token} "
f"host={HOST} port=5432 sslmode=require"
)
def init_pool_and_saver():
pool = ConnectionPool(
conninfo=conninfo,
max_size=5,
kwargs={"autocommit": True, "prepare_threshold": 0},
open=True,
)
# setup() は冪等なので再呼び出しは不要だが、呼んでも問題ない
checkpointer = PostgresSaver(pool)
return pool, checkpointer
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as ex:
pool, checkpointer = ex.submit(init_pool_and_saver).result(timeout=60)
print("Pool and checkpointer ready")
エージェントを組み立てます。
from datetime import datetime
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
from databricks_langchain import ChatDatabricks
llm = ChatDatabricks(endpoint="databricks-claude-sonnet-4")
@tool
def get_current_datetime() -> str:
"""現在の日時を返します。"""
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
agent = create_react_agent(
model=llm,
tools=[get_current_datetime],
checkpointer=checkpointer,
)
print("Agent ready")
ポイントは create_react_agent(... checkpointer=checkpointer) の部分です。Checkpointer に PostgresSaver を渡すだけで、エージェントは毎ターンの会話状態を Lakebase に永続化するようになります。LangGraph 側でこれ以上特別な設定は不要です。
ステップ6: 動作確認 (同一スレッドでの会話保持)
thread_id を configurable に渡して会話を始めます。同じ thread_id で再度 invoke すれば、過去の会話の文脈が保持されたまま続けられます。
THREAD_ID = "tutorial-session-001"
config = {"configurable": {"thread_id": THREAD_ID}}
# ターン1: 自分の名前を伝える
print("=== ターン1 ===")
result = agent.invoke(
{"messages": [{"role": "user", "content": "私の名前は太郎です。よろしくお願いします。"}]},
config=config,
)
print(result["messages"][-1].content)
# ターン2: 名前を覚えているか
print("\n=== ターン2 ===")
result = agent.invoke(
{"messages": [{"role": "user", "content": "私の名前は何でしたっけ?"}]},
config=config,
)
print(result["messages"][-1].content)
実行結果:
=== ターン1 ===
太郎さん、はじめまして!よろしくお願いします。
何かお手伝いできることがあれば、お気軽にお声かけください。
現在の日時を確認したり、その他のご質問にもお答えできます。
=== ターン2 ===
太郎さんですね!先ほど自己紹介していただいた際に、お名前を太郎とおっしゃっていました。
ターン2でエージェントが「太郎さん」と返答しているのは、Lakebase 上に保存された前ターンの会話状態を読み込んで、コンテキストを維持できている証拠です。短期メモリが正常に動作しています。
ステップ7: 動作確認 (別スレッドでは記憶を引き継がないこと)
thread_id を変えると、同じエージェントでも別のセッションとして扱われ、前の会話は引き継がれません。
NEW_THREAD_ID = "tutorial-session-002"
config2 = {"configurable": {"thread_id": NEW_THREAD_ID}}
print("=== 別スレッドでの確認 ===")
result = agent.invoke(
{"messages": [{"role": "user", "content": "私の名前は何でしたっけ?"}]},
config=config2,
)
print(result["messages"][-1].content)
実行結果:
=== 別スレッドでの確認 ===
申し訳ございませんが、私はあなたのお名前を知りません。
この会話の中で、あなたがお名前を教えてくださっていないためです。
もしよろしければ、お名前を教えていただけますでしょうか?
期待通り、別スレッドでは前の会話を引き継いでいません。短期メモリ(Checkpointer)は thread_id をキーにスコープされているためです。
ということは、ユーザーをまたいで永続的に「太郎さんは温泉が好き」のような知識を覚えさせたい場合は、Checkpointer とは別の仕組み(LangGraph の Store API)が必要になります。これは次回記事で扱います。
ステップ8: Lakebase内のチェックポイントを覗く
会話のたびに何が Lakebase に保存されたのか、SQL で直接確認できます。
def show_checkpoints():
with pool.connection() as conn:
with conn.cursor() as cur:
cur.execute("""
SELECT thread_id, checkpoint_id, type
FROM checkpoints
ORDER BY thread_id, checkpoint_id;
""")
return cur.fetchall()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as ex:
rows = ex.submit(show_checkpoints).result(timeout=15)
print(f"Total checkpoints: {len(rows)}\n")
print(f"{'thread_id':<30} {'checkpoint_id':<40}")
print("-" * 70)
for thread_id, ckpt_id, _ in rows:
print(f"{thread_id:<30} {ckpt_id:<40}")
実行結果:
Total checkpoints: 9
thread_id checkpoint_id
----------------------------------------------------------------------
tutorial-session-001 1f142ce1-012c-60ad-bfff-865ce2882b43
tutorial-session-001 1f142ce1-012f-6f71-8000-ff5c7b7e8d4f
tutorial-session-001 1f142ce1-1aa7-6754-8001-82ed883163d7
tutorial-session-001 1f142ce1-1b11-687e-8002-06f25dc4d1ed
tutorial-session-001 1f142ce1-1b14-68d7-8003-a8b5c54c1a38
tutorial-session-001 1f142ce1-28cc-6625-8004-8629b1758f77
tutorial-session-002 1f142ce1-cb7c-6990-bfff-a961470ed7d1
tutorial-session-002 1f142ce1-cb80-6913-8000-3be462eb6d14
tutorial-session-002 1f142ce1-dad6-6b22-8001-a82e3468497c
tutorial-session-001 は 6 個、tutorial-session-002 は 3 個のチェックポイントが残っています。session-001 は2ターンの会話で、各ターンの中で「ユーザー入力」「ツール呼び出し検討」「LLM応答」のような中間状態が複数記録されるため、ターン数より多くのチェックポイントが残ります。session-002 は1ターンだけなので少なめです。
LangGraph の time-travel 機能を使えば、これらの過去のチェックポイントから会話を任意のポイントで再開・分岐させることもできます。デバッグや A/Bテストに非常に便利な機能ですが、本記事のスコープ外なので別の機会に。
ハマりどころのまとめ
実際に試して詰まった箇所を記録しておきます。
databricks-langchain を入れると langgraph がダウングレードされて ImportError: cannot import name 'ExecutionInfo' が出る。これは --upgrade 付きで langgraph を再インストールすれば解消する。
Autoscaling プロジェクトでは SDK の API が w.postgres.* 系になる。Provisioned 用の w.database.* を使うと Resource not found エラーになる。Provisioned と Autoscaling は同居も可能だが、SDK の呼び分けが必要。
OAuth トークンは60分で失効する。長時間動かすエージェントでは、ConnectionPool の connection_class をカスタマイズして接続のたびにトークンを再発行する仕組みを入れるのが定石(本記事では検証目的なのでシンプルな構成にしてある)。トークンローテーションのサンプルは公式ドキュメントの Connect external app to Lakebase using SDK にあります。
Free Edition のサーバレスコンピュートでは psycopg3 binary の動的ロードが不安定で、import psycopg の段階で SIGABRT で落ちることがあります。本記事は有償版で動作確認済みです。
次回予告
短期メモリだけでは「ユーザーが過去のセッションで話した好み」は引き継げません。次回は LangGraph の PostgresStore を使って長期メモリを実装し、agent-langgraph-advanced 相当の構成に拡張します。
その先の連載では、評価ハーネス層(MLflow Tracing → 評価データセット自動生成 → カスタムジャッジ → 継続的改善ループ)も扱う予定です。
なお、本記事の構成を Unity Catalog 登録 + デプロイ + Agent Evaluation までフルパスで実装する場合は、過去記事 Databricks Lakebaseを用いたステートフルAIエージェント を参照してください。ResponsesAgent でラップする部分や agents.deploy() の流れは過去記事のコードがそのまま参考になります(認証部分は本記事の Autoscaling 用コードに置き換える必要があります)。
まとめ
- Lakebase Autoscaling + LangGraph PostgresSaver で短期メモリ付きエージェントが構築できる
-
thread_idを切り替えることで会話セッションを分離できる - 全ての状態は Lakebase に永続化されており、SQL で中身を直接覗ける
- Autoscaling 用の SDK は
w.postgres.*系で、Provisioned とは API が異なる - 依存関係まわりにいくつか注意点があるので、バージョンを意識してインストールするのが吉
参考リンク
- Databricks Lakebaseを用いたステートフルAIエージェント (過去記事、Provisioned版フルパス)
- Lakebase Autoscaling とは (公式ドキュメント)
- Lakebase Autoscaling 入門 (公式ドキュメント)
- Autoscaling by default (公式ドキュメント、移行説明)
- AI agent memory (公式ドキュメント)
- Agent state and memory (Lakebase 視点の解説)
- LangGraph Persistence (公式ドキュメント)
- databricks/app-templates (GitHub)