マニュアルサイトに以下のページができていました。
サンプルノートブックを動かしてみます。
注意
- 執筆時点ではLakebaseは日本リージョンでは利用できません。AWS USリージョンのワークスペースを使っています。
- サンプルノートブックではサービスプリンシパルの作成が必要です。今回はPATで代替しています。そのため、一部が動作していません。
Mosaic AIエージェントフレームワーク:Databricks LakebaseとLangGraphを使ったスレッドスコープメモリ付きステートフルエージェントの作成とデプロイ
このノートブックでは、Mosaic AIエージェントフレームワークとLangGraphを使い、Lakebaseをエージェントの永続メモリおよびチェックポイントストアとして利用したステートフルエージェントの構築方法を紹介します。スレッドを使うことで、会話の状態をLakebaseに保存し、エージェントにスレッドIDを渡すだけで会話履歴全体を送信する必要がなくなります。
このノートブックで行うこと:
- Lakebase(Databricksの新しいPostgresデータベース)とLangGraphを使い、DatabricksエージェントでスレッドIDによる状態管理を行うステートフルエージェントグラフを作成
- LangGraphエージェントを
ResponsesAgentインターフェースでラップし、Databricksの各種機能と互換性を持たせる - エージェントの動作をローカルでテスト
- モデルをUnity Catalogに登録し、エージェントをログ・デプロイしてアプリやPlaygroundで利用可能にする
LanggraphのPostgresSaverを使い、Lakebase Postgresデータベースへの接続を行います。
なぜLakebaseを使うのか?
ステートフルエージェントは、作業内容を永続化・再開・検査するための保存先が必要です。Lakebaseは、エージェントの状態を管理されたUCガバナンス付きストアとして提供します:
- 耐障害性・再開可能な状態管理。スレッド、途中のチェックポイント、ツール出力、ノード状態などを自動的に保存し、任意の時点から再開・分岐・リプレイが可能です。
- クエリ・可視化が容易。状態はLakehouseに保存されるため、SQLやノートブックで会話を監査したり、ダッシュボードなど他のDatabricks機能と連携できます。
- Unity Catalogによるガバナンス。AIの状態も他のテーブル同様にデータ権限・リネージ・監査を適用できます。
ステートフルエージェントとは?
ステートレスなLLM呼び出しと異なり、ステートフルエージェントはステップやセッションをまたいでコンテキストを保持・再利用します。新しい会話ごとにスレッドIDで論理的なタスクや対話ストリームを追跡します。既存のスレッドをいつでも再開でき、会話履歴全体を渡す必要がありません。
前提条件
- Lakebaseインスタンスの作成(Databricksドキュメント参照:AWS | Azure)
- SQL Warehouses → Lakebase Postgres → データベースインスタンス作成 からLakebaseインスタンスを作成し、「接続情報」セクションの値をこのノートブックに入力してください。
- ノートブック内の"TODO"をすべて完了してください。
依存関係のインストール
%pip install -U -qqqq databricks-langchain langgraph==0.5.3 uv databricks-agents mlflow-skinny[databricks] \
langgraph-checkpoint-postgres==2.0.21 psycopg[binary,pool]
dbutils.library.restartPython()
初回のみ: Lakebaseインスタンスでチェックポインタをセットアップ
データベースインスタンスを作成しておきます。
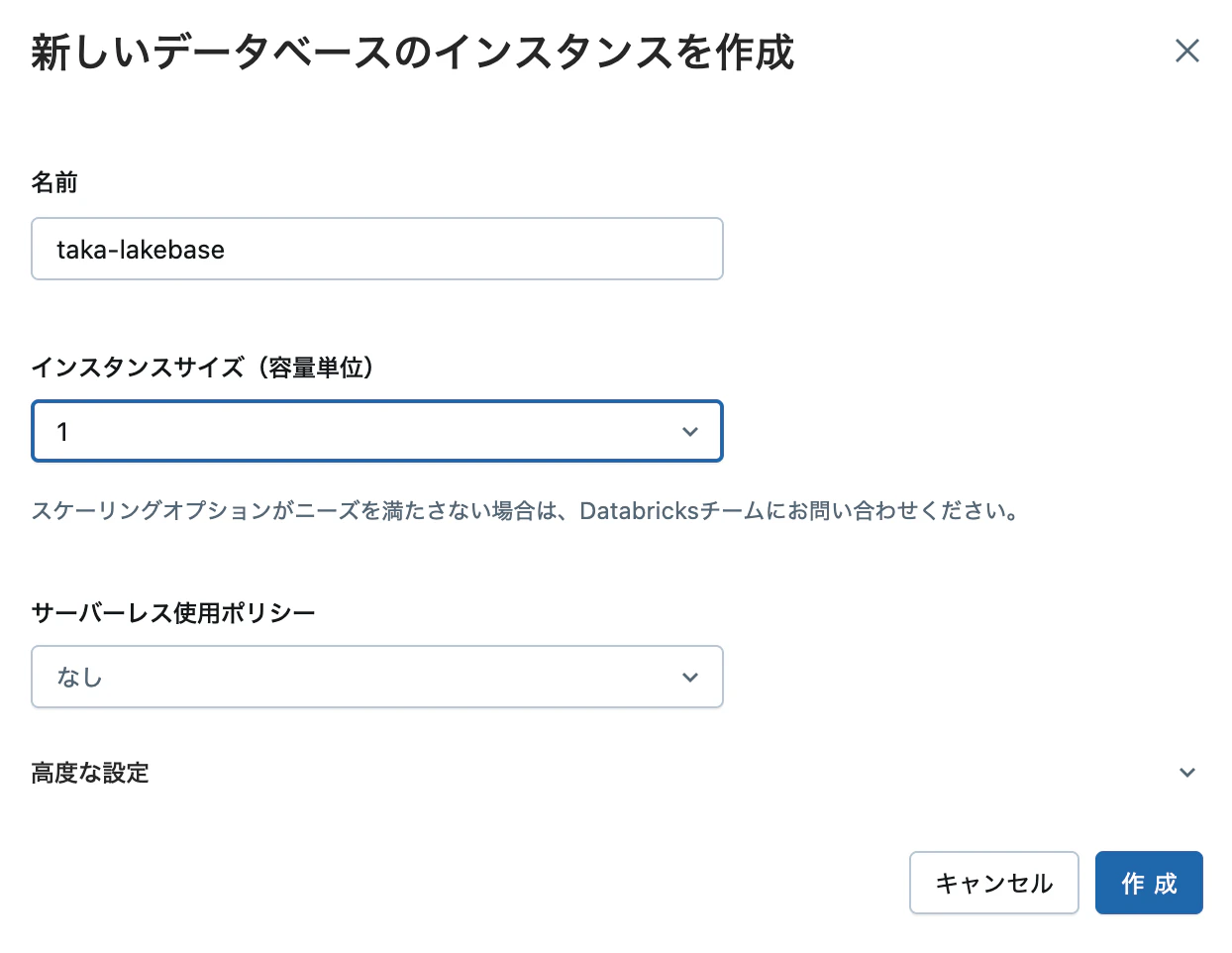
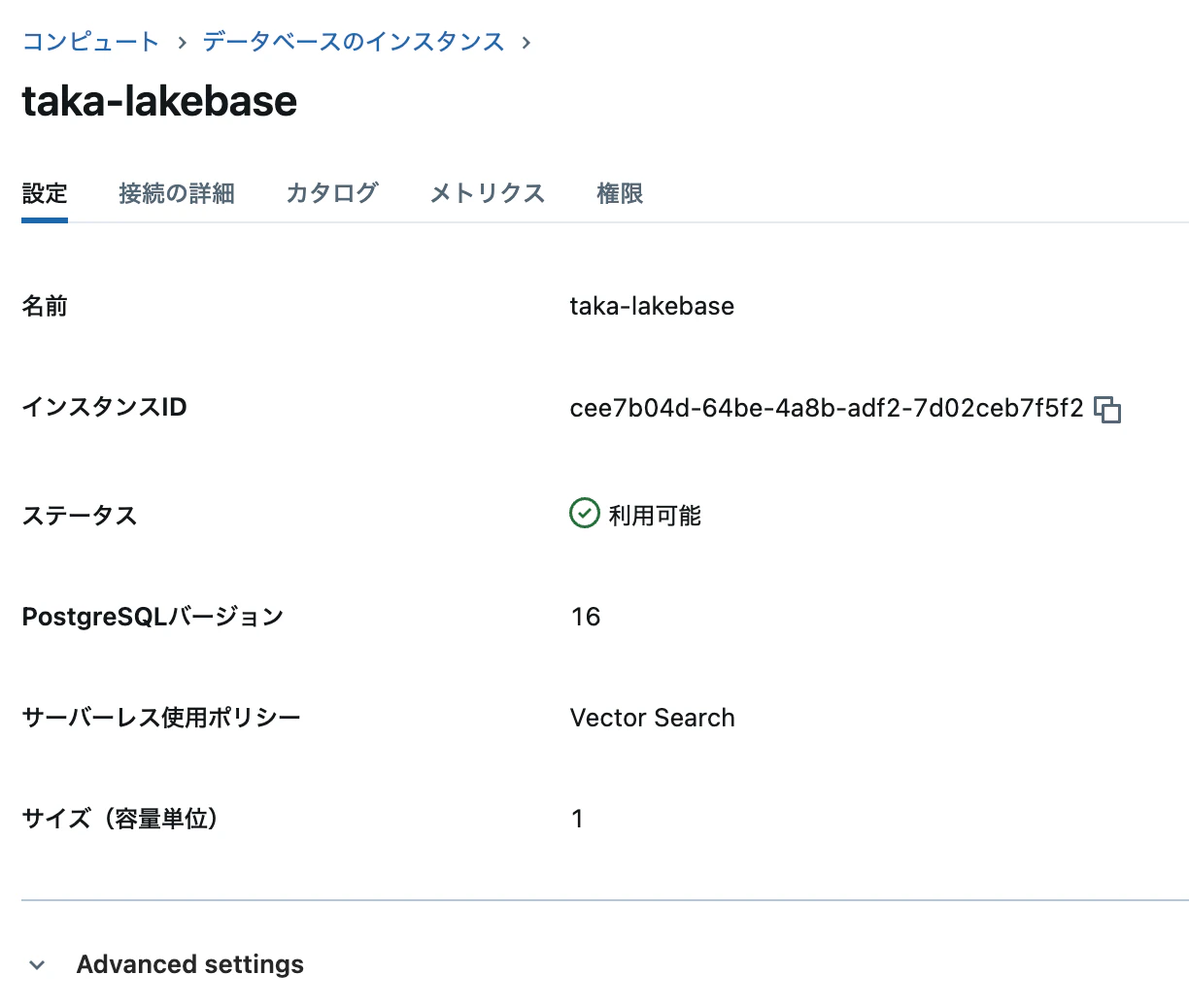
起動したらインスタンス名やホスト名をコピーしておきます。
import os
import uuid
from databricks.sdk import WorkspaceClient
from psycopg_pool import ConnectionPool
import psycopg
from langgraph.checkpoint.postgres import PostgresSaver
# TODO: ここにLakebaseインスタンスの詳細を入力してください。ユーザー名にはサービスプリンシパルを作成し、lakebaseインスタンスにdatabricks_superuser権限を付与してください。
# 詳細はサービスプリンシパルのドキュメントを参照してください:
# https://docs.databricks.com/ja/admin/users-groups/service-principals
# サービスプリンシパルのクライアントIDとシークレットをSP_CLIENT_ID/SP_CLIENT_SECRETとして使用します。
# これによりチェックポインタの初期化が可能になります。
DB_INSTANCE_NAME = "taka-lakebase"
DB_NAME = "databricks_postgres"
#SP_CLIENT_ID = "insert-sp-client-id-here"
#SP_CLIENT_SECRET = "insert-sp-client-secret-here"
TOKEN = "<パーソナルアクセストークン>"
SSL_MODE = "require"
DB_HOST = "instance-xxxx.database.cloud.databricks.com"
DB_PORT = 5432
WORKSPACE_HOST = "https://xxxx.cloud.databricks.com/"
w = WorkspaceClient(
host = WORKSPACE_HOST,
token=TOKEN
#client_id = SP_CLIENT_ID,
#client_secret = SP_CLIENT_SECRET
)
def db_password_provider() -> str:
"""
Databricksにこのインスタンス用の新しいDB認証情報を発行させます。
"""
cred = w.database.generate_database_credential(
request_id=str(uuid.uuid4()),
instance_names=[DB_INSTANCE_NAME],
)
return cred.token
class CustomConnection(psycopg.Connection):
"""
プールが新しい接続を作成する際に、
*接続時*に新しいパスワードを注入するpsycopg Connectionのサブクラスです。
"""
@classmethod
def connect(cls, conninfo="", **kwargs):
# 新しいパスワードをkwargsに追加
kwargs["password"] = db_password_provider()
# 更新したkwargsでスーパークラスのconnectメソッドを呼び出す
return super().connect(conninfo, **kwargs)
pool = ConnectionPool(
#conninfo=f"dbname={DB_NAME} user={SP_CLIENT_ID} host={DB_HOST} port={DB_PORT} sslmode={SSL_MODE}",
conninfo=f"dbname={DB_NAME} user=takaaki.yayoi@databricks.com host={DB_HOST} port={DB_PORT} sslmode={SSL_MODE}",
connection_class=CustomConnection,
min_size=1,
max_size=10,
open=True,
)
# プールを使ってチェックポイントテーブルを初期化
with pool.connection() as conn:
conn.autocommit = True # トランザクションラッピングを無効化
checkpointer = PostgresSaver(conn)
checkpointer.setup()
conn.autocommit = False # 後でトランザクションを使いたい場合はデフォルトに戻す
with conn.cursor() as cur:
cur.execute("select 1")
print("✅ プールに接続し、チェックポイントテーブルの準備ができました。")
✅ プールに接続し、チェックポイントテーブルの準備ができました。
なお、ネットワークが疎通していればローカルからも接続できます。
MacなのでHomebrewでクライアントをインストールします。
brew install postgresql@15
echo 'export PATH="/opt/homebrew/opt/postgresql@15/bin:$PATH"' >> ~/.zshrc
source ~/.zshrc
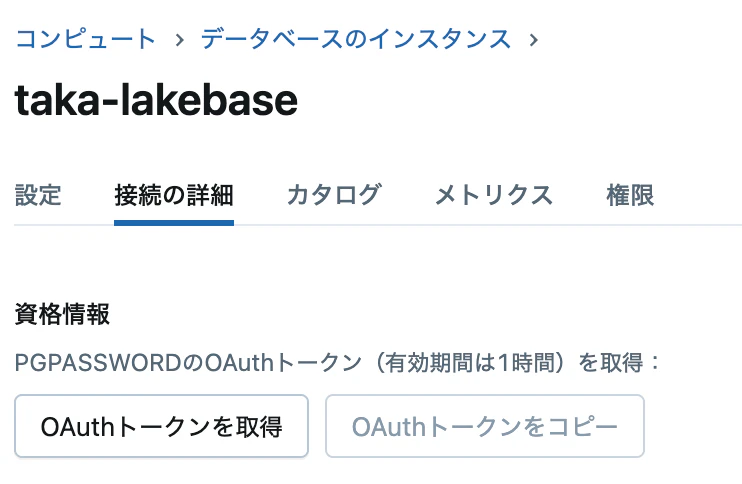
データベースインスタンスの接続の詳細タブで、OAuthトークンの取得、コピーをしておきます。
psql "host=instance-xxxx.database.cloud.databricks.com user=takaaki.yayoi@databricks.com dbname=databricks_postgres port=5432 sslmode=require"
パスワードには上でコピーしたOAuthトークンを指定します。
databricks_postgres=> SELECT version();
version
-------------------------------------------------------------------------------------------------------
PostgreSQL 16.9 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0, 64-bit
(1 row)
エージェントをコードで定義
agent.pyにエージェントコードを書き込む
下のセルでエージェントコードを1つのPythonファイルとして定義します。%%writefileマジックコマンドを使い、後でログやデプロイに利用できるようにします。
LangGraphエージェントをResponsesAgentインターフェースでラップ
Databricks AI機能との互換性のため、LangGraphResponsesAgentクラスはLangGraphエージェントをResponsesAgentインターフェースでラップします。
DatabricksではResponsesAgentの利用を推奨しています。これにより、オープンソース標準に基づくマルチターン会話エージェントの作成が簡単になります。MLflowのResponsesAgentドキュメントも参照してください。
%%writefile agent.py
import json
import logging
import os
import time
import urllib.parse
import uuid
from threading import Lock
from typing import Annotated, Any, Generator, Optional, Sequence, TypedDict
import mlflow
from databricks_langchain import (
ChatDatabricks,
DatabricksFunctionClient,
UCFunctionToolkit,
)
from databricks.sdk import WorkspaceClient
from langchain_core.messages import (
AIMessage,
AIMessageChunk,
BaseMessage,
)
from langchain_core.runnables import RunnableConfig, RunnableLambda
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.graph import END, StateGraph
from langgraph.graph.message import add_messages
from langgraph.prebuilt.tool_node import ToolNode
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
ResponsesAgentStreamEvent,
)
import psycopg
from psycopg_pool import ConnectionPool
from psycopg.rows import dict_row
from contextlib import contextmanager
logger = logging.getLogger(__name__)
logging.basicConfig(level=os.getenv("LOG_LEVEL", "INFO"))
############################################
# LLMエンドポイントとシステムプロンプトを定義
############################################
# TODO: モデルサービングエンドポイントを指定してください
LLM_ENDPOINT_NAME = "databricks-claude-3-7-sonnet"
# TODO: システムプロンプトを更新してください
SYSTEM_PROMPT = "あなたは役に立つアシスタントです。利用可能なツールを使用して質問に答えてください。"
# TODO: ここにLakebaseの設定値を入力してください
LAKEBASE_CONFIG = {
"instance_name": "taka-lakebase",
"conn_host": "instance-xxxx.database.cloud.databricks.com",
"conn_db_name": "databricks_postgres",
"conn_ssl_mode": "require",
}
###############################################################################
## エージェント用のツールを定義します。これによりテキスト生成以外のデータ取得やアクションが可能になります
## さらに多くのツールの作成や使用例は下記を参照
## https://docs.databricks.com/en/generative-ai/agent-framework/agent-tool.html
###############################################################################
tools = []
# UCツールの例。必要に応じて追加してください
UC_TOOL_NAMES: list[str] = []
if UC_TOOL_NAMES:
uc_toolkit = UCFunctionToolkit(function_names=UC_TOOL_NAMES)
tools.extend(uc_toolkit.tools)
# Databricksベクトルサーチインデックスをツールとして利用
# 詳細: https://docs.databricks.com/ja/generative-ai/agent-framework/unstructured-retrieval-tools.html#locally-develop-vector-search-retriever-tools-with-ai-bridge
# 非構造化検索用のベクトルサーチツールインスタンスを格納するリスト
VECTOR_SEARCH_TOOLS = []
# ベクトルサーチリトリーバーツールを追加する場合は、
# VectorSearchRetrieverToolとcreate_tool_infoを使い、
# 結果をTOOL_INFOSにappendしてください。
# 例:
# VECTOR_SEARCH_TOOLS.append(
# VectorSearchRetrieverTool(
# index_name="",
# # filters="..."
# )
# )
tools.extend(VECTOR_SEARCH_TOOLS)
#####################
## エージェントロジックを定義
#####################
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], add_messages]
custom_inputs: Optional[dict[str, Any]]
custom_outputs: Optional[dict[str, Any]]
class CredentialConnection(psycopg.Connection):
"""キャッシュ付きで新しいOAuthトークンを生成するカスタム接続クラス。"""
workspace_client = None
instance_name = None
# キャッシュ属性
_cached_credential = None
_cache_timestamp = None
_cache_duration = 3000 # 50分(50 * 60秒)
_cache_lock = Lock()
@classmethod
def connect(cls, conninfo='', **kwargs):
"""50分キャッシュ付きでOAuthトークンを注入するconnectをオーバーライド"""
if cls.workspace_client is None or cls.instance_name is None:
raise ValueError("workspace_clientとinstance_nameをCredentialConnectionクラスにセットしてください")
# キャッシュ済みまたは新しい認証情報を取得し、kwargsに新しいパスワードを追加
credential_token = cls._get_cached_credential()
kwargs['password'] = credential_token
# 更新したkwargsでスーパークラスのconnectメソッドを呼び出す
return super().connect(conninfo, **kwargs)
@classmethod
def _get_cached_credential(cls):
"""キャッシュから認証情報を取得、またはキャッシュが期限切れなら新規発行"""
with cls._cache_lock:
current_time = time.time()
# 有効なキャッシュがあればそれを返す
if (cls._cached_credential is not None and
cls._cache_timestamp is not None and
current_time - cls._cache_timestamp < cls._cache_duration):
return cls._cached_credential
# 新しい認証情報を発行
credential = cls.workspace_client.database.generate_database_credential(
request_id=str(uuid.uuid4()),
instance_names=[cls.instance_name]
)
# 新しい認証情報をキャッシュ
cls._cached_credential = credential.token
cls._cache_timestamp = current_time
return cls._cached_credential
class LangGraphResponsesAgent(ResponsesAgent):
"""Lakebase PostgreSQLチェックポイントを使ったステートフルエージェント(ResponsesAgent利用)。
特徴:
- 資格情報のローテーションとキャッシュ付きのコネクションプーリング
- スレッドベースの会話状態永続化
- UC関数によるツールサポート
"""
def __init__(self, lakebase_config: dict[str, Any]):
self.lakebase_config = lakebase_config
self.workspace_client = WorkspaceClient()
# モデルとツール
self.model = ChatDatabricks(endpoint=LLM_ENDPOINT_NAME)
self.system_prompt = SYSTEM_PROMPT
self.model_with_tools = self.model.bind_tools(tools) if tools else self.model
# コネクションプール設定
self.pool_min_size = int(os.getenv("DB_POOL_MIN_SIZE", "1"))
self.pool_max_size = int(os.getenv("DB_POOL_MAX_SIZE", "10"))
self.pool_timeout = float(os.getenv("DB_POOL_TIMEOUT", "30.0"))
# トークンキャッシュ期間(分単位、環境変数で上書き可能)
cache_duration_minutes = int(os.getenv("DB_TOKEN_CACHE_MINUTES", "50"))
CredentialConnection._cache_duration = cache_duration_minutes * 60
# 資格情報ローテーション付きのコネクションプールを初期化
self._connection_pool = self._create_rotating_pool()
mlflow.langchain.autolog()
def _get_username(self) -> str:
"""DB接続用のユーザー名を取得"""
try:
sp = self.workspace_client.current_service_principal.me()
return sp.application_id
except Exception:
user = self.workspace_client.current_user.me()
return user.user_name
def _create_rotating_pool(self) -> ConnectionPool:
"""資格情報を自動ローテーションしキャッシュするコネクションプールを作成"""
# カスタム接続クラスにワークスペースクライアントとインスタンス名をセット
CredentialConnection.workspace_client = self.workspace_client
CredentialConnection.instance_name = self.lakebase_config["instance_name"]
username = self._get_username()
host = self.lakebase_config["conn_host"]
database = self.lakebase_config.get("conn_db_name", "databricks_postgres")
# カスタム接続クラスでプールを作成
pool = ConnectionPool(
conninfo=f"dbname={database} user={username} host={host} sslmode=require",
connection_class=CredentialConnection,
min_size=self.pool_min_size,
max_size=self.pool_max_size,
timeout=self.pool_timeout,
open=True,
kwargs={
"autocommit": True, # .setup()メソッドでチェックポイントテーブルをDBにコミットするために必要
"row_factory": dict_row, # PostgresSaver実装がDB行を辞書形式でアクセスするために必要
"keepalives": 1,
"keepalives_idle": 30,
"keepalives_interval": 10,
"keepalives_count": 5,
}
)
# プールのテスト
try:
with pool.connection() as conn:
with conn.cursor() as cursor:
cursor.execute("SELECT 1")
logger.info(
f"資格情報ローテーション付きコネクションプールの作成に成功 "
f"(min={self.pool_min_size}, max={self.pool_max_size}, "
f"token_cache={CredentialConnection._cache_duration / 60:.0f}分)"
)
except Exception as e:
pool.close()
raise ConnectionError(f"コネクションプールの作成に失敗: {e}")
return pool
@contextmanager
def get_connection(self):
"""プールからコネクションを取得するコンテキストマネージャ"""
with self._connection_pool.connection() as conn:
yield conn
def _langchain_to_responses(self, messages: list[BaseMessage]) -> list[dict[str, Any]]:
"""LangChainメッセージをResponses API形式に変換"""
responses = []
for message in messages:
message_dict = message.model_dump()
msg_type = message_dict["type"]
if msg_type == "ai":
if tool_calls := message_dict.get("tool_calls"):
for tool_call in tool_calls:
responses.append(
self.create_function_call_item(
id=message_dict.get("id") or str(uuid.uuid4()),
call_id=tool_call["id"],
name=tool_call["name"],
arguments=json.dumps(tool_call["args"]),
)
)
else:
responses.append(
self.create_text_output_item(
text=message_dict.get("content", ""),
id=message_dict.get("id") or str(uuid.uuid4()),
)
)
elif msg_type == "tool":
responses.append(
self.create_function_call_output_item(
call_id=message_dict["tool_call_id"],
output=message_dict["content"],
)
)
elif msg_type == "human":
responses.append({
"role": "user",
"content": message_dict.get("content", "")
})
return responses
def _create_graph(self, checkpointer: PostgresSaver):
"""LangGraphワークフローを作成"""
def should_continue(state: AgentState):
messages = state["messages"]
last_message = messages[-1]
if isinstance(last_message, AIMessage) and last_message.tool_calls:
return "continue"
return "end"
if self.system_prompt:
preprocessor = RunnableLambda(
lambda state: [{"role": "system", "content": self.system_prompt}] + state["messages"]
)
else:
preprocessor = RunnableLambda(lambda state: state["messages"])
model_runnable = preprocessor | self.model_with_tools
def call_model(state: AgentState, config: RunnableConfig):
response = model_runnable.invoke(state, config)
return {"messages": [response]}
workflow = StateGraph(AgentState)
workflow.add_node("agent", RunnableLambda(call_model))
if tools:
workflow.add_node("tools", ToolNode(tools))
workflow.add_conditional_edges(
"agent",
should_continue,
{"continue": "tools", "end": END}
)
workflow.add_edge("tools", "agent")
else:
workflow.add_edge("agent", END)
workflow.set_entry_point("agent")
return workflow.compile(checkpointer=checkpointer)
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
"""ストリーミングなしの予測"""
# predict()とpredict_stream()の両方で同じthread_idを使用
ci = dict(request.custom_inputs or {})
if "thread_id" not in ci:
ci["thread_id"] = str(uuid.uuid4())
request.custom_inputs = ci
outputs = [
event.item
for event in self.predict_stream(request)
if event.type == "response.output_item.done"
]
return ResponsesAgentResponse(output=outputs, custom_outputs={"thread_id": ci["thread_id"]})
def predict_stream(
self,
request: ResponsesAgentRequest,
) -> Generator[ResponsesAgentStreamEvent, None, None]:
"""PostgreSQLチェックポイント付きのストリーミング予測"""
# カスタム入力からthread_idを取得、なければ新規発行
thread_id = (request.custom_inputs or {}).get("thread_id", str(uuid.uuid4()))
# 入力ResponsesメッセージをChatCompletions形式に変換
# LangChainが自動的にChatCompletions→LangChain形式に変換
cc_msgs = self.prep_msgs_for_cc_llm([i.model_dump() for i in request.input])
langchain_msgs = cc_msgs
checkpoint_config = {"configurable": {"thread_id": thread_id}}
# プールからコネクションを取得
with self.get_connection() as conn:
# チェックポインタとグラフを作成
checkpointer = PostgresSaver(conn)
graph = self._create_graph(checkpointer)
# グラフ実行をストリーム
for event in graph.stream(
{"messages": langchain_msgs},
checkpoint_config,
stream_mode=["updates", "messages"]
):
if event[0] == "updates":
for node_data in event[1].values():
for item in self._langchain_to_responses(node_data["messages"]):
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=item
)
# テキスト生成のリアルタイムチャンクをストリーム
elif event[0] == "messages":
try:
chunk = event[1][0]
if isinstance(chunk, AIMessageChunk) and chunk.content:
yield ResponsesAgentStreamEvent(
**self.create_text_delta(
delta=chunk.content,
item_id=chunk.id
),
)
except Exception as e:
logger.error(f"チャンクのストリーミング中にエラー: {e}")
# ----- モデルをエクスポート -----
AGENT = LangGraphResponsesAgent(LAKEBASE_CONFIG)
mlflow.models.set_model(AGENT)
エージェントをローカルでテスト
dbutils.library.restartPython()
from agent import AGENT
# メッセージ1: thread_idを含めずに呼び出し(新しいスレッドが作成されます)
result = AGENT.predict({
"input": [{"role": "user", "content": "私はステートフルエージェントに取り組んでいます"}]
})
print(result.model_dump(exclude_none=True))
thread_id = result.custom_outputs["thread_id"]
INFO:agent:資格情報ローテーション付きコネクションプールの作成に成功 (min=1, max=10, token_cache=50分)
INFO:httpx:HTTP Request: POST https://xxxx.cloud.databricks.com/serving-endpoints/chat/completions "HTTP/1.1 200 OK"
INFO:py4j.clientserver:Closing down clientserver connection
{'object': 'response', 'output': [{'type': 'message', 'id': 'run--cd0941f5-9deb-4872-9cb1-04934f854ff9', 'content': [{'text': 'ステートフルエージェントについて取り組まれているんですね。ステートフルエージェントとは、過去のやり取りや状態を記憶し、それに基づいて行動できるAIシステムのことです。\n\n具体的にどのような側面に取り組んでいるのでしょうか?例えば:\n- ステートフルエージェントの設計や実装について\n- 特定の応用分野(会話AI、ロボティクス、推薦システムなど)\n- メモリ管理や状態保持の技術的側面\n- 評価方法\n\nより詳細な情報をいただければ、お役に立てる情報を提供できます。', 'type': 'output_text'}], 'role': 'assistant'}], 'custom_outputs': {'thread_id': '70d3b327-3db0-4972-ad44-9a30c8143e17'}}
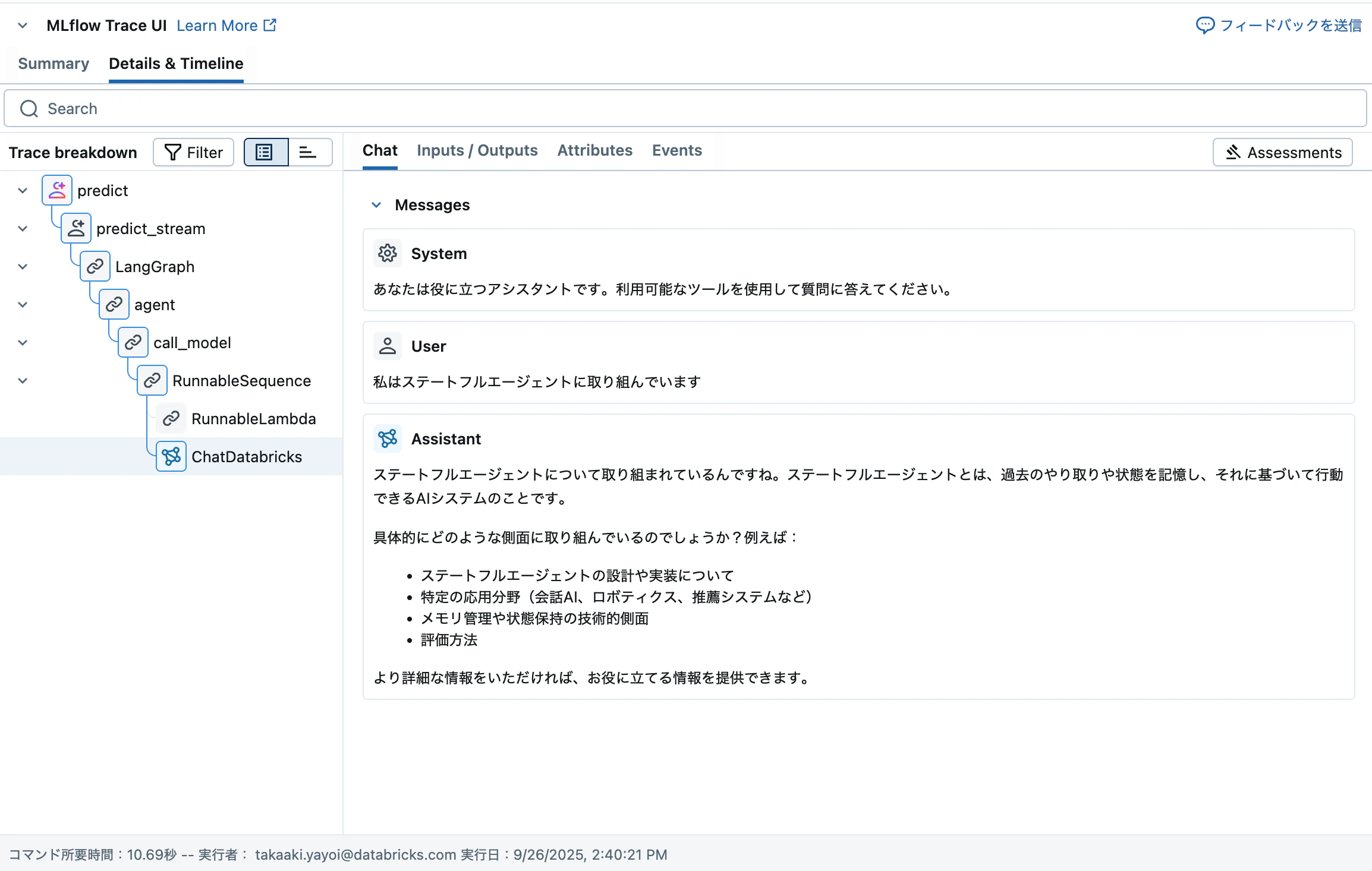
この時点でpsqlでデータベースを確認します。
databricks_postgres=> \dt
List of relations
Schema | Name | Type | Owner
--------+-----------------------+-------+------------------------------
public | checkpoint_blobs | table | takaaki.yayoi@databricks.com
public | checkpoint_migrations | table | takaaki.yayoi@databricks.com
public | checkpoint_writes | table | takaaki.yayoi@databricks.com
public | checkpoints | table | takaaki.yayoi@databricks.com
(4 rows)
テーブルが作成されています。
# メッセージ2: thread_idを指定して呼び出し。エージェントが前回のpredictメッセージのコンテキストを記憶していることを確認できます。
response2 = AGENT.predict({
"input": [{"role": "user", "content": "私は何に取り組んでいますか?"}],
"custom_inputs": {"thread_id": thread_id}
})
print("レスポンス2:", response2.model_dump(exclude_none=True))
INFO:py4j.clientserver:Python Server ready to receive messages
INFO:py4j.clientserver:Received command c on object id p0
INFO:httpx:HTTP Request: POST https://xxxx.cloud.databricks.com/serving-endpoints/chat/completions "HTTP/1.1 200 OK"
INFO:py4j.clientserver:Closing down clientserver connection
レスポンス2: {'object': 'response', 'output': [{'type': 'message', 'id': 'run--aa394c91-c844-4b71-b3c8-1fb4c060da78', 'content': [{'text': '先ほどのメッセージでは、あなたが「ステートフルエージェント」に取り組んでいるとおっしゃっていました。しかし、具体的にどのような側面や目的で取り組んでいるのかについての詳細は共有されていません。\n\nもし具体的な内容や目標、直面している課題などについて教えていただければ、より適切なサポートができるかと思います。', 'type': 'output_text'}], 'role': 'assistant'}], 'custom_outputs': {'thread_id': '70d3b327-3db0-4972-ad44-9a30c8143e17'}}
回答の精度は若干微妙ですが、状態が記録されていることが確認できます。
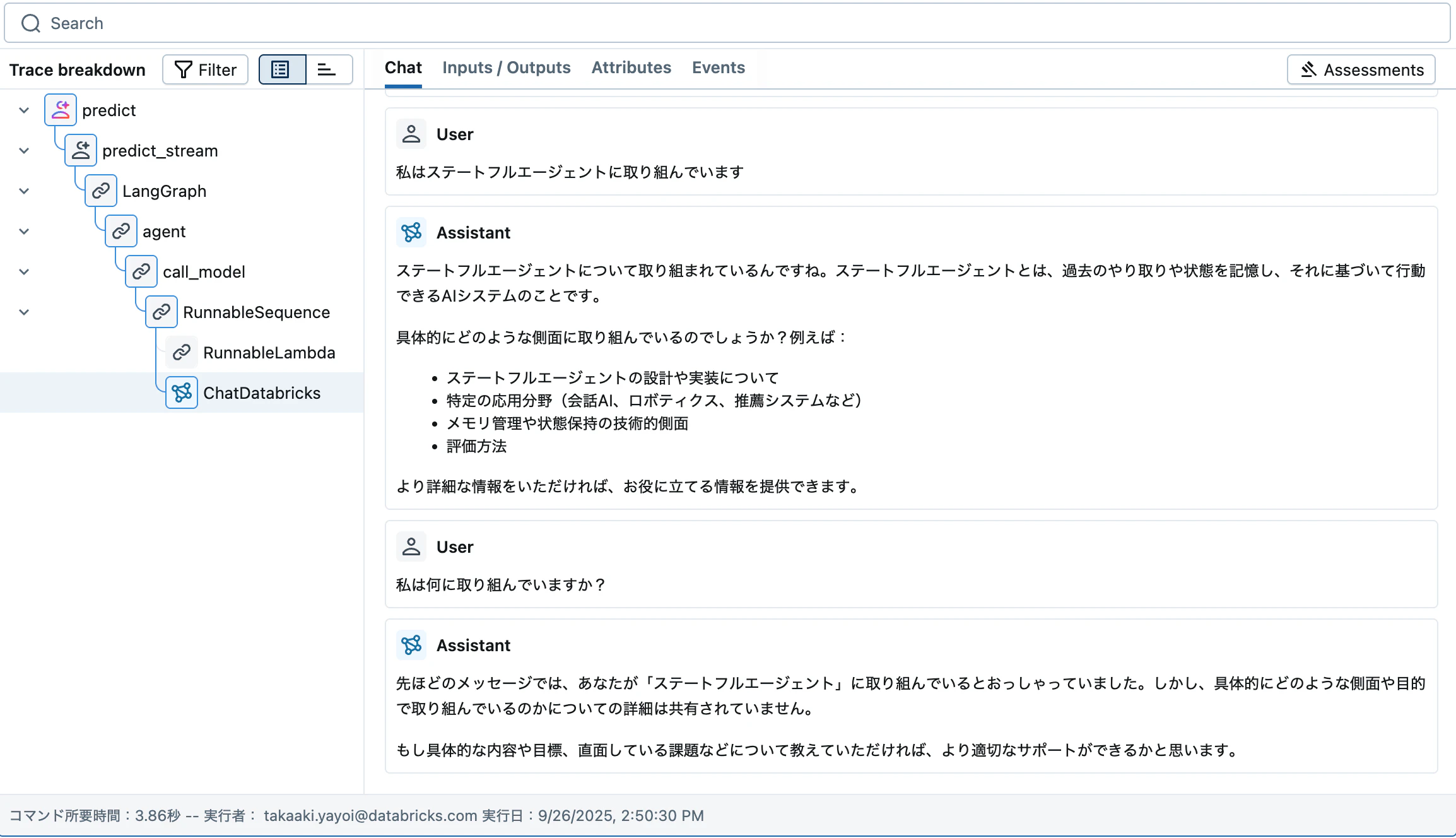
# thread_idを渡さずにエージェントを呼び出す例 - メモリが保持されないことに注意してください
response3 = AGENT.predict({
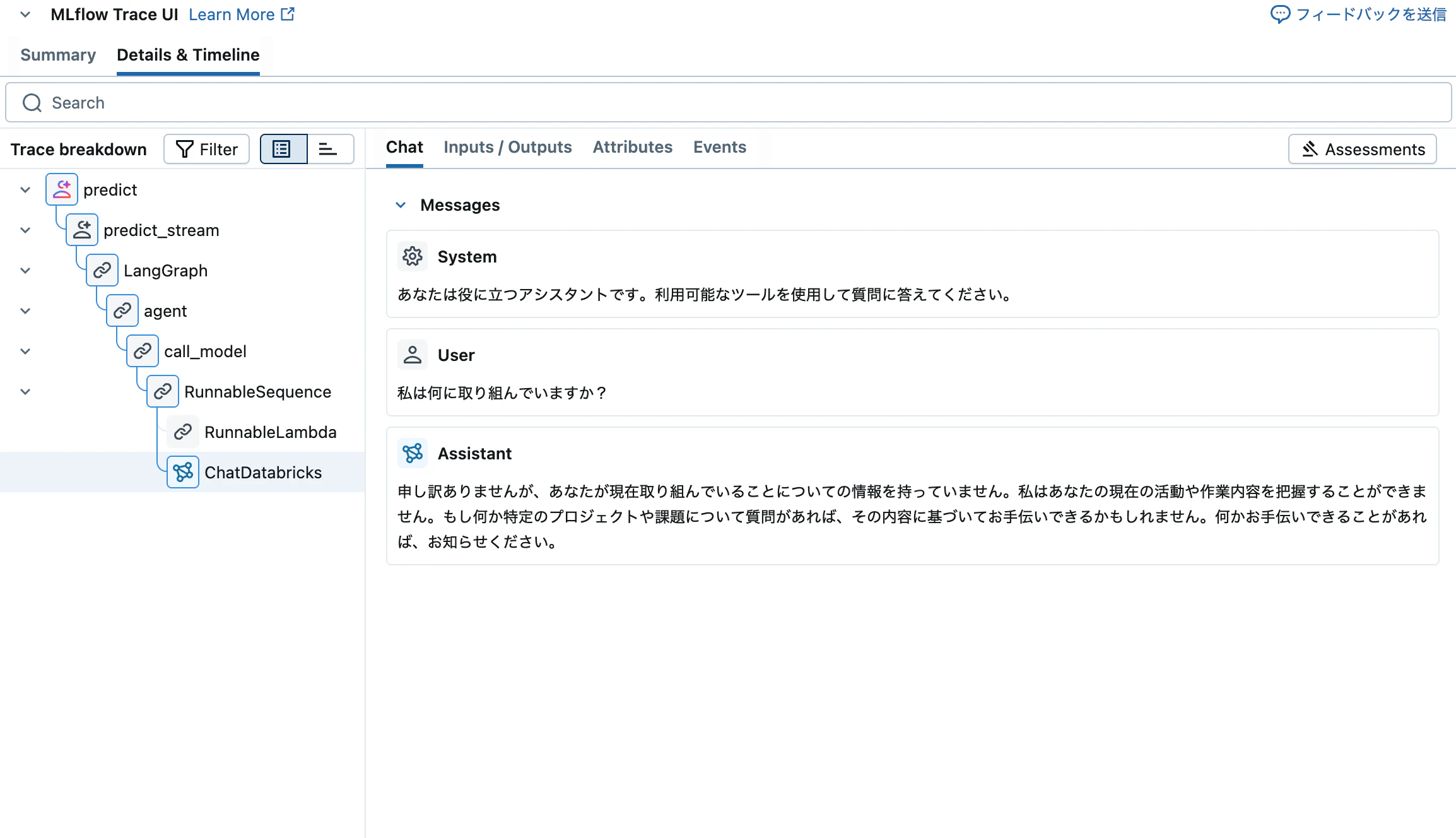
"input": [{"role": "user", "content": "私は何に取り組んでいますか?"}],
})
print("レスポンス3(thread_id未指定):", response3.model_dump(exclude_none=True))
スレッドIDを渡さない場合は過去の状態を参照しません。
エージェントをMLflowモデルとしてログ
agent.pyファイルのコードとしてエージェントをMLflowモデルとしてログします。詳細はMLflow - Models from Codeを参照してください。
Databricksリソースの自動認証を有効化
よく使われるDatabricksリソースタイプについては、エージェントのログ時に依存リソースを事前に宣言することで自動認証パススルーを有効化できます。これにより、エージェントエンドポイント内からこれらのリソースへ安全に短命な認証情報が自動的に払い出されます。
自動認証を有効にするには、mlflow.pyfunc.log_model()呼び出し時に依存するDatabricksリソースを指定してください。
TODO:
- lakebaseをresource typeとして追加
- Unity Catalogツールがvector search indexやexternal functionsを利用する場合は、該当するvector search indexやUC接続オブジェクトもresourcesに含めてください。詳細はドキュメント(AWS | Azure)を参照。
# デプロイ時に自動認証パススルーのために指定するDatabricksリソースを決定
import mlflow
from agent import tools, LLM_ENDPOINT_NAME, LAKEBASE_CONFIG
from databricks_langchain import VectorSearchRetrieverTool
from mlflow.models.resources import DatabricksFunction, DatabricksServingEndpoint, DatabricksLakebase
from unitycatalog.ai.langchain.toolkit import UnityCatalogTool
from pkg_resources import get_distribution
resources = [
DatabricksServingEndpoint(LLM_ENDPOINT_NAME),
DatabricksLakebase(database_instance_name=LAKEBASE_CONFIG["instance_name"])
]
for tool in tools:
if isinstance(tool, VectorSearchRetrieverTool):
resources.extend(tool.resources)
elif isinstance(tool, UnityCatalogTool):
resources.append(DatabricksFunction(function_name=tool.uc_function_name))
input_example = {
"input": [
{
"role": "user",
"content": "LLMエージェントとは何ですか?"
}
],
"custom_inputs": {"thread_id": "例スレッド-123"},
}
with mlflow.start_run():
logged_agent_info = mlflow.pyfunc.log_model(
name="agent",
python_model="agent.py",
input_example=input_example,
resources=resources,
pip_requirements=[
"databricks-langchain",
f"databricks-connect=={get_distribution('databricks-connect').version}",
f"langgraph=={get_distribution('langgraph').version}",
f"langgraph-checkpoint-postgres=={get_distribution('langgraph-checkpoint-postgres').version}",
f"psycopg[binary,pool]",
f"pydantic=={get_distribution('pydantic').version}",
]
)
Agent Evaluationによるエージェントの評価
Mosaic AI Agent Evaluationを使い、期待される応答や評価基準に基づいてエージェントの応答を評価します。指定した評価基準をもとに反復的に改善し、MLflowで品質指標を記録します。
ツール呼び出しの評価にはカスタムメトリクスを追加できます。Databricksドキュメント(AWS | Azure)も参照してください。
import mlflow
from mlflow.genai.scorers import RelevanceToQuery, RetrievalGroundedness, RetrievalRelevance, Safety
# 評価用データセット(例: 15番目のフィボナッチ数を計算)
eval_dataset = [
{
"inputs": {"input": [{"role": "user", "content": "15番目のフィボナッチ数を計算してください"}]},
"expected_response": "15番目のフィボナッチ数は610です。",
}
]
# モデルの評価を実行(MLflow UIで結果を確認できます)
eval_results = mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=lambda input: AGENT.predict({"input": input}),
scorers=[RelevanceToQuery(), Safety()], # 必要に応じて他のスコアラーも追加可能
)
デプロイ前のエージェント検証
エージェントを登録・デプロイする前に、mlflow.models.predict() APIを使って事前チェックを行います。
mlflow.models.predict(
model_uri=f"runs:/{logged_agent_info.run_id}/agent",
input_data={"input": [{"role": "user", "content": "私はステートフルエージェントに取り組んでいます"}]},
env_manager="uv",
)
モデルをUnity Catalogに登録
下記のcatalog、schema、model_nameを更新して、MLflowモデルをUnity Catalogに登録してください。
mlflow.set_registry_uri("databricks-uc")
# TODO: UCモデル用のカタログ、スキーマ、モデル名を定義してください
catalog = "users"
schema = "takaaki_yayoi"
model_name = "stateful-agent-threads-example"
UC_MODEL_NAME = f"{catalog}.{schema}.{model_name}"
# モデルをUCに登録
uc_registered_model_info = mlflow.register_model(
model_uri=logged_agent_info.model_uri, name=UC_MODEL_NAME
)
エージェントをデプロイ
注意
PATを用いてる場合はここでエラーになります。サービスプリンシパルを使いましょう。
from databricks import agents
agents.deploy(UC_MODEL_NAME, uc_registered_model_info.version, tags = {"endpointSource": "docs"})
次のステップ
エージェントのデプロイには約15分かかります。デプロイが完了したら、AI playgroundでチャットして追加チェックを行ったり、組織内のSMEに共有してフィードバックを得たり、プロダクションアプリケーションに組み込むことができます。
このステートフルエージェントを使えば、過去のスレッドを再開して会話を続けることができます。
Lakebaseインスタンスをクエリして、さまざまなスレッドやチェックポイントでの会話記録を確認できます。以下は10件のチェックポイントを確認する基本的なクエリ例です:
-- See all conversation threads with their metadata
SELECT
*
FROM checkpoints
LIMIT 10;
最近記録されたチェックポイントをチェックします:
SELECT
c.*,
(c.checkpoint::json->>'ts')::timestamptz AS ts
FROM checkpoints c
ORDER BY ts DESC
LIMIT 10;
実際に永続されていました。
\x auto
Expanded display is used automatically.
databricks_postgres=> select * from checkpoints;
-[ RECORD 1 ]--------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
thread_id | 70d3b327-3db0-4972-ad44-9a30c8143e17
checkpoint_ns |
checkpoint_id | 1f09a9b4-d4c2-6154-bfff-8b378d334d16
parent_checkpoint_id |
type |
checkpoint | {"v": 4, "id": "1f09a9b4-d4c2-6154-bfff-8b378d334d16", "ts": "2025-09-26T05:40:25.592856+00:00", "pending_sends": [], "versions_seen": {"__input__": {}}, "channel_versions": {"__start__": "00000000000000000000000000000001.0.05868272011326392"}}
metadata | {"step": -1, "source": "input", "parents": {}}
-[ RECORD 2 ]--------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
thread_id | 70d3b327-3db0-4972-ad44-9a30c8143e17
checkpoint_ns |
checkpoint_id | 1f09a9b4-d4c7-63b4-8000-d9527c05b954
parent_checkpoint_id | 1f09a9b4-d4c2-6154-bfff-8b378d334d16
type |
checkpoint | {"v": 4, "id": "1f09a9b4-d4c7-63b4-8000-d9527c05b954", "ts": "2025-09-26T05:40:25.594962+00:00", "pending_sends": [], "versions_seen": {"__input__": {}, "__start__": {"__start__": "00000000000000000000000000000001.0.05868272011326392"}}, "channel_versions": {"messages": "00000000000000000000000000000002.0.46667627401836886", "__start__": "00000000000000000000000000000002.0.46667627401836886", "branch:to:agent": "00000000000000000000000000000002.0.46667627401836886"}}
metadata | {"step": 0, "source": "loop", "parents": {}}
まとめ
まだ日本では使えないLakebaseですが、今回のようにエージェントの状態管理やDatabricks Appsとの連携など、組み合わせによっていろいろ価値が出てきそうです。