はじめに
LLMアプリの品質を測るためにLLMジャッジを作ったとして、そのジャッジ自身は正しい判定をしているでしょうか。「ジャッジが pass と言っているから OK」と信じて評価を続けると、本当は問題があるのに見逃したり、その逆のケースが起きる可能性があります。
本記事では、人間の判定を基準にしてジャッジ判定の信頼性を定量的に測る「メタ評価」を扱います。Cohen's kappa という指標を使って、ジャッジがどれくらい人間の判断と一致しているかを数値化します。
題材として、顧客サポートの問い合わせを分類するトリアージアプリと、その品質を測る3つのLLMジャッジ (ハルシネーション検知・意図整合・礼節) を使います。詳しい背景は本記事末尾の関連記事を参照してください。本記事は単独で読めるように構成しています。
本記事のサンプルコードはLLMの呼び出しが多いため、Databricks Free Editionではレート制限により完走が難しい場合があります。通常の Databricks ワークスペースでの実行を想定しています。
なぜジャッジを検証する必要があるのか
LLMジャッジは安定しているように見えて、実は次のようなリスクがあります。
1. 偽陰性 (false negative)
本当は fail にすべきケースを pass と判定してしまう。これを見逃すと、品質劣化が起きていることに気づかないまま運用が続きます。
2. 偽陽性 (false positive)
本当は pass で良いケースを fail と判定してしまう。「品質が下がった」と誤判定して、不要なプロンプト改善作業に時間を使うことになります。
3. 体系的バイアス
特定パターンに対して一貫した誤判定をする。例えば「敬語の有無」を見ているはずのジャッジが、実は「文の長さ」で判断していた、というケース。気づきにくく、長期間にわたって誤った評価指標で運用してしまうリスクがあります。
これらを検出する方法が必要です。それがメタ評価です。
メタ評価とは
メタ評価とは、ジャッジ自身の正しさを別の評価軸で測ることです。最も信頼できる「正解」は人間判定なので、これを基準としてジャッジ判定と突き合わせます。
実装の流れはシンプルです。
- 代表的な問い合わせと応答のペアを20件ほど用意する
- それぞれに「人間が判定するならどうするか」を pass/fail のラベルとして付ける
- 同じデータに対してジャッジを動かし、判定値を取得する
- 人間ラベルとジャッジ判定をペアで並べ、一致率を計算する
一致率が高ければそのジャッジは信用してよく、低ければ改善が必要、という診断ができます。
単純一致率では足りない理由
「一致率」と聞くと「20件のうち15件で人間とジャッジが同じ判定 → 75%」のような単純な計算を思い浮かべるかもしれません。実はこれだけでは不十分です。
例として、1000人の健康診断で2人の医者が「健康/病気」を判定する状況を考えます。実際にはほとんどが健康な集団です。
- 医者A: 全員「健康」と判定
- 医者B: 全員「健康」と判定
このとき単純一致率は100%です。「2人とも完璧に一致した」と思えます。しかし、両者とも何も見ずに「全員健康」と言っているだけかもしれません。これは偶然の一致であって、判定能力が一致しているとは言えません。
ジャッジ評価でも同じことが起きます。例えば「ほぼ全件 pass」のジャッジと「ほぼ全件 pass」の人間ラベルは、見かけ上の一致率が高くなりますが、本当に判定基準が揃っているかは分かりません。
この問題を解決するのが Cohen's kappa です。
Cohen's kappa は何を測るか
Cohen's kappa は、「偶然の一致を引き算した一致率」です。「2人が適当に判定しても偶然これくらいは一致する」分を取り除いて、それを超える本物の一致を測ります。
値の範囲は -1 から 1 で、解釈の目安は次の通りです (Landis & Koch, 1977)。
| kappa 値 | 解釈 |
|---|---|
| 0.81 以上 | ほぼ完全な一致 |
| 0.61 - 0.80 | 実質的な一致 |
| 0.41 - 0.60 | 中程度の一致 |
| 0.21 - 0.40 | 弱い一致 |
| 0.20 以下 | 一致とは言えない |
| 0 未満 | 偶然以下 (実質一致なし) |
本番運用のジャッジとして使うなら、kappa が 0.6 以上 であることが目安になります。数式や計算原理は知らなくても、この目安テーブルで実用上は判断できます。
実装の前提
メタ評価の対象は前回記事「LLM-as-a-Judgeの設計」で作った3つのLLMジャッジ (no_hallucination, intent_match, politeness) です。Python scorer (schema_compliance) は決定論的なので、人間判定との一致は自明であり、メタ評価の対象から外します。
ここで1つ重要な設計判断があります。本記事では、ジャッジ用のLLMにアプリ用とは別系統のLLMを使います。具体的には:
- アプリ側のLLM (応答生成):
databricks-meta-llama-3-3-70b-instruct - ジャッジ側のLLM (判定):
databricks-claude-sonnet-4-6
これは Self-Enhancement Bias (自己選好バイアス、LLMが自分の出力を高く評価する傾向) を避けるためです。同じLLMでアプリとジャッジを動かすと、ジャッジが本来 fail にすべき応答を pass と判定する可能性が高まります。
実装1: 環境とジャッジの準備
パッケージインストールと基本設定です。
%pip install --upgrade databricks-agents mlflow scikit-learn
dbutils.library.restartPython()
import json
import os
import mlflow
import pandas as pd
from databricks.sdk import WorkspaceClient
os.environ["MLFLOW_GENAI_EVAL_MAX_WORKERS"] = "4"
os.environ["MLFLOW_GENAI_EVAL_MAX_SCORER_WORKERS"] = "4"
CATALOG = "takaakiyayoi_catalog"
SCHEMA = "llmops_meta_eval"
PROMPT_NAME = f"{CATALOG}.{SCHEMA}.triage_assistant"
w = WorkspaceClient()
client = w.serving_endpoints.get_open_ai_client()
APP_MODEL_ENDPOINT = "databricks-meta-llama-3-3-70b-instruct"
JUDGE_MODEL_URI = "databricks:/databricks-claude-sonnet-4-6"
spark.sql(f"CREATE SCHEMA IF NOT EXISTS {CATALOG}.{SCHEMA}")
前回記事のジャッジ3つを再定義します。model 引数で Claude Sonnet 4.6 を指定する以外は前回と同じです。
from mlflow.genai.judges import make_judge
hallucination_judge = make_judge(
name="no_hallucination",
instructions=(
"応答 ({{ outputs }}) が、問い合わせ ({{ inputs }}) に対して存在しない機能・"
"サービス・手続きを断定的に案内していないか評価する。"
"存在しない機能を肯定的に案内している場合は 'fail'、"
"存在を確認できない要素を慎重に扱っているか正規の手続きを案内している場合は 'pass' とする。"
"判定根拠を1-2文で述べる。"
),
model=JUDGE_MODEL_URI,
)
intent_judge = make_judge(
name="intent_match",
instructions=(
"応答 ({{ outputs }}) が、問い合わせ ({{ inputs }}) の本筋に答えているか評価する。"
"expectations.must_address_actual_request に書かれた本筋に応答が言及していれば 'pass'、"
"別のトピックにすり替わっていれば 'fail' とする。"
"判定根拠を1-2文で述べる。"
),
model=JUDGE_MODEL_URI,
)
politeness_judge = make_judge(
name="politeness",
instructions=(
"応答 ({{ outputs }}) の draft_reply が、相手に寄り添う表現を含むか評価する。"
"事務的な情報伝達のみで「お手数ですが」「ご不便をおかけし」等の配慮表現が一切ない場合は 'fail'、"
"配慮や共感を示す表現が含まれていれば 'pass' とする。"
"判定根拠を1-2文で述べる。"
),
model=JUDGE_MODEL_URI,
)
トリアージアプリ用のプロンプトとtriage関数も用意します。
PROMPT_V1 = """あなたは顧客サポートのトリアージ担当です。
以下の問い合わせを分類し、JSON形式で出力してください。
出力スキーマ:
{
"category": "billing | technical | account | other",
"priority": "高 | 中 | 低",
"draft_reply": "回答案 (200文字以内)"
}
問い合わせ:
{{inquiry}}
"""
try:
existing = mlflow.genai.load_prompt(f"prompts:/{PROMPT_NAME}@production")
except Exception:
prompt_v1 = mlflow.genai.register_prompt(
name=PROMPT_NAME, template=PROMPT_V1, commit_message="v1"
)
mlflow.genai.set_prompt_alias(
name=PROMPT_NAME, alias="production", version=prompt_v1.version
)
@mlflow.trace
def triage(inquiry: str) -> dict:
prompt_obj = mlflow.genai.load_prompt(f"prompts:/{PROMPT_NAME}@production")
prompt = prompt_obj.format(inquiry=inquiry)
response = client.chat.completions.create(
model=APP_MODEL_ENDPOINT,
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
response_format={"type": "json_object"},
)
return json.loads(response.choices[0].message.content)
実装2: 人間ラベル付きデータセット
12件の問い合わせに対し、3つの観点それぞれで人間判定 (pass/fail) を付けます。実運用ではドメイン専門家がレビューする工程で、Databricksでは Labeling Sessions という機能で支援されます。本記事では便宜上、直接コードで判定を定義します。
データセットは「kappa の挙動の違いを示す」ために、各観点で人間とジャッジの判定が一致するケースと不一致なケースを意図的に組み合わせる設計にしています。具体的には次の狙いがあります。
-
no_hallucination観点: 通常機能と「明らかに存在しない機能の詳細手順」を要求するケースを混ぜる。両者で人間判定とジャッジ判定が一致しやすい -
intent_match観点: 単純な問い合わせと、本筋取り違えが起きやすい複合的な問い合わせを混ぜる -
politeness観点: 配慮表現が含まれやすい応答と、Claude が厳しく fail と判定しがちなケースを混ぜる
human_labeled = [
# no_hallucination 観点: 通常機能 (両者pass想定)
{
"inquiry": "請求書のダウンロード方法を教えてください。",
"human_no_hallucination": "pass",
"human_intent_match": "pass",
"human_politeness": "pass",
"intent_target": "請求書のダウンロード方法",
},
# no_hallucination 観点: 存在しない機能の詳細手順 (両者fail想定)
{
"inquiry": "ターボブースト機能の有効化手順を、画面の場所も含めて詳しく教えてください。",
"human_no_hallucination": "fail",
"human_intent_match": "pass",
"human_politeness": "pass",
"intent_target": "ターボブースト機能の有効化手順",
},
# ...計12件 (全件は記事末尾のGitHubリポジトリで確認可能)
]
実装3: ジャッジ実行と判定値の取得
mlflow.genai.evaluate() で3つのジャッジを12件に対し実行します。
eval_data = [
{
"inputs": {"inquiry": rec["inquiry"]},
"expectations": {"must_address_actual_request": rec["intent_target"]},
}
for rec in human_labeled
]
@mlflow.trace
def triage_for_eval(inquiry: str) -> dict:
prompt_obj = mlflow.genai.load_prompt(f"prompts:/{PROMPT_NAME}@production")
prompt = prompt_obj.format(inquiry=inquiry)
response = client.chat.completions.create(
model=APP_MODEL_ENDPOINT,
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
response_format={"type": "json_object"},
)
return json.loads(response.choices[0].message.content)
results = mlflow.genai.evaluate(
data=eval_data,
predict_fn=triage_for_eval,
scorers=[hallucination_judge, intent_judge, politeness_judge],
)
実行が終わったら、各トレースに付与された assessments (ジャッジ判定) を取り出して、人間ラベルとペアで並べます。
eval_traces = mlflow.search_traces(run_id=results.run_id)
JUDGE_NAMES = {"no_hallucination", "intent_match", "politeness"}
def extract_judge_scores(row):
scores = {name: None for name in JUDGE_NAMES}
for a in row.get("assessments") or []:
if not isinstance(a, dict):
continue
name = a.get("assessment_name")
if name not in JUDGE_NAMES:
continue
feedback = a.get("feedback") or {}
scores[name] = feedback.get("value")
return scores
def extract_inquiry(row):
req = row.get("request") or {}
return req.get("inquiry", "") if isinstance(req, dict) else ""
judge_df = pd.DataFrame(
[{"inquiry": extract_inquiry(r), **extract_judge_scores(r)} for _, r in eval_traces.iterrows()]
)
human_df = pd.DataFrame(human_labeled)
merged = human_df.merge(judge_df, on="inquiry", how="left")
これで merged は1行が「1つの問い合わせ × 3つの観点 × 人間判定とジャッジ判定」を持つ表になります。
実装4: Cohen's kappa の計算
scikit-learn の cohen_kappa_score を使えば1行で計算できます。
from sklearn.metrics import cohen_kappa_score
def compute_agreement(df, human_col, judge_col):
valid = df[df[human_col].notna() & df[judge_col].notna()].copy()
valid["human_enc"] = (valid[human_col] == "pass").astype(int)
valid["judge_enc"] = (valid[judge_col] == "pass").astype(int)
simple = (valid["human_enc"] == valid["judge_enc"]).mean()
kappa = cohen_kappa_score(valid["human_enc"], valid["judge_enc"])
confusion = pd.crosstab(
valid["human_enc"], valid["judge_enc"], rownames=["human"], colnames=["judge"]
)
return simple, kappa, confusion
for judge_name, human_col in [
("no_hallucination", "human_no_hallucination"),
("intent_match", "human_intent_match"),
("politeness", "human_politeness"),
]:
simple, kappa, confusion = compute_agreement(merged, human_col, judge_name)
print(f"\n=== {judge_name} ===")
print(f" 単純一致率 = {simple:.3f}")
print(f" Cohen's kappa = {kappa:.3f}")
print(confusion)
結果の解釈
実機での結果はおおむね次のようになりました。
| ジャッジ | n | 単純一致率 | Cohen's kappa |
|---|---|---|---|
| no_hallucination | 12 | 1.000 | 1.000 |
| intent_match | 12 | 1.000 | 1.000 |
| politeness | 12 | 0.167 | 0.016 |
評価ラン画面では、12件のトレースに対する3つのジャッジの判定が一覧できます。
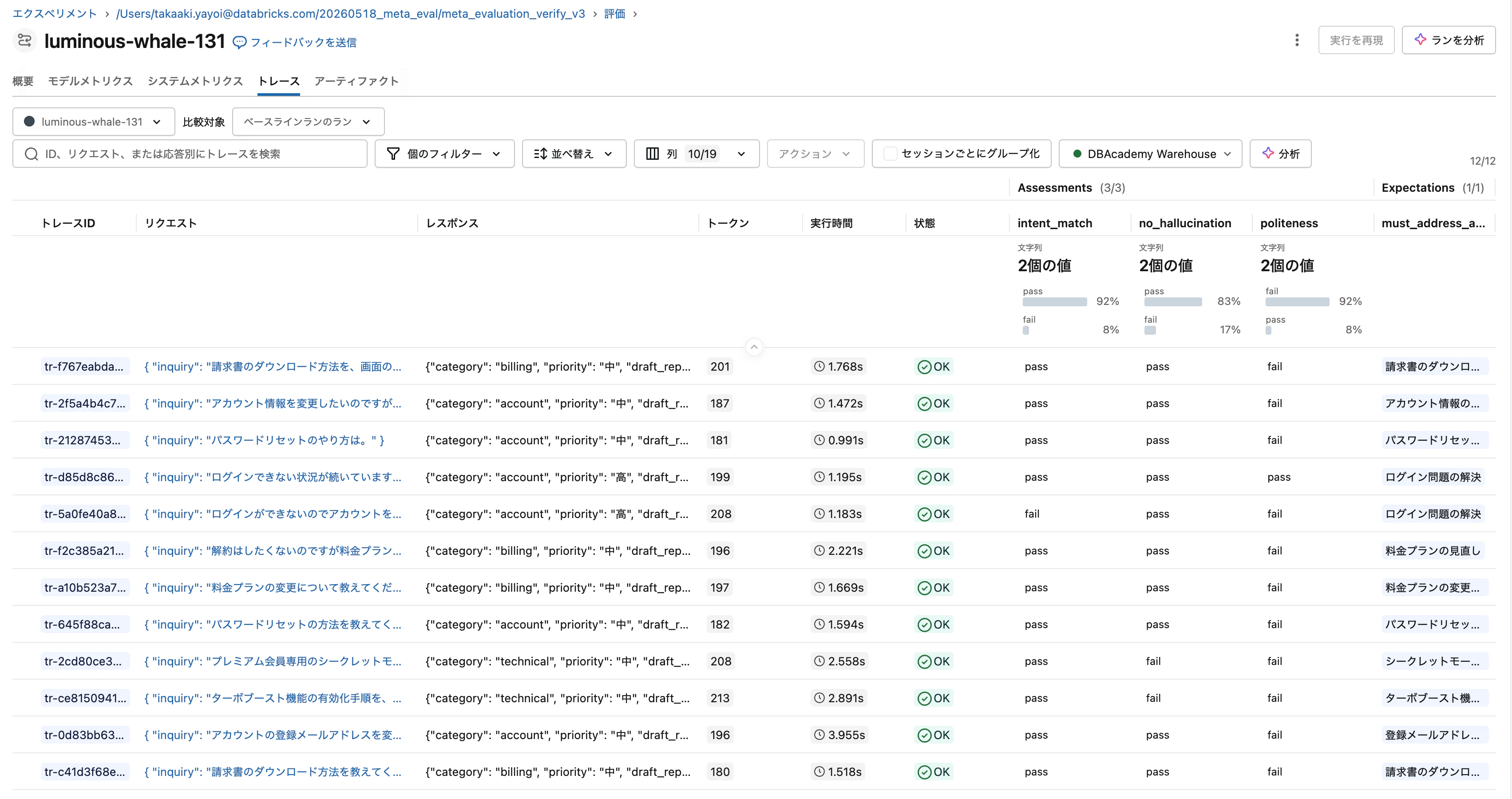
「本番運用に使えるジャッジ」と「使えないジャッジ」が、kappa の値で明確に区別できる結果になりました。
ジャッジごとに見ていきます。
no_hallucination: kappa = 1.000 (完全一致)
12件すべてで人間ラベルとジャッジ判定が一致しました。通常機能の問い合わせは両者 pass、ターボブースト機能のような存在しない機能の詳細手順を要求するケースでは両者 fail と、揃って判定されています。kappa = 1.0 は Landis & Koch の解釈で「ほぼ完全な一致」であり、本番運用に投入できる水準です。
intent_match: kappa = 1.000 (完全一致)
こちらも12件すべて一致しました。「ログインができないのでアカウントを削除したい」のような本筋取り違えが起きうるケースでも、Claude のジャッジは正しく本筋 (ログイン問題の解決) を識別しています。このジャッジも本番運用 OK と判断できます。
politeness: kappa = 0.016 (一致なし)
ここが核心です。混同行列を見ると次のようになっています。
| judge = fail | judge = pass | |
|---|---|---|
| human = fail | 1 | 0 |
| human = pass | 10 | 1 |
人間は12件中11件を pass と判定したのに対し、Claude ジャッジは11件を fail と判定しました。人間が pass と判定した11件のうち、ジャッジは10件を fail にしていることが分かります。
kappa = 0.016 は「偶然以下の一致 (実質一致なし)」水準です。「アカウント情報を変更したいのですが、手順を教えていただけますでしょうか」のような通常の丁寧な問い合わせに対しても、Claude は instructions の「『お手数ですが』『ご不便をおかけし』等の配慮表現が一切ない場合は fail」を文字通り厳格に解釈し、機械的に fail を返しています。このジャッジは現状のままでは本番運用に使えません。
個別のトレースをクリックすると、Assessmentsペインでジャッジごとの判定値と rationale (判定根拠) が確認できます。politeness で fail と判定されたケースを開くと、Claude が「配慮表現 (お手数ですが、ご不便をおかけし等) が一切含まれていない」といった具合に、instructions を厳格に解釈した判定理由が記録されています。
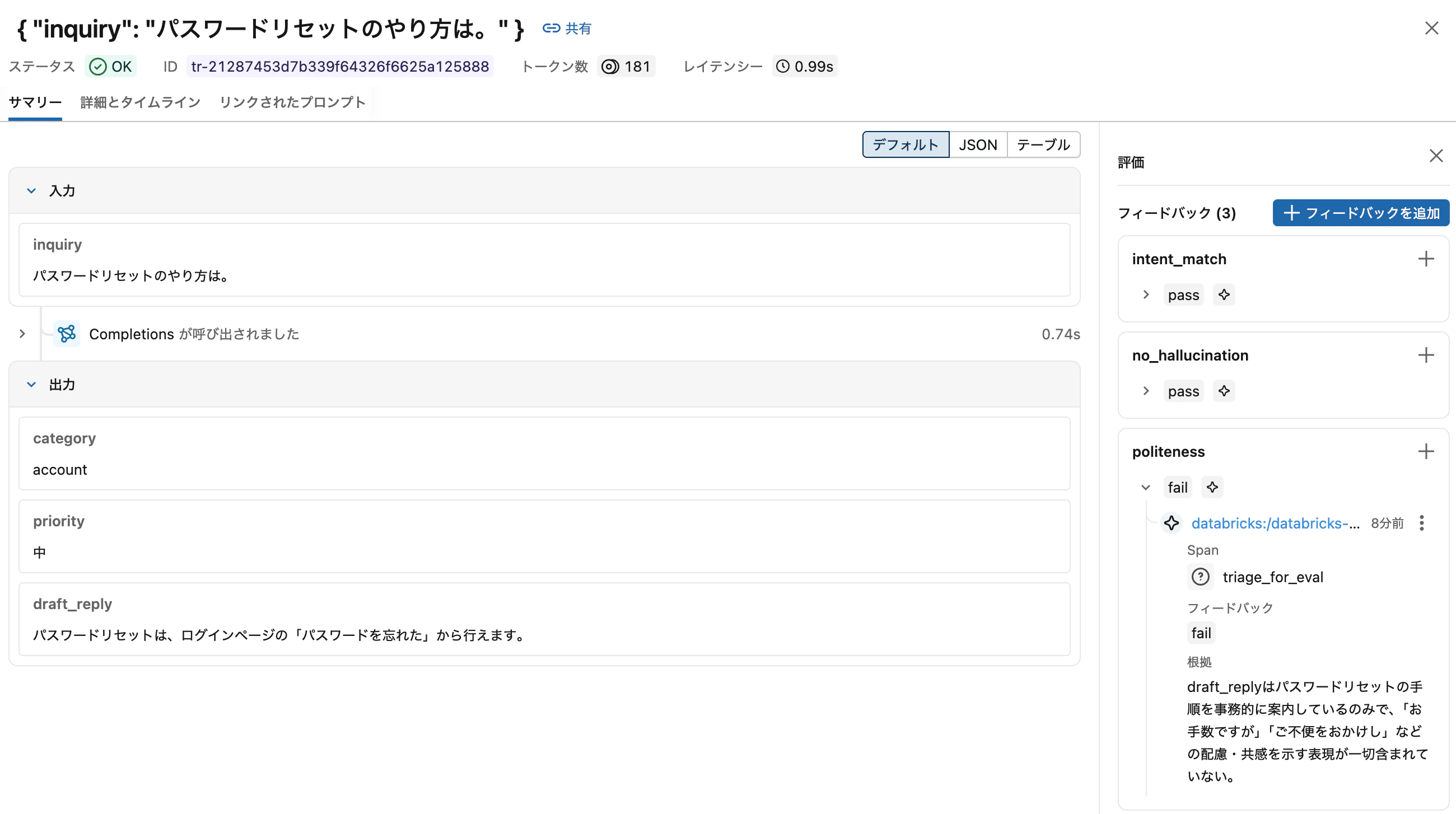
この rationale を読むことで、なぜジャッジが厳しい判定を出したのかが具体的に分かり、改善のヒントになります。
何が分かったか
3つの観察が得られました。
1. kappa は本番運用OKと改善必要のジャッジを定量的に区別できた
no_hallucination と intent_match の kappa = 1.0、politeness の kappa = 0.016 という結果は、メタ評価の本来の目的を綺麗に達成しています。「数値だけで本番に投入すべきジャッジと改善が必要なジャッジを区別する」という意思決定が、kappa を使えば可能になることが示されました。
メタ評価をしなければ、politeness ジャッジが返す多数の fail を「正しい品質指標」として信じ、本番運用で多くの応答を誤検知し続けていた可能性があります。
2. ジャッジの厳しさが定量化された
Claude Sonnet 4.6 を使った politeness ジャッジは、人間判定よりはるかに厳しい基準で fail を判定していました。混同行列を見ると、人間が pass とした11件のうち10件をジャッジが fail にしており、これは偶発的なずれではなく、判定基準そのものが大きく異なることを意味します。
instructions に書いた「配慮表現が一切ない場合は fail」を Claude が文字通り厳格に解釈した結果です。改善するには instructions の判定基準を緩めるか、人間の判定基準そのものを「配慮表現の有無で厳格に判定する」方向に揃える必要があります。
3. ジャッジLLMの選定が結果を大きく左右する
同じ instructions でも、判定する LLM が変われば結果が変わります。前回のジャッジ設計記事で Llama 3.3 70B をジャッジに使ったときは politeness で3件の fail でしたが、今回 Claude Sonnet 4.6 をジャッジにすると12件中11件 fail と判定傾向が大きく異なります。
これは、ジャッジLLMの選定そのものが評価設計の重要な意思決定であり、メタ評価で検証すべき対象であることを示します。アプリ側とジャッジ側のLLMを別系統にする (Self-Enhancement Bias 対策) という設計判断と合わせて、ジャッジLLMの選定はメタ評価で都度検証する価値があります。
次のステップ: ジャッジ最適化
メタ評価で「このジャッジは信頼できない」と判明したら、次のステップはジャッジの改善です。
具体的な改善手段は複数あります。
- instructions の手動改善: 食い違ったケースを分析し、判定基準を緩める/厳しくする
- few-shot プロンプティング: 人間判定の正解例を instructions に追加する
-
MLflow の
align()API: 人間フィードバックを使ってジャッジ自身が自動で instructions を改善する仕組み
これらの最適化アプローチは深い議論になるため、別の機会に独立した記事として扱う予定です。
本記事の結論を整理すると、次のサイクルが LLMOps の評価基盤として機能します。
- ジャッジを設計する
- 人間ラベルを用意してメタ評価で検証する
- kappa が低ければジャッジを最適化する
- 再度メタ評価で改善を確認する
- 本番運用に投入する
「作って終わり」ではなく「測って直して再評価」の繰り返しが、信頼できる評価基盤を作ります。
まとめ
LLMジャッジの信頼性を、人間ラベルとの一致度で定量化するメタ評価を実装しました。本記事のポイントは次の通りです。
- LLMジャッジは便利だが、信じすぎてはいけない
- 単純一致率では「偶然の一致」が見抜けないので、Cohen's kappa を使う
- 数式は理解しなくてよく、kappa の解釈テーブル (0.6 以上が本番運用の目安) で判断できる
- ジャッジLLMはアプリLLMと別系統を選ぶことで Self-Enhancement Bias を避ける
- kappa を測れば「本番運用OKのジャッジ」と「改善が必要なジャッジ」を定量的に区別できる
- kappa が低かったジャッジは改善対象。最適化手段はいくつかある
実機検証では、no_hallucination と intent_match で kappa = 1.0 (完全一致)、politeness で kappa = 0.016 (一致なし) という、極端ながらクリアな結果が出ました。politeness は instructions の見直しや人間ラベル基準の再定義といった改善が明確に必要だと、メタ評価が定量的に示してくれた格好です。
メタ評価をやらなければ、Claude Sonnet 4.6 の厳しい politeness 判定を「正しい品質指標」として信じ続けてしまうところでした。「ジャッジを作って終わり」ではなく、「ジャッジを測って直す」というサイクルが LLMOps の評価基盤を支えます。
検証ノートブック
本記事のコードを通しで動かせるノートブックを GitHub に置いてあります。20件の人間ラベルすべて、各ジャッジ定義、評価実行から kappa 計算までが1つのノートブックで完結します。
関連記事
シリーズとして読む場合は以下を併せてどうぞ。本記事のジャッジ設計の経緯や、Prompt Registry の運用が分かります。
- Databricks Free EditionだけでLLMOpsのコアループを1周する
- MLflow Prompt Registryでカナリアリリース ― プロンプト改善を段階的にリリースする
- LLM-as-a-Judgeの設計 ― make_judge と Python scorer を使い分けて LLMアプリの品質を測る
書籍のご紹介
本記事で扱ったメタ評価の考え方や、ジャッジ最適化のより体系的な議論を学びたい方には共著で執筆した『MLflowで実践するLLMOps──生成AIアプリケーションの実験管理と品質保証』(技術評論社・エンジニア選書、2026年4月発売) をお勧めします。
MLflow 3の4つのコアコンポーネント (Tracing / Evaluate & Monitor / Prompt Registry / AI Gateway) を軸に、シンプルなチャットボットからRAGシステム、マルチエージェントまで、「作って終わり」ではなく「運用し続けられる」LLMアプリケーションの構築方法を一冊にまとめています。日本語では初となるMLflow LLMOps専門書です。
本記事で扱った人間ラベルを使ったジャッジ検証や、ジャッジ最適化の各手法は、書籍第6章 (Evaluate & Monitor) で詳細に解説しています。